 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Sentence Functions for Short-Text Conversation
Jul 26, 2019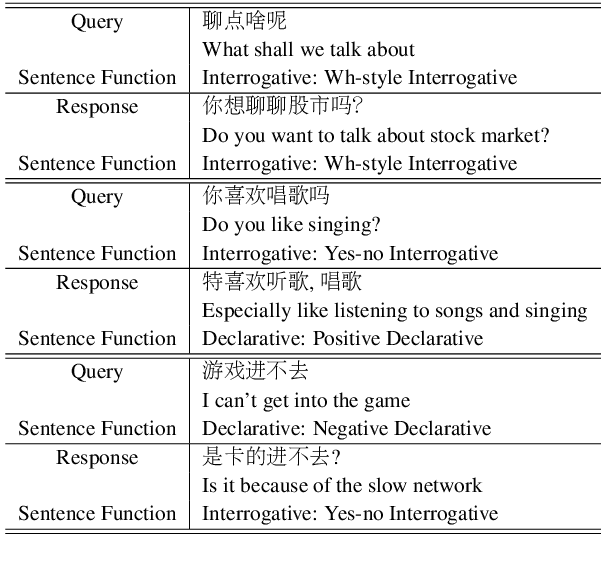
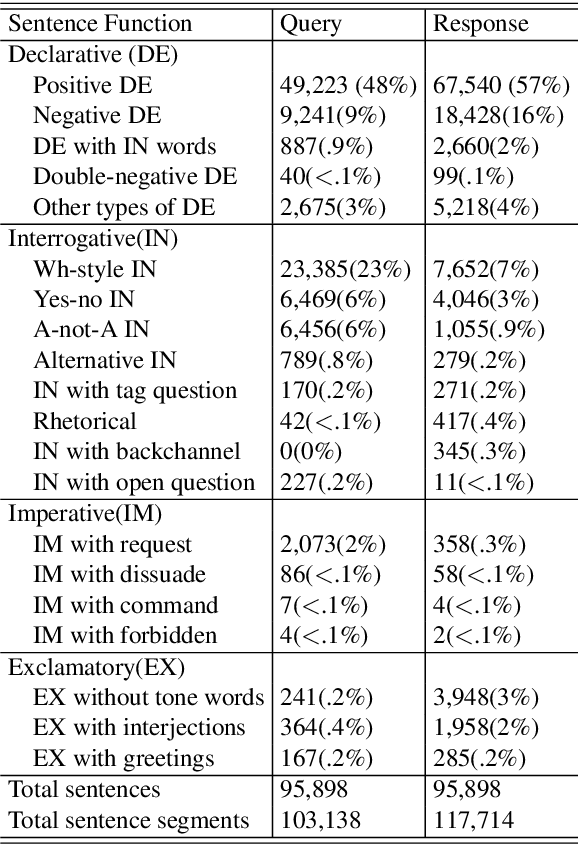


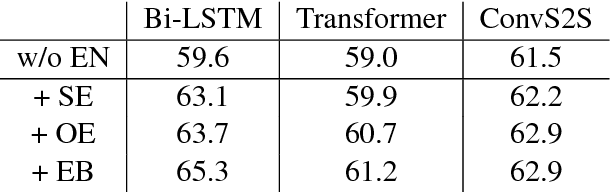
Sentence function is an important linguistic feature referring to a user's purpose in uttering a specific sentence. The use of sentence function has shown promising results to improve the performance of conversation models. However, there is no large conversation dataset annotated with sentence functions. In this work, we collect a new Short-Text Conversation dataset with manually annotated SEntence FUNctions (STC-Sefun). Classification models are trained on this dataset to (i) recognize the sentence function of new data in a large corpus of short-text conversations; (ii) estimate a proper sentence function of the response given a test query. We later train conversation models conditioned on the sentence functions, including information retrieval-based and neural generative models. Experimental results demonstrate that the use of sentence functions can help improve the quality of the returned responses.
