 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphEcho: Graph-Driven Unsupervised Domain Adaptation for Echocardiogram Video Segmentation
Sep 20, 2023



Echocardiogram video segmentation plays an important role in cardiac disease diagnosis. This paper studies the unsupervised domain adaption (UDA) for echocardiogram video segmentation, where the goal is to generalize the model trained on the source domain to other unlabelled target domains. Existing UDA segmentation methods are not suitable for this task because they do not model local information and the cyclical consistency of heartbeat. In this paper, we introduce a newly collected CardiacUDA dataset and a novel GraphEcho method for cardiac structure segmentation. Our GraphEcho comprises two innovative modules, the Spatial-wise Cross-domain Graph Matching (SCGM) and the Temporal Cycle Consistency (TCC) module, which utilize prior knowledge of echocardiogram videos, i.e., consistent cardiac structure across patients and centers and the heartbeat cyclical consistency, respectively. These two modules can better align global and local features from source and target domains, improving UDA segmentation results. Experimental results showed that our GraphEcho outperforms existing state-of-the-art UDA segmentation methods. Our collected dataset and code will be publicly released upon acceptance. This work will lay a new and solid cornerstone for cardiac structure segmentation from echocardiogram videos. Code and dataset are available at: https://github.com/xmed-lab/GraphEcho
GL-Fusion: Global-Local Fusion Network for Multi-view Echocardiogram Video Segmentation
Sep 20, 2023



Cardiac structure segmentation from echocardiogram videos plays a crucial role in diagnosing heart disease. The combination of multi-view echocardiogram data is essential to enhance the accuracy and robustness of automated methods. However, due to the visual disparity of the data, deriving cross-view context information remains a challenging task, and unsophisticated fusion strategies can even lower performance. In this study, we propose a novel Gobal-Local fusion (GL-Fusion) network to jointly utilize multi-view information globally and locally that improve the accuracy of echocardiogram analysis. Specifically, a Multi-view Global-based Fusion Module (MGFM) is proposed to extract global context information and to explore the cyclic relationship of different heartbeat cycles in an echocardiogram video. Additionally, a Multi-view Local-based Fusion Module (MLFM) is designed to extract correlations of cardiac structures from different views. Furthermore, we collect a multi-view echocardiogram video dataset (MvEVD) to evaluate our method. Our method achieves an 82.29% average dice score, which demonstrates a 7.83% improvement over the baseline method, and outperforms other existing state-of-the-art methods. To our knowledge, this is the first exploration of a multi-view method for echocardiogram video segmentation. Code available at: https://github.com/xmed-lab/GL-Fusion
BNS-Net: A Dual-channel Sarcasm Detection Method Considering Behavior-level and Sentence-level Conflicts
Sep 07, 2023



Sarcasm detection is a binary classification task that aims to determine whether a given utterance is sarcastic. Over the past decade, sarcasm detection has evolved from classical pattern recognition to deep learning approaches, where features such as user profile, punctuation and sentiment words have been commonly employed for sarcasm detection. In real-life sarcastic expressions, behaviors without explicit sentimental cues often serve as carriers of implicit sentimental meanings. Motivated by this observation, we proposed a dual-channel sarcasm detection model named BNS-Net. The model considers behavior and sentence conflicts in two channels. Channel 1: Behavior-level Conflict Channel reconstructs the text based on core verbs while leveraging the modified attention mechanism to highlight conflict information. Channel 2: Sentence-level Conflict Channel introduces external sentiment knowledge to segment the text into explicit and implicit sentences, capturing conflicts between them. To validate the effectiveness of BNS-Net, several comparative and ablation experiments are conducted on three public sarcasm datasets. The analysis and evaluation of experimental results demonstrate that the BNS-Net effectively identifies sarcasm in text and achieves the state-of-the-art performance.
How to Efficiently Adapt Large Segmentation Model(SAM) to Medical Images
Jun 23, 2023



