 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSportsTrack: An Innovative Method for Tracking Athletes in Sports Scenes
Nov 14, 2022The SportsMOT competition aims to solve multiple object tracking of athletes in different sports scenes such as basketball or soccer. The competition is challenging because of the unstable camera view, athletes' complex trajectory, and complicated background. Previous MOT methods can not match enough high-quality tracks of athletes. To pursue higher performance of MOT in sports scenes, we introduce an innovative tracker named SportsTrack, we utilize tracking by detection as our detection paradigm. Then we will introduce a three-stage matching process to solve the motion blur and body overlapping in sports scenes. Meanwhile, we present another innovation point: one-to-many correspondence between detection bboxes and crowded tracks to handle the overlap of athletes' bodies during sports competitions. Compared to other trackers such as BOT-SORT and ByteTrack, We carefully restored edge-lost tracks that were ignored by other trackers. Finally, we reached the top 1 tracking score (76.264 HOTA) in the ECCV 2022 DeepAction SportsMOT competition.
QML for Argoverse 2 Motion Forecasting Challenge
Jul 13, 2022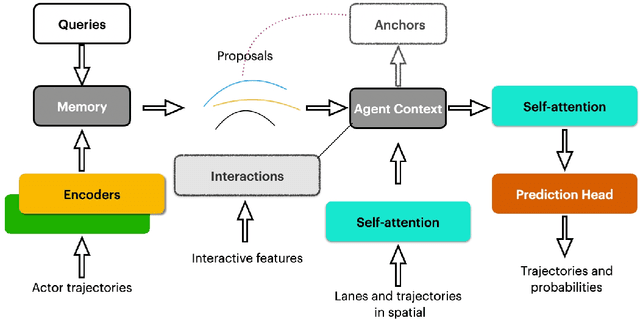

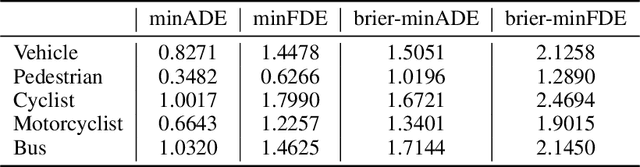

To safely navigate in various complex traffic scenarios, autonomous driving systems are generally equipped with a motion forecasting module to provide vital information for the downstream planning module. For the real-world onboard applications, both accuracy and latency of a motion forecasting model are essential. In this report, we present an effective and efficient solution, which ranks the 3rd place in the Argoverse 2 Motion Forecasting Challenge 2022.
Normalized/Clipped SGD with Perturbation for Differentially Private Non-Convex Optimization
Jun 27, 2022
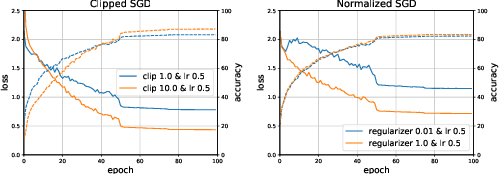
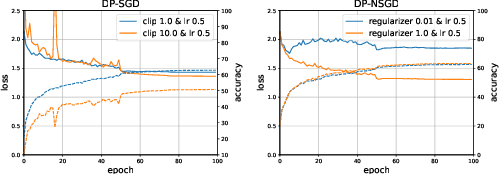
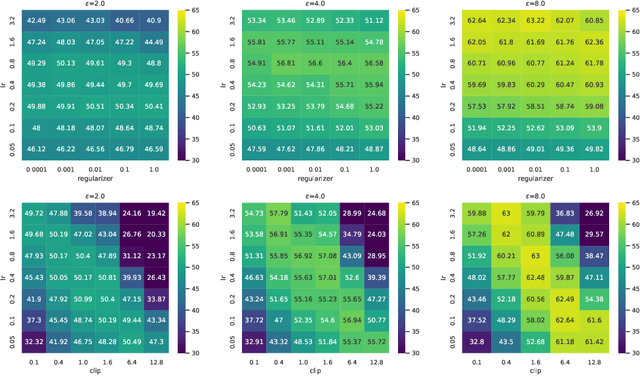
By ensuring differential privacy in the learning algorithms, one can rigorously mitigate the risk of large models memorizing sensitive training data. In this paper, we study two algorithms for this purpose, i.e., DP-SGD and DP-NSGD, which first clip or normalize \textit{per-sample} gradients to bound the sensitivity and then add noise to obfuscate the exact information. We analyze the convergence behavior of these two algorithms in the non-convex optimization setting with two common assumptions and achieve a rate $\mathcal{O}\left(\sqrt[4]{\frac{d\log(1/\delta)}{N^2\epsilon^2}}\right)$ of the gradient norm for a $d$-dimensional model, $N$ samples and $(\epsilon,\delta)$-DP, which improves over previous bounds under much weaker assumptions. Specifically, we introduce a regularizing factor in DP-NSGD and show that it is crucial in the convergence proof and subtly controls the bias and noise trade-off. Our proof deliberately handles the per-sample gradient clipping and normalization that are specified for the private setting. Empirically, we demonstrate that these two algorithms achieve similar best accuracy while DP-NSGD is comparatively easier to tune than DP-SGD and hence may help further save the privacy budget when accounting the tuning effort.
