 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Sense Beyond English: Evaluating and Improving Multilingual Language Models for Commonsense Reasoning
Jun 13, 2021
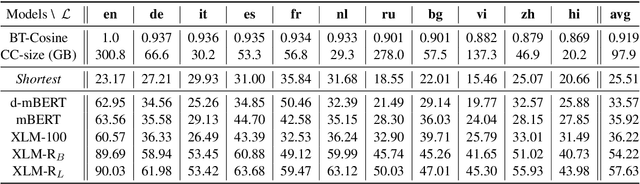

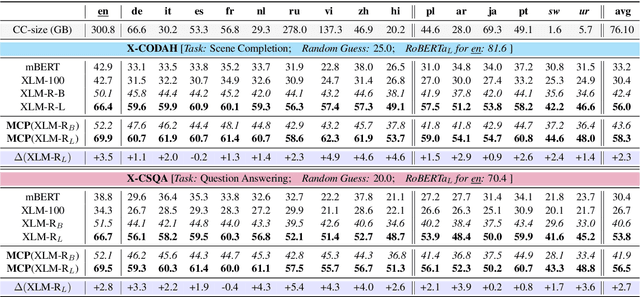
Commonsense reasoning research has so far been limited to English. We aim to evaluate and improve popular multilingual language models (ML-LMs) to help advance commonsense reasoning (CSR) beyond English. We collect the Mickey Corpus, consisting of 561k sentences in 11 different languages, which can be used for analyzing and improving ML-LMs. We propose Mickey Probe, a language-agnostic probing task for fairly evaluating the common sense of popular ML-LMs across different languages. In addition, we also create two new datasets, X-CSQA and X-CODAH, by translating their English versions to 15 other languages, so that we can evaluate popular ML-LMs for cross-lingual commonsense reasoning. To improve the performance beyond English, we propose a simple yet effective method -- multilingual contrastive pre-training (MCP). It significantly enhances sentence representations, yielding a large performance gain on both benchmarks.
AdaTag: Multi-Attribute Value Extraction from Product Profiles with Adaptive Decoding
Jun 04, 2021

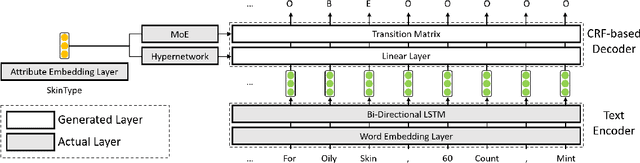
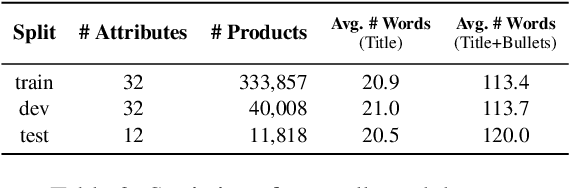
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model's capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.
Probing Causal Common Sense in Dialogue Response Generation
Apr 21, 2021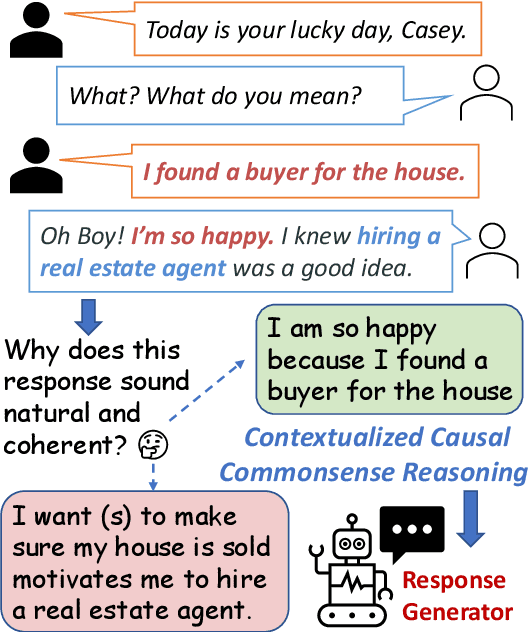
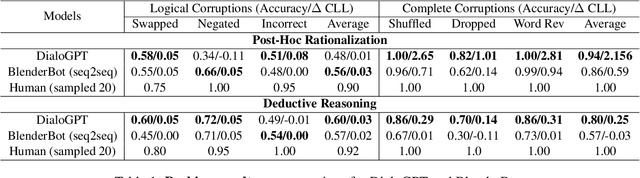


Communication is a cooperative effort that requires reaching mutual understanding among the participants. Humans use commonsense reasoning implicitly to produce natural and logically-coherent responses. As a step towards fluid human-AI communication, we study if response generation (RG) models can emulate human reasoning process and use common sense to help produce better-quality responses. We aim to tackle two research questions: how to formalize conversational common sense and how to examine RG models capability to use common sense? We first propose a task, CEDAR: Causal common sEnse in DiAlogue Response generation, that concretizes common sense as textual explanations for what might lead to the response and evaluates RG models behavior by comparing the modeling loss given a valid explanation with an invalid one. Then we introduce a process that automatically generates such explanations and ask humans to verify them. Finally, we design two probing settings for RG models targeting two reasoning capabilities using verified explanations. We find that RG models have a hard time determining the logical validity of explanations but can identify grammatical naturalness of the explanation easily.