The emerging scale segmentation model, Segment Anything (SAM), exhibits impressive capabilities in zero-shot segmentation for natural images. However, when applied to medical images, SAM suffers from noticeable performance drop. To make SAM a real ``foundation model" for the computer vision community, it is critical to find an efficient way to customize SAM for medical image dataset. In this work, we propose to freeze SAM encoder and finetune a lightweight task-specific prediction head, as most of weights in SAM are contributed by the encoder. In addition, SAM is a promptable model, while prompt is not necessarily available in all application cases, and precise prompts for multiple class segmentation are also time-consuming. Therefore, we explore three types of prompt-free prediction heads in this work, include ViT, CNN, and linear layers. For ViT head, we remove the prompt tokens in the mask decoder of SAM, which is named AutoSAM. AutoSAM can also generate masks for different classes with one single inference after modification. To evaluate the label-efficiency of our finetuning method, we compare the results of these three prediction heads on a public medical image segmentation dataset with limited labeled data. Experiments demonstrate that finetuning SAM significantly improves its performance on medical image dataset, even with just one labeled volume. Moreover, AutoSAM and CNN prediction head also has better segmentation accuracy than training from scratch and self-supervised learning approaches when there is a shortage of annotations.
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023


This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.
TinyML Design Contest for Life-Threatening Ventricular Arrhythmia Detection
May 23, 2023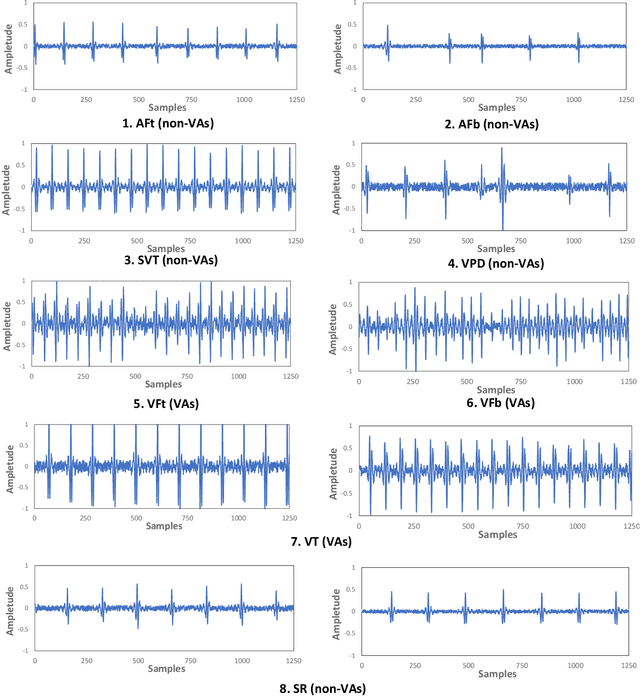

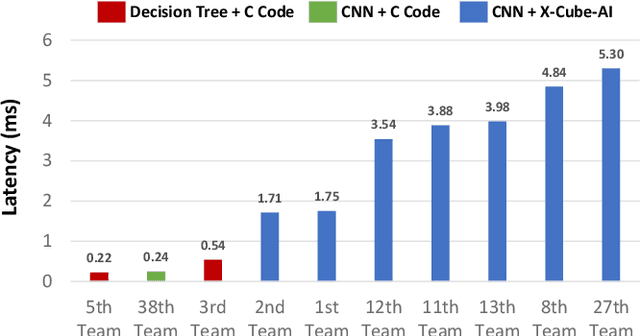
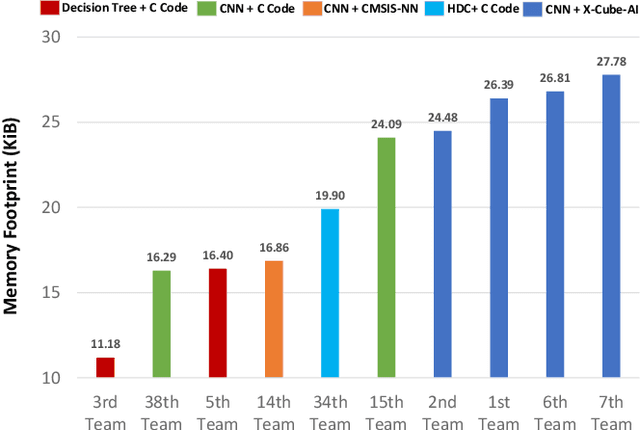
The first ACM/IEEE TinyML Design Contest (TDC) held at the 41st International Conference on Computer-Aided Design (ICCAD) in 2022 is a challenging, multi-month, research and development competition. TDC'22 focuses on real-world medical problems that require the innovation and implementation of artificial intelligence/machine learning (AI/ML) algorithms on implantable devices. The challenge problem of TDC'22 is to develop a novel AI/ML-based real-time detection algorithm for life-threatening ventricular arrhythmia over low-power microcontrollers utilized in Implantable Cardioverter-Defibrillators (ICDs). The dataset contains more than 38,000 5-second intracardiac electrograms (IEGMs) segments over 8 different types of rhythm from 90 subjects. The dedicated hardware platform is NUCLEO-L432KC manufactured by STMicroelectronics. TDC'22, which is open to multi-person teams world-wide, attracted more than 150 teams from over 50 organizations. This paper first presents the medical problem, dataset, and evaluation procedure in detail. It further demonstrates and discusses the designs developed by the leading teams as well as representative results. This paper concludes with the direction of improvement for the future TinyML design for health monitoring applications.
SATBA: An Invisible Backdoor Attack Based On Spatial Attention
Feb 25, 2023