TL-GAN: Improving Traffic Light Recognition via Data Synthesis for Autonomous Driving
Mar 28, 2022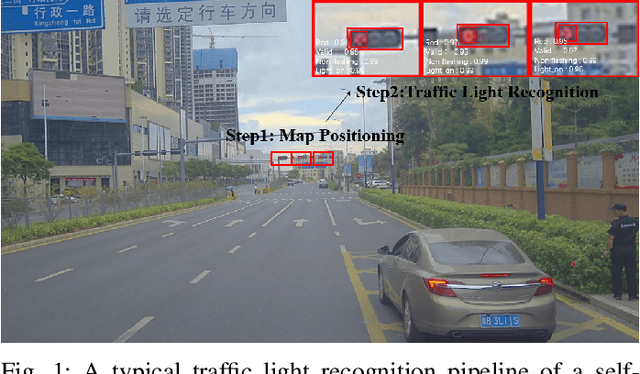
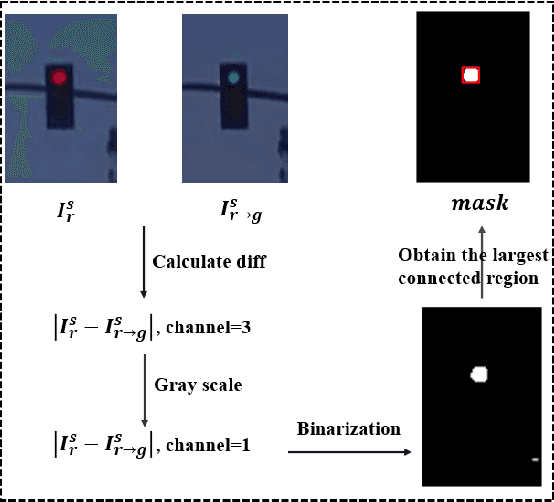


Traffic light recognition, as a critical component of the perception module of self-driving vehicles, plays a vital role in the intelligent transportation systems. The prevalent deep learning based traffic light recognition methods heavily hinge on the large quantity and rich diversity of training data. However, it is quite challenging to collect data in various rare scenarios such as flashing, blackout or extreme weather, thus resulting in the imbalanced distribution of training data and consequently the degraded performance in recognizing rare classes. In this paper, we seek to improve traffic light recognition by leveraging data synthesis. Inspired by the generative adversarial networks (GANs), we propose a novel traffic light generation approach TL-GAN to synthesize the data of rare classes to improve traffic light recognition for autonomous driving. TL-GAN disentangles traffic light sequence generation into image synthesis and sequence assembling. In the image synthesis stage, our approach enables conditional generation to allow full control of the color of the generated traffic light images. In the sequence assembling stage, we design the style mixing and adaptive template to synthesize realistic and diverse traffic light sequences. Extensive experiments show that the proposed TL-GAN renders remarkable improvement over the baseline without using the generated data, leading to the state-of-the-art performance in comparison with the competing algorithms that are used for general image synthesis and data imbalance tackling.
