 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWPPG Net: A Non-contact Video Based Heart Rate Extraction Network Framework with Compatible Training Capability
Jul 04, 2022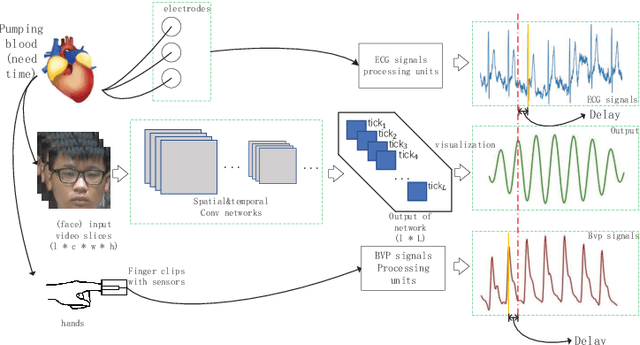
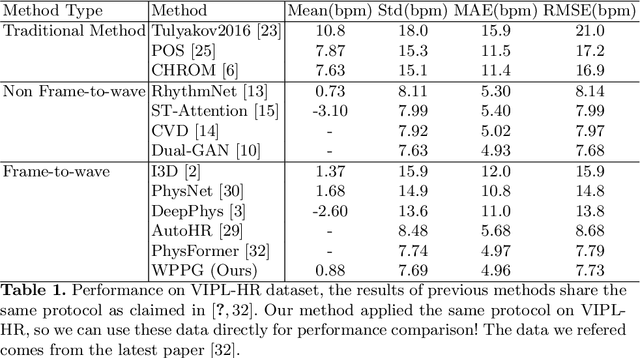
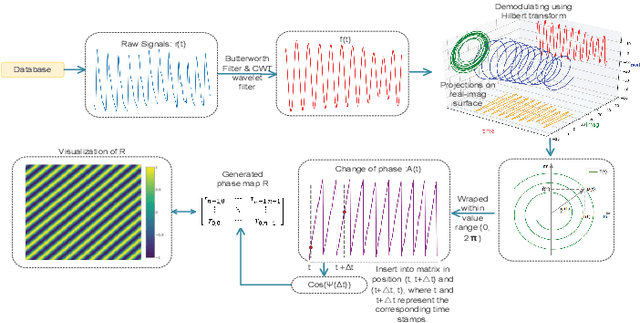
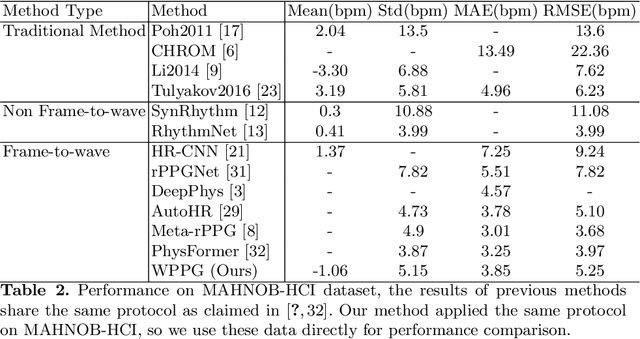
Our facial skin presents subtle color change known as remote Photoplethysmography (rPPG) signal, from which we could extract the heart rate of the subject. Recently many deep learning methods and related datasets on rPPG signal extraction are proposed. However, because of the time consumption blood flowing through our body and other factors, label waves such as BVP signals have uncertain delays with real rPPG signals in some datasets, which results in the difficulty on training of networks which output predicted rPPG waves directly. In this paper, by analyzing the common characteristics on rhythm and periodicity of rPPG signals and label waves, we propose a whole set of training methodology which wraps these networks so that they could remain efficient when be trained at the presence of frequent uncertain delay in datasets and gain more precise and robust heart rate prediction results than other delay-free rPPG extraction methods.