X-METRA-ADA: Cross-lingual Meta-Transfer Learning Adaptation to Natural Language Understanding and Question Answering
Apr 20, 2021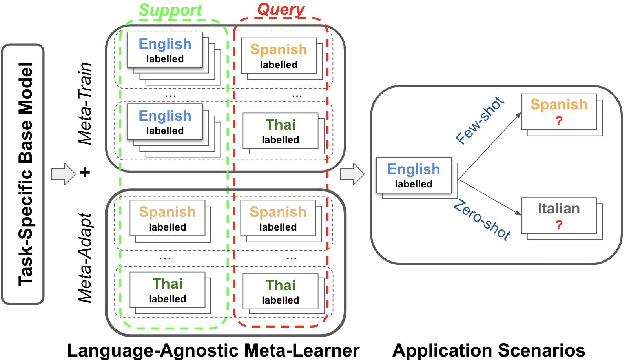
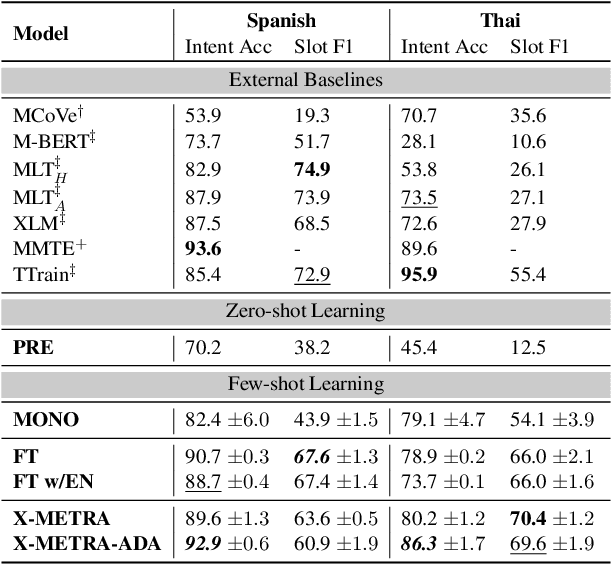
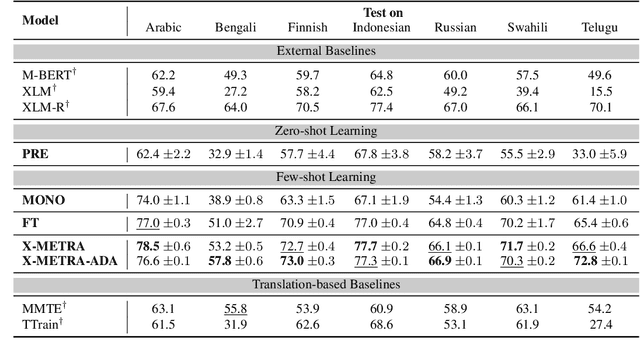
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.