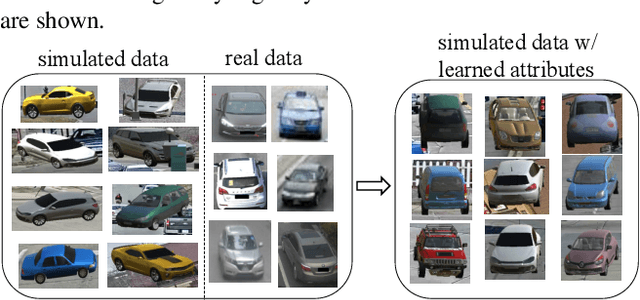
Attribute Descent: Simulating Object-Centric Datasets on the Content Level and Beyond
Feb 28, 2022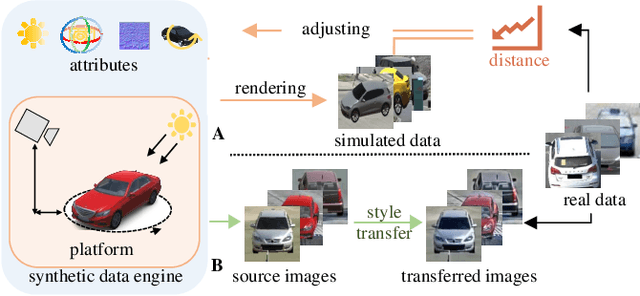
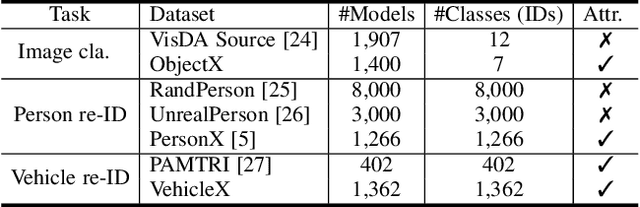

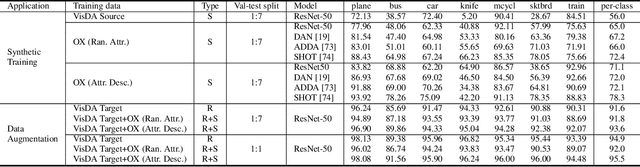
This article aims to use graphic engines to simulate a large number of training data that have free annotations and possibly strongly resemble to real-world data. Between synthetic and real, a two-level domain gap exists, involving content level and appearance level. While the latter is concerned with appearance style, the former problem arises from a different mechanism, i.e., content mismatch in attributes such as camera viewpoint, object placement and lighting conditions. In contrast to the widely-studied appearance-level gap, the content-level discrepancy has not been broadly studied. To address the content-level misalignment, we propose an attribute descent approach that automatically optimizes engine attributes to enable synthetic data to approximate real-world data. We verify our method on object-centric tasks, wherein an object takes up a major portion of an image. In these tasks, the search space is relatively small, and the optimization of each attribute yields sufficiently obvious supervision signals. We collect a new synthetic asset VehicleX, and reformat and reuse existing the synthetic assets ObjectX and PersonX. Extensive experiments on image classification and object re-identification confirm that adapted synthetic data can be effectively used in three scenarios: training with synthetic data only, training data augmentation and numerically understanding dataset content.