Piecewise Linear Neural Networks and Deep Learning
Jun 18, 2022As a powerful modelling method, PieceWise Linear Neural Networks (PWLNNs) have proven successful in various fields, most recently in deep learning. To apply PWLNN methods, both the representation and the learning have long been studied. In 1977, the canonical representation pioneered the works of shallow PWLNNs learned by incremental designs, but the applications to large-scale data were prohibited. In 2010, the Rectified Linear Unit (ReLU) advocated the prevalence of PWLNNs in deep learning. Ever since, PWLNNs have been successfully applied to extensive tasks and achieved advantageous performances. In this Primer, we systematically introduce the methodology of PWLNNs by grouping the works into shallow and deep networks. Firstly, different PWLNN representation models are constructed with elaborated examples. With PWLNNs, the evolution of learning algorithms for data is presented and fundamental theoretical analysis follows up for in-depth understandings. Then, representative applications are introduced together with discussions and outlooks.
Trainable Weight Averaging for Fast Convergence and Better Generalization
May 26, 2022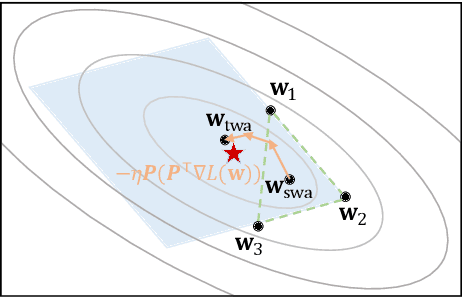
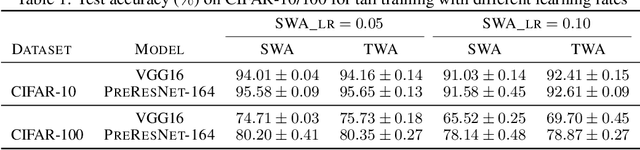
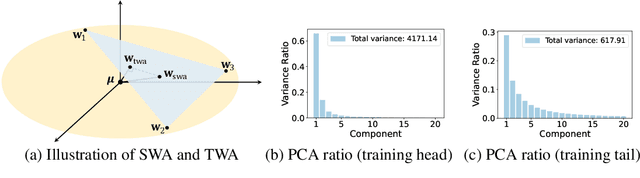
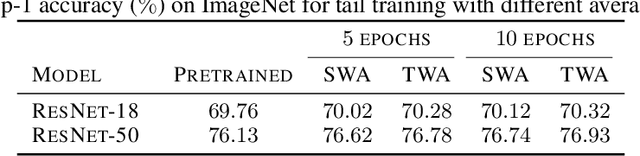
Stochastic gradient descent (SGD) and its variants are commonly considered as the de-facto methods to train deep neural networks (DNNs). While recent improvements to SGD mainly focus on the descent algorithm itself, few works pay attention to utilizing the historical solutions -- as an iterative method, SGD has actually gone through substantial explorations before its final convergence. Recently, an interesting attempt is stochastic weight averaging (SWA), which significantly improves the generalization by simply averaging the solutions at the tail stage of training. In this paper, we propose to optimize the averaging coefficients, leading to our Trainable Weight Averaging (TWA), essentially a novel training method in a reduced subspace spanned by historical solutions. TWA is quite efficient and has good generalization capability as the degree of freedom for training is small. It largely reduces the estimation error from SWA, making it not only further improve the SWA solutions but also take full advantage of the solutions generated in the head of training where SWA fails. In the extensive numerical experiments, (i) TWA achieves consistent improvements over SWA with less sensitivity to learning rate; (ii) applying TWA in the head stage of training largely speeds up the convergence, resulting in over 40% time saving on CIFAR and 30% on ImageNet with improved generalization compared with regular training. The code is released at https://github.com/nblt/TWA.
