 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECAD-Net: Self-Supervised CAD Reconstruction by Learning Sketch-Extrude Operations
Mar 19, 2023

Reverse engineering CAD models from raw geometry is a classic but strenuous research problem. Previous learning-based methods rely heavily on labels due to the supervised design patterns or reconstruct CAD shapes that are not easily editable. In this work, we introduce SECAD-Net, an end-to-end neural network aimed at reconstructing compact and easy-to-edit CAD models in a self-supervised manner. Drawing inspiration from the modeling language that is most commonly used in modern CAD software, we propose to learn 2D sketches and 3D extrusion parameters from raw shapes, from which a set of extrusion cylinders can be generated by extruding each sketch from a 2D plane into a 3D body. By incorporating the Boolean operation (i.e., union), these cylinders can be combined to closely approximate the target geometry. We advocate the use of implicit fields for sketch representation, which allows for creating CAD variations by interpolating latent codes in the sketch latent space. Extensive experiments on both ABC and Fusion 360 datasets demonstrate the effectiveness of our method, and show superiority over state-of-the-art alternatives including the closely related method for supervised CAD reconstruction. We further apply our approach to CAD editing and single-view CAD reconstruction. The code is released at https://github.com/BunnySoCrazy/SECAD-Net.
Rethinking Visual Prompt Learning as Masked Visual Token Modeling
Mar 09, 2023Prompt learning has achieved great success in efficiently exploiting large-scale pre-trained models in natural language processing (NLP). It reformulates the downstream tasks as the generative pre-training ones, thus narrowing down the gap between them and improving the performance stably. However, when transferring it to the vision area, current visual prompt learning methods are all designed on discriminative pre-trained models, and there is also a lack of careful design to unify the forms of pre-training and downstream tasks. To explore prompt learning on the generative pre-trained visual model as well as keeping the task consistency, we propose Visual Prompt learning as masked visual Token Modeling (VPTM) to transform the downstream visual classification into the pre-trained masked visual token prediction. In addition, we develop the prototypical verbalizer for mapping the predicted visual token with implicit semantics to explicit downstream labels. To our best knowledge, VPTM is the first visual prompt method on the generative pre-trained visual model, and the first to achieve consistency between pre-training and downstream visual classification by task reformulation. Experiments show that VPTM outperforms other visual prompt methods and achieves excellent efficiency. Moreover, the task consistency of VPTM contributes to the robustness against prompt location, prompt length and prototype dimension, and could be deployed uniformly.
R-Tuning: Regularized Prompt Tuning in Open-Set Scenarios
Mar 09, 2023



In realistic open-set scenarios where labels of a part of testing data are totally unknown, current prompt methods on vision-language (VL) models always predict the unknown classes as the downstream training classes. The exhibited label bias causes difficulty in the open set recognition (OSR), by which an image should be correctly predicted as one of the known classes or the unknown one. To learn prompts in open-set scenarios, we propose the Regularized prompt Tuning (R-Tuning) to mitigate the label bias. It introduces open words from the WordNet to extend the range of words forming the prompt texts from only closed-set label words to more. Thus, prompts are tuned in a simulated open-set scenario. Besides, inspired by the observation that classifying directly on large datasets causes a much higher false positive rate than on small datasets, we propose the Combinatorial Tuning and Testing (CTT) strategy for improving performance. CTT decomposes R-Tuning on large datasets as multiple independent group-wise tuning on fewer classes, then makes comprehensive predictions by selecting the optimal sub-prompt. For fair comparisons, we construct new baselines for OSR based on VL models, especially for prompt methods. Our method achieves the best results on datasets with various scales. Extensive ablation studies validate the effectiveness of our method.
