 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvertible Sharpening Network for MRI Reconstruction Enhancement
Jun 06, 2022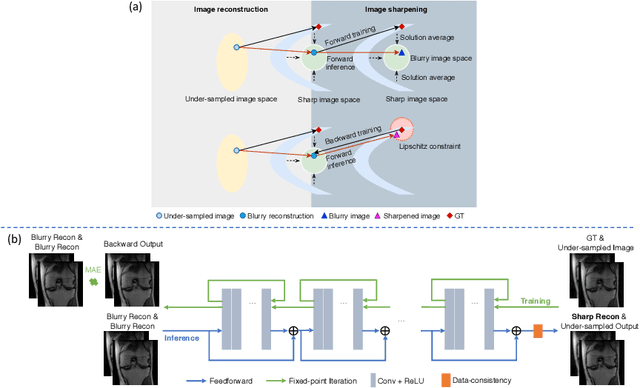

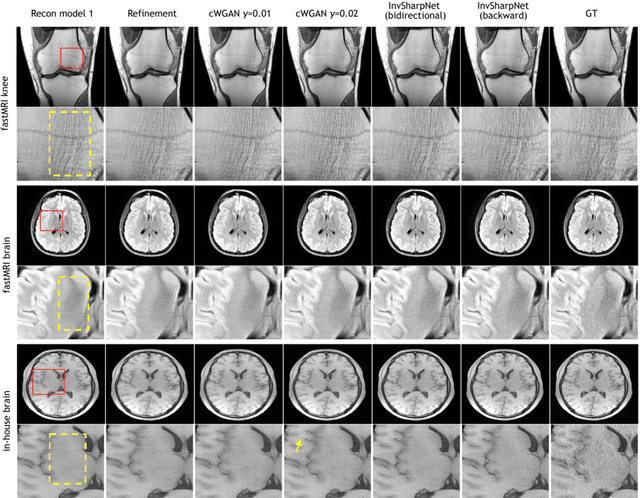

High-quality MRI reconstruction plays a critical role in clinical applications. Deep learning-based methods have achieved promising results on MRI reconstruction. However, most state-of-the-art methods were designed to optimize the evaluation metrics commonly used for natural images, such as PSNR and SSIM, whereas the visual quality is not primarily pursued. Compared to the fully-sampled images, the reconstructed images are often blurry, where high-frequency features might not be sharp enough for confident clinical diagnosis. To this end, we propose an invertible sharpening network (InvSharpNet) to improve the visual quality of MRI reconstructions. During training, unlike the traditional methods that learn to map the input data to the ground truth, InvSharpNet adapts a backward training strategy that learns a blurring transform from the ground truth (fully-sampled image) to the input data (blurry reconstruction). During inference, the learned blurring transform can be inverted to a sharpening transform leveraging the network's invertibility. The experiments on various MRI datasets demonstrate that InvSharpNet can improve reconstruction sharpness with few artifacts. The results were also evaluated by radiologists, indicating better visual quality and diagnostic confidence of our proposed method.