One-Pixel Shortcut: on the Learning Preference of Deep Neural Networks
May 24, 2022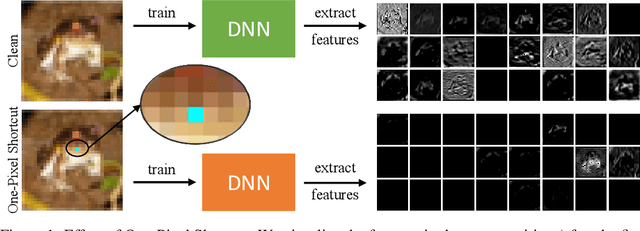
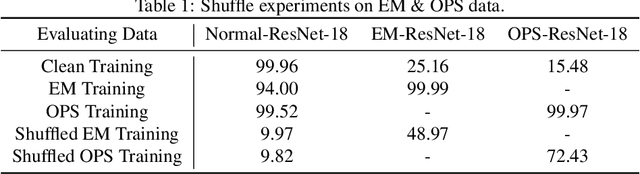
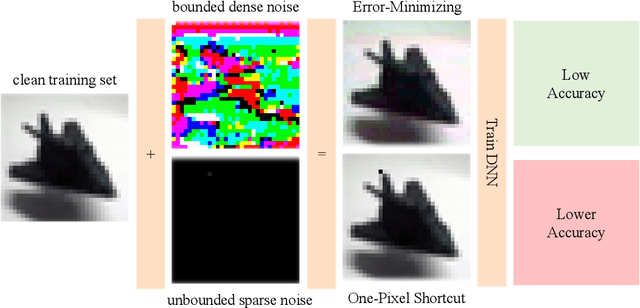
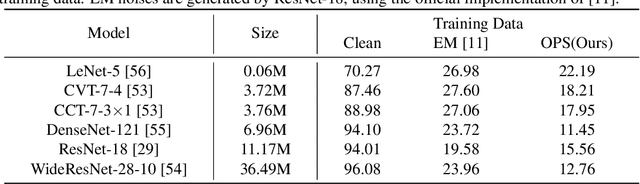
Unlearnable examples (ULEs) aim to protect data from unauthorized usage for training DNNs. Error-minimizing noise, which is injected to clean data, is one of the most successful methods for preventing DNNs from giving correct predictions on incoming new data. Nonetheless, under specific training strategies such as adversarial training, the unlearnability of error-minimizing noise will severely degrade. In addition, the transferability of error-minimizing noise is inherently limited by the mismatch between the generator model and the targeted learner model. In this paper, we investigate the mechanism of unlearnable examples and propose a novel model-free method, named \emph{One-Pixel Shortcut}, which only perturbs a single pixel of each image and makes the dataset unlearnable. Our method needs much less computational cost and obtains stronger transferability and thus can protect data from a wide range of different models. Based on this, we further introduce the first unlearnable dataset called CIFAR-10-S, which is indistinguishable from normal CIFAR-10 by human observers and can serve as a benchmark for different models or training strategies to evaluate their abilities to extract critical features from the disturbance of non-semantic representations. The original error-minimizing ULEs will lose efficiency under adversarial training, where the model can get over 83\% clean test accuracy. Meanwhile, even if adversarial training and strong data augmentation like RandAugment are applied together, the model trained on CIFAR-10-S cannot get over 50\% clean test accuracy.