Learning Intrinsic Images for Clothing
Nov 16, 2021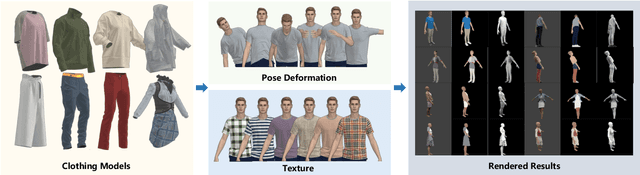


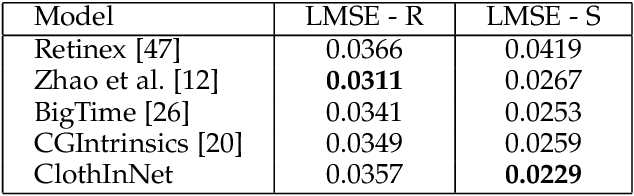
Reconstruction of human clothing is an important task and often relies on intrinsic image decomposition. With a lack of domain-specific data and coarse evaluation metrics, existing models failed to produce satisfying results for graphics applications. In this paper, we focus on intrinsic image decomposition for clothing images and have comprehensive improvements. We collected CloIntrinsics, a clothing intrinsic image dataset, including a synthetic training set and a real-world testing set. A more interpretable edge-aware metric and an annotation scheme is designed for the testing set, which allows diagnostic evaluation for intrinsic models. Finally, we propose ClothInNet model with carefully designed loss terms and an adversarial module. It utilizes easy-to-acquire labels to learn from real-world shading, significantly improves performance with only minor additional annotation effort. We show that our proposed model significantly reduce texture-copying artifacts while retaining surprisingly tiny details, outperforming existing state-of-the-art methods.
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving
Aug 23, 2021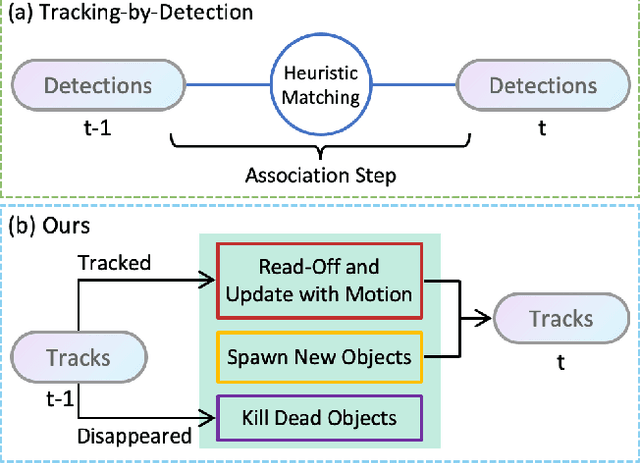
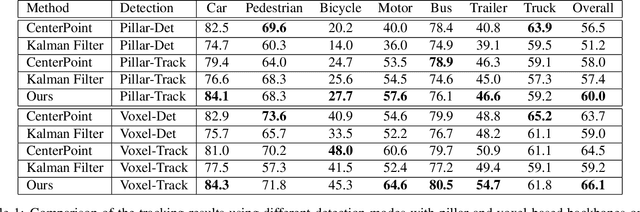
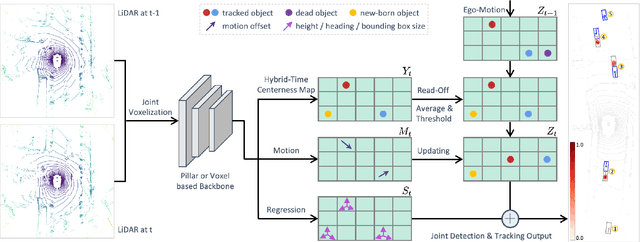

3D multi-object tracking in LiDAR point clouds is a key ingredient for self-driving vehicles. Existing methods are predominantly based on the tracking-by-detection pipeline and inevitably require a heuristic matching step for the detection association. In this paper, we present SimTrack to simplify the hand-crafted tracking paradigm by proposing an end-to-end trainable model for joint detection and tracking from raw point clouds. Our key design is to predict the first-appear location of each object in a given snippet to get the tracking identity and then update the location based on motion estimation. In the inference, the heuristic matching step can be completely waived by a simple read-off operation. SimTrack integrates the tracked object association, newborn object detection, and dead track killing in a single unified model. We conduct extensive evaluations on two large-scale datasets: nuScenes and Waymo Open Dataset. Experimental results reveal that our simple approach compares favorably with the state-of-the-art methods while ruling out the heuristic matching rules.
