 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Alignment and Many-to-many Entailment Based Reasoning for Conversational Machine Reading
Oct 20, 2023



Conversational Machine Reading (CMR) requires answering a user's initial question through multi-turn dialogue interactions based on a given document. Although there exist many effective methods, they largely neglected the alignment between the document and the user-provided information, which significantly affects the intermediate decision-making and subsequent follow-up question generation. To address this issue, we propose a pipeline framework that (1) aligns the aforementioned two sides in an explicit way, (2)makes decisions using a lightweight many-to-many entailment reasoning module, and (3) directly generates follow-up questions based on the document and previously asked questions. Our proposed method achieves state-of-the-art in micro-accuracy and ranks the first place on the public leaderboard of the CMR benchmark dataset ShARC.
A Task-oriented Dialog Model with Task-progressive and Policy-aware Pre-training
Oct 01, 2023Pre-trained conversation models (PCMs) have achieved promising progress in recent years. However, existing PCMs for Task-oriented dialog (TOD) are insufficient for capturing the sequential nature of the TOD-related tasks, as well as for learning dialog policy information. To alleviate these problems, this paper proposes a task-progressive PCM with two policy-aware pre-training tasks. The model is pre-trained through three stages where TOD-related tasks are progressively employed according to the task logic of the TOD system. A global policy consistency task is designed to capture the multi-turn dialog policy sequential relation, and an act-based contrastive learning task is designed to capture similarities among samples with the same dialog policy. Our model achieves better results on both MultiWOZ and In-Car end-to-end dialog modeling benchmarks with only 18\% parameters and 25\% pre-training data compared to the previous state-of-the-art PCM, GALAXY.
AKEM: Aligning Knowledge Base to Queries with Ensemble Model for Entity Recognition and Linking
Sep 13, 2023

This paper presents a novel approach to address the Entity Recognition and Linking Challenge at NLPCC 2015. The task involves extracting named entity mentions from short search queries and linking them to entities within a reference Chinese knowledge base. To tackle this problem, we first expand the existing knowledge base and utilize external knowledge to identify candidate entities, thereby improving the recall rate. Next, we extract features from the candidate entities and utilize Support Vector Regression and Multiple Additive Regression Tree as scoring functions to filter the results. Additionally, we apply rules to further refine the results and enhance precision. Our method is computationally efficient and achieves an F1 score of 0.535.
Whether you can locate or not? Interactive Referring Expression Generation
Aug 19, 2023



Referring Expression Generation (REG) aims to generate unambiguous Referring Expressions (REs) for objects in a visual scene, with a dual task of Referring Expression Comprehension (REC) to locate the referred object. Existing methods construct REG models independently by using only the REs as ground truth for model training, without considering the potential interaction between REG and REC models. In this paper, we propose an Interactive REG (IREG) model that can interact with a real REC model, utilizing signals indicating whether the object is located and the visual region located by the REC model to gradually modify REs. Our experimental results on three RE benchmark datasets, RefCOCO, RefCOCO+, and RefCOCOg show that IREG outperforms previous state-of-the-art methods on popular evaluation metrics. Furthermore, a human evaluation shows that IREG generates better REs with the capability of interaction.
FATRER: Full-Attention Topic Regularizer for Accurate and Robust Conversational Emotion Recognition
Jul 23, 2023This paper concentrates on the understanding of interlocutors' emotions evoked in conversational utterances. Previous studies in this literature mainly focus on more accurate emotional predictions, while ignoring model robustness when the local context is corrupted by adversarial attacks. To maintain robustness while ensuring accuracy, we propose an emotion recognizer augmented by a full-attention topic regularizer, which enables an emotion-related global view when modeling the local context in a conversation. A joint topic modeling strategy is introduced to implement regularization from both representation and loss perspectives. To avoid over-regularization, we drop the constraints on prior distributions that exist in traditional topic modeling and perform probabilistic approximations based entirely on attention alignment. Experiments show that our models obtain more favorable results than state-of-the-art models, and gain convincing robustness under three types of adversarial attacks.
Multimodal Recommendation Dialog with Subjective Preference: A New Challenge and Benchmark
May 26, 2023Existing multimodal task-oriented dialog data fails to demonstrate the diverse expressions of user subjective preferences and recommendation acts in the real-life shopping scenario. This paper introduces a new dataset SURE (Multimodal Recommendation Dialog with SUbjective PREference), which contains 12K shopping dialogs in complex store scenes. The data is built in two phases with human annotations to ensure quality and diversity. SURE is well-annotated with subjective preferences and recommendation acts proposed by sales experts. A comprehensive analysis is given to reveal the distinguishing features of SURE. Three benchmark tasks are then proposed on the data to evaluate the capability of multimodal recommendation agents. Based on the SURE, we propose a baseline model, powered by a state-of-the-art multimodal model, for these tasks.
An Asynchronous Updating Reinforcement Learning Framework for Task-oriented Dialog System
May 04, 2023


Reinforcement learning has been applied to train the dialog systems in many works. Previous approaches divide the dialog system into multiple modules including DST (dialog state tracking) and DP (dialog policy), and train these modules simultaneously. However, different modules influence each other during training. The errors from DST might misguide the dialog policy, and the system action brings extra difficulties for the DST module. To alleviate this problem, we propose Asynchronous Updating Reinforcement Learning framework (AURL) that updates the DST module and the DP module asynchronously under a cooperative setting. Furthermore, curriculum learning is implemented to address the problem of unbalanced data distribution during reinforcement learning sampling, and multiple user models are introduced to increase the dialog diversity. Results on the public SSD-PHONE dataset show that our method achieves a compelling result with a 31.37% improvement on the dialog success rate. The code is publicly available via https://github.com/shunjiu/AURL.
SPRING: Situated Conversation Agent Pretrained with Multimodal Questions from Incremental Layout Graph
Jan 05, 2023



