 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDProxy: Cold-Start CTR Prediction for Ads and Recommendation at Xiaohongshu with Multimodal LLMs
Mar 02, 2026Click-through rate (CTR) models in advertising and recommendation systems rely heavily on item ID embeddings, which struggle in item cold-start settings. We present IDProxy, a solution that leverages multimodal large language models (MLLMs) to generate proxy embeddings from rich content signals, enabling effective CTR prediction for new items without usage data. These proxies are explicitly aligned with the existing ID embedding space and are optimized end-to-end under CTR objectives together with the ranking model, allowing seamless integration into existing large-scale ranking pipelines. Offline experiments and online A/B tests demonstrate the effectiveness of IDProxy, which has been successfully deployed in both Content Feed and Display Ads features of Xiaohongshu's Explore Feed, serving hundreds of millions of users daily.
A Metric for MLLM Alignment in Large-scale Recommendation
Aug 07, 2025



Multimodal recommendation has emerged as a critical technique in modern recommender systems, leveraging content representations from advanced multimodal large language models (MLLMs). To ensure these representations are well-adapted, alignment with the recommender system is essential. However, evaluating the alignment of MLLMs for recommendation presents significant challenges due to three key issues: (1) static benchmarks are inaccurate because of the dynamism in real-world applications, (2) evaluations with online system, while accurate, are prohibitively expensive at scale, and (3) conventional metrics fail to provide actionable insights when learned representations underperform. To address these challenges, we propose the Leakage Impact Score (LIS), a novel metric for multimodal recommendation. Rather than directly assessing MLLMs, LIS efficiently measures the upper bound of preference data. We also share practical insights on deploying MLLMs with LIS in real-world scenarios. Online A/B tests on both Content Feed and Display Ads of Xiaohongshu's Explore Feed production demonstrate the effectiveness of our proposed method, showing significant improvements in user spent time and advertiser value.
Enhancing Fine-Grained Visual Recognition in the Low-Data Regime Through Feature Magnitude Regularization
Sep 03, 2024



Training a fine-grained image recognition model with limited data presents a significant challenge, as the subtle differences between categories may not be easily discernible amidst distracting noise patterns. One commonly employed strategy is to leverage pretrained neural networks, which can generate effective feature representations for constructing an image classification model with a restricted dataset. However, these pretrained neural networks are typically trained for different tasks than the fine-grained visual recognition (FGVR) task at hand, which can lead to the extraction of less relevant features. Moreover, in the context of building FGVR models with limited data, these irrelevant features can dominate the training process, overshadowing more useful, generalizable discriminative features. Our research has identified a surprisingly simple solution to this challenge: we introduce a regularization technique to ensure that the magnitudes of the extracted features are evenly distributed. This regularization is achieved by maximizing the uniformity of feature magnitude distribution, measured through the entropy of the normalized features. The motivation behind this regularization is to remove bias in feature magnitudes from pretrained models, where some features may be more prominent and, consequently, more likely to be used for classification. Additionally, we have developed a dynamic weighting mechanism to adjust the strength of this regularization throughout the learning process. Despite its apparent simplicity, our approach has demonstrated significant performance improvements across various fine-grained visual recognition datasets.
MuseBarControl: Enhancing Fine-Grained Control in Symbolic Music Generation through Pre-Training and Counterfactual Loss
Jul 05, 2024



Automatically generating symbolic music-music scores tailored to specific human needs-can be highly beneficial for musicians and enthusiasts. Recent studies have shown promising results using extensive datasets and advanced transformer architectures. However, these state-of-the-art models generally offer only basic control over aspects like tempo and style for the entire composition, lacking the ability to manage finer details, such as control at the level of individual bars. While fine-tuning a pre-trained symbolic music generation model might seem like a straightforward method for achieving this finer control, our research indicates challenges in this approach. The model often fails to respond adequately to new, fine-grained bar-level control signals. To address this, we propose two innovative solutions. First, we introduce a pre-training task designed to link control signals directly with corresponding musical tokens, which helps in achieving a more effective initialization for subsequent fine-tuning. Second, we implement a novel counterfactual loss that promotes better alignment between the generated music and the control prompts. Together, these techniques significantly enhance our ability to control music generation at the bar level, showing a 13.06\% improvement over conventional methods. Our subjective evaluations also confirm that this enhanced control does not compromise the musical quality of the original pre-trained generative model.
A Simple-but-effective Baseline for Training-free Class-Agnostic Counting
Mar 03, 2024



Class-Agnostic Counting (CAC) seeks to accurately count objects in a given image with only a few reference examples. While previous methods achieving this relied on additional training, recent efforts have shown that it's possible to accomplish this without training by utilizing pre-existing foundation models, particularly the Segment Anything Model (SAM), for counting via instance-level segmentation. Although promising, current training-free methods still lag behind their training-based counterparts in terms of performance. In this research, we present a straightforward training-free solution that effectively bridges this performance gap, serving as a strong baseline. The primary contribution of our work lies in the discovery of four key technologies that can enhance performance. Specifically, we suggest employing a superpixel algorithm to generate more precise initial point prompts, utilizing an image encoder with richer semantic knowledge to replace the SAM encoder for representing candidate objects, and adopting a multiscale mechanism and a transductive prototype scheme to update the representation of reference examples. By combining these four technologies, our approach achieves significant improvements over existing training-free methods and delivers performance on par with training-based ones.
Revisiting Image Reconstruction for Semi-supervised Semantic Segmentation
Mar 17, 2023