Neural Network Repair with Reachability Analysis
Aug 09, 2021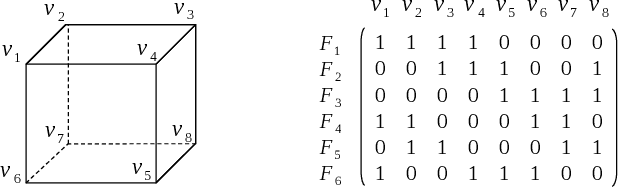

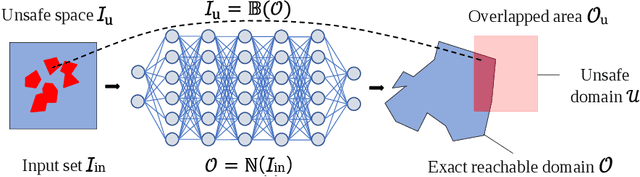
Safety is a critical concern for the next generation of autonomy that is likely to rely heavily on deep neural networks for perception and control. Formally verifying the safety and robustness of well-trained DNNs and learning-enabled systems under attacks, model uncertainties, and sensing errors is essential for safe autonomy. This research proposes a framework to repair unsafe DNNs in safety-critical systems with reachability analysis. The repair process is inspired by adversarial training which has demonstrated high effectiveness in improving the safety and robustness of DNNs. Different from traditional adversarial training approaches where adversarial examples are utilized from random attacks and may not be representative of all unsafe behaviors, our repair process uses reachability analysis to compute the exact unsafe regions and identify sufficiently representative examples to enhance the efficacy and efficiency of the adversarial training. The performance of our framework is evaluated on two types of benchmarks without safe models as references. One is a DNN controller for aircraft collision avoidance with access to training data. The other is a rocket lander where our framework can be seamlessly integrated with the well-known deep deterministic policy gradient (DDPG) reinforcement learning algorithm. The experimental results show that our framework can successfully repair all instances on multiple safety specifications with negligible performance degradation. In addition, to increase the computational and memory efficiency of the reachability analysis algorithm, we propose a depth-first-search algorithm that combines an existing exact analysis method with an over-approximation approach based on a new set representation. Experimental results show that our method achieves a five-fold improvement in runtime and a two-fold improvement in memory usage compared to exact analysis.
Reachability Analysis of Convolutional Neural Networks
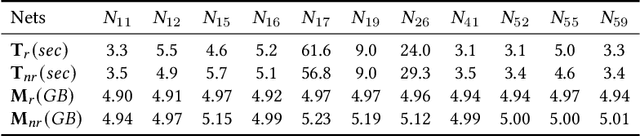
Jun 22, 2021

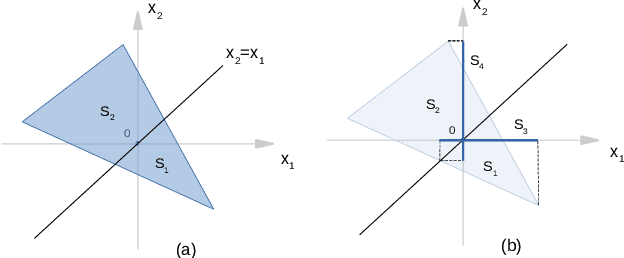
Deep convolutional neural networks have been widely employed as an effective technique to handle complex and practical problems. However, one of the fundamental problems is the lack of formal methods to analyze their behavior. To address this challenge, we propose an approach to compute the exact reachable sets of a network given an input domain, where the reachable set is represented by the face lattice structure. Besides the computation of reachable sets, our approach is also capable of backtracking to the input domain given an output reachable set. Therefore, a full analysis of a network's behavior can be realized. In addition, an approach for fast analysis is also introduced, which conducts fast computation of reachable sets by considering selected sensitive neurons in each layer. The exact pixel-level reachability analysis method is evaluated on a CNN for the CIFAR10 dataset and compared to related works. The fast analysis method is evaluated over a CNN CIFAR10 dataset and VGG16 architecture for the ImageNet dataset.