As a new realm of AI security, backdoor attack has drew growing attention research in recent years. It is well known that backdoor can be injected in a DNN model through the process of model training with poisoned dataset which is consist of poisoned sample. The injected model output correct prediction on benign samples yet behave abnormally on poisoned samples included trigger pattern. Most existing trigger of poisoned sample are visible and can be easily found by human visual inspection, and the trigger injection process will cause the feature loss of natural sample and trigger. To solve the above problems and inspire by spatial attention mechanism, we introduce a novel backdoor attack named SATBA, which is invisible and can minimize the loss of trigger to improve attack success rate and model accuracy. It extracts data features and generate trigger pattern related to clean data through spatial attention, poisons clean image by using a U-type models to plant a trigger into the original data. We demonstrate the effectiveness of our attack against three popular image classification DNNs on three standard datasets. Besides, we conduct extensive experiments about image similarity to show that our proposed attack can provide practical stealthiness which is critical to resist to backdoor defense.
ImageCAS: A Large-Scale Dataset and Benchmark for Coronary Artery Segmentation based on Computed Tomography Angiography Images
Nov 03, 2022Cardiovascular disease (CVD) accounts for about half of non-communicable diseases. Vessel stenosis in the coronary artery is considered to be the major risk of CVD. Computed tomography angiography (CTA) is one of the widely used noninvasive imaging modalities in coronary artery diagnosis due to its superior image resolution. Clinically, segmentation of coronary arteries is essential for the diagnosis and quantification of coronary artery disease. Recently, a variety of works have been proposed to address this problem. However, on one hand, most works rely on in-house datasets, and only a few works published their datasets to the public which only contain tens of images. On the other hand, their source code have not been published, and most follow-up works have not made comparison with existing works, which makes it difficult to judge the effectiveness of the methods and hinders the further exploration of this challenging yet critical problem in the community. In this paper, we propose a large-scale dataset for coronary artery segmentation on CTA images. In addition, we have implemented a benchmark in which we have tried our best to implement several typical existing methods. Furthermore, we propose a strong baseline method which combines multi-scale patch fusion and two-stage processing to extract the details of vessels. Comprehensive experiments show that the proposed method achieves better performance than existing works on the proposed large-scale dataset. The benchmark and the dataset are published at https://github.com/XiaoweiXu/ImageCAS-A-Large-Scale-Dataset-and-Benchmark-for-Coronary-Artery-Segmentation-based-on-CT.
Unsupervised Knowledge Graph Construction and Event-centric Knowledge Infusion for Scientific NLI
Oct 28, 2022



