 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural rendering enables dynamic tomography
Oct 27, 2024Interrupted X-ray computed tomography (X-CT) has been the common way to observe the deformation of materials during an experiment. While this approach is effective for quasi-static experiments, it has never been possible to reconstruct a full 3d tomography during a dynamic experiment which cannot be interrupted. In this work, we propose that neural rendering tools can be used to drive the paradigm shift to enable 3d reconstruction during dynamic events. First, we derive theoretical results to support the selection of projections angles. Via a combination of synthetic and experimental data, we demonstrate that neural radiance fields can reconstruct data modalities of interest more efficiently than conventional reconstruction methods. Finally, we develop a spatio-temporal model with spline-based deformation field and demonstrate that such model can reconstruct the spatio-temporal deformation of lattice samples in real-world experiments.
Modeling the Real World with High-Density Visual Particle Dynamics
Jun 28, 2024



We present High-Density Visual Particle Dynamics (HD-VPD), a learned world model that can emulate the physical dynamics of real scenes by processing massive latent point clouds containing 100K+ particles. To enable efficiency at this scale, we introduce a novel family of Point Cloud Transformers (PCTs) called Interlacers leveraging intertwined linear-attention Performer layers and graph-based neighbour attention layers. We demonstrate the capabilities of HD-VPD by modeling the dynamics of high degree-of-freedom bi-manual robots with two RGB-D cameras. Compared to the previous graph neural network approach, our Interlacer dynamics is twice as fast with the same prediction quality, and can achieve higher quality using 4x as many particles. We illustrate how HD-VPD can evaluate motion plan quality with robotic box pushing and can grasping tasks. See videos and particle dynamics rendered by HD-VPD at https://sites.google.com/view/hd-vpd.
Learning rigid-body simulators over implicit shapes for large-scale scenes and vision
May 22, 2024Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and PyBullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection. For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view images.
Scaling Face Interaction Graph Networks to Real World Scenes
Jan 22, 2024Accurately simulating real world object dynamics is essential for various applications such as robotics, engineering, graphics, and design. To better capture complex real dynamics such as contact and friction, learned simulators based on graph networks have recently shown great promise. However, applying these learned simulators to real scenes comes with two major challenges: first, scaling learned simulators to handle the complexity of real world scenes which can involve hundreds of objects each with complicated 3D shapes, and second, handling inputs from perception rather than 3D state information. Here we introduce a method which substantially reduces the memory required to run graph-based learned simulators. Based on this memory-efficient simulation model, we then present a perceptual interface in the form of editable NeRFs which can convert real-world scenes into a structured representation that can be processed by graph network simulator. We show that our method uses substantially less memory than previous graph-based simulators while retaining their accuracy, and that the simulators learned in synthetic environments can be applied to real world scenes captured from multiple camera angles. This paves the way for expanding the application of learned simulators to settings where only perceptual information is available at inference time.
Learning 3D Particle-based Simulators from RGB-D Videos
Dec 08, 2023



Realistic simulation is critical for applications ranging from robotics to animation. Traditional analytic simulators sometimes struggle to capture sufficiently realistic simulation which can lead to problems including the well known "sim-to-real" gap in robotics. Learned simulators have emerged as an alternative for better capturing real-world physical dynamics, but require access to privileged ground truth physics information such as precise object geometry or particle tracks. Here we propose a method for learning simulators directly from observations. Visual Particle Dynamics (VPD) jointly learns a latent particle-based representation of 3D scenes, a neural simulator of the latent particle dynamics, and a renderer that can produce images of the scene from arbitrary views. VPD learns end to end from posed RGB-D videos and does not require access to privileged information. Unlike existing 2D video prediction models, we show that VPD's 3D structure enables scene editing and long-term predictions. These results pave the way for downstream applications ranging from video editing to robotic planning.