The 5th AI City Challenge
May 24, 2021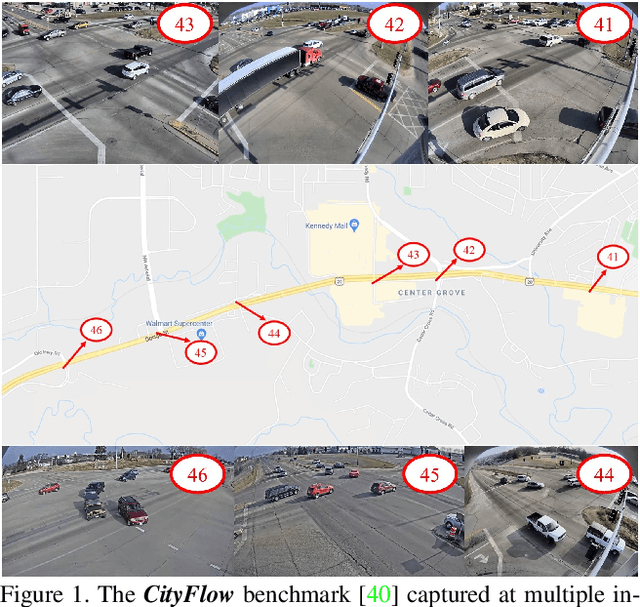
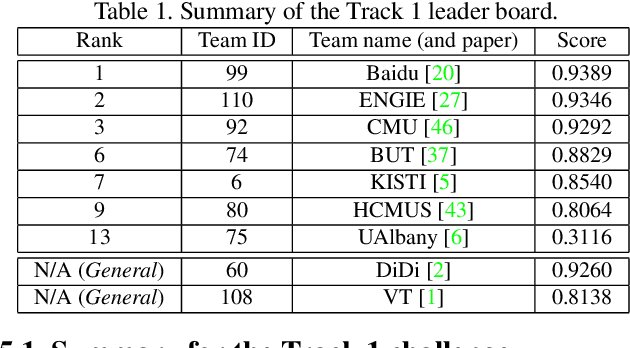
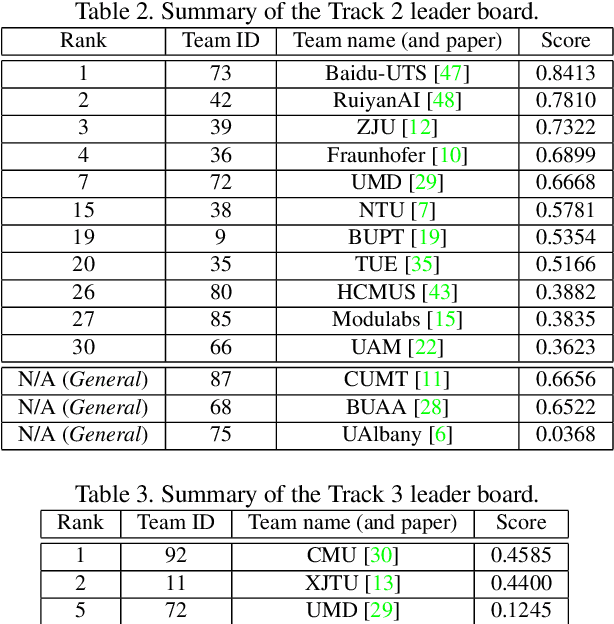
The AI City Challenge was created with two goals in mind: (1) pushing the boundaries of research and development in intelligent video analysis for smarter cities use cases, and (2) assessing tasks where the level of performance is enough to cause real-world adoption. Transportation is a segment ripe for such adoption. The fifth AI City Challenge attracted 305 participating teams across 38 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in five challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation being conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. Track 5 was a new track addressing vehicle retrieval using natural language descriptions. The evaluation system shows a general leader board of all submitted results, and a public leader board of results limited to the contest participation rules, where teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data is limited. Results show the promise of AI in Smarter Transportation. State-of-the-art performance for some tasks shows that these technologies are ready for adoption in real-world systems.