Adversarial Attack on Attackers: Post-Process to Mitigate Black-Box Score-Based Query Attacks
May 24, 2022
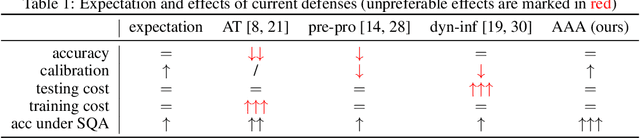

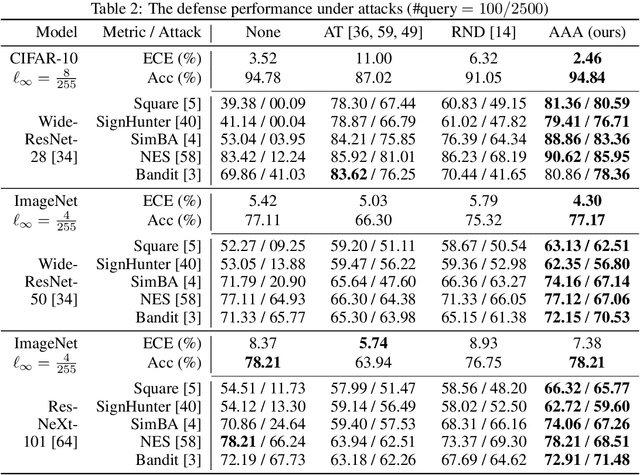
The score-based query attacks (SQAs) pose practical threats to deep neural networks by crafting adversarial perturbations within dozens of queries, only using the model's output scores. Nonetheless, we note that if the loss trend of the outputs is slightly perturbed, SQAs could be easily misled and thereby become much less effective. Following this idea, we propose a novel defense, namely Adversarial Attack on Attackers (AAA), to confound SQAs towards incorrect attack directions by slightly modifying the output logits. In this way, (1) SQAs are prevented regardless of the model's worst-case robustness; (2) the original model predictions are hardly changed, i.e., no degradation on clean accuracy; (3) the calibration of confidence scores can be improved simultaneously. Extensive experiments are provided to verify the above advantages. For example, by setting $\ell_\infty=8/255$ on CIFAR-10, our proposed AAA helps WideResNet-28 secure $80.59\%$ accuracy under Square attack ($2500$ queries), while the best prior defense (i.e., adversarial training) only attains $67.44\%$. Since AAA attacks SQA's general greedy strategy, such advantages of AAA over 8 defenses can be consistently observed on 8 CIFAR-10/ImageNet models under 6 SQAs, using different attack targets and bounds. Moreover, AAA calibrates better without hurting the accuracy. Our code would be released.
Learning with Asymmetric Kernels: Least Squares and Feature Interpretation
Feb 03, 2022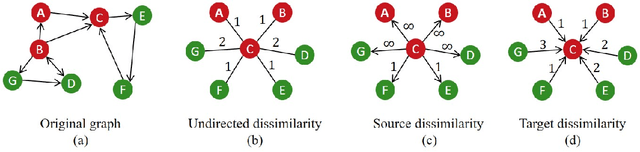
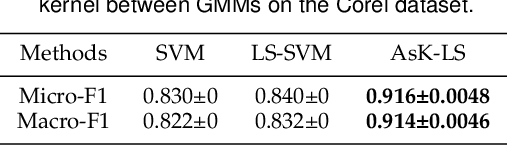
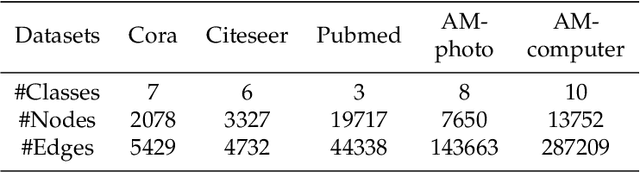
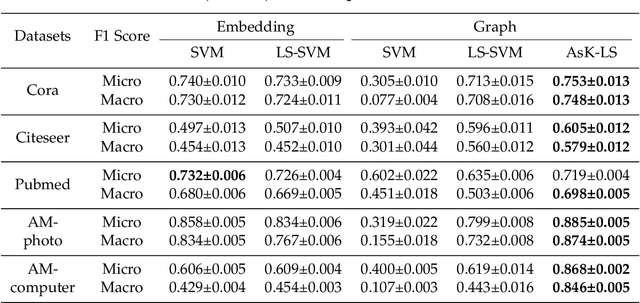
Asymmetric kernels naturally exist in real life, e.g., for conditional probability and directed graphs. However, most of the existing kernel-based learning methods require kernels to be symmetric, which prevents the use of asymmetric kernels. This paper addresses the asymmetric kernel-based learning in the framework of the least squares support vector machine named AsK-LS, resulting in the first classification method that can utilize asymmetric kernels directly. We will show that AsK-LS can learn with asymmetric features, namely source and target features, while the kernel trick remains applicable, i.e., the source and target features exist but are not necessarily known. Besides, the computational burden of AsK-LS is as cheap as dealing with symmetric kernels. Experimental results on the Corel database, directed graphs, and the UCI database will show that in the case asymmetric information is crucial, the proposed AsK-LS can learn with asymmetric kernels and performs much better than the existing kernel methods that have to do symmetrization to accommodate asymmetric kernels.