Generating Multiple Diverse Responses for Short-Text Conversation
Nov 29, 2018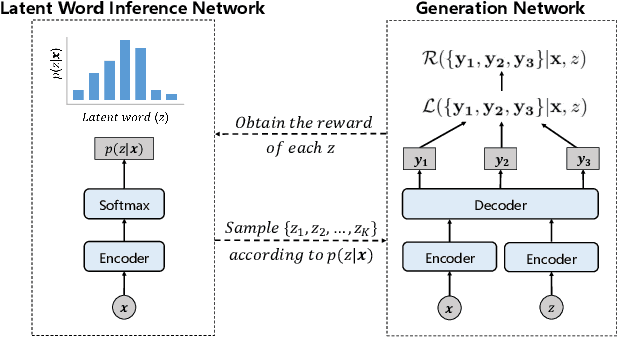
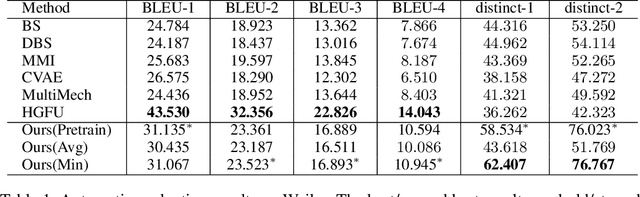

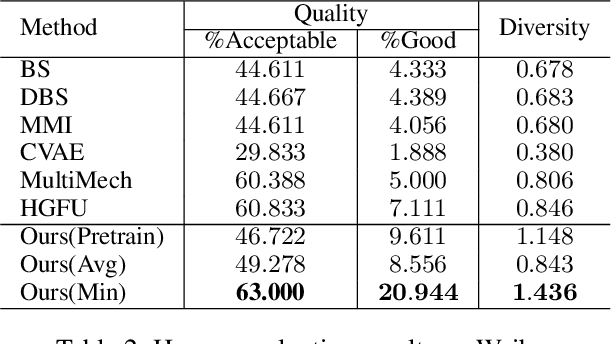
Neural generative models have become popular and achieved promising performance on short-text conversation tasks. They are generally trained to build a 1-to-1 mapping from the input post to its output response. However, a given post is often associated with multiple replies simultaneously in real applications. Previous research on this task mainly focuses on improving the relevance and informativeness of the top one generated response for each post. Very few works study generating multiple accurate and diverse responses for the same post. In this paper, we propose a novel response generation model, which considers a set of responses jointly and generates multiple diverse responses simultaneously. A reinforcement learning algorithm is designed to solve our model. Experiments on two short-text conversation tasks validate that the multiple responses generated by our model obtain higher quality and larger diversity compared with various state-of-the-art generative models.
Translating a Math Word Problem to an Expression Tree
Nov 15, 2018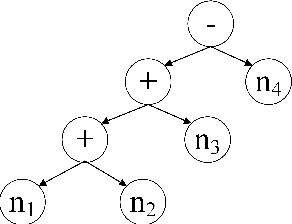
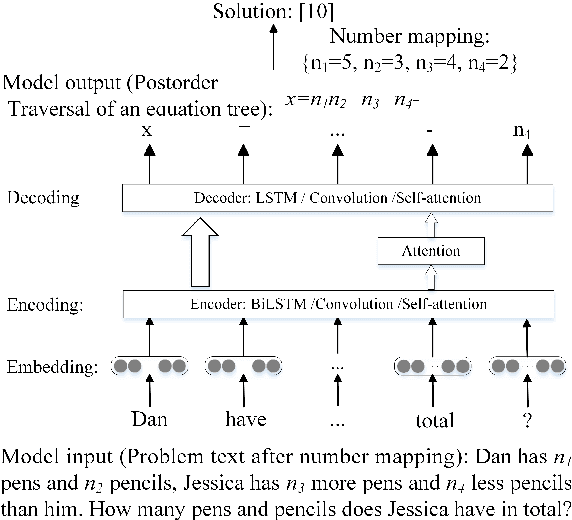
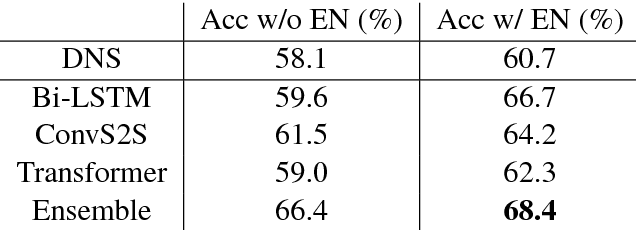
Sequence-to-sequence (SEQ2SEQ) models have been successfully applied to automatic math word problem solving. Despite its simplicity, a drawback still remains: a math word problem can be correctly solved by more than one equations. This non-deterministic transduction harms the performance of maximum likelihood estimation. In this paper, by considering the uniqueness of expression tree, we propose an equation normalization method to normalize the duplicated equations. Moreover, we analyze the performance of three popular SEQ2SEQ models on the math word problem solving. We find that each model has its own specialty in solving problems, consequently an ensemble model is then proposed to combine their advantages. Experiments on dataset Math23K show that the ensemble model with equation normalization significantly outperforms the previous state-of-the-art methods.
