 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff$^2$I2P: Differentiable Image-to-Point Cloud Registration with Diffusion Prior
Jul 09, 2025Learning cross-modal correspondences is essential for image-to-point cloud (I2P) registration. Existing methods achieve this mostly by utilizing metric learning to enforce feature alignment across modalities, disregarding the inherent modality gap between image and point data. Consequently, this paradigm struggles to ensure accurate cross-modal correspondences. To this end, inspired by the cross-modal generation success of recent large diffusion models, we propose Diff$^2$I2P, a fully Differentiable I2P registration framework, leveraging a novel and effective Diffusion prior for bridging the modality gap. Specifically, we propose a Control-Side Score Distillation (CSD) technique to distill knowledge from a depth-conditioned diffusion model to directly optimize the predicted transformation. However, the gradients on the transformation fail to backpropagate onto the cross-modal features due to the non-differentiability of correspondence retrieval and PnP solver. To this end, we further propose a Deformable Correspondence Tuning (DCT) module to estimate the correspondences in a differentiable way, followed by the transformation estimation using a differentiable PnP solver. With these two designs, the Diffusion model serves as a strong prior to guide the cross-modal feature learning of image and point cloud for forming robust correspondences, which significantly improves the registration. Extensive experimental results demonstrate that Diff$^2$I2P consistently outperforms SoTA I2P registration methods, achieving over 7% improvement in registration recall on the 7-Scenes benchmark.
M2Restore: Mixture-of-Experts-based Mamba-CNN Fusion Framework for All-in-One Image Restoration
Jun 09, 2025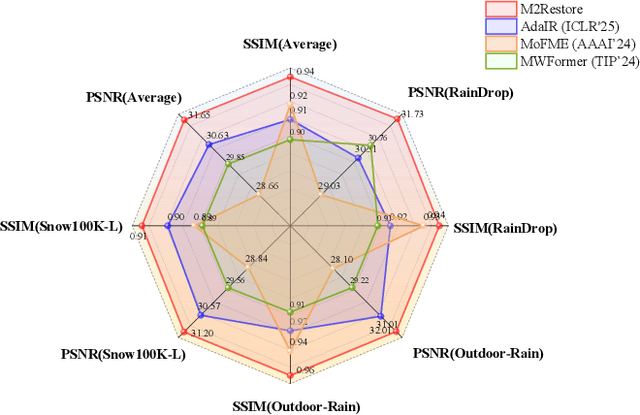
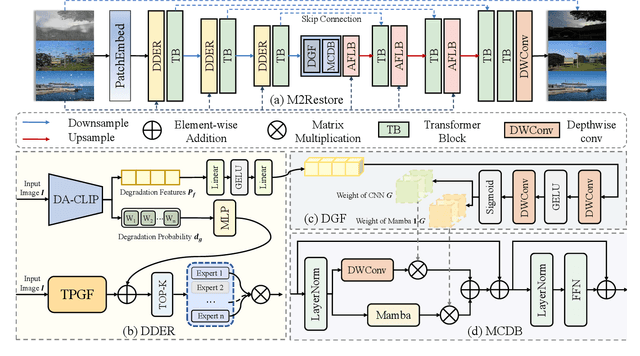
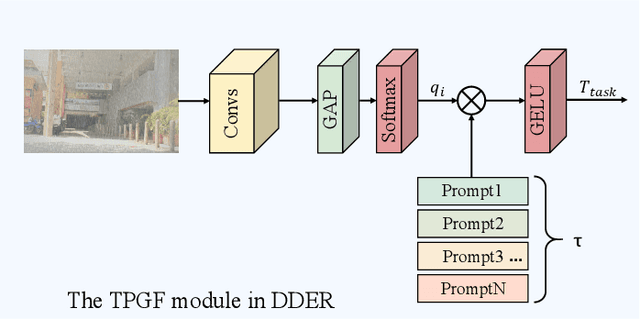

Natural images are often degraded by complex, composite degradations such as rain, snow, and haze, which adversely impact downstream vision applications. While existing image restoration efforts have achieved notable success, they are still hindered by two critical challenges: limited generalization across dynamically varying degradation scenarios and a suboptimal balance between preserving local details and modeling global dependencies. To overcome these challenges, we propose M2Restore, a novel Mixture-of-Experts (MoE)-based Mamba-CNN fusion framework for efficient and robust all-in-one image restoration. M2Restore introduces three key contributions: First, to boost the model's generalization across diverse degradation conditions, we exploit a CLIP-guided MoE gating mechanism that fuses task-conditioned prompts with CLIP-derived semantic priors. This mechanism is further refined via cross-modal feature calibration, which enables precise expert selection for various degradation types. Second, to jointly capture global contextual dependencies and fine-grained local details, we design a dual-stream architecture that integrates the localized representational strength of CNNs with the long-range modeling efficiency of Mamba. This integration enables collaborative optimization of global semantic relationships and local structural fidelity, preserving global coherence while enhancing detail restoration. Third, we introduce an edge-aware dynamic gating mechanism that adaptively balances global modeling and local enhancement by reallocating computational attention to degradation-sensitive regions. This targeted focus leads to more efficient and precise restoration. Extensive experiments across multiple image restoration benchmarks validate the superiority of M2Restore in both visual quality and quantitative performance.
