 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multiplexed Network for End-to-End, Multilingual OCR
Mar 29, 2021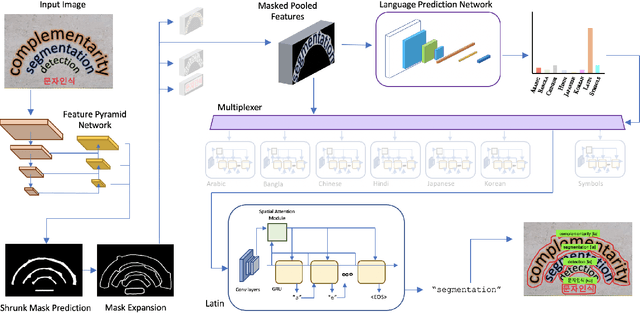
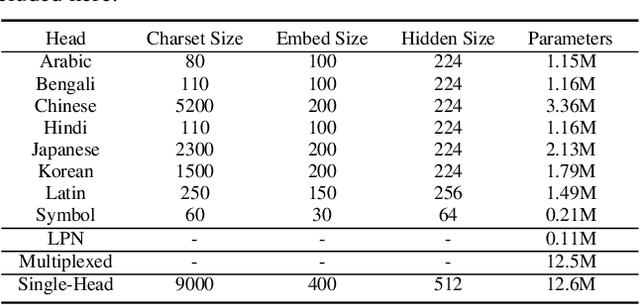
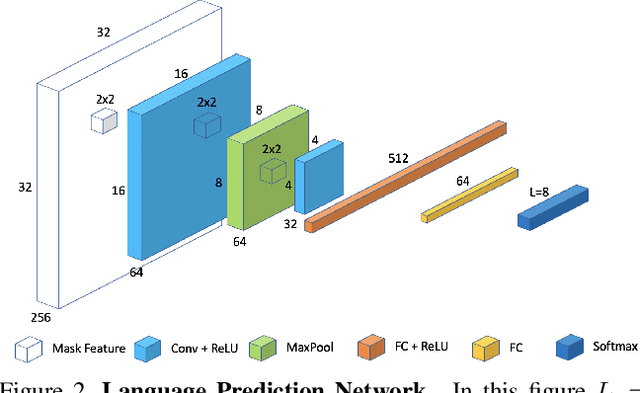
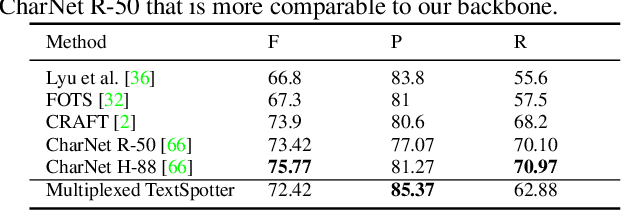
Recent advances in OCR have shown that an end-to-end (E2E) training pipeline that includes both detection and recognition leads to the best results. However, many existing methods focus primarily on Latin-alphabet languages, often even only case-insensitive English characters. In this paper, we propose an E2E approach, Multiplexed Multilingual Mask TextSpotter, that performs script identification at the word level and handles different scripts with different recognition heads, all while maintaining a unified loss that simultaneously optimizes script identification and multiple recognition heads. Experiments show that our method outperforms the single-head model with similar number of parameters in end-to-end recognition tasks, and achieves state-of-the-art results on MLT17 and MLT19 joint text detection and script identification benchmarks. We believe that our work is a step towards the end-to-end trainable and scalable multilingual multi-purpose OCR system. Our code and model will be released.