Skeleton-to-Response: Dialogue Generation Guided by Retrieval Memory
Nov 02, 2018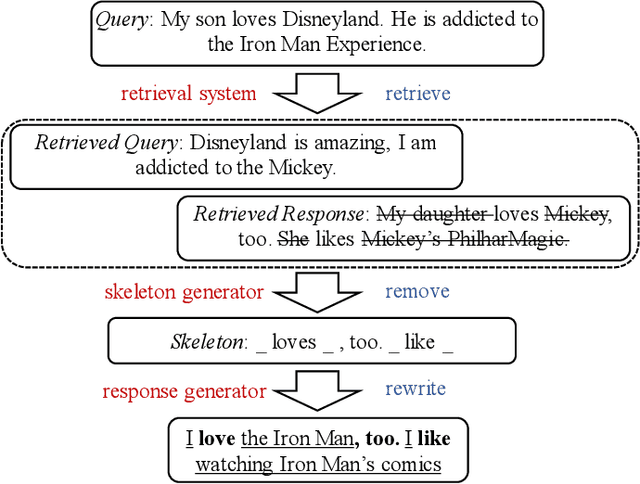
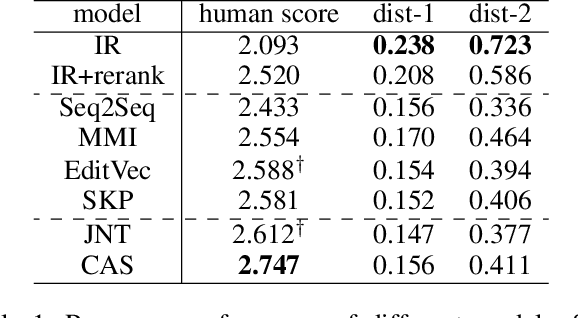
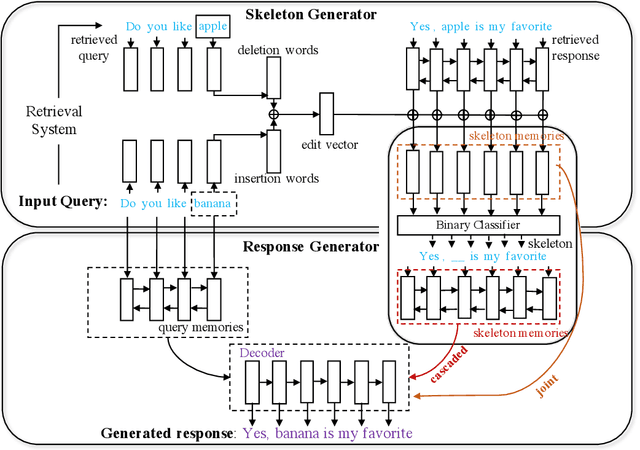
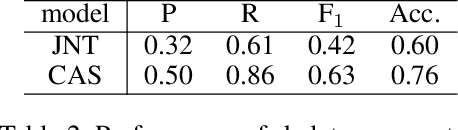
For dialogue response generation, traditional generative models generate responses solely from input queries. Such models rely on insufficient information for generating a specific response since a certain query could be answered in multiple ways. Consequentially, those models tend to output generic and dull responses, impeding the generation of informative utterances. Recently, researchers have attempted to fill the information gap by exploiting information retrieval techniques. When generating a response for a current query, similar dialogues retrieved from the entire training data are considered as an additional knowledge source. While this may harvest massive information, the generative models could be overwhelmed, leading to undesirable performance. In this paper, we propose a new framework which exploits retrieval results via a skeleton-then-response paradigm. At first, a skeleton is generated by revising the retrieved responses. Then, a novel generative model uses both the generated skeleton and the original query for response generation. Experimental results show that our approaches significantly improve the diversity and informativeness of the generated responses.