Beyond Identity: A Generalizable Approach for Deepfake Audio Detection
May 10, 2025



Deepfake audio presents a growing threat to digital security, due to its potential for social engineering, fraud, and identity misuse. However, existing detection models suffer from poor generalization across datasets, due to implicit identity leakage, where models inadvertently learn speaker-specific features instead of manipulation artifacts. To the best of our knowledge, this is the first study to explicitly analyze and address identity leakage in the audio deepfake detection domain. This work proposes an identity-independent audio deepfake detection framework that mitigates identity leakage by encouraging the model to focus on forgery-specific artifacts instead of overfitting to speaker traits. Our approach leverages Artifact Detection Modules (ADMs) to isolate synthetic artifacts in both time and frequency domains, enhancing cross-dataset generalization. We introduce novel dynamic artifact generation techniques, including frequency domain swaps, time domain manipulations, and background noise augmentation, to enforce learning of dataset-invariant features. Extensive experiments conducted on ASVspoof2019, ADD 2022, FoR, and In-The-Wild datasets demonstrate that the proposed ADM-enhanced models achieve F1 scores of 0.230 (ADD 2022), 0.604 (FoR), and 0.813 (In-The-Wild), consistently outperforming the baseline. Dynamic Frequency Swap proves to be the most effective strategy across diverse conditions. These findings emphasize the value of artifact-based learning in mitigating implicit identity leakage for more generalizable audio deepfake detection.
WDMamba: When Wavelet Degradation Prior Meets Vision Mamba for Image Dehazing
May 07, 2025In this paper, we reveal a novel haze-specific wavelet degradation prior observed through wavelet transform analysis, which shows that haze-related information predominantly resides in low-frequency components. Exploiting this insight, we propose a novel dehazing framework, WDMamba, which decomposes the image dehazing task into two sequential stages: low-frequency restoration followed by detail enhancement. This coarse-to-fine strategy enables WDMamba to effectively capture features specific to each stage of the dehazing process, resulting in high-quality restored images. Specifically, in the low-frequency restoration stage, we integrate Mamba blocks to reconstruct global structures with linear complexity, efficiently removing overall haze and producing a coarse restored image. Thereafter, the detail enhancement stage reinstates fine-grained information that may have been overlooked during the previous phase, culminating in the final dehazed output. Furthermore, to enhance detail retention and achieve more natural dehazing, we introduce a self-guided contrastive regularization during network training. By utilizing the coarse restored output as a hard negative example, our model learns more discriminative representations, substantially boosting the overall dehazing performance. Extensive evaluations on public dehazing benchmarks demonstrate that our method surpasses state-of-the-art approaches both qualitatively and quantitatively. Code is available at https://github.com/SunJ000/WDMamba.
VTire: A Bimodal Visuotactile Tire with High-Resolution Sensing Capability
Apr 27, 2025Developing smart tires with high sensing capability is significant for improving the moving stability and environmental adaptability of wheeled robots and vehicles. However, due to the classical manufacturing design, it is always challenging for tires to infer external information precisely. To this end, this paper introduces a bimodal sensing tire, which can simultaneously capture tactile and visual data. By leveraging the emerging visuotactile techniques, the proposed smart tire can realize various functions, including terrain recognition, ground crack detection, load sensing, and tire damage detection. Besides, we optimize the material and structure of the tire to ensure its outstanding elasticity, toughness, hardness, and transparency. In terms of algorithms, a transformer-based multimodal classification algorithm, a load detection method based on finite element analysis, and a contact segmentation algorithm have been developed. Furthermore, we construct an intelligent mobile platform to validate the system's effectiveness and develop visual and tactile datasets in complex terrains. The experimental results show that our multimodal terrain sensing algorithm can achieve a classification accuracy of 99.2\%, a tire damage detection accuracy of 97\%, a 98\% success rate in object search, and the ability to withstand tire loading weights exceeding 35 kg. In addition, we open-source our algorithms, hardware, and datasets at https://sites.google.com/view/vtire.
