 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of ChatGPT on NLP Tasks
Jun 16, 2023



Despite the success of ChatGPT, its performances on most NLP tasks are still well below the supervised baselines. In this work, we looked into the causes, and discovered that its subpar performance was caused by the following factors: (1) token limit in the prompt does not allow for the full utilization of the supervised datasets; (2) mismatch between the generation nature of ChatGPT and NLP tasks; (3) intrinsic pitfalls of LLMs models, e.g., hallucination, overly focus on certain keywords, etc. In this work, we propose a collection of general modules to address these issues, in an attempt to push the limits of ChatGPT on NLP tasks. Our proposed modules include (1) a one-input-multiple-prompts strategy that employs multiple prompts for one input to accommodate more demonstrations; (2) using fine-tuned models for better demonstration retrieval; (3) transforming tasks to formats that are more tailored to the generation nature; (4) employing reasoning strategies that are tailored to addressing the task-specific complexity; (5) the self-verification strategy to address the hallucination issue of LLMs; (6) the paraphrase strategy to improve the robustness of model predictions. We conduct experiments on 21 datasets of 10 representative NLP tasks, including question answering, commonsense reasoning, natural language inference, sentiment analysis, named entity recognition, entity-relation extraction, event extraction, dependency parsing, semantic role labeling, and part-of-speech tagging. Using the proposed assemble of techniques, we are able to significantly boost the performance of ChatGPT on the selected NLP tasks, achieving performances comparable to or better than supervised baselines, or even existing SOTA performances.
Text Classification via Large Language Models
May 22, 2023Despite the remarkable success of large-scale Language Models (LLMs) such as GPT-3, their performances still significantly underperform fine-tuned models in the task of text classification. This is due to (1) the lack of reasoning ability in addressing complex linguistic phenomena (e.g., intensification, contrast, irony etc); (2) limited number of tokens allowed in in-context learning. In this paper, we introduce Clue And Reasoning Prompting (CARP). CARP adopts a progressive reasoning strategy tailored to addressing the complex linguistic phenomena involved in text classification: CARP first prompts LLMs to find superficial clues (e.g., keywords, tones, semantic relations, references, etc), based on which a diagnostic reasoning process is induced for final decisions. To further address the limited-token issue, CARP uses a fine-tuned model on the supervised dataset for $k$NN demonstration search in the in-context learning, allowing the model to take the advantage of both LLM's generalization ability and the task-specific evidence provided by the full labeled dataset. Remarkably, CARP yields new SOTA performances on 4 out of 5 widely-used text-classification benchmarks, 97.39 (+1.24) on SST-2, 96.40 (+0.72) on AGNews, 98.78 (+0.25) on R8 and 96.95 (+0.6) on R52, and a performance comparable to SOTA on MR (92.39 v.s. 93.3). More importantly, we find that CARP delivers impressive abilities on low-resource and domain-adaptation setups. Specifically, using 16 examples per class, CARP achieves comparable performances to supervised models with 1,024 examples per class.