Equivariant Data Augmentation for Generalization in Offline Reinforcement Learning
Sep 14, 2023We present a novel approach to address the challenge of generalization in offline reinforcement learning (RL), where the agent learns from a fixed dataset without any additional interaction with the environment. Specifically, we aim to improve the agent's ability to generalize to out-of-distribution goals. To achieve this, we propose to learn a dynamics model and check if it is equivariant with respect to a fixed type of transformation, namely translations in the state space. We then use an entropy regularizer to increase the equivariant set and augment the dataset with the resulting transformed samples. Finally, we learn a new policy offline based on the augmented dataset, with an off-the-shelf offline RL algorithm. Our experimental results demonstrate that our approach can greatly improve the test performance of the policy on the considered environments.
Quantile Filtered Imitation Learning
Dec 02, 2021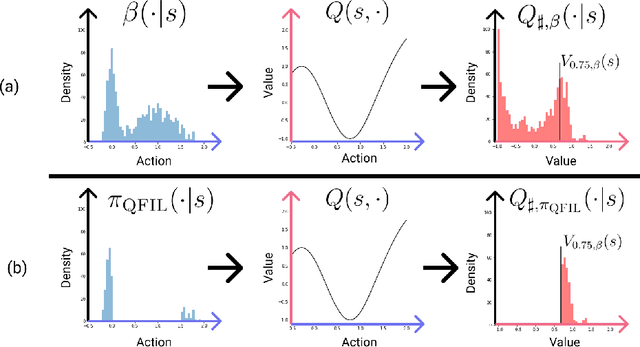
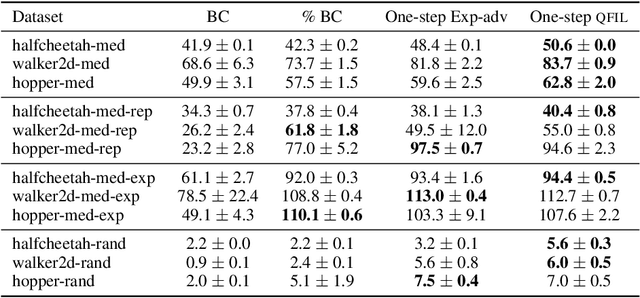
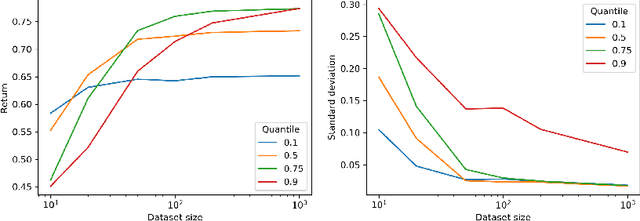
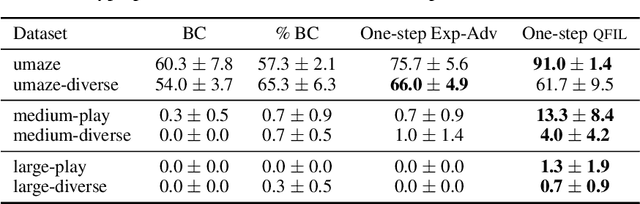
We introduce quantile filtered imitation learning (QFIL), a novel policy improvement operator designed for offline reinforcement learning. QFIL performs policy improvement by running imitation learning on a filtered version of the offline dataset. The filtering process removes $ s,a $ pairs whose estimated Q values fall below a given quantile of the pushforward distribution over values induced by sampling actions from the behavior policy. The definitions of both the pushforward Q distribution and resulting value function quantile are key contributions of our method. We prove that QFIL gives us a safe policy improvement step with function approximation and that the choice of quantile provides a natural hyperparameter to trade off bias and variance of the improvement step. Empirically, we perform a synthetic experiment illustrating how QFIL effectively makes a bias-variance tradeoff and we see that QFIL performs well on the D4RL benchmark.