Self Correspondence Distillation for End-to-End Weakly-Supervised Semantic Segmentation
Feb 27, 2023



Efficiently training accurate deep models for weakly supervised semantic segmentation (WSSS) with image-level labels is challenging and important. Recently, end-to-end WSSS methods have become the focus of research due to their high training efficiency. However, current methods suffer from insufficient extraction of comprehensive semantic information, resulting in low-quality pseudo-labels and sub-optimal solutions for end-to-end WSSS. To this end, we propose a simple and novel Self Correspondence Distillation (SCD) method to refine pseudo-labels without introducing external supervision. Our SCD enables the network to utilize feature correspondence derived from itself as a distillation target, which can enhance the network's feature learning process by complementing semantic information. In addition, to further improve the segmentation accuracy, we design a Variation-aware Refine Module to enhance the local consistency of pseudo-labels by computing pixel-level variation. Finally, we present an efficient end-to-end Transformer-based framework (TSCD) via SCD and Variation-aware Refine Module for the accurate WSSS task. Extensive experiments on the PASCAL VOC 2012 and MS COCO 2014 datasets demonstrate that our method significantly outperforms other state-of-the-art methods. Our code is available at {https://github.com/Rongtao-Xu/RepresentationLearning/tree/main/SCD-AAAI2023}.
Feature Calibration Network for Occluded Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially for scenes containing serious occlusion. In this paper, we propose a novel feature learning method in the deep learning framework, referred to as Feature Calibration Network (FC-Net), to adaptively detect pedestrians under various occlusions. FC-Net is based on the observation that the visible parts of pedestrians are selective and decisive for detection, and is implemented as a self-paced feature learning framework with a self-activation (SA) module and a feature calibration (FC) module. In a new self-activated manner, FC-Net learns features which highlight the visible parts and suppress the occluded parts of pedestrians. The SA module estimates pedestrian activation maps by reusing classifier weights, without any additional parameter involved, therefore resulting in an extremely parsimony model to reinforce the semantics of features, while the FC module calibrates the convolutional features for adaptive pedestrian representation in both pixel-wise and region-based ways. Experiments on CityPersons and Caltech datasets demonstrate that FC-Net improves detection performance on occluded pedestrians up to 10% while maintaining excellent performance on non-occluded instances.
Integrally Pre-Trained Transformer Pyramid Networks
Nov 23, 2022