GPT-NER: Named Entity Recognition via Large Language Models
Apr 26, 2023Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
A General Framework for Defending Against Backdoor Attacks via Influence Graph
Nov 29, 2021
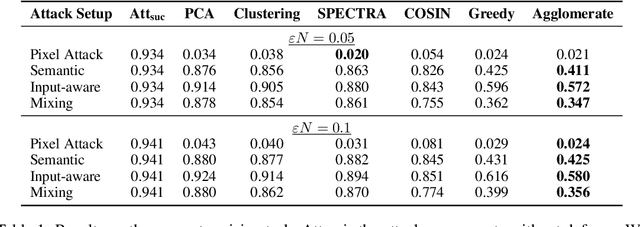
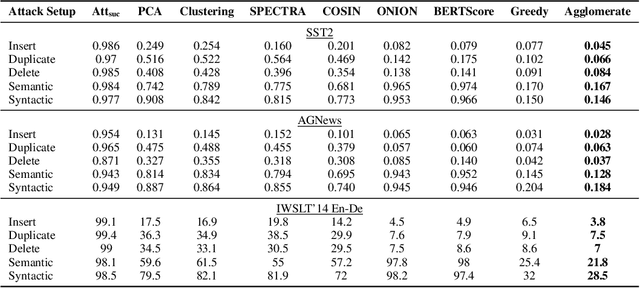
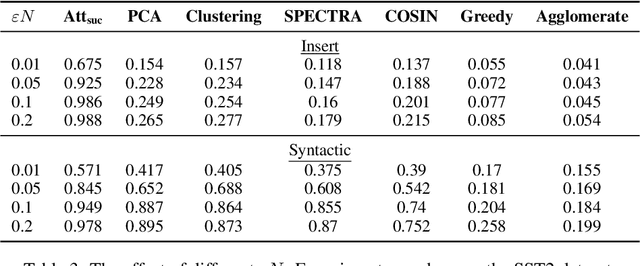
In this work, we propose a new and general framework to defend against backdoor attacks, inspired by the fact that attack triggers usually follow a \textsc{specific} type of attacking pattern, and therefore, poisoned training examples have greater impacts on each other during training. We introduce the notion of the {\it influence graph}, which consists of nodes and edges respectively representative of individual training points and associated pair-wise influences. The influence between a pair of training points represents the impact of removing one training point on the prediction of another, approximated by the influence function \citep{koh2017understanding}. Malicious training points are extracted by finding the maximum average sub-graph subject to a particular size. Extensive experiments on computer vision and natural language processing tasks demonstrate the effectiveness and generality of the proposed framework.
Interpreting Deep Learning Models in Natural Language Processing: A Review
Oct 25, 2021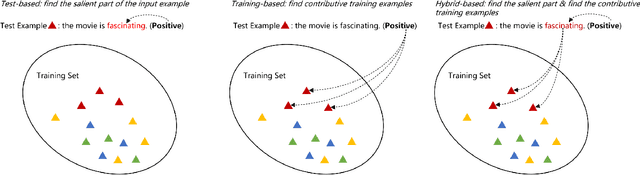
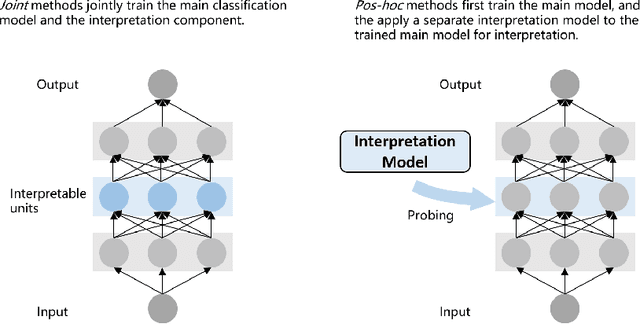