A Novel Radar Constant False Alarm Rate Detection Algorithm Based on VAMP Deep Unfolding
Apr 14, 2025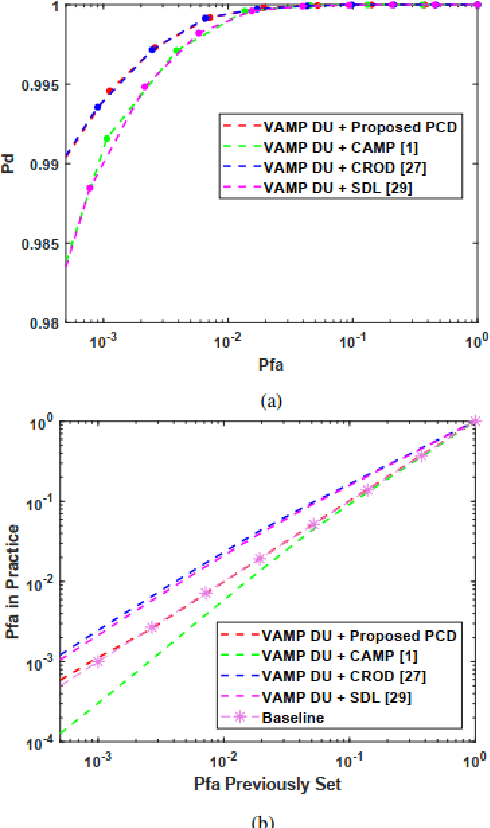
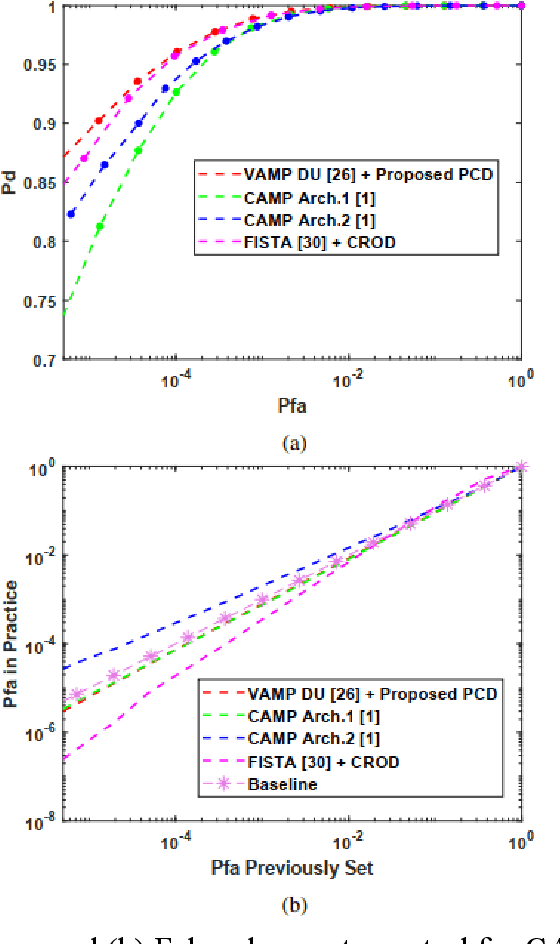
The combination of deep unfolding with vector approximate message passing (VAMP) algorithm, results in faster convergence and higher sparse recovery accuracy than traditional compressive sensing approaches. However, deep unfolding alters the parameters in traditional VAMP algorithm, resulting in the unattainable distribution parameter of the recovery error of non-sparse noisy estimation via traditional VAMP, which hinders the utilization of VAMP deep unfolding in constant false alarm rate (CFAR) detection in sub-Nyquist radar system. Based on VAMP deep unfolding, we provide a parameter convergence detector (PCD) to estimate the recovery error distribution parameter and implement CFAR detection. Compared to the state-of-the-art approaches, both the sparse solution and non-sparse noisy estimation are utilized to estimate the distribution parameter and implement CFAR detection in PCD, which leverages both the VAMP distribution property and the improved sparse recovery accuracy provided by deep unfolding. Simulation results indicate that PCD offers improved false alarm rate control performance and higher target detection rate.