In this paper, we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pre-training stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular, the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1x training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead -- all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
Security Closure of IC Layouts Against Hardware Trojans
Nov 15, 2022Due to cost benefits, supply chains of integrated circuits (ICs) are largely outsourced nowadays. However, passing ICs through various third-party providers gives rise to many threats, like piracy of IC intellectual property or insertion of hardware Trojans, i.e., malicious circuit modifications. In this work, we proactively and systematically harden the physical layouts of ICs against post-design insertion of Trojans. Toward that end, we propose a multiplexer-based logic-locking scheme that is (i) devised for layout-level Trojan prevention, (ii) resilient against state-of-the-art, oracle-less machine learning attacks, and (iii) fully integrated into a tailored, yet generic, commercial-grade design flow. Our work provides in-depth security and layout analysis on a challenging benchmark suite. We show that ours can render layouts resilient, with reasonable overheads, against Trojan insertion in general and also against second-order attacks (i.e., adversaries seeking to bypass the locking defense in an oracle-less setting). We release our layout artifacts for independent verification [29] and we will release our methodology's source code.
Motion-inductive Self-supervised Object Discovery in Videos
Oct 01, 2022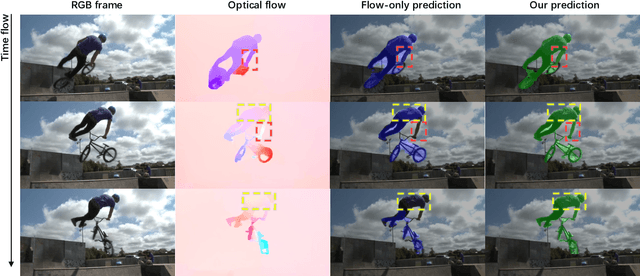
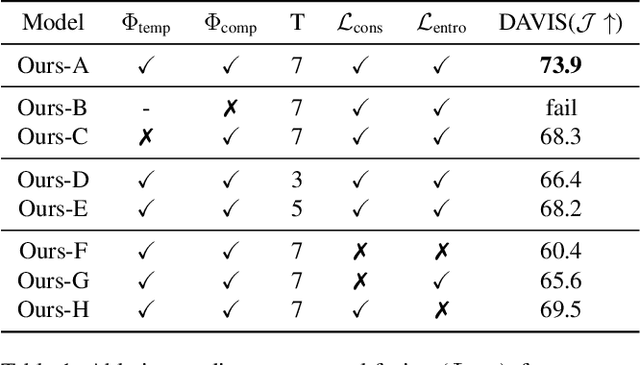
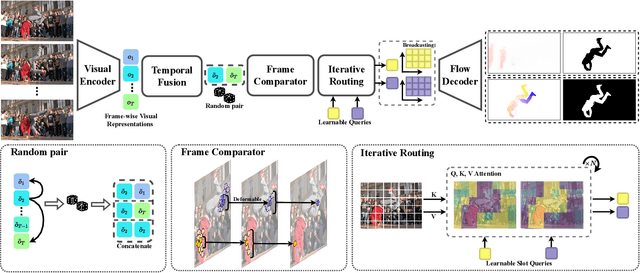
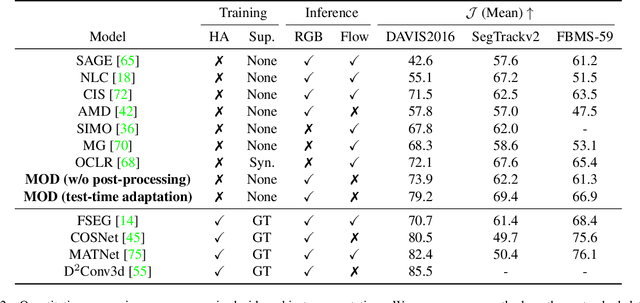
In this paper, we consider the task of unsupervised object discovery in videos. Previous works have shown promising results via processing optical flows to segment objects. However, taking flow as input brings about two drawbacks. First, flow cannot capture sufficient cues when objects remain static or partially occluded. Second, it is challenging to establish temporal coherency from flow-only input, due to the missing texture information. To tackle these limitations, we propose a model for directly processing consecutive RGB frames, and infer the optical flow between any pair of frames using a layered representation, with the opacity channels being treated as the segmentation. Additionally, to enforce object permanence, we apply temporal consistency loss on the inferred masks from randomly-paired frames, which refer to the motions at different paces, and encourage the model to segment the objects even if they may not move at the current time point. Experimentally, we demonstrate superior performance over previous state-of-the-art methods on three public video segmentation datasets (DAVIS2016, SegTrackv2, and FBMS-59), while being computationally efficient by avoiding the overhead of computing optical flow as input.
SdAE: Self-distillated Masked Autoencoder
Jul 31, 2022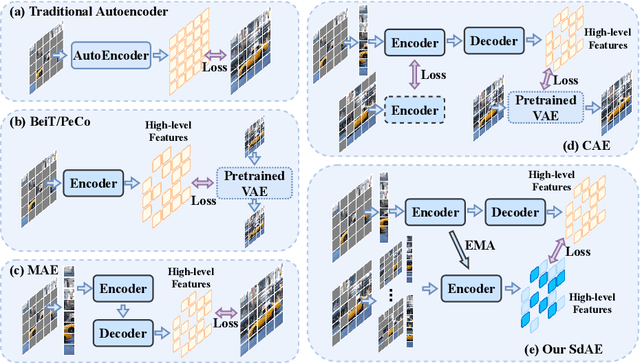