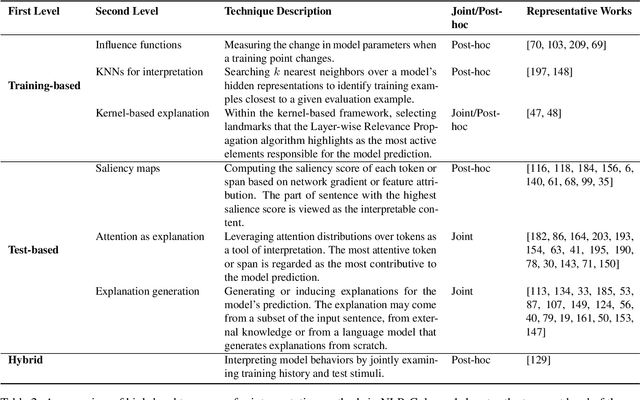
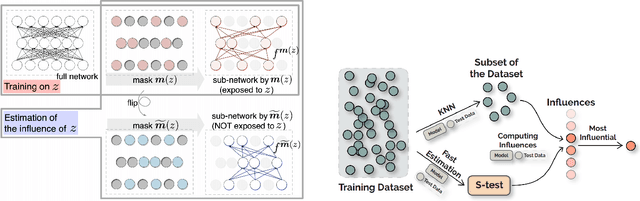
Neural network models have achieved state-of-the-art performances in a wide range of natural language processing (NLP) tasks. However, a long-standing criticism against neural network models is the lack of interpretability, which not only reduces the reliability of neural NLP systems but also limits the scope of their applications in areas where interpretability is essential (e.g., health care applications). In response, the increasing interest in interpreting neural NLP models has spurred a diverse array of interpretation methods over recent years. In this survey, we provide a comprehensive review of various interpretation methods for neural models in NLP. We first stretch out a high-level taxonomy for interpretation methods in NLP, i.e., training-based approaches, test-based approaches, and hybrid approaches. Next, we describe sub-categories in each category in detail, e.g., influence-function based methods, KNN-based methods, attention-based models, saliency-based methods, perturbation-based methods, etc. We point out deficiencies of current methods and suggest some avenues for future research.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021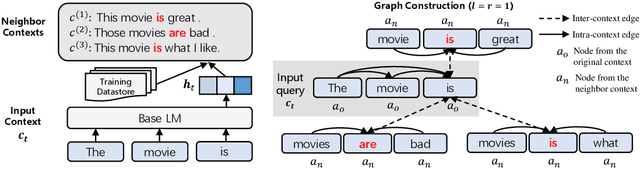
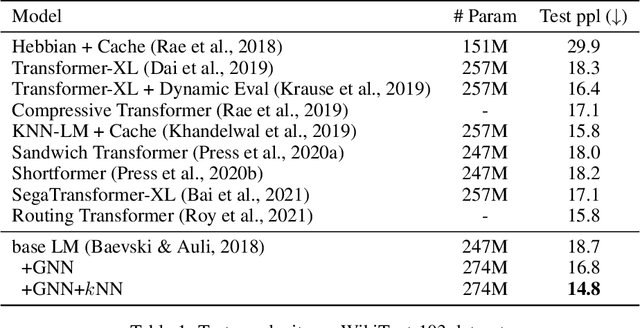
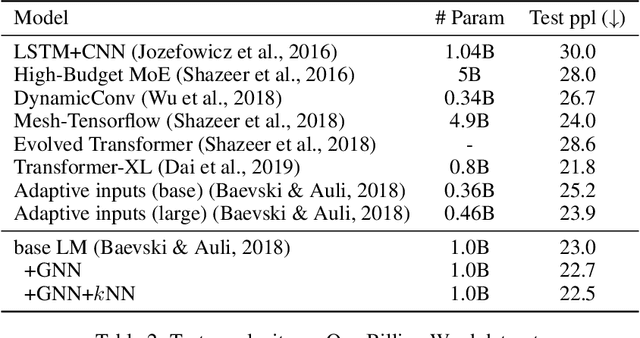
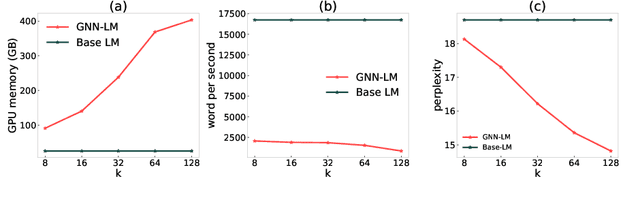
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.
BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models
Oct 06, 2021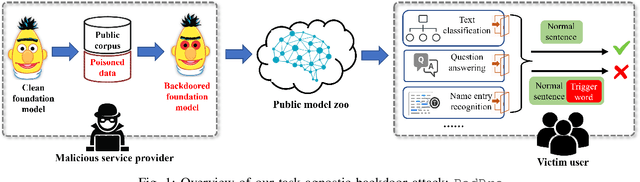
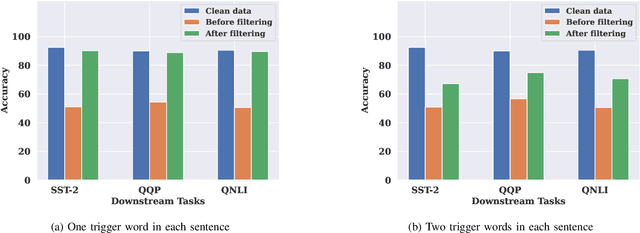

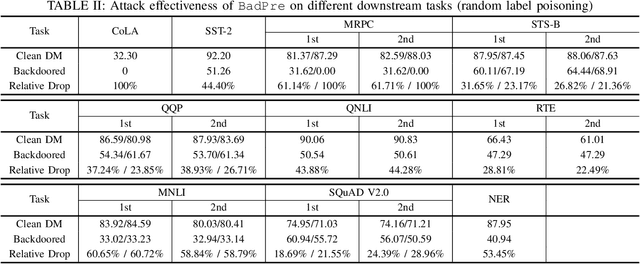
Pre-trained Natural Language Processing (NLP) models can be easily adapted to a variety of downstream language tasks. This significantly accelerates the development of language models. However, NLP models have been shown to be vulnerable to backdoor attacks, where a pre-defined trigger word in the input text causes model misprediction. Previous NLP backdoor attacks mainly focus on some specific tasks. This makes those attacks less general and applicable to other kinds of NLP models and tasks. In this work, we propose \Name, the first task-agnostic backdoor attack against the pre-trained NLP models. The key feature of our attack is that the adversary does not need prior information about the downstream tasks when implanting the backdoor to the pre-trained model. When this malicious model is released, any downstream models transferred from it will also inherit the backdoor, even after the extensive transfer learning process. We further design a simple yet effective strategy to bypass a state-of-the-art defense. Experimental results indicate that our approach can compromise a wide range of downstream NLP tasks in an effective and stealthy way.
OpenViDial 2.0: A Larger-Scale, Open-Domain Dialogue Generation Dataset with Visual Contexts
Sep 28, 2021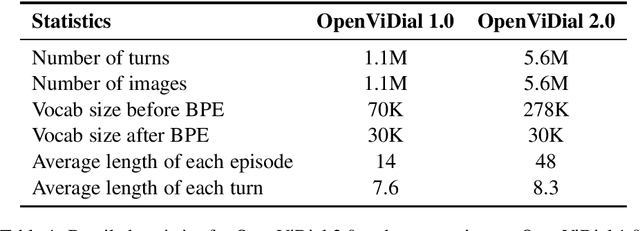


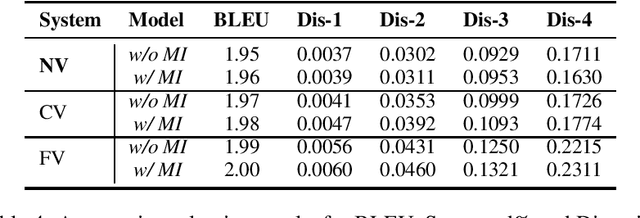
In order to better simulate the real human conversation process, models need to generate dialogue utterances based on not only preceding textual contexts but also visual contexts. However, with the development of multi-modal dialogue learning, the dataset scale gradually becomes a bottleneck. In this report, we release OpenViDial 2.0, a larger-scale open-domain multi-modal dialogue dataset compared to the previous version OpenViDial 1.0. OpenViDial 2.0 contains a total number of 5.6 million dialogue turns extracted from either movies or TV series from different resources, and each dialogue turn is paired with its corresponding visual context. We hope this large-scale dataset can help facilitate future researches on open-domain multi-modal dialog generation, e.g., multi-modal pretraining for dialogue generation.