img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation
Dec 14, 2020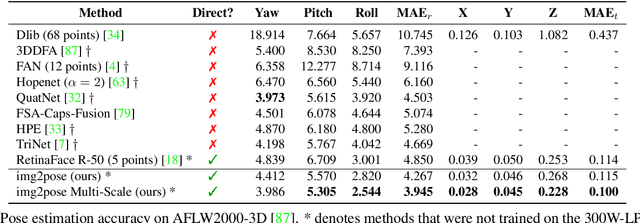

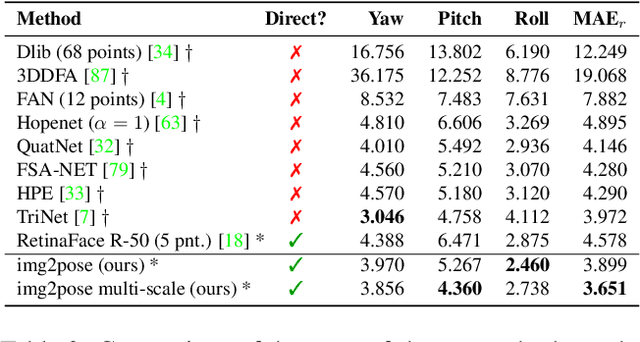
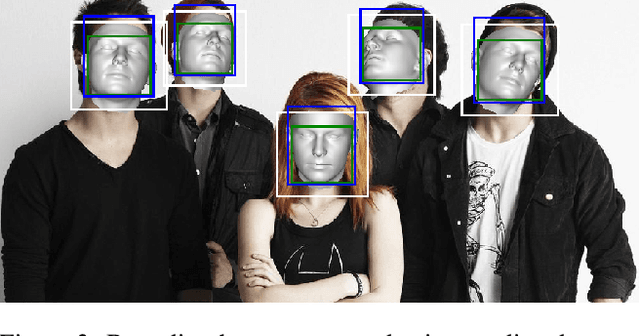
We propose real-time, six degrees of freedom (6DoF), 3D face pose estimation without face detection or landmark localization. We observe that estimating the 6DoF rigid transformation of a face is a simpler problem than facial landmark detection, often used for 3D face alignment. In addition, 6DoF offers more information than face bounding box labels. We leverage these observations to make multiple contributions: (a) We describe an easily trained, efficient, Faster R-CNN--based model which regresses 6DoF pose for all faces in the photo, without preliminary face detection. (b) We explain how pose is converted and kept consistent between the input photo and arbitrary crops created while training and evaluating our model. (c) Finally, we show how face poses can replace detection bounding box training labels. Tests on AFLW2000-3D and BIWI show that our method runs at real-time and outperforms state of the art (SotA) face pose estimators. Remarkably, our method also surpasses SotA models of comparable complexity on the WIDER FACE detection benchmark, despite not been optimized on bounding box labels.
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
Dec 08, 2020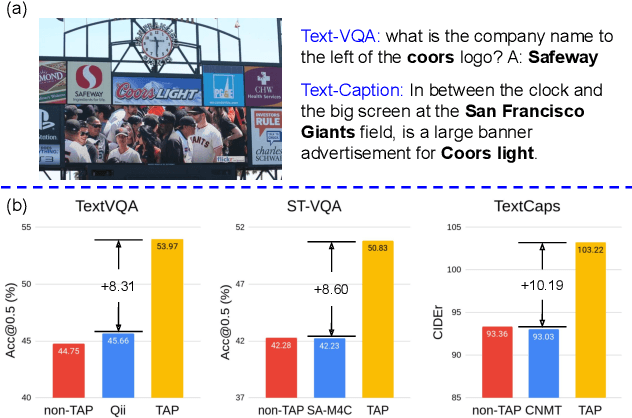
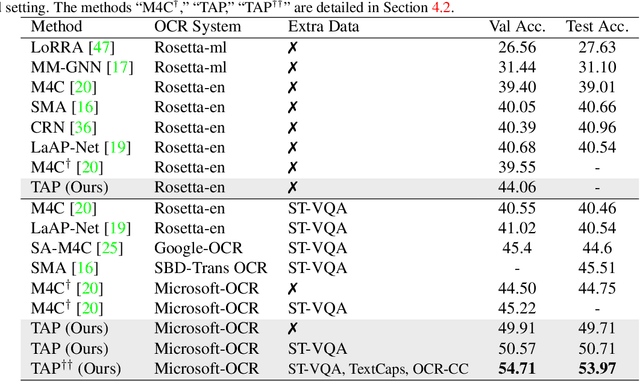
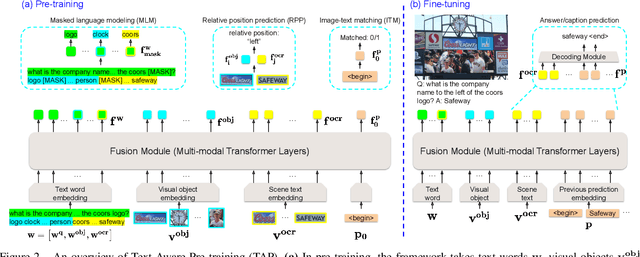
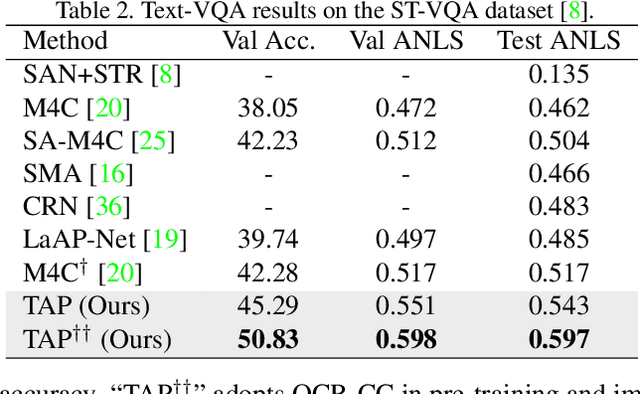