EGR: Equivariant Graph Refinement and Assessment of 3D Protein Complex Structures
May 24, 2022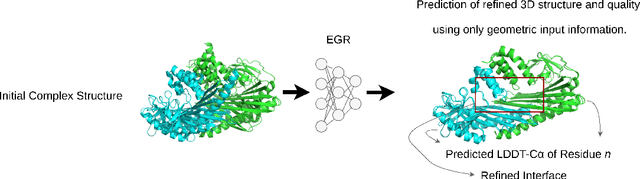
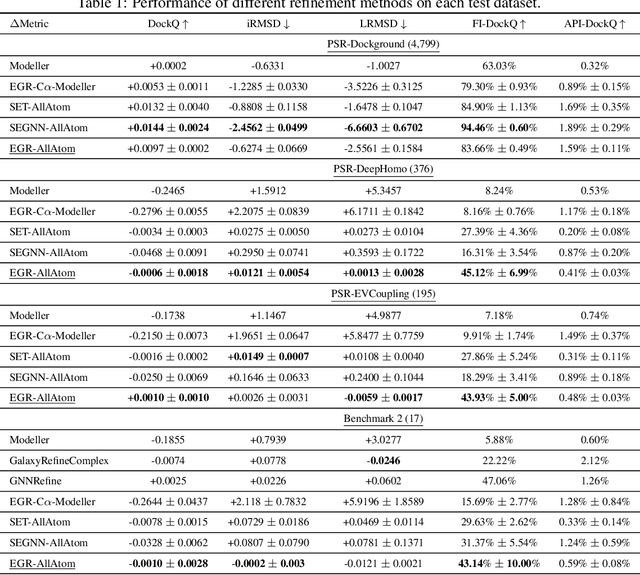
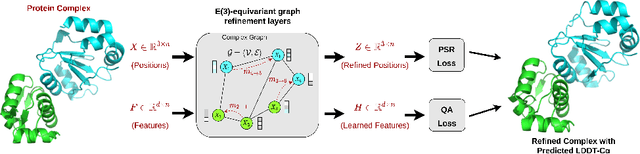
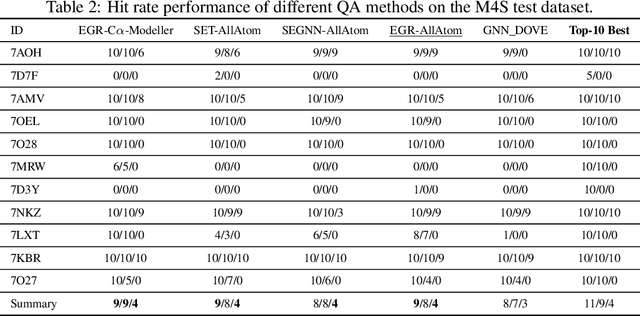
Protein complexes are macromolecules essential to the functioning and well-being of all living organisms. As the structure of a protein complex, in particular its region of interaction between multiple protein subunits (i.e., chains), has a notable influence on the biological function of the complex, computational methods that can quickly and effectively be used to refine and assess the quality of a protein complex's 3D structure can directly be used within a drug discovery pipeline to accelerate the development of new therapeutics and improve the efficacy of future vaccines. In this work, we introduce the Equivariant Graph Refiner (EGR), a novel E(3)-equivariant graph neural network (GNN) for multi-task structure refinement and assessment of protein complexes. Our experiments on new, diverse protein complex datasets, all of which we make publicly available in this work, demonstrate the state-of-the-art effectiveness of EGR for atomistic refinement and assessment of protein complexes and outline directions for future work in the field. In doing so, we establish a baseline for future studies in macromolecular refinement and structure analysis.
DProQ: A Gated-Graph Transformer for Protein Complex Structure Assessment
May 21, 2022



Proteins interact to form complexes to carry out essential biological functions. Computational methods have been developed to predict the structures of protein complexes. However, an important challenge in protein complex structure prediction is to estimate the quality of predicted protein complex structures without any knowledge of the corresponding native structures. Such estimations can then be used to select high-quality predicted complex structures to facilitate biomedical research such as protein function analysis and drug discovery. We challenge this significant task with DProQ, which introduces a gated neighborhood-modulating Graph Transformer (GGT) designed to predict the quality of 3D protein complex structures. Notably, we incorporate node and edge gates within a novel Graph Transformer framework to control information flow during graph message passing. We train and evaluate DProQ on four newly-developed datasets that we make publicly available in this work. Our rigorous experiments demonstrate that DProQ achieves state-of-the-art performance in ranking protein complex structures.