Generative Stock Question Answering
Sep 20, 2018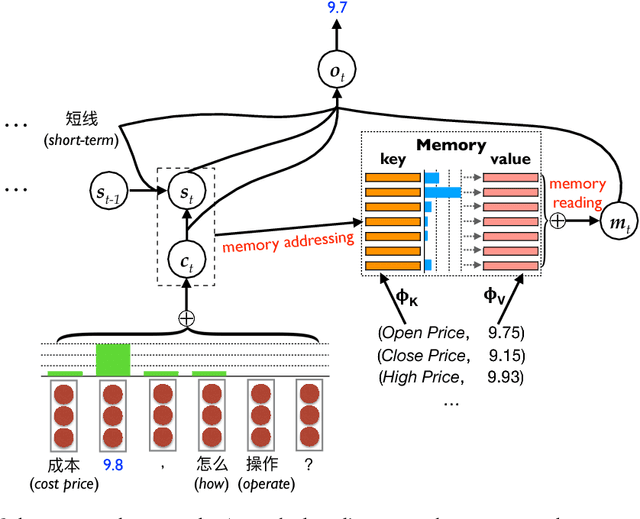
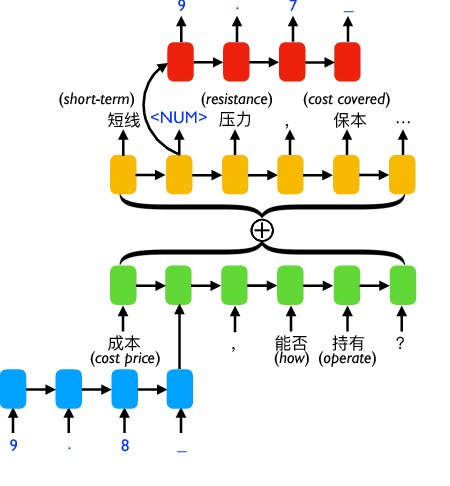
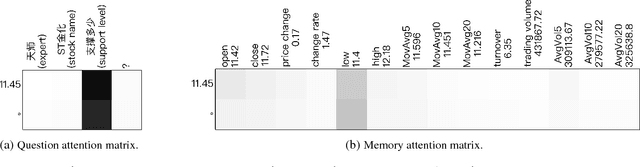
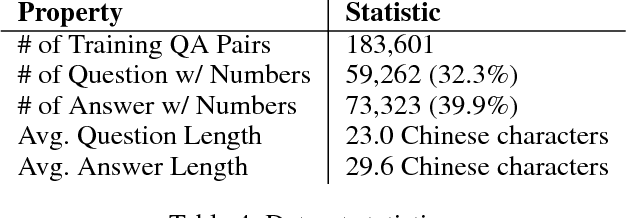
We study the problem of stock related question answering (StockQA): automatically generating answers to stock related questions, just like professional stock analysts providing action recommendations to stocks upon user's requests. StockQA is quite different from previous QA tasks since (1) the answers in StockQA are natural language sentences (rather than entities or values) and due to the dynamic nature of StockQA, it is scarcely possible to get reasonable answers in an extractive way from the training data; and (2) StockQA requires properly analyzing the relationship between keywords in QA pair and the numerical features of a stock. We propose to address the problem with a memory-augmented encoder-decoder architecture, and integrate different mechanisms of number understanding and generation, which is a critical component of StockQA. We build a large-scale dataset containing over 180K StockQA instances, based on which various technique combinations are extensively studied and compared. Experimental results show that a hybrid word-character model with separate character components for number processing, achieves the best performance. By analyzing the results, we found that 44.8% of answers generated by our best model still suffer from the generic answer problem, which can be alleviated by a straightforward hybrid retrieval-generation model.