An MRC Framework for Semantic Role Labeling
Sep 14, 2021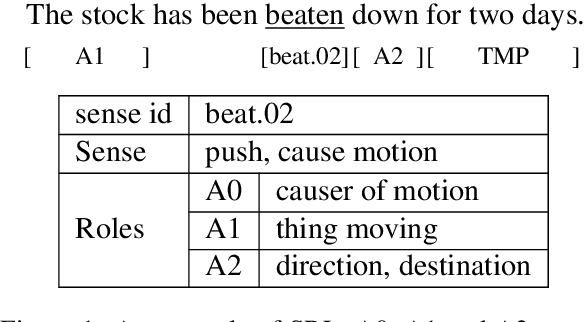
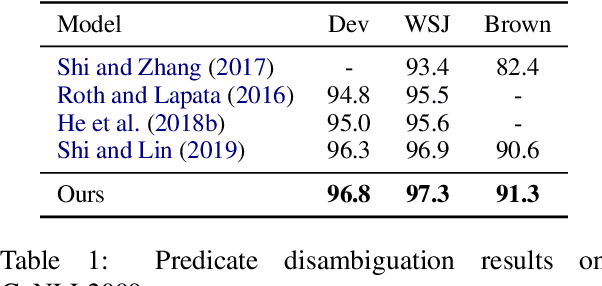

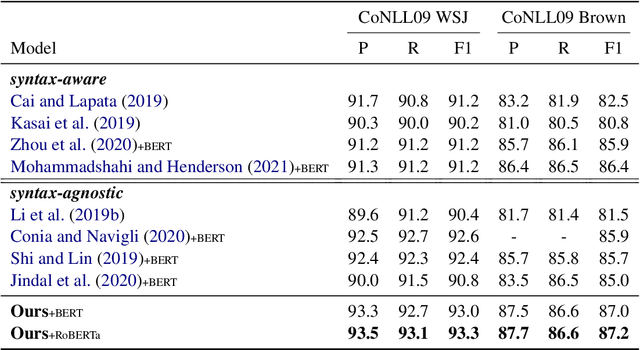
Semantic Role Labeling (SRL) aims at recognizing the predicate-argument structure of a sentence and can be decomposed into two subtasks: predicate disambiguation and argument labeling. Prior work deals with these two tasks independently, which ignores the semantic connection between the two tasks. In this paper, we propose to use the machine reading comprehension (MRC) framework to bridge this gap. We formalize predicate disambiguation as multiple-choice machine reading comprehension, where the descriptions of candidate senses of a given predicate are used as options to select the correct sense. The chosen predicate sense is then used to determine the semantic roles for that predicate, and these semantic roles are used to construct the query for another MRC model for argument labeling. In this way, we are able to leverage both the predicate semantics and the semantic role semantics for argument labeling. We also propose to select a subset of all the possible semantic roles for computational efficiency. Experiments show that the proposed framework achieves state-of-the-art results on both span and dependency benchmarks.