DeepFD: Automated Fault Diagnosis and Localization for Deep Learning Programs
May 04, 2022
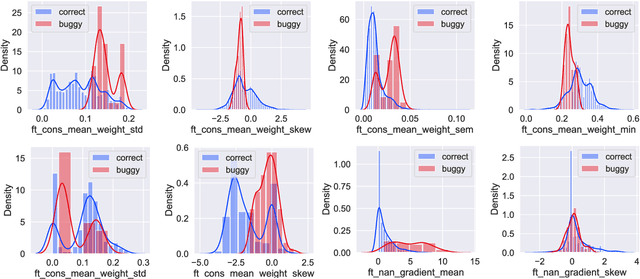

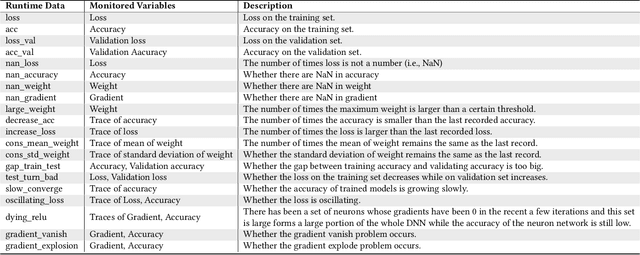
As Deep Learning (DL) systems are widely deployed for mission-critical applications, debugging such systems becomes essential. Most existing works identify and repair suspicious neurons on the trained Deep Neural Network (DNN), which, unfortunately, might be a detour. Specifically, several existing studies have reported that many unsatisfactory behaviors are actually originated from the faults residing in DL programs. Besides, locating faulty neurons is not actionable for developers, while locating the faulty statements in DL programs can provide developers with more useful information for debugging. Though a few recent studies were proposed to pinpoint the faulty statements in DL programs or the training settings (e.g. too large learning rate), they were mainly designed based on predefined rules, leading to many false alarms or false negatives, especially when the faults are beyond their capabilities. In view of these limitations, in this paper, we proposed DeepFD, a learning-based fault diagnosis and localization framework which maps the fault localization task to a learning problem. In particular, it infers the suspicious fault types via monitoring the runtime features extracted during DNN model training and then locates the diagnosed faults in DL programs. It overcomes the limitations by identifying the root causes of faults in DL programs instead of neurons and diagnosing the faults by a learning approach instead of a set of hard-coded rules. The evaluation exhibits the potential of DeepFD. It correctly diagnoses 52% faulty DL programs, compared