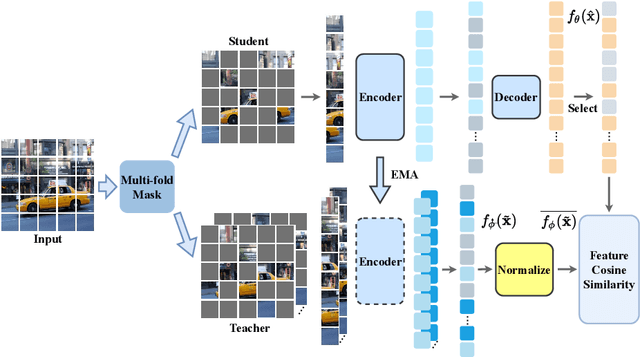
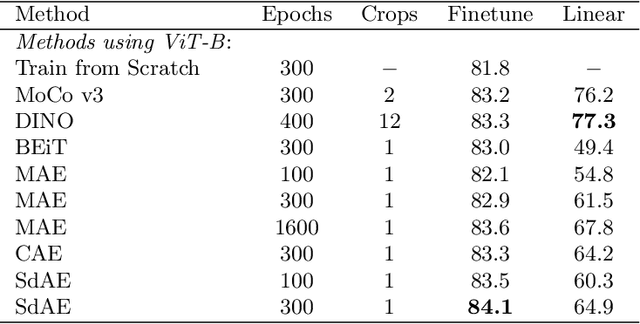
With the development of generative-based self-supervised learning (SSL) approaches like BeiT and MAE, how to learn good representations by masking random patches of the input image and reconstructing the missing information has grown in concern. However, BeiT and PeCo need a "pre-pretraining" stage to produce discrete codebooks for masked patches representing. MAE does not require a pre-training codebook process, but setting pixels as reconstruction targets may introduce an optimization gap between pre-training and downstream tasks that good reconstruction quality may not always lead to the high descriptive capability for the model. Considering the above issues, in this paper, we propose a simple Self-distillated masked AutoEncoder network, namely SdAE. SdAE consists of a student branch using an encoder-decoder structure to reconstruct the missing information, and a teacher branch producing latent representation of masked tokens. We also analyze how to build good views for the teacher branch to produce latent representation from the perspective of information bottleneck. After that, we propose a multi-fold masking strategy to provide multiple masked views with balanced information for boosting the performance, which can also reduce the computational complexity. Our approach generalizes well: with only 300 epochs pre-training, a vanilla ViT-Base model achieves an 84.1% fine-tuning accuracy on ImageNet-1k classification, 48.6 mIOU on ADE20K segmentation, and 48.9 mAP on COCO detection, which surpasses other methods by a considerable margin. Code is available at https://github.com/AbrahamYabo/SdAE.
Visual Recognition by Request
Jul 28, 2022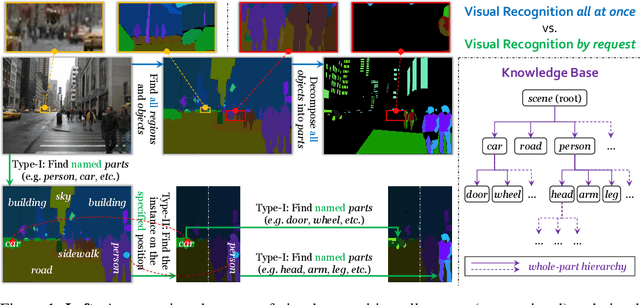
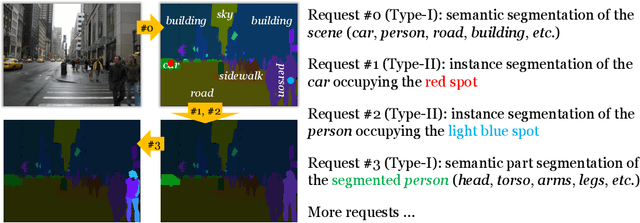

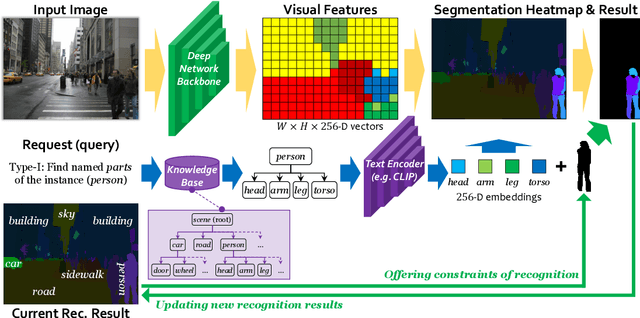
In this paper, we present a novel protocol of annotation and evaluation for visual recognition. Different from traditional settings, the protocol does not require the labeler/algorithm to annotate/recognize all targets (objects, parts, etc.) at once, but instead raises a number of recognition instructions and the algorithm recognizes targets by request. This mechanism brings two beneficial properties to reduce the burden of annotation, namely, (i) variable granularity: different scenarios can have different levels of annotation, in particular, object parts can be labeled only in large and clear instances, (ii) being open-domain: new concepts can be added to the database in minimal costs. To deal with the proposed setting, we maintain a knowledge base and design a query-based visual recognition framework that constructs queries on-the-fly based on the requests. We evaluate the recognition system on two mixed-annotated datasets, CPP and ADE20K, and demonstrate its promising ability of learning from partially labeled data as well as adapting to new concepts with only text labels.