Subspace Adversarial Training
Nov 24, 2021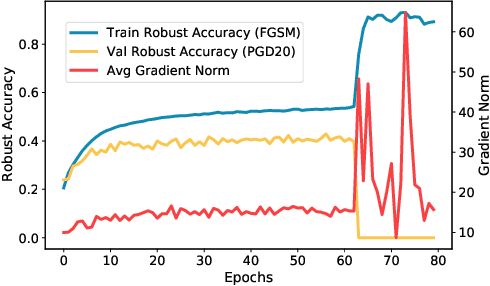
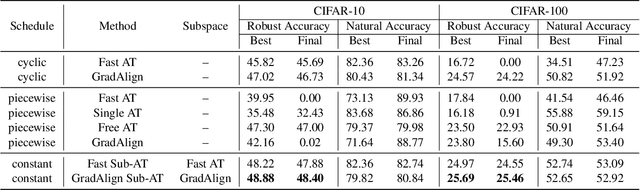
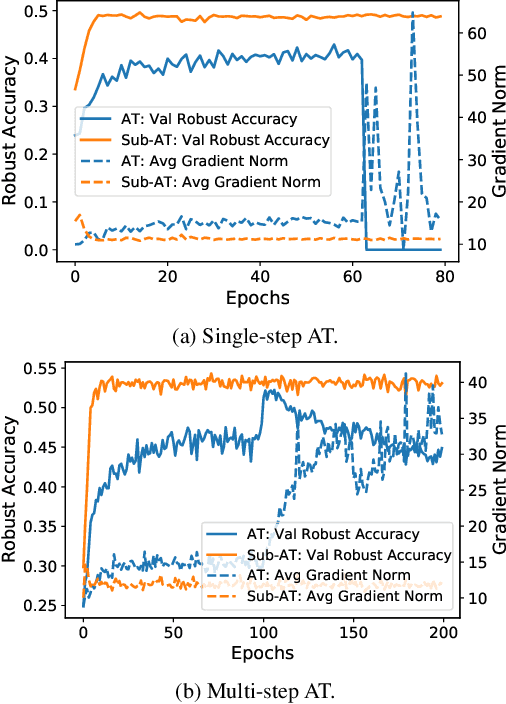
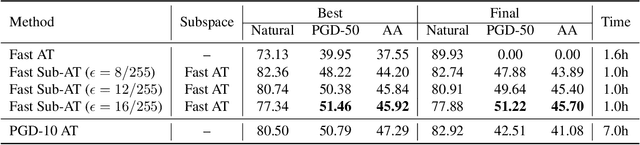
Single-step adversarial training (AT) has received wide attention as it proved to be both efficient and robust. However, a serious problem of catastrophic overfitting exists, i.e., the robust accuracy against projected gradient descent (PGD) attack suddenly drops to $0\%$ during the training. In this paper, we understand this problem from a novel perspective of optimization and firstly reveal the close link between the fast-growing gradient of each sample and overfitting, which can also be applied to understand the robust overfitting phenomenon in multi-step AT. To control the growth of the gradient during the training, we propose a new AT method, subspace adversarial training (Sub-AT), which constrains the AT in a carefully extracted subspace. It successfully resolves both two kinds of overfitting and hence significantly boosts the robustness. In subspace, we also allow single-step AT with larger steps and larger radius, which further improves the robustness performance. As a result, we achieve the state-of-the-art single-step AT performance: our pure single-step AT can reach over $\mathbf{51}\%$ robust accuracy against strong PGD-50 attack with radius $8/255$ on CIFAR-10, even surpassing the standard multi-step PGD-10 AT with huge computational advantages. The code is released$\footnote{\url{https://github.com/nblt/Sub-AT}}$.