Offline RL Without Off-Policy Evaluation
Jun 16, 2021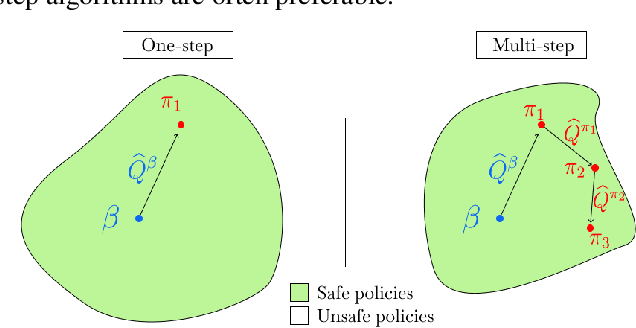
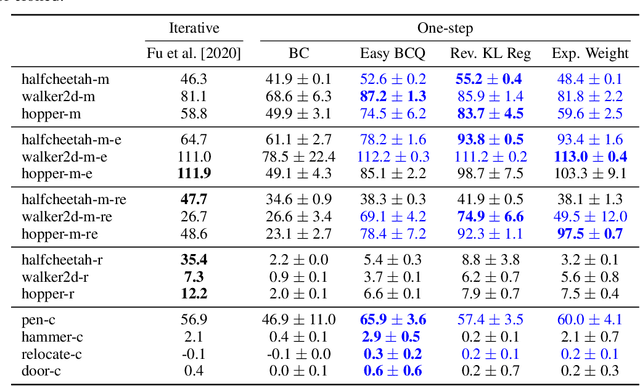

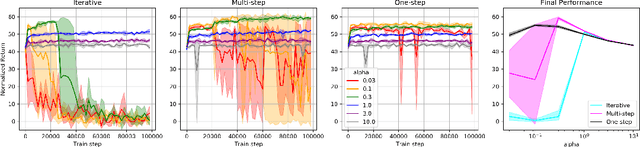
Most prior approaches to offline reinforcement learning (RL) have taken an iterative actor-critic approach involving off-policy evaluation. In this paper we show that simply doing one step of constrained/regularized policy improvement using an on-policy Q estimate of the behavior policy performs surprisingly well. This one-step algorithm beats the previously reported results of iterative algorithms on a large portion of the D4RL benchmark. The simple one-step baseline achieves this strong performance without many of the tricks used by previously proposed iterative algorithms and is more robust to hyperparameters. We argue that the relatively poor performance of iterative approaches is a result of the high variance inherent in doing off-policy evaluation and magnified by the repeated optimization of policies against those high-variance estimates. In addition, we hypothesize that the strong performance of the one-step algorithm is due to a combination of favorable structure in the environment and behavior policy.
Rethinking Exploration for Sample-Efficient Policy Learning
Jan 23, 2021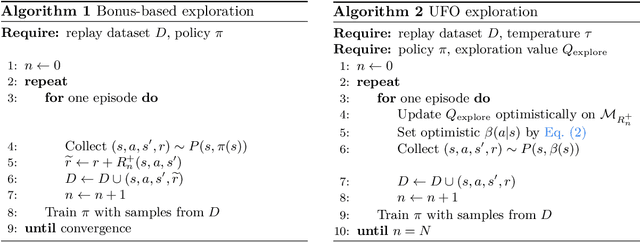
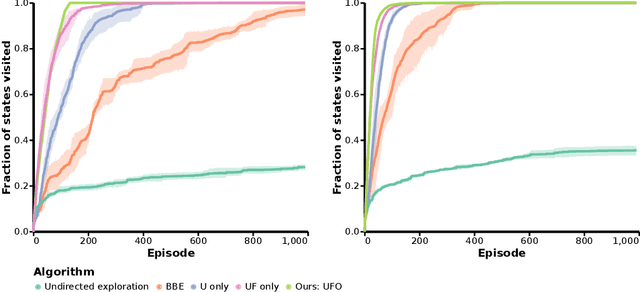
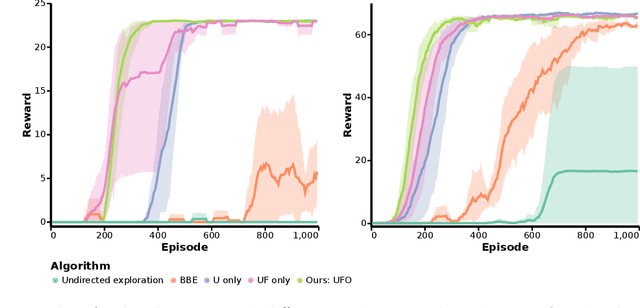
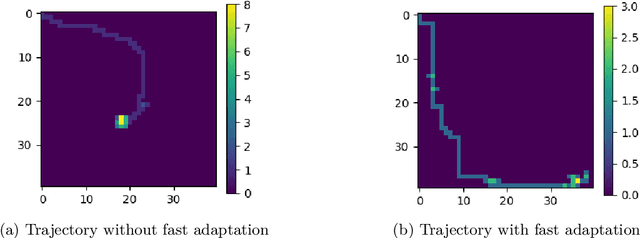
Off-policy reinforcement learning for control has made great strides in terms of performance and sample efficiency. We suggest that for many tasks the sample efficiency of modern methods is now limited by the richness of the data collected rather than the difficulty of policy fitting. We examine the reasons that directed exploration methods in the bonus-based exploration (BBE) family have not been more influential in the sample efficient control problem. Three issues have limited the applicability of BBE: bias with finite samples, slow adaptation to decaying bonuses, and lack of optimism on unseen transitions. We propose modifications to the bonus-based exploration recipe to address each of these limitations. The resulting algorithm, which we call UFO, produces policies that are Unbiased with finite samples, Fast-adapting as the exploration bonus changes, and Optimistic with respect to new transitions. We include experiments showing that rapid directed exploration is a promising direction to improve sample efficiency for control.