with around half (27%) achieved by the best state-of-the-art works. Besides, for fault localization, DeepFD also outperforms the existing works, correctly locating 42% faulty programs, which almost doubles the best result (23%) achieved by the existing works.
Constructing dynamic residential energy lifestyles using Latent Dirichlet Allocation
Apr 22, 2022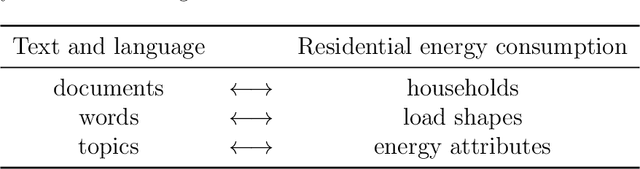
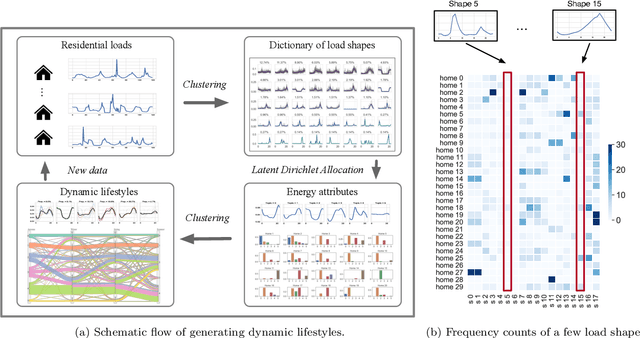
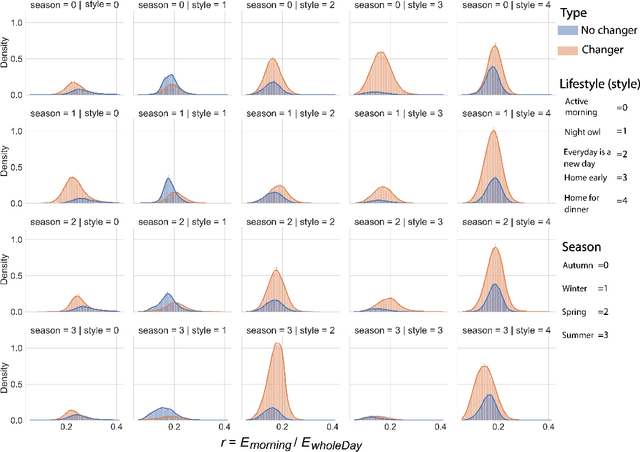
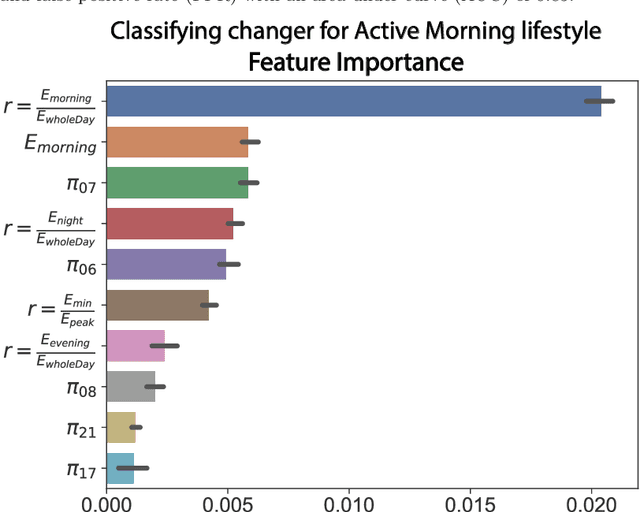
The rapid expansion of Advanced Meter Infrastructure (AMI) has dramatically altered the energy information landscape. However, our ability to use this information to generate actionable insights about residential electricity demand remains limited. In this research, we propose and test a new framework for understanding residential electricity demand by using a dynamic energy lifestyles approach that is iterative and highly extensible. To obtain energy lifestyles, we develop a novel approach that applies Latent Dirichlet Allocation (LDA), a method commonly used for inferring the latent topical structure of text data, to extract a series of latent household energy attributes. By doing so, we provide a new perspective on household electricity consumption where each household is characterized by a mixture of energy attributes that form the building blocks for identifying a sparse collection of energy lifestyles. We examine this approach by running experiments on one year of hourly smart meter data from 60,000 households and we extract six energy attributes that describe general daily use patterns. We then use clustering techniques to derive six distinct energy lifestyle profiles from energy attribute