Language Style Transfer from Sentences with Arbitrary Unknown Styles
Aug 13, 2018
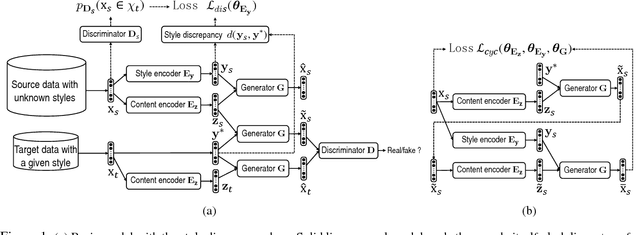
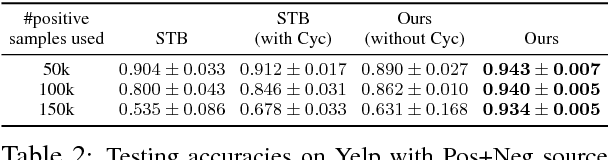

Language style transfer is the problem of migrating the content of a source sentence to a target style. In many of its applications, parallel training data are not available and source sentences to be transferred may have arbitrary and unknown styles. First, each sentence is encoded into its content and style latent representations. Then, by recombining the content with the target style, we decode a sentence aligned in the target domain. To adequately constrain the encoding and decoding functions, we couple them with two loss functions. The first is a style discrepancy loss, enforcing that the style representation accurately encodes the style information guided by the discrepancy between the sentence style and the target style. The second is a cycle consistency loss, which ensures that the transferred sentence should preserve the content of the original sentence disentangled from its style. We validate the effectiveness of our model in three tasks: sentiment modification of restaurant reviews, dialog response revision with a romantic style, and sentence rewriting with a Shakespearean style.
Automatic Article Commenting: the Task and Dataset
May 11, 2018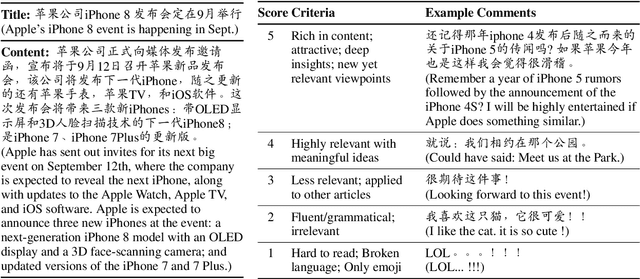
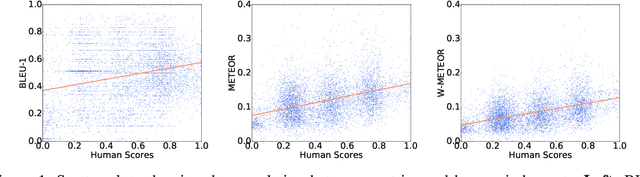
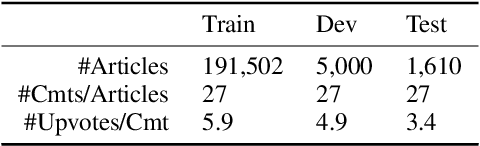
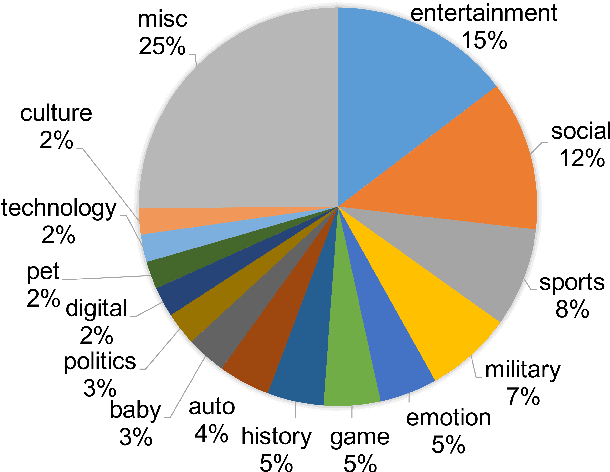
Comments of online articles provide extended views and improve user engagement. Automatically making comments thus become a valuable functionality for online forums, intelligent chatbots, etc. This paper proposes the new task of automatic article commenting, and introduces a large-scale Chinese dataset with millions of real comments and a human-annotated subset characterizing the comments' varying quality. Incorporating the human bias of comment quality, we further develop automatic metrics that generalize a broad set of popular reference-based metrics and exhibit greatly improved correlations with human evaluations.