In this paper, we propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks. These two tasks aim at reading and understanding scene text in images for question answering and image caption generation, respectively. In contrast to the conventional vision-language pre-training that fails to capture scene text and its relationship with the visual and text modalities, TAP explicitly incorporates scene text (generated from OCR engines) in pre-training. With three pre-training tasks, including masked language modeling (MLM), image-text (contrastive) matching (ITM), and relative (spatial) position prediction (RPP), TAP effectively helps the model learn a better aligned representation among the three modalities: text word, visual object, and scene text. Due to this aligned representation learning, even pre-trained on the same downstream task dataset, TAP already boosts the absolute accuracy on the TextVQA dataset by +5.4%, compared with a non-TAP baseline. To further improve the performance, we build a large-scale dataset based on the Conceptual Caption dataset, named OCR-CC, which contains 1.4 million scene text-related image-text pairs. Pre-trained on this OCR-CC dataset, our approach outperforms the state of the art by large margins on multiple tasks, i.e., +8.3% accuracy on TextVQA, +8.6% accuracy on ST-VQA, and +10.2 CIDEr score on TextCaps.
VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training
Sep 28, 2020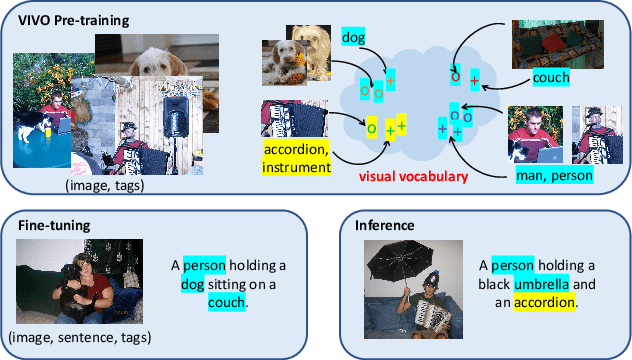
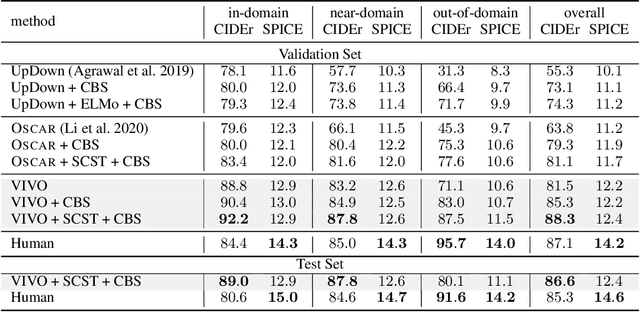
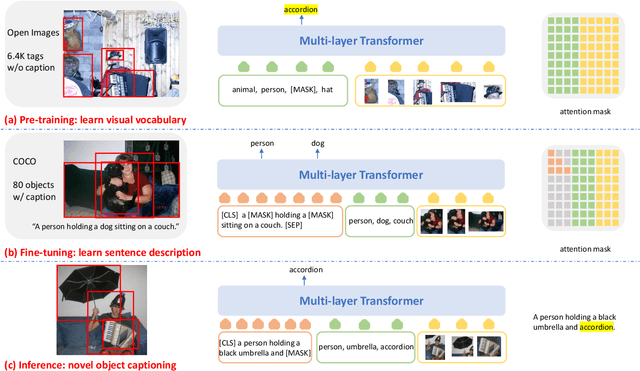