proportions. Our lifestyle approach is also flexible to varying time interval lengths, and we test our lifestyle approach seasonally (Autumn, Winter, Spring, and Summer) to track energy lifestyle dynamics within and across households and find that around 73% of households manifest multiple lifestyles across a year. These energy lifestyles are then compared to different energy use characteristics, and we discuss their practical applications for demand response program design and lifestyle change analysis.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022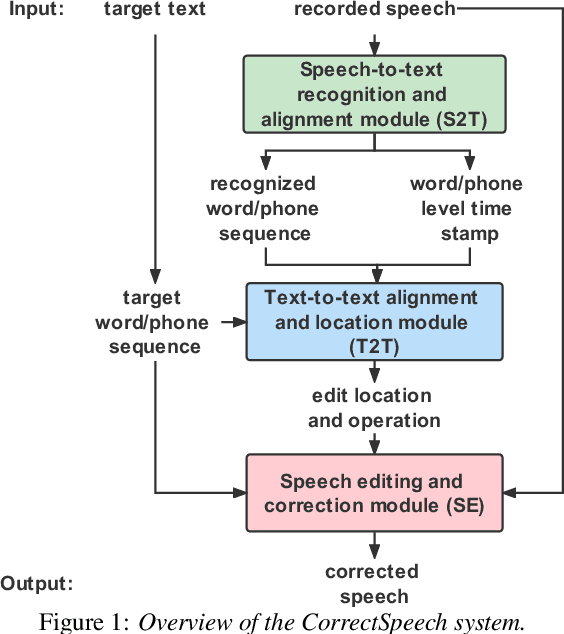
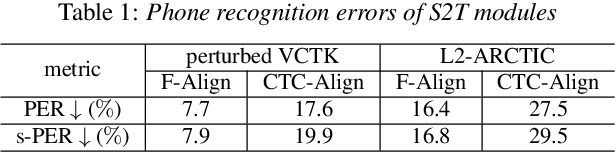
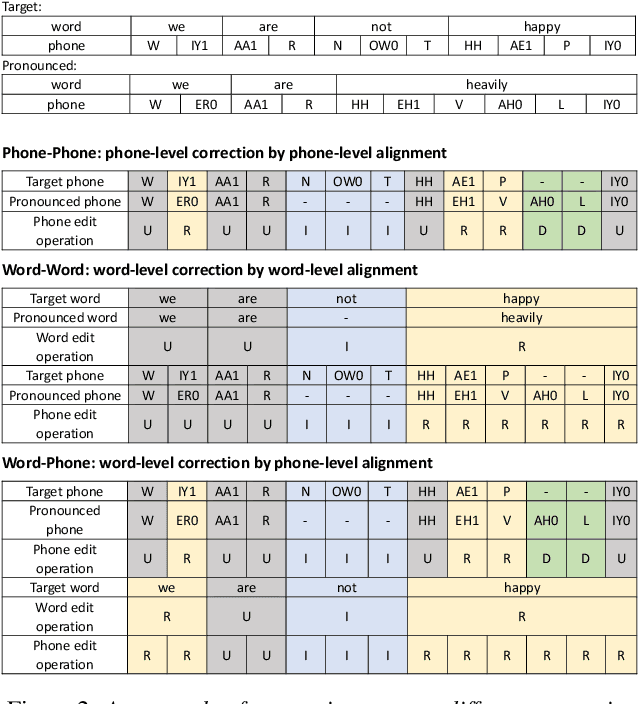
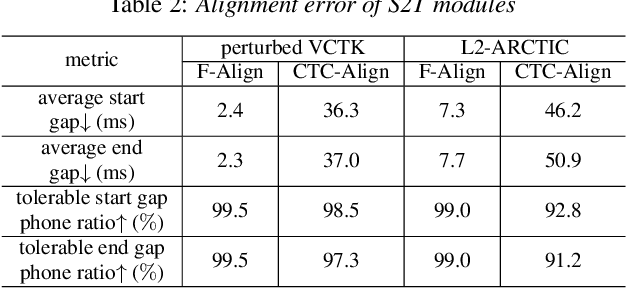
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
Accelerating Representation Learning with View-Consistent Dynamics in Data-Efficient Reinforcement Learning
Jan 18, 2022



Learning informative representations from image-based observations is of fundamental concern in deep Reinforcement Learning (RL). However, data-inefficiency remains a significant barrier to this objective. To overcome this obstacle, we propose to accelerate state representation learning by enforcing view-consistency on the dynamics. Firstly, we introduce a formalism of Multi-view Markov Decision Process (MMDP) that incorporates multiple views of the state. Following the structure of MMDP, our method, View-Consistent Dynamics (VCD), learns state representations by training a view-consistent dynamics model in the latent space, where views are generated by applying data augmentation to states. Empirical evaluation on DeepMind Control Suite and Atari-100k demonstrates VCD to be the SoTA data-efficient algorithm on visual control tasks.
