 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Object Detection in Complex Backgrounds with Multi-Scale Attention and Global Relation Modeling
Mar 04, 2026Small object detection under complex backgrounds remains a challenging task due to severe feature degradation, weak semantic representation, and inaccurate localization caused by downsampling operations and background interference. Existing detection frameworks are mainly designed for general objects and often fail to explicitly address the unique characteristics of small objects, such as limited structural cues and strong sensitivity to localization errors. In this paper, we propose a multi-level feature enhancement and global relation modeling framework tailored for small object detection. Specifically, a Residual Haar Wavelet Downsampling module is introduced to preserve fine-grained structural details by jointly exploiting spatial-domain convolutional features and frequency-domain representations. To enhance global semantic awareness and suppress background noise, a Global Relation Modeling module is employed to capture long-range dependencies at high-level feature stages. Furthermore, a Cross-Scale Hybrid Attention module is designed to establish sparse and aligned interactions across multi-scale features, enabling effective fusion of high-resolution details and high-level semantic information with reduced computational overhead. Finally, a Center-Assisted Loss is incorporated to stabilize training and improve localization accuracy for small objects. Extensive experiments conducted on the large-scale RGBT-Tiny benchmark demonstrate that the proposed method consistently outperforms existing state-of-the-art detectors under both IoU-based and scale-adaptive evaluation metrics. These results validate the effectiveness and robustness of the proposed framework for small object detection in complex environments.
Gem5Pred: Predictive Approaches For Gem5 Simulation Time
Oct 10, 2023Gem5, an open-source, flexible, and cost-effective simulator, is widely recognized and utilized in both academic and industry fields for hardware simulation. However, the typically time-consuming nature of simulating programs on Gem5 underscores the need for a predictive model that can estimate simulation time. As of now, no such dataset or model exists. In response to this gap, this paper makes a novel contribution by introducing a unique dataset specifically created for this purpose. We also conducted analysis of the effects of different instruction types on the simulation time in Gem5. After this, we employ three distinct models leveraging CodeBERT to execute the prediction task based on the developed dataset. Our superior regression model achieves a Mean Absolute Error (MAE) of 0.546, while our top-performing classification model records an Accuracy of 0.696. Our models establish a foundation for future investigations on this topic, serving as benchmarks against which subsequent models can be compared. We hope that our contribution can simulate further research in this field. The dataset we used is available at https://github.com/XueyangLiOSU/Gem5Pred.
Has Sentiment Returned to the Pre-pandemic Level? A Sentiment Analysis Using U.S. College Subreddit Data from 2019 to 2022
Sep 16, 2023



As impact of COVID-19 pandemic winds down, both individuals and society gradually return to pre-pandemic activities. This study aims to explore how people's emotions have changed from the pre-pandemic during the pandemic to post-emergency period and whether it has returned to pre-pandemic level. We collected Reddit data in 2019 (pre-pandemic), 2020 (peak pandemic), 2021, and 2022 (late stages of pandemic, transitioning period to post-emergency period) from subreddits in 128 universities/colleges in the U.S., and a set of school-level characteristics. We predicted two sets of sentiments from a pre-trained Robustly Optimized BERT pre-training approach (RoBERTa) and graph attention network (GAT) that leverages both rich semantic and relational information among posted messages and then applied a logistic stacking method to obtain the final sentiment classification. After obtaining sentiment label for each message, we used a generalized linear mixed-effects model to estimate temporal trend in sentiment from 2019 to 2022 and how school-level factors may affect sentiment. Compared to the year 2019, the odds of negative sentiment in years 2020, 2021, and 2022 are 24%, 4.3%, and 10.3% higher, respectively, which are all statistically significant(adjusted $p$<0.05). Our study findings suggest a partial recovery in the sentiment composition in the post-pandemic-emergency era. The results align with common expectations and provide a detailed quantification of how sentiments have evolved from 2019 to 2022.
Noise-Augmented $\ell_0$ Regularization of Tensor Regression with Tucker Decomposition
Feb 19, 2023



Tensor data are multi-dimension arrays. Low-rank decomposition-based regression methods with tensor predictors exploit the structural information in tensor predictors while significantly reducing the number of parameters in tensor regression. We propose a method named NA$_0$CT$^2$ (Noise Augmentation for $\ell_0$ regularization on Core Tensor in Tucker decomposition) to regularize the parameters in tensor regression (TR), coupled with Tucker decomposition. We establish theoretically that NA$_0$CT$^2$ achieves exact $\ell_0$ regularization in linear TR and generalized linear TR on the core tensor from the Tucker decomposition. To our knowledge, NA$_0$CT$^2$ is the first Tucker decomposition-based regularization method in TR to achieve $\ell_0$ in core tensor. NA$_0$CT$^2$ is implemented through an iterative procedure and involves two simple steps in each iteration -- generating noisy data based on the core tensor from the Tucker decomposition of the updated parameter estimate and running a regular GLM on noise-augmented data on vectorized predictors. We demonstrate the implementation of NA$_0$CT$^2$ and its $\ell_0$ regularization effect in both simulation studies and real data applications. The results suggest that NA$_0$CT$^2$ improves predictions compared to other decomposition-based TR approaches, with or without regularization and it also helps to identify important predictors though not designed for that purpose.