Evaluating representations by the complexity of learning low-loss predictors
Sep 15, 2020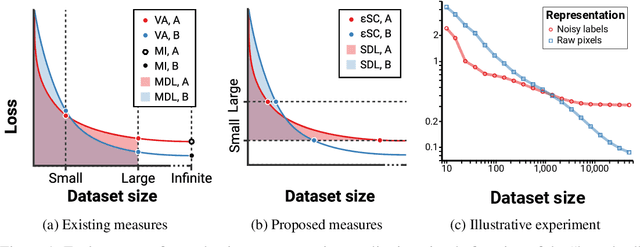
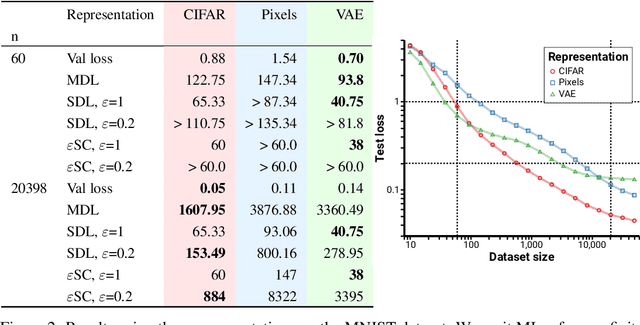
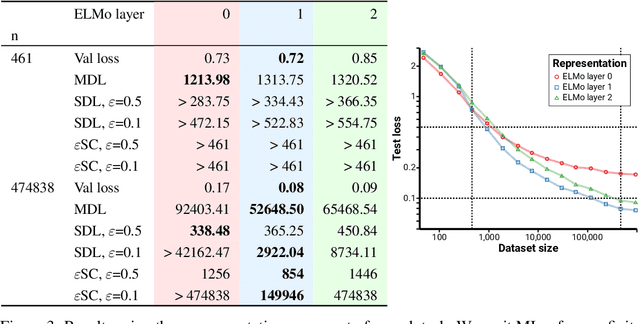
We consider the problem of evaluating representations of data for use in solving a downstream task. We propose to measure the quality of a representation by the complexity of learning a predictor on top of the representation that achieves low loss on a task of interest, and introduce two methods, surplus description length (SDL) and $\varepsilon$ sample complexity ($\varepsilon$SC). In contrast to prior methods, which measure the amount of information about the optimal predictor that is present in a specific amount of data, our methods measure the amount of information needed from the data to recover an approximation of the optimal predictor up to a specified tolerance. We present a framework to compare these methods based on plotting the validation loss versus training set size (the "loss-data" curve). Existing measures, such as mutual information and minimum description length probes, correspond to slices and integrals along the data-axis of the loss-data curve, while ours correspond to slices and integrals along the loss-axis. We provide experiments on real data to compare the behavior of each of these methods over datasets of varying size along with a high performance open source library for representation evaluation at https://github.com/willwhitney/reprieve.