bert2BERT: Towards Reusable Pretrained Language Models
Oct 14, 2021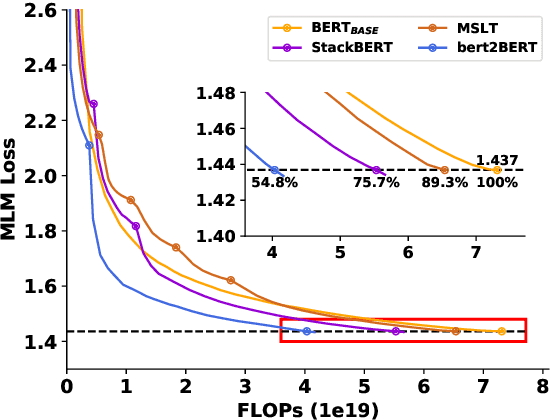
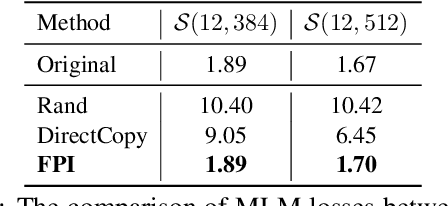
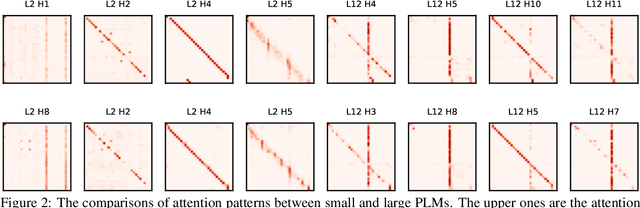
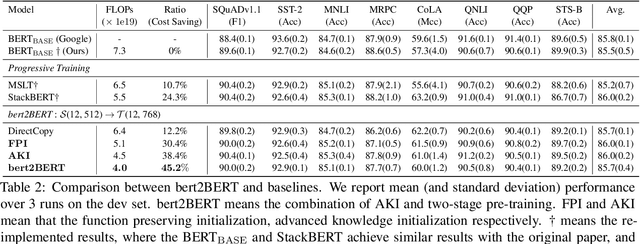
In recent years, researchers tend to pre-train ever-larger language models to explore the upper limit of deep models. However, large language model pre-training costs intensive computational resources and most of the models are trained from scratch without reusing the existing pre-trained models, which is wasteful. In this paper, we propose bert2BERT, which can effectively transfer the knowledge of an existing smaller pre-trained model (e.g., BERT_BASE) to a large model (e.g., BERT_LARGE) through parameter initialization and significantly improve the pre-training efficiency of the large model. Specifically, we extend the previous function-preserving on Transformer-based language model, and further improve it by proposing advanced knowledge for large model's initialization. In addition, a two-stage pre-training method is proposed to further accelerate the training process. We did extensive experiments on representative PLMs (e.g., BERT and GPT) and demonstrate that (1) our method can save a significant amount of training cost compared with baselines including learning from scratch, StackBERT and MSLT; (2) our method is generic and applicable to different types of pre-trained models. In particular, bert2BERT saves about 45% and 47% computational cost of pre-training BERT_BASE and GPT_BASE by reusing the models of almost their half sizes. The source code will be publicly available upon publication.
Efficient, Interpretable Atomistic Graph Neural Network Representation for Angle-dependent Properties and its Application to Optical Spectroscopy Prediction
Sep 23, 2021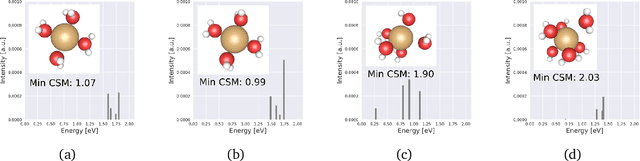

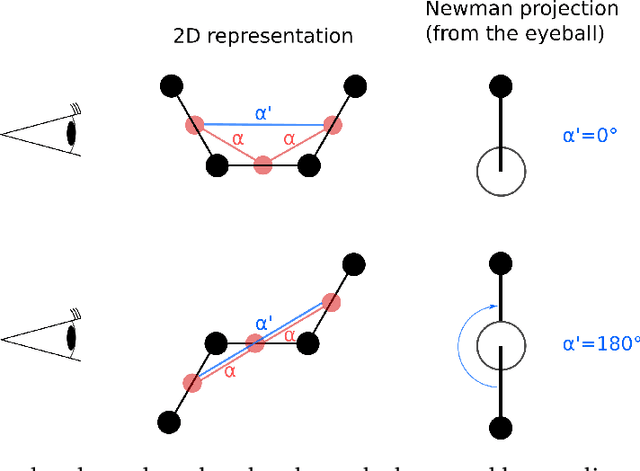

Graph neural networks (GNNs) are attractive for learning properties of atomic structures thanks to their intuitive, physically informed graph encoding of atoms and bonds. However, conventional GNN encodings do not account for angular information, which is critical for describing complex atomic arrangements in disordered materials, interfaces, and molecular distortions. In this work, we extend the recently proposed ALIGNN encoding, which incorporates bond angles, to also include dihedral angles (ALIGNN-d), and we apply the model to capture the structures of aqua copper complexes for spectroscopy prediction. This simple extension is shown to lead to a memory-efficient graph representation capable of capturing the full geometric information of atomic structures. Specifically, the ALIGNN-d encoding is a sparse yet equally expressive representation compared to the dense, maximally-connected graph, in which all bonds are encoded. We also explore model interpretability based on ALIGNN-d by elucidating the relative contributions of individual structural components to the optical response of the copper complexes. Lastly, we briefly discuss future developments to validate the computational efficiency and to extend the interpretability of ALIGNN-d.