On the Influence of Masking Policies in Intermediate Pre-training
Apr 18, 2021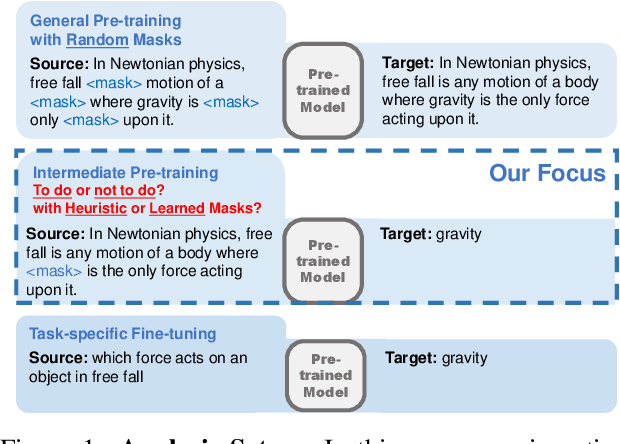
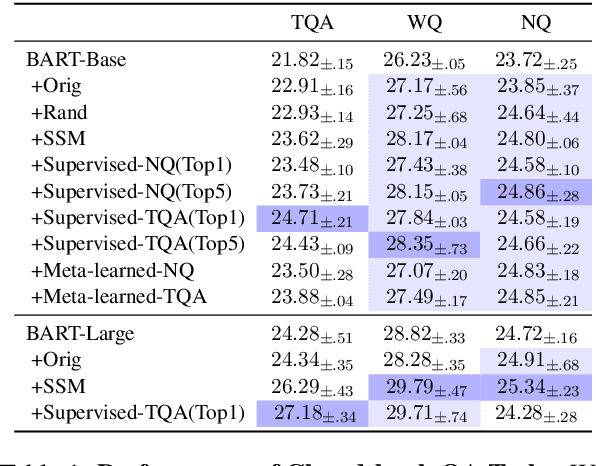
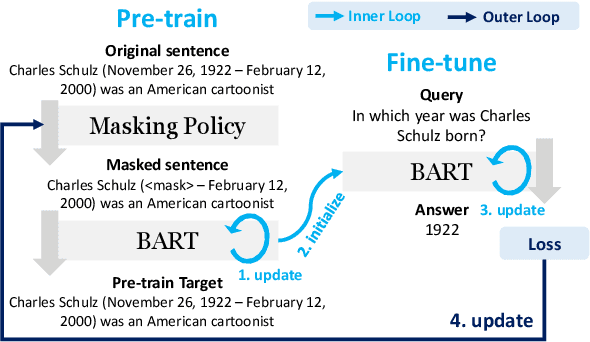
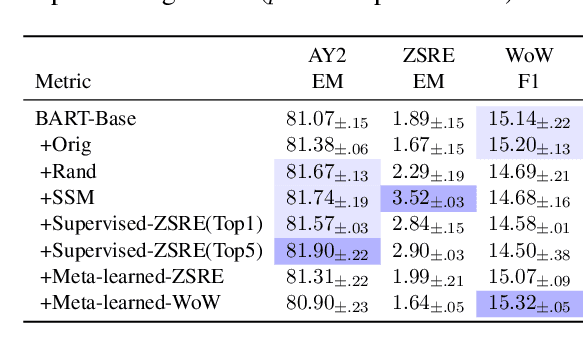
Current NLP models are predominantly trained through a pretrain-then-finetune pipeline, where models are first pretrained on a large text corpus with a masked-language-modelling (MLM) objective, then finetuned on the downstream task. Prior work has shown that inserting an intermediate pre-training phase, with heuristic MLM objectives that resemble downstream tasks, can significantly improve final performance. However, it is still unclear (1) in what cases such intermediate pre-training is helpful, (2) whether hand-crafted heuristic objectives are optimal for a given task, and (3) whether a MLM policy designed for one task is generalizable beyond that task. In this paper, we perform a large-scale empirical study to investigate the effect of various MLM policies in intermediate pre-training. Crucially, we introduce methods to automate discovery of optimal MLM policies, by learning a masking model through either direct supervision or meta-learning on the downstream task. We investigate the effects of using heuristic, directly supervised, and meta-learned MLM policies for intermediate pretraining, on eight selected tasks across three categories (closed-book QA, knowledge-intensive language tasks, and abstractive summarization). Most notably, we show that learned masking policies outperform the heuristic of masking named entities on TriviaQA, and masking policies learned on one task can positively transfer to other tasks in certain cases.
CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP
Apr 18, 2021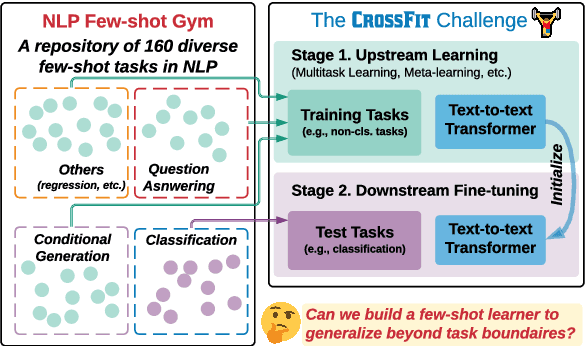
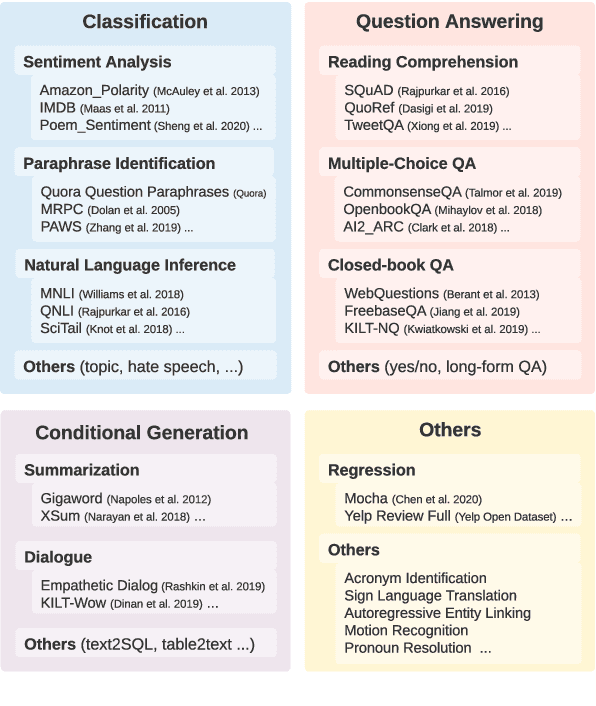
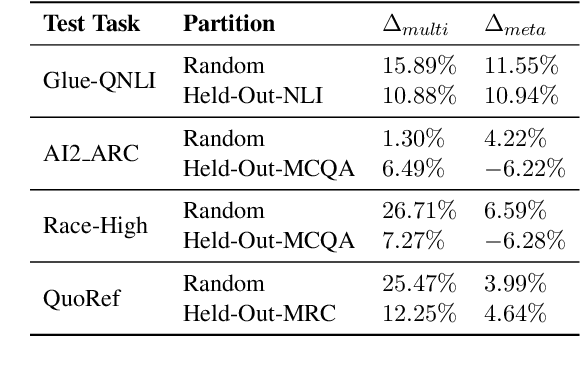
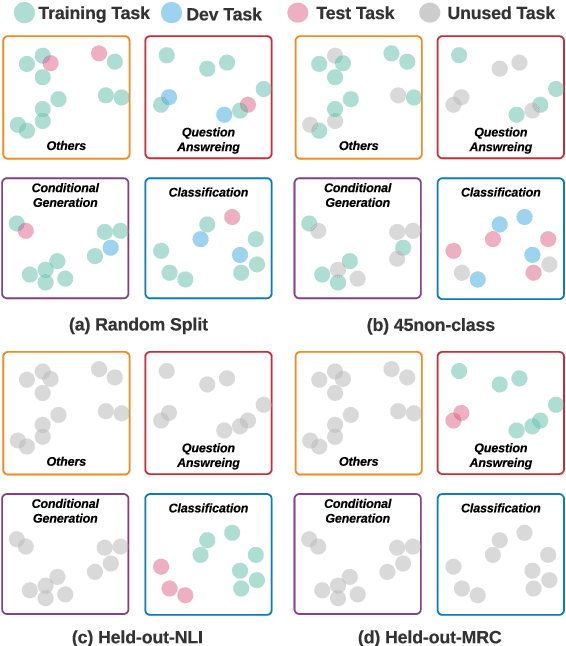
Humans can learn a new language task more efficiently than machines, conceivably by leveraging their prior experience and knowledge in learning other tasks. In this paper, we explore whether such cross-task generalization ability can be acquired, and further applied to build better few-shot learners across diverse NLP tasks. We introduce CrossFit, a task setup for studying cross-task few-shot learning ability, which standardizes seen/unseen task splits, data access during different learning stages, and the evaluation protocols. In addition, we present NLP Few-shot Gym, a repository of 160 few-shot NLP tasks, covering diverse task categories and applications, and converted to a unified text-to-text format. Our empirical analysis reveals that the few-shot learning ability on unseen tasks can be improved via an upstream learning stage using a set of seen tasks. Additionally, the advantage lasts into medium-resource scenarios when thousands of training examples are available. We also observe that selection of upstream learning tasks can significantly influence few-shot performance on unseen tasks, asking further analysis on task similarity and transferability.