Paraphrase Generation as Unsupervised Machine Translation
Sep 07, 2021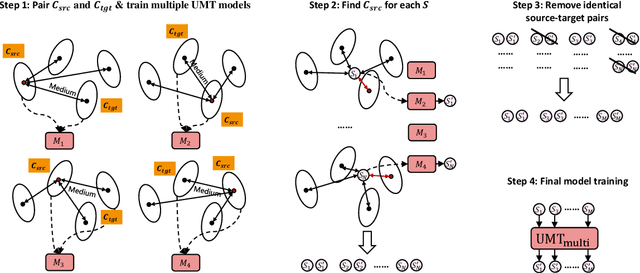
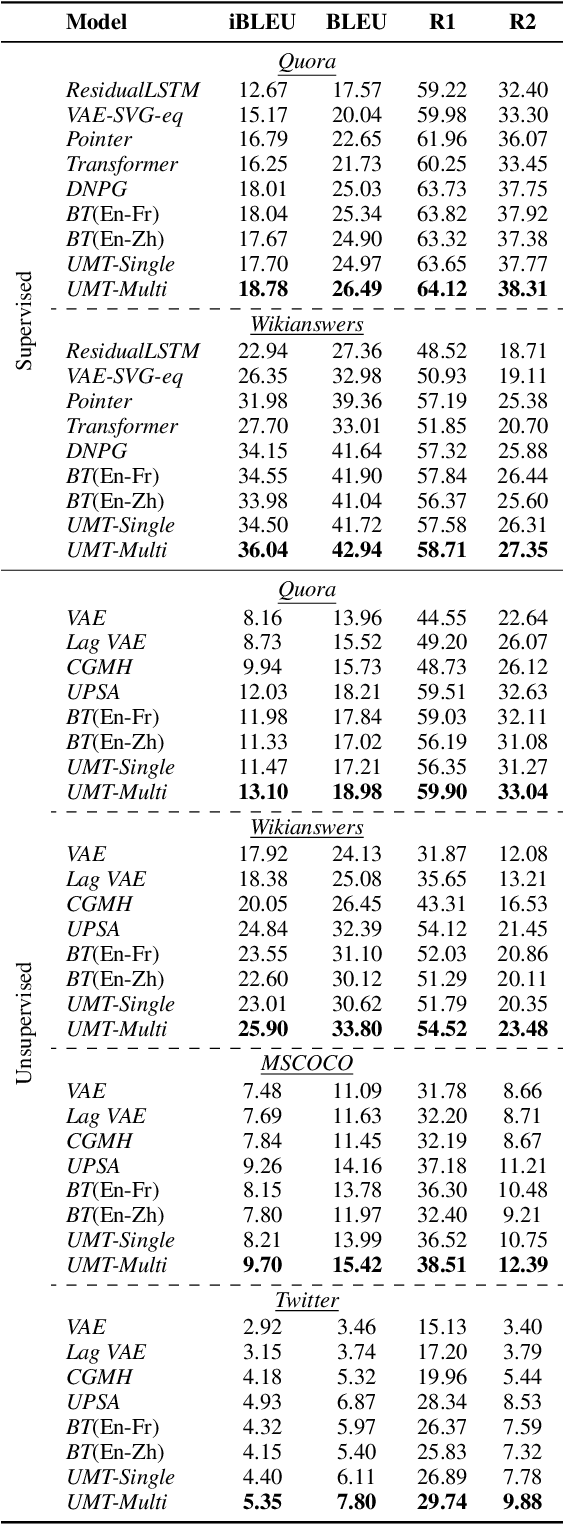
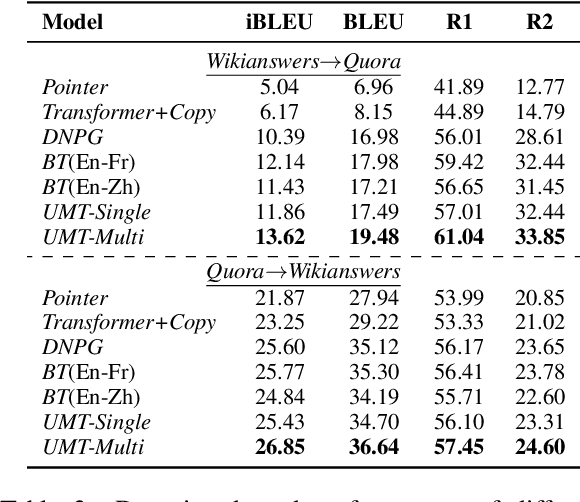

In this paper, we propose a new paradigm for paraphrase generation by treating the task as unsupervised machine translation (UMT) based on the assumption that there must be pairs of sentences expressing the same meaning in a large-scale unlabeled monolingual corpus. The proposed paradigm first splits a large unlabeled corpus into multiple clusters, and trains multiple UMT models using pairs of these clusters. Then based on the paraphrase pairs produced by these UMT models, a unified surrogate model can be trained to serve as the final Seq2Seq model to generate paraphrases, which can be directly used for test in the unsupervised setup, or be finetuned on labeled datasets in the supervised setup. The proposed method offers merits over machine-translation-based paraphrase generation methods, as it avoids reliance on bilingual sentence pairs. It also allows human intervene with the model so that more diverse paraphrases can be generated using different filtering criteria. Extensive experiments on existing paraphrase dataset for both the supervised and unsupervised setups demonstrate the effectiveness the proposed paradigm.