It is highly desirable yet challenging to generate image captions that can describe novel objects which are unseen in caption-labeled training data, a capability that is evaluated in the novel object captioning challenge (nocaps). In this challenge, no additional image-caption training data, other than COCO Captions, is allowed for model training. Thus, conventional Vision-Language Pre-training (VLP) methods cannot be applied. This paper presents VIsual VOcabulary pre-training (VIVO) that performs pre-training in the absence of caption annotations. By breaking the dependency of paired image-caption training data in VLP, VIVO can leverage large amounts of paired image-tag data to learn a visual vocabulary. This is done by pre-training a multi-layer Transformer model that learns to align image-level tags with their corresponding image region features. To address the unordered nature of image tags, VIVO uses a Hungarian matching loss with masked tag prediction to conduct pre-training. We validate the effectiveness of VIVO by fine-tuning the pre-trained model for image captioning. In addition, we perform an analysis of the visual-text alignment inferred by our model. The results show that our model can not only generate fluent image captions that describe novel objects, but also identify the locations of these objects. Our single model has achieved new state-of-the-art results on nocaps and surpassed the human CIDEr score.
Hashing-based Non-Maximum Suppression for Crowded Object Detection
May 22, 2020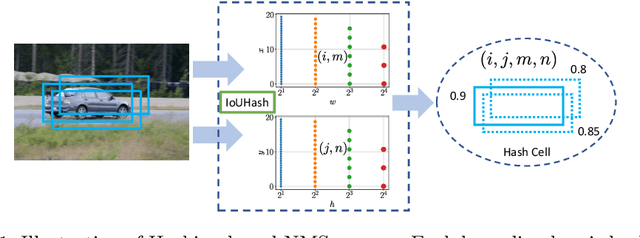