Existing multimodal conversation agents have shown impressive abilities to locate absolute positions or retrieve attributes in simple scenarios, but they fail to perform well when complex relative positions and information alignments are involved, which poses a bottleneck in response quality. In this paper, we propose a Situated Conversation Agent Petrained with Multimodal Questions from INcremental Layout Graph (SPRING) with abilities of reasoning multi-hops spatial relations and connecting them with visual attributes in crowded situated scenarios. Specifically, we design two types of Multimodal Question Answering (MQA) tasks to pretrain the agent. All QA pairs utilized during pretraining are generated from novel Incremental Layout Graphs (ILG). QA pair difficulty labels automatically annotated by ILG are used to promote MQA-based Curriculum Learning. Experimental results verify the SPRING's effectiveness, showing that it significantly outperforms state-of-the-art approaches on both SIMMC 1.0 and SIMMC 2.0 datasets.
Towards Unifying Reference Expression Generation and Comprehension
Oct 24, 2022



Reference Expression Generation (REG) and Comprehension (REC) are two highly correlated tasks. Modeling REG and REC simultaneously for utilizing the relation between them is a promising way to improve both. However, the problem of distinct inputs, as well as building connections between them in a single model, brings challenges to the design and training of the joint model. To address the problems, we propose a unified model for REG and REC, named UniRef. It unifies these two tasks with the carefully-designed Image-Region-Text Fusion layer (IRTF), which fuses the image, region and text via the image cross-attention and region cross-attention. Additionally, IRTF could generate pseudo input regions for the REC task to enable a uniform way for sharing the identical representation space across the REC and REG. We further propose Vision-conditioned Masked Language Modeling (VMLM) and Text-Conditioned Region Prediction (TRP) to pre-train UniRef model on multi-granular corpora. The VMLM and TRP are directly related to REG and REC, respectively, but could help each other. We conduct extensive experiments on three benchmark datasets, RefCOCO, RefCOCO+ and RefCOCOg. Experimental results show that our model outperforms previous state-of-the-art methods on both REG and REC.
GR-GAN: Gradual Refinement Text-to-image Generation
May 23, 2022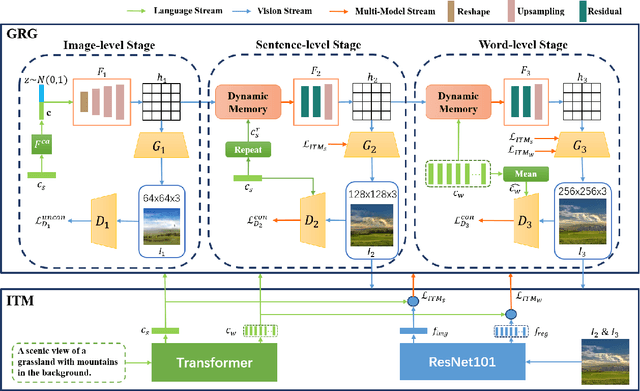
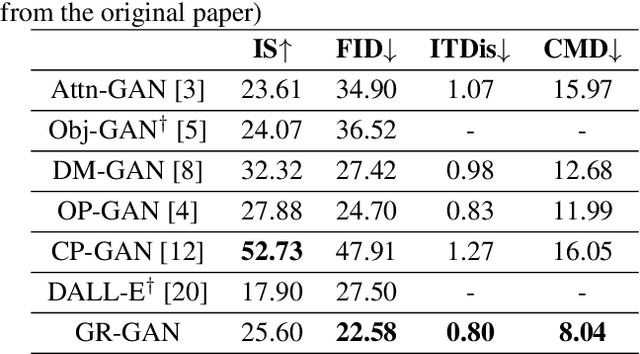

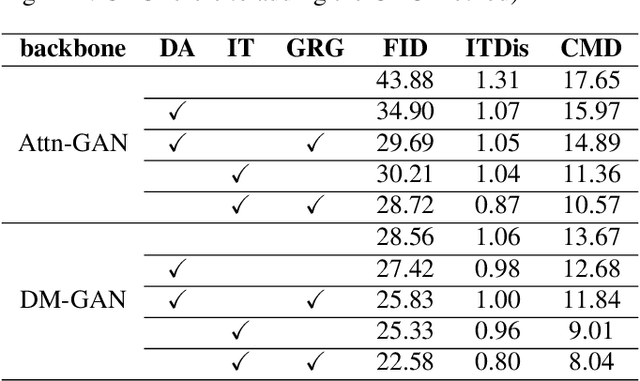
A good Text-to-Image model should not only generate high quality images, but also ensure the consistency between the text and the generated image. Previous models failed to simultaneously fix both sides well. This paper proposes a Gradual Refinement Generative Adversarial Network (GR-GAN) to alleviates the problem efficiently. A GRG module is designed to generate images from low resolution to high resolution with the corresponding text constraints from coarse granularity (sentence) to fine granularity (word) stage by stage, a ITM module is designed to provide image-text matching losses at both sentence-image level and word-region level for corresponding stages. We also introduce a new metric Cross-Model Distance (CMD) for simultaneously evaluating image quality and image-text consistency. Experimental results show GR-GAN significant outperform previous models, and achieve new state-of-the-art on both FID and CMD. A detailed analysis demonstrates the efficiency of different generation stages in GR-GAN.