FedNLP: A Research Platform for Federated Learning in Natural Language Processing
Apr 18, 2021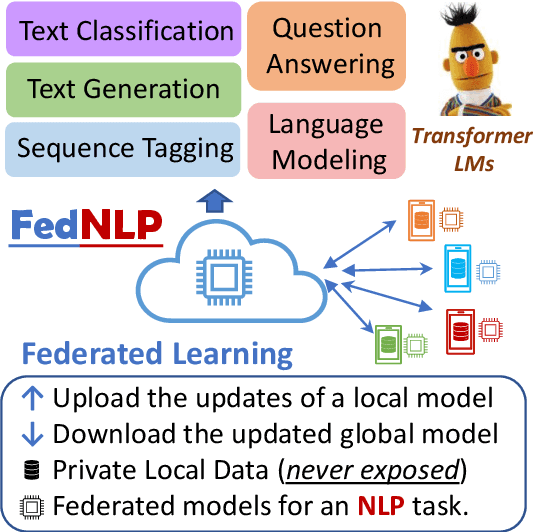
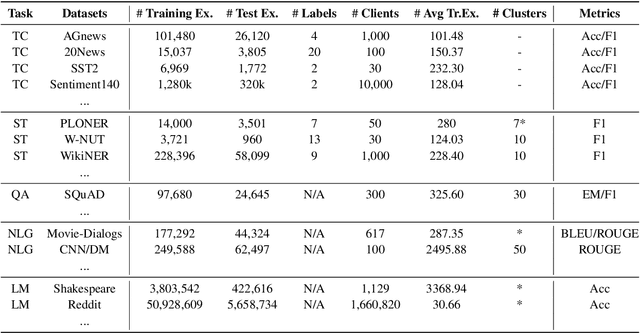
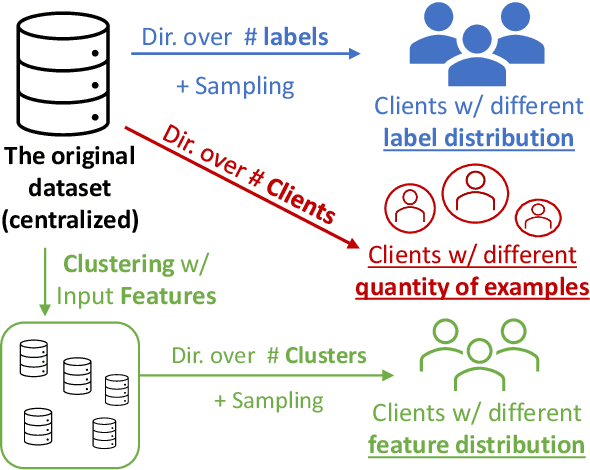
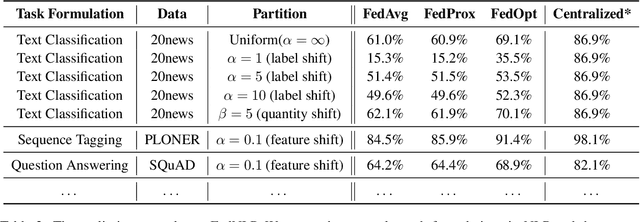
Increasing concerns and regulations about data privacy, necessitate the study of privacy-preserving methods for natural language processing (NLP) applications. Federated learning (FL) provides promising methods for a large number of clients (i.e., personal devices or organizations) to collaboratively learn a shared global model to benefit all clients, while allowing users to keep their data locally. To facilitate FL research in NLP, we present the FedNLP, a research platform for federated learning in NLP. FedNLP supports various popular task formulations in NLP such as text classification, sequence tagging, question answering, seq2seq generation, and language modeling. We also implement an interface between Transformer language models (e.g., BERT) and FL methods (e.g., FedAvg, FedOpt, etc.) for distributed training. The evaluation protocol of this interface supports a comprehensive collection of non-IID partitioning strategies. Our preliminary experiments with FedNLP reveal that there exists a large performance gap between learning on decentralized and centralized datasets -- opening intriguing and exciting future research directions aimed at developing FL methods suited to NLP tasks.