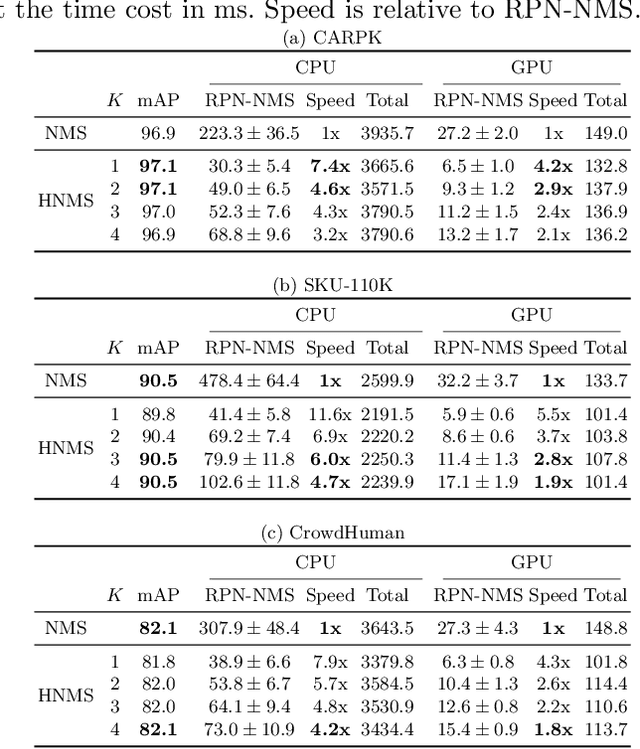
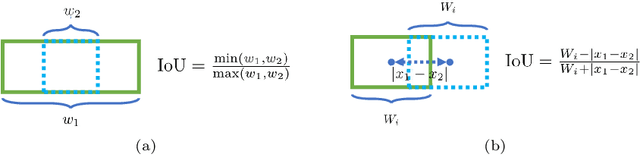
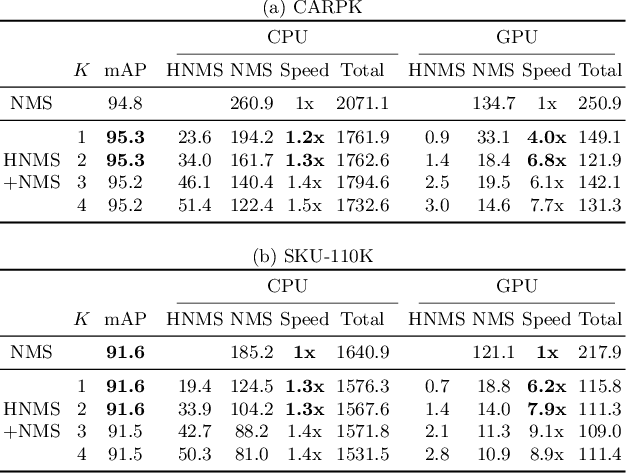
In this paper, we propose an algorithm, named hashing-based non-maximum suppression (HNMS) to efficiently suppress the non-maximum boxes for object detection. Non-maximum suppression (NMS) is an essential component to suppress the boxes at closely located locations with similar shapes. The time cost tends to be huge when the number of boxes becomes large, especially for crowded scenes. The basic idea of HNMS is to firstly map each box to a discrete code (hash cell) and then remove the boxes with lower confidences if they are in the same cell. Considering the intersection-over-union (IoU) as the metric, we propose a simple yet effective hashing algorithm, named IoUHash, which guarantees that the boxes within the same cell are close enough by a lower IoU bound. For two-stage detectors, we replace NMS in region proposal network with HNMS, and observe significant speed-up with comparable accuracy. For one-stage detectors, HNMS is used as a pre-filter to speed up the suppression with a large margin. Extensive experiments are conducted on CARPK, SKU-110K, CrowdHuman datasets to demonstrate the efficiency and effectiveness of HNMS. Code is released at \url{https://github.com/microsoft/hnms.git}.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
May 18, 2020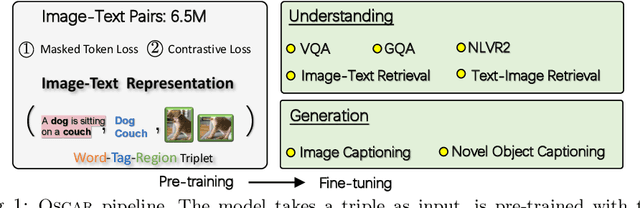

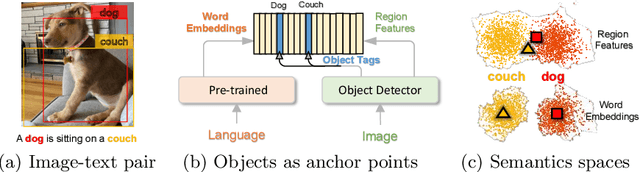
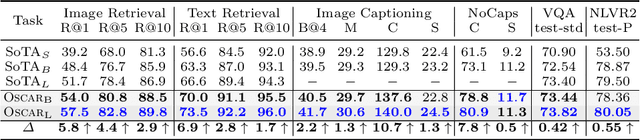
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.