Semi-tensor Product-based TensorDecomposition for Neural Network Compression
Sep 30, 2021
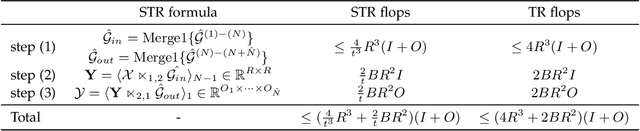
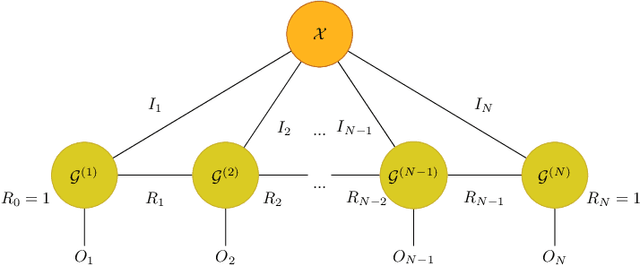

The existing tensor networks adopt conventional matrix product for connection. The classical matrix product requires strict dimensionality consistency between factors, which can result in redundancy in data representation. In this paper, the semi-tensor product is used to generalize classical matrix product-based mode product to semi-tensor mode product. As it permits the connection of two factors with different dimensionality, more flexible and compact tensor decompositions can be obtained with smaller sizes of factors. Tucker decomposition, Tensor Train (TT) and Tensor Ring (TR) are common decomposition for low rank compression of deep neural networks. The semi-tensor product is applied to these tensor decompositions to obtained their generalized versions, i.e., semi-tensor Tucker decomposition (STTu), semi-tensor train(STT) and semi-tensor ring (STR). Experimental results show the STTu, STT and STR achieve higher compression factors than the conventional tensor decompositions with the same accuracy but less training times in ResNet and WideResNetcompression. With 2% accuracy degradation, the TT-RN (rank = 14) and the TR-WRN (rank = 16) only obtain 3 times and99t times compression factors while the STT-RN (rank = 14) and the STR-WRN (rank = 16) achieve 9 times and 179 times compression factors, respectively.
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Aug 04, 2021
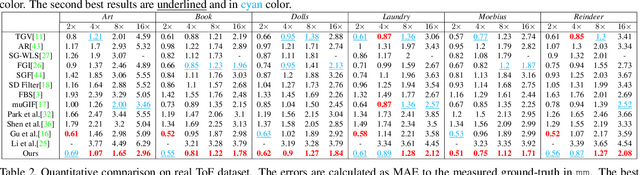
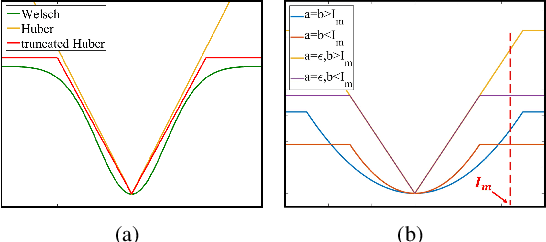

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, we first introduce the truncated Huber penalty function which shows strong flexibility under different parameter settings. A generalized framework is then proposed with the introduced truncated Huber penalty function. When combined with its strong flexibility, our framework is able to achieve diverse smoothing natures where contradictive smoothing behaviors can even be achieved. It can also yield the smoothing behavior that can seldom be achieved by previous methods, and superior performance is thus achieved in challenging cases. These together enable our framework capable of a range of applications and able to outperform the state-of-the-art approaches in several tasks, such as image detail enhancement, clip-art compression artifacts removal, guided depth map restoration, image texture removal, etc. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. A simple yet effective approach is further proposed to reduce the computational cost of our method while maintaining its performance. The effectiveness and superior performance of our approach are validated through comprehensive experiments in a range of applications. Our code is available at https://github.com/wliusjtu/Generalized-Smoothing-Framework.