Autoencoding, which aims to reconstruct the input images through a bottleneck latent representation, is one of the classic feature representation learning strategies. It has been shown effective as an auxiliary task for semi-supervised learning but has become less popular as more sophisticated methods have been proposed in recent years. In this paper, we revisit the idea of using image reconstruction as the auxiliary task and incorporate it with a modern semi-supervised semantic segmentation framework. Surprisingly, we discover that such an old idea in semi-supervised learning can produce results competitive with state-of-the-art semantic segmentation algorithms. By visualizing the intermediate layer activations of the image reconstruction module, we show that the feature map channel could correlate well with the semantic concept, which explains why joint training with the reconstruction task is helpful for the segmentation task. Motivated by our observation, we further proposed a modification to the image reconstruction task, aiming to further disentangle the object clue from the background patterns. From experiment evaluation on various datasets, we show that using reconstruction as auxiliary loss can lead to consistent improvements in various datasets and methods. The proposed method can further lead to significant improvement in object-centric segmentation tasks.
Improving Fine-Grained Visual Recognition in Low Data Regimes via Self-Boosting Attention Mechanism
Aug 01, 2022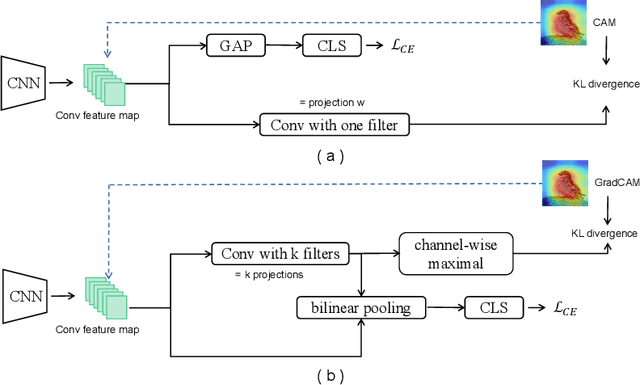
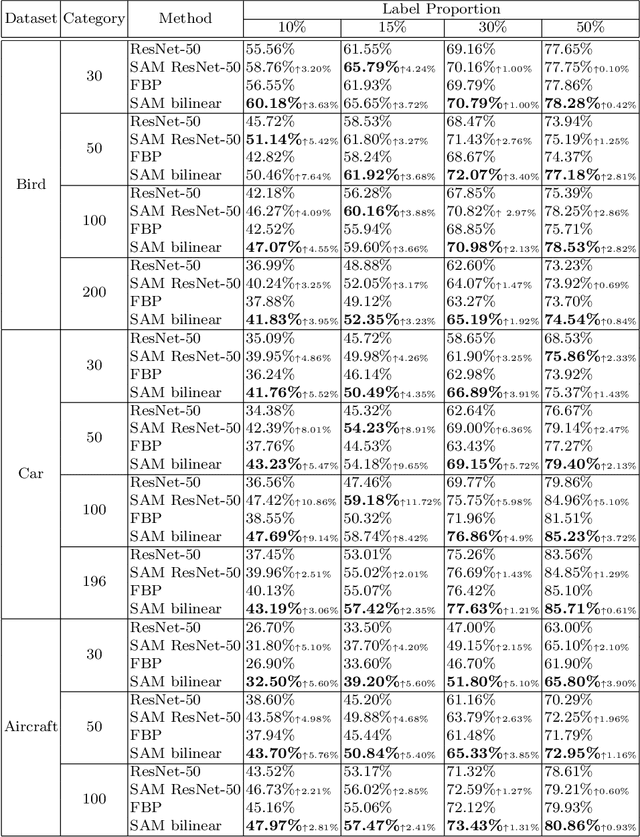
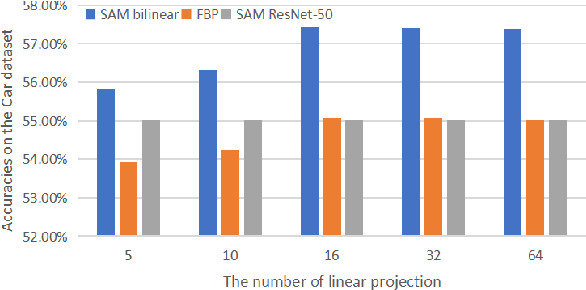
The challenge of fine-grained visual recognition often lies in discovering the key discriminative regions. While such regions can be automatically identified from a large-scale labeled dataset, a similar method might become less effective when only a few annotations are available. In low data regimes, a network often struggles to choose the correct regions for recognition and tends to overfit spurious correlated patterns from the training data. To tackle this issue, this paper proposes the self-boosting attention mechanism, a novel method for regularizing the network to focus on the key regions shared across samples and classes. Specifically, the proposed method first generates an attention map for each training image, highlighting the discriminative part for identifying the ground-truth object category. Then the generated attention maps are used as pseudo-annotations. The network is enforced to fit them as an auxiliary task. We call this approach the self-boosting attention mechanism (SAM). We also develop a variant by using SAM to create multiple attention maps to pool convolutional maps in a style of bilinear pooling, dubbed SAM-Bilinear. Through extensive experimental studies, we show that both methods can significantly improve fine-grained visual recognition performance on low data regimes and can be incorporated into existing network architectures. The source code is publicly available at: https://github.com/GANPerf/SAM