FAN: Feature Adaptation Network for Surveillance Face Recognition and Normalization
Nov 26, 2019
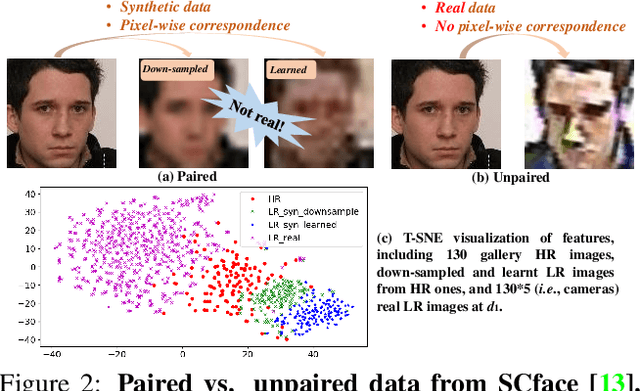

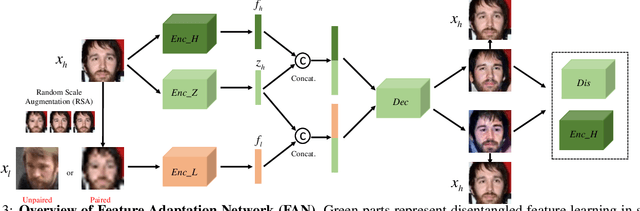
This paper studies face recognition (FR) and normalization in surveillance imagery. Surveillance FR is a challenging problem that has great values in law enforcement. Despite recent progress in conventional FR, less effort has been devoted to surveillance FR. To bridge this gap, we propose a Feature Adaptation Network (FAN) to jointly perform surveillance FR and normalization. Our face normalization mainly acts on the aspect of image resolution, closely related to face super-resolution. However, previous face super-resolution methods require paired training data with pixel-to-pixel correspondence, which is typically unavailable between real low- and high-resolution faces. Our FAN can leverage both paired and unpaired data as we disentangle the features into identity and non-identity components and adapt the distribution of the identity features, which breaks the limit of current face super-resolution methods. We further propose a random scale augmentation scheme to learn resolution robust identity features, with advantages over previous fixed scale augmentation. Extensive experiments on LFW, WIDER FACE, QUML-SurvFace and SCface datasets have demonstrated the superiority of our proposed method compared to the state of the arts on surveillance face recognition and normalization.
Gait Recognition via Disentangled Representation Learning
Apr 09, 2019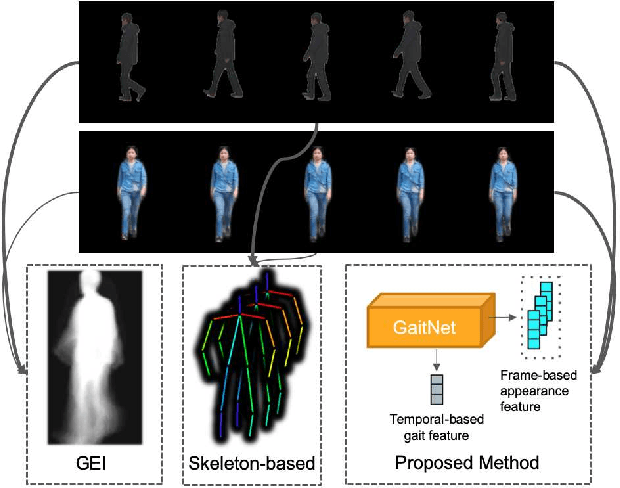

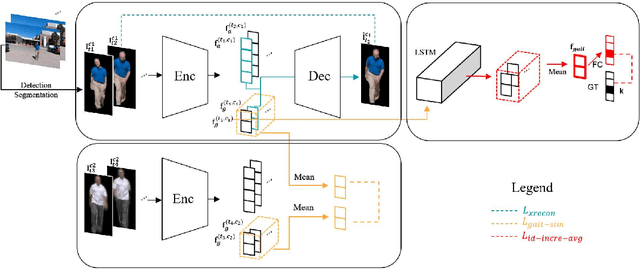

Gait, the walking pattern of individuals, is one of the most important biometrics modalities. Most of the existing gait recognition methods take silhouettes or articulated body models as the gait features. These methods suffer from degraded recognition performance when handling confounding variables, such as clothing, carrying and view angle. To remedy this issue, we propose a novel AutoEncoder framework to explicitly disentangle pose and appearance features from RGB imagery and the LSTM-based integration of pose features over time produces the gait feature. In addition, we collect a Frontal-View Gait (FVG) dataset to focus on gait recognition from frontal-view walking, which is a challenging problem since it contains minimal gait cues compared to other views. FVG also includes other important variations, e.g., walking speed, carrying, and clothing. With extensive experiments on CASIA-B, USF and FVG datasets, our method demonstrates superior performance to the state of the arts quantitatively, the ability of feature disentanglement qualitatively, and promising computational efficiency.