Adaptive Feature Alignment for Adversarial Training
Jun 16, 2021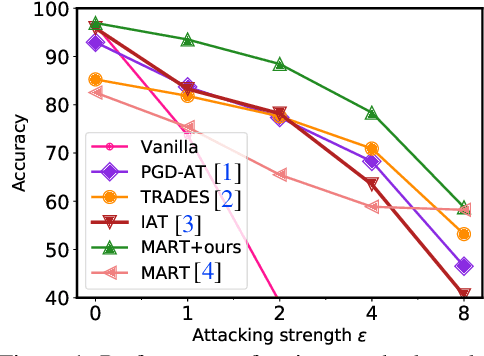
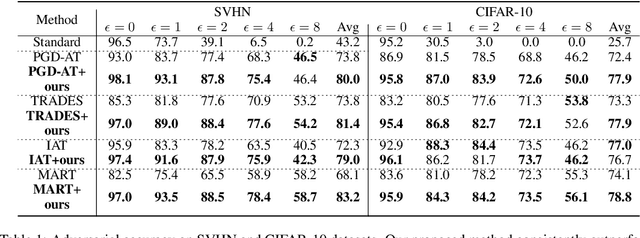
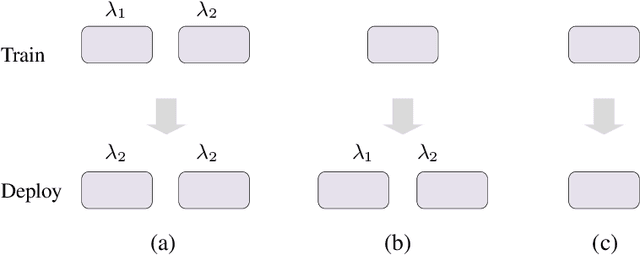
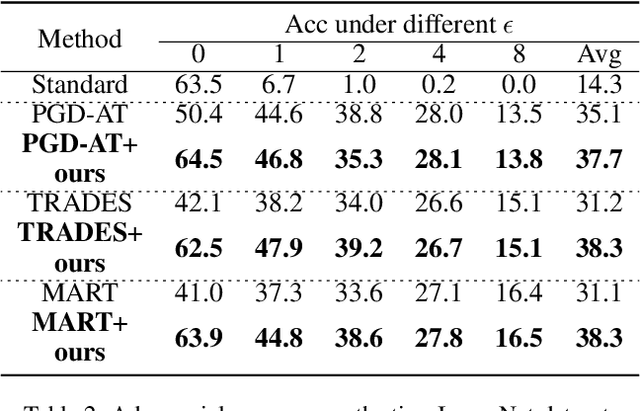
Recent studies reveal that Convolutional Neural Networks (CNNs) are typically vulnerable to adversarial attacks, which pose a threat to security-sensitive applications. Many adversarial defense methods improve robustness at the cost of accuracy, raising the contradiction between standard and adversarial accuracies. In this paper, we observe an interesting phenomenon that feature statistics change monotonically and smoothly w.r.t the rising of attacking strength. Based on this observation, we propose the adaptive feature alignment (AFA) to generate features of arbitrary attacking strengths. Our method is trained to automatically align features of arbitrary attacking strength. This is done by predicting a fusing weight in a dual-BN architecture. Unlike previous works that need to either retrain the model or manually tune a hyper-parameters for different attacking strengths, our method can deal with arbitrary attacking strengths with a single model without introducing any hyper-parameter. Importantly, our method improves the model robustness against adversarial samples without incurring much loss in standard accuracy. Experiments on CIFAR-10, SVHN, and tiny-ImageNet datasets demonstrate that our method outperforms the state-of-the-art under a wide range of attacking strengths.