DyLex: Incorporating Dynamic Lexicons into BERT for Sequence Labeling
Sep 22, 2021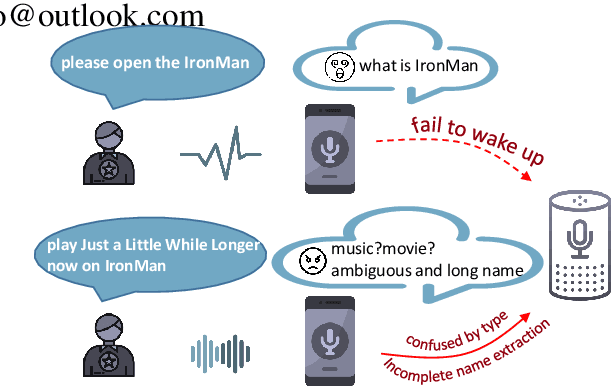

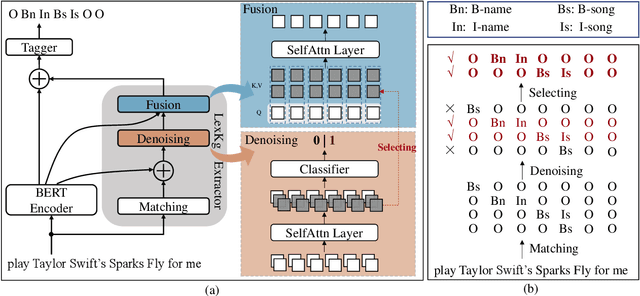
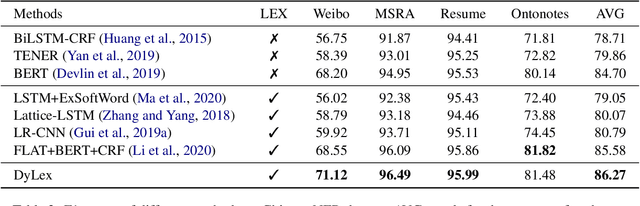
Incorporating lexical knowledge into deep learning models has been proved to be very effective for sequence labeling tasks. However, previous works commonly have difficulty dealing with large-scale dynamic lexicons which often cause excessive matching noise and problems of frequent updates. In this paper, we propose DyLex, a plug-in lexicon incorporation approach for BERT based sequence labeling tasks. Instead of leveraging embeddings of words in the lexicon as in conventional methods, we adopt word-agnostic tag embeddings to avoid re-training the representation while updating the lexicon. Moreover, we employ an effective supervised lexical knowledge denoising method to smooth out matching noise. Finally, we introduce a col-wise attention based knowledge fusion mechanism to guarantee the pluggability of the proposed framework. Experiments on ten datasets of three tasks show that the proposed framework achieves new SOTA, even with very large scale lexicons.