 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsertion-Deletion Transformer
Jan 15, 2020