Lifelong Learning of Few-shot Learners across NLP Tasks
Apr 18, 2021
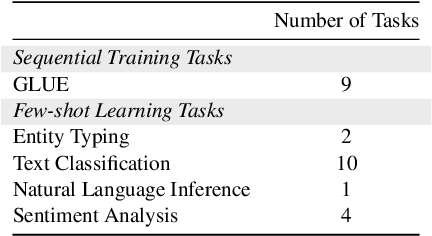

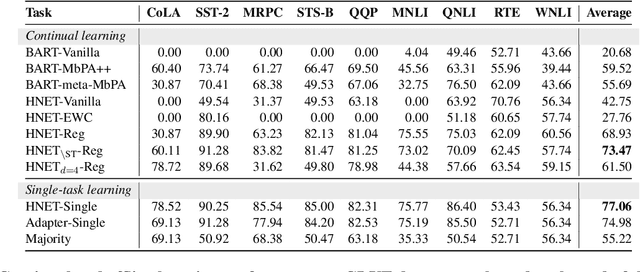
Recent advances in large pre-trained language models have greatly improved the performance on a broad set of NLP tasks. However, adapting an existing model to new tasks often requires (repeated) re-training over enormous labeled data that is prohibitively expensive to obtain. Moreover, models learned on new tasks may gradually "forget" about the knowledge learned from earlier tasks (i.e., catastrophic forgetting). In this paper, we study the challenge of lifelong learning to few-shot learn over a sequence of diverse NLP tasks, through continuously fine-tuning a language model. We investigate the model's ability of few-shot generalization to new tasks while retaining its performance on the previously learned tasks. We explore existing continual learning methods in solving this problem and propose a continual meta-learning approach which learns to generate adapter weights from a few examples while regularizing changes of the weights to mitigate catastrophic forgetting. We demonstrate our approach preserves model performance over training tasks and leads to positive knowledge transfer when the future tasks are learned.
SalKG: Learning From Knowledge Graph Explanations for Commonsense Reasoning
Apr 18, 2021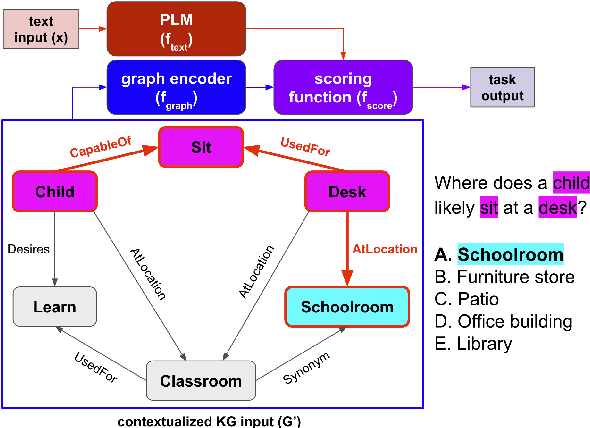

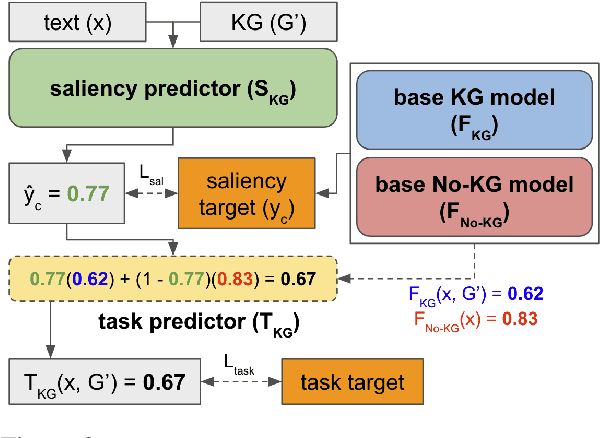
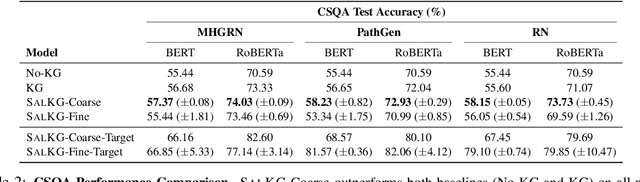
Augmenting pre-trained language models with knowledge graphs (KGs) has achieved success on various commonsense reasoning tasks. Although some works have attempted to explain the behavior of such KG-augmented models by indicating which KG inputs are salient (i.e., important for the model's prediction), it is not always clear how these explanations should be used to make the model better. In this paper, we explore whether KG explanations can be used as supervision for teaching these KG-augmented models how to filter out unhelpful KG information. To this end, we propose SalKG, a simple framework for learning from KG explanations of both coarse (Is the KG salient?) and fine (Which parts of the KG are salient?) granularity. Given the explanations generated from a task's training set, SalKG trains KG-augmented models to solve the task by focusing on KG information highlighted by the explanations as salient. Across two popular commonsense QA benchmarks and three KG-augmented models, we find that SalKG's training process can consistently improve model performance.