Representation Learning by Rotating Your Faces
Sep 11, 2018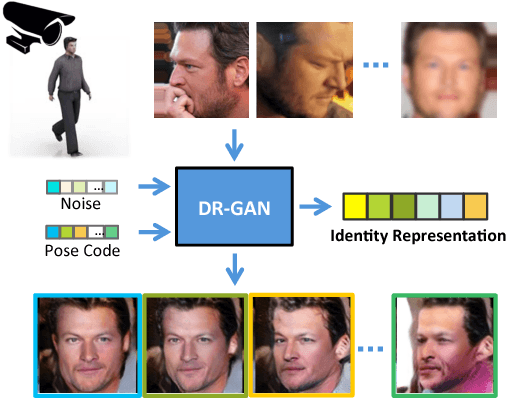
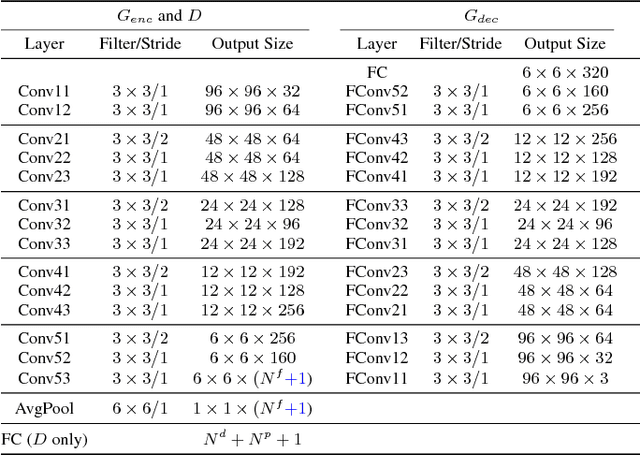
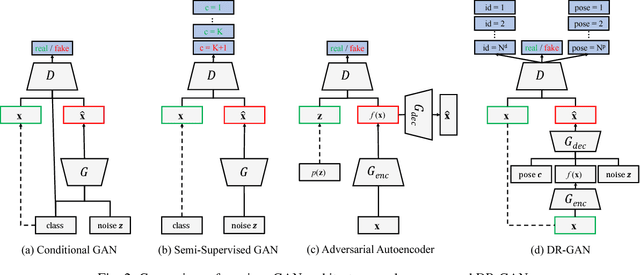
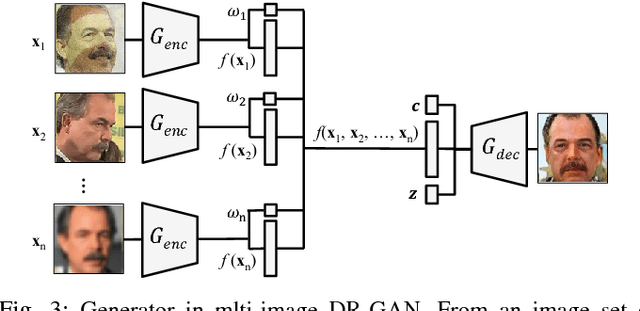
The large pose discrepancy between two face images is one of the fundamental challenges in automatic face recognition. Conventional approaches to pose-invariant face recognition either perform face frontalization on, or learn a pose-invariant representation from, a non-frontal face image. We argue that it is more desirable to perform both tasks jointly to allow them to leverage each other. To this end, this paper proposes a Disentangled Representation learning-Generative Adversarial Network (DR-GAN) with three distinct novelties. First, the encoder-decoder structure of the generator enables DR-GAN to learn a representation that is both generative and discriminative, which can be used for face image synthesis and pose-invariant face recognition. Second, this representation is explicitly disentangled from other face variations such as pose, through the pose code provided to the decoder and pose estimation in the discriminator. Third, DR-GAN can take one or multiple images as the input, and generate one unified identity representation along with an arbitrary number of synthetic face images. Extensive quantitative and qualitative evaluation on a number of controlled and in-the-wild databases demonstrate the superiority of DR-GAN over the state of the art in both learning representations and rotating large-pose face images.