Parameter Convergence Detector Based on VAMP Deep Unfolding: A Novel Radar Constant False Alarm Rate Detection Algorithm
Apr 14, 2025The sub-Nyquist radar framework exploits the sparsity of signals, which effectively alleviates the pressure on system storage and transmission bandwidth. Compressed sensing (CS) algorithms, such as the VAMP algorithm, are used for sparse signal processing in the sub-Nyquist radar framework. By combining deep unfolding techniques with VAMP, faster convergence and higher accuracy than traditional CS algorithms are achieved. However, deep unfolding disrupts the parameter constrains in traditional VAMP algorithm, leading to the distribution of non-sparse noisy estimation in VAMP deep unfolding unknown, and its distribution parameter unable to be obtained directly using method of traditional VAMP, which prevents the application of VAMP deep unfolding in radar constant false alarm rate (CFAR) detection. To address this problem, we explore the distribution of the non-sparse noisy estimation and propose a parameter convergence detector (PCD) to achieve CFAR detection based on VAMP deep unfolding. Compared to the state-of-the-art methods, PCD leverages not only the sparse solution, but also the non-sparse noisy estimation, which is used to iteratively estimate the distribution parameter and served as the test statistic in detection process. In this way, the proposed algorithm takes advantage of both the enhanced sparse recovery accuracy from deep unfolding and the distribution property of VAMP, thereby achieving superior CFAR detection performance. Additionally, the PCD requires no information about the power of AWGN in the environment, which is more suitable for practical application. The convergence performance and effectiveness of the proposed PCD are analyzed based on the Banach Fixed-Point Theorem. Numerical simulations and practical data experiments demonstrate that PCD can achieve better false alarm control and target detection performance.
DA2Diff: Exploring Degradation-aware Adaptive Diffusion Priors for All-in-One Weather Restoration
Apr 07, 2025



Image restoration under adverse weather conditions is a critical task for many vision-based applications. Recent all-in-one frameworks that handle multiple weather degradations within a unified model have shown potential. However, the diversity of degradation patterns across different weather conditions, as well as the complex and varied nature of real-world degradations, pose significant challenges for multiple weather removal. To address these challenges, we propose an innovative diffusion paradigm with degradation-aware adaptive priors for all-in-one weather restoration, termed DA2Diff. It is a new exploration that applies CLIP to perceive degradation-aware properties for better multi-weather restoration. Specifically, we deploy a set of learnable prompts to capture degradation-aware representations by the prompt-image similarity constraints in the CLIP space. By aligning the snowy/hazy/rainy images with snow/haze/rain prompts, each prompt contributes to different weather degradation characteristics. The learned prompts are then integrated into the diffusion model via the designed weather specific prompt guidance module, making it possible to restore multiple weather types. To further improve the adaptiveness to complex weather degradations, we propose a dynamic expert selection modulator that employs a dynamic weather-aware router to flexibly dispatch varying numbers of restoration experts for each weather-distorted image, allowing the diffusion model to restore diverse degradations adaptively. Experimental results substantiate the favorable performance of DA2Diff over state-of-the-arts in quantitative and qualitative evaluation. Source code will be available after acceptance.
Z1: Efficient Test-time Scaling with Code
Apr 01, 2025



Large Language Models (LLMs) can achieve enhanced complex problem-solving through test-time computing scaling, yet this often entails longer contexts and numerous reasoning token costs. In this paper, we propose an efficient test-time scaling method that trains LLMs on code-related reasoning trajectories, facilitating their reduction of excess thinking tokens while maintaining performance. First, we create Z1-Code-Reasoning-107K, a curated dataset of simple and complex coding problems paired with their short and long solution trajectories. Second, we present a novel Shifted Thinking Window to mitigate overthinking overhead by removing context-delimiting tags (e.g., <think>. . . </think>) and capping reasoning tokens. Trained with long and short trajectory data and equipped with Shifted Thinking Window, our model, Z1-7B, demonstrates the ability to adjust its reasoning level as the complexity of problems and exhibits efficient test-time scaling across different reasoning tasks that matches R1-Distill-Qwen-7B performance with about 30% of its average thinking tokens. Notably, fine-tuned with only code trajectories, Z1-7B demonstrates generalization to broader reasoning tasks (47.5% on GPQA Diamond). Our analysis of efficient reasoning elicitation also provides valuable insights for future research.
Open3DVQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space
Mar 14, 2025Spatial reasoning is a fundamental capability of embodied agents and has garnered widespread attention in the field of multimodal large language models (MLLMs). In this work, we propose a novel benchmark, Open3DVQA, to comprehensively evaluate the spatial reasoning capacities of current state-of-the-art (SOTA) foundation models in open 3D space. Open3DVQA consists of 9k VQA samples, collected using an efficient semi-automated tool in a high-fidelity urban simulator. We evaluate several SOTA MLLMs across various aspects of spatial reasoning, such as relative and absolute spatial relationships, situational reasoning, and object-centric spatial attributes. Our results reveal that: 1) MLLMs perform better at answering questions regarding relative spatial relationships than absolute spatial relationships, 2) MLLMs demonstrate similar spatial reasoning abilities for both egocentric and allocentric perspectives, and 3) Fine-tuning large models significantly improves their performance across different spatial reasoning tasks. We believe that our open-source data collection tools and in-depth analyses will inspire further research on MLLM spatial reasoning capabilities. The benchmark is available at https://github.com/WeichenZh/Open3DVQA.