On the Strengths of Cross-Attention in Pretrained Transformers for Machine Translation
Apr 18, 2021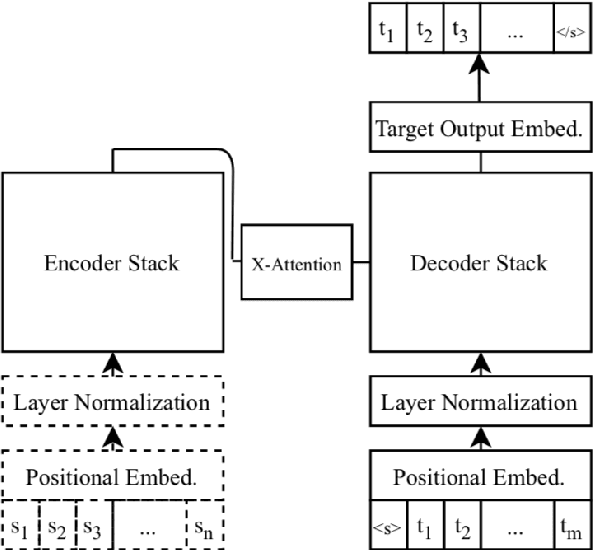
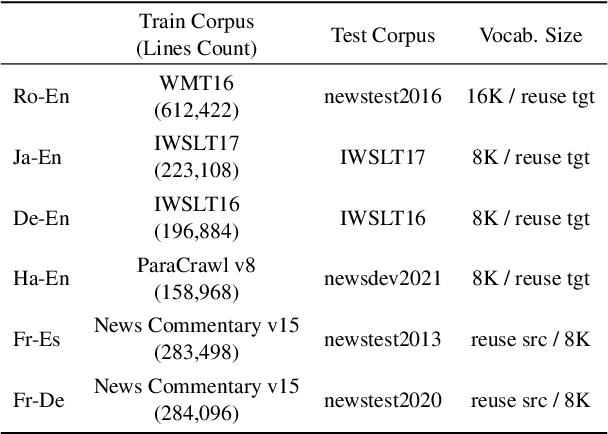
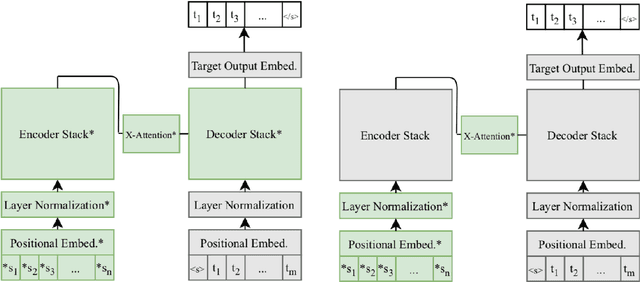
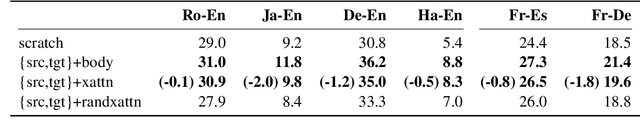
We study the power of cross-attention in the Transformer architecture within the context of machine translation. In transfer learning experiments, where we fine-tune a translation model on a dataset with one new language, we find that, apart from the new language's embeddings, only the cross-attention parameters need to be fine-tuned to obtain competitive BLEU performance. We provide insights into why this is the case and further find that limiting fine-tuning in this manner yields cross-lingually aligned type embeddings. The implications of this finding include a mitigation of catastrophic forgetting in the network and the potential for zero-shot translation.