With the advance of natural language inference (NLI), a rising demand for NLI is to handle scientific texts. Existing methods depend on pre-trained models (PTM) which lack domain-specific knowledge. To tackle this drawback, we introduce a scientific knowledge graph to generalize PTM to scientific domain. However, existing knowledge graph construction approaches suffer from some drawbacks, i.e., expensive labeled data, failure to apply in other domains, long inference time and difficulty extending to large corpora. Therefore, we propose an unsupervised knowledge graph construction method to build a scientific knowledge graph (SKG) without any labeled data. Moreover, to alleviate noise effect from SKG and complement knowledge in sentences better, we propose an event-centric knowledge infusion method to integrate external knowledge into each event that is a fine-grained semantic unit in sentences. Experimental results show that our method achieves state-of-the-art performance and the effectiveness and reliability of SKG.
Sub-cluster-aware Network for Few-shot Skin Disease Classification
Jul 03, 2022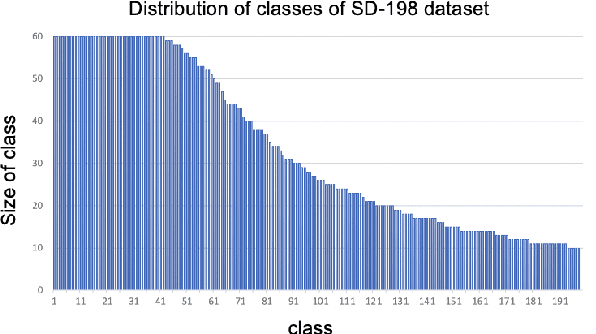
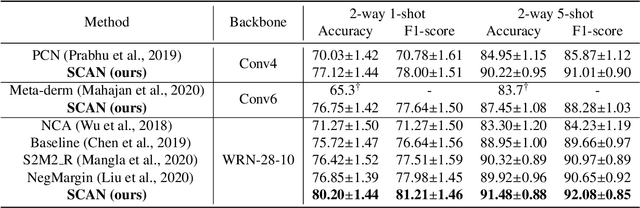
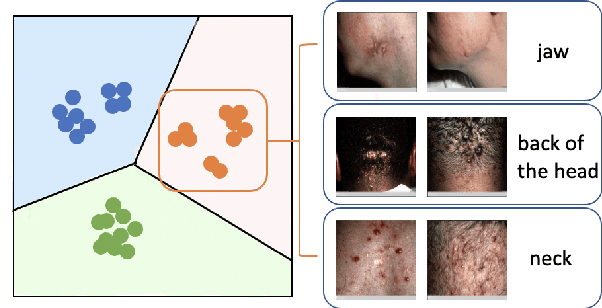
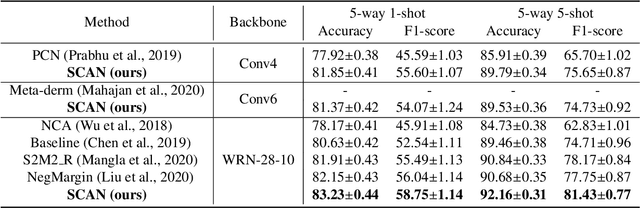
This paper studies the few-shot skin disease classification problem. Based on a crucial observation that skin disease images often exist multiple sub-clusters within a class (i.e., the appearances of images within one class of disease vary and form multiple distinct sub-groups), we design a novel Sub-Cluster-Aware Network, namely SCAN, for rare skin disease diagnosis with enhanced accuracy. As the performance of few-shot learning highly depends on the quality of the learned feature encoder, the main principle guiding the design of SCAN is the intrinsic sub-clustered representation learning for each class so as to better describe feature distributions. Specifically, SCAN follows a dual-branch framework, where the first branch is to learn class-wise features to distinguish different skin diseases, and the second one aims to learn features which can effectively partition each class into several groups so as to preserve the sub-clustered structure within each class. To achieve the objective of the second branch, we present a cluster loss to learn image similarities via unsupervised clustering. To ensure that the samples in each sub-cluster are from the same class, we further design a purity loss to refine the unsupervised clustering results. We evaluate the proposed approach on two public datasets for few-shot skin disease classification. The experimental results validate that our framework outperforms the other state-of-the-art methods by around 2% to 4% on the SD-198 and Derm7pt datasets.