Feature Transfer Learning for Deep Face Recognition with Long-Tail Data
Mar 23, 2018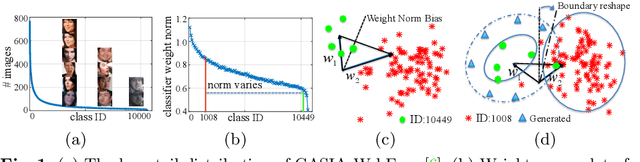
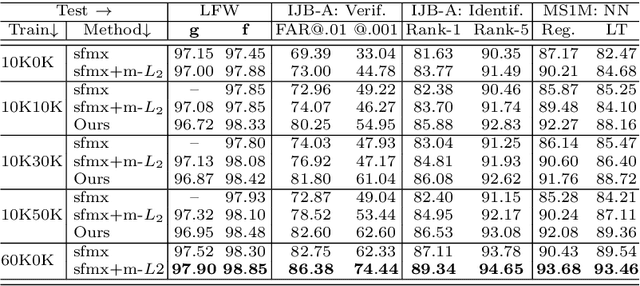
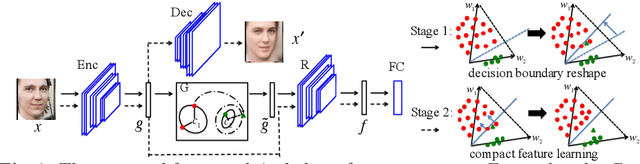
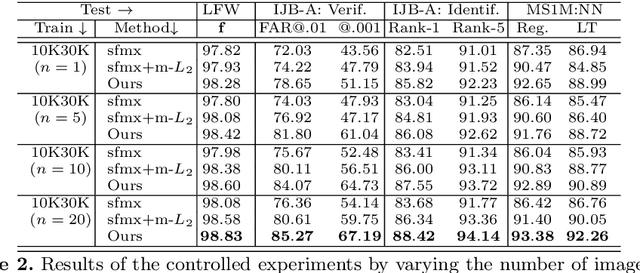
Real-world face recognition datasets exhibit long-tail characteristics, which results in biased classifiers in conventionally-trained deep neural networks, or insufficient data when long-tail classes are ignored. In this paper, we propose to handle long-tail classes in the training of a face recognition engine by augmenting their feature space under a center-based feature transfer framework. A Gaussian prior is assumed across all the head (regular) classes and the variance from regular classes are transferred to the long-tail class representation. This encourages the long-tail distribution to be closer to the regular distribution, while enriching and balancing the limited training data. Further, an alternating training regimen is proposed to simultaneously achieve less biased decision boundaries and a more discriminative feature representation. We conduct empirical studies that mimic long-tail datasets by limiting the number of samples and the proportion of long-tail classes on the MS-Celeb-1M dataset. We compare our method with baselines not designed to handle long-tail classes and also with state-of-the-art methods on face recognition benchmarks. State-of-the-art results on LFW, IJB-A and MS-Celeb-1M datasets demonstrate the effectiveness of our feature transfer approach and training strategy. Finally, our feature transfer allows smooth visual interpolation, which demonstrates disentanglement to preserve identity of a class while augmenting its feature space with non-identity variations.