Sentiment Analysis and Effect of COVID-19 Pandemic using College SubReddit Data
Nov 30, 2021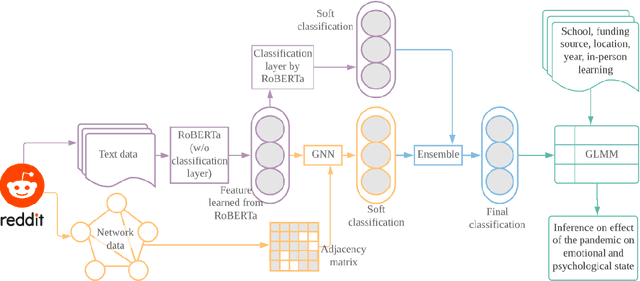
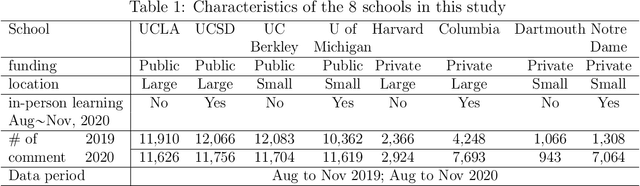
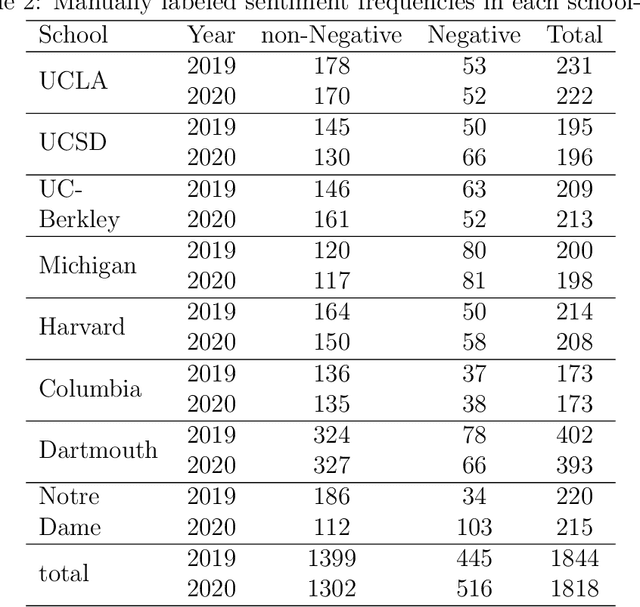
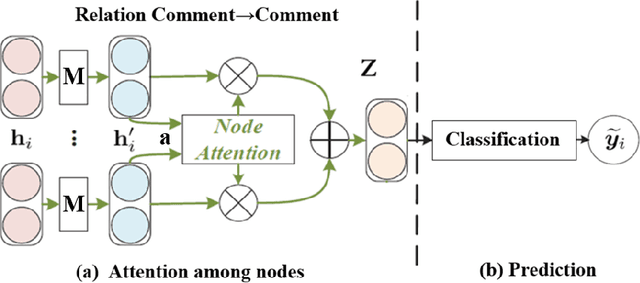
The COVID-19 pandemic has affected societies and human health and well-being in various ways. In this study, we collected Reddit data from 2019 (pre-pandemic) and 2020 (pandemic) from the subreddits communities associated with 8 universities, applied natural language processing (NLP) techniques, and trained graphical neural networks with social media data, to study how the pandemic has affected people's emotions and psychological states compared to the pre-pandemic era. Specifically, we first applied a pre-trained Robustly Optimized BERT pre-training approach (RoBERTa) to learn embedding from the semantic information of Reddit messages and trained a graph attention network (GAT) for sentiment classification. The usage of GAT allows us to leverage the relational information among the messages during training. We then applied subgroup-adaptive model stacking to combine the prediction probabilities from RoBERTa and GAT to yield the final classification on sentiment. With the manually labeled and model-predicted sentiment labels on the collected data, we applied a generalized linear mixed-effects model to estimate the effects of pandemic and online teaching on people's sentiment in a statistically significant manner. The results suggest the odds of negative sentiments in 2020 is $14.6\%$ higher than the odds in 2019 ($p$-value $<0.001$), and the odds of negative sentiments are $41.6\%$ higher with in-person teaching than with online teaching in 2020 ($p$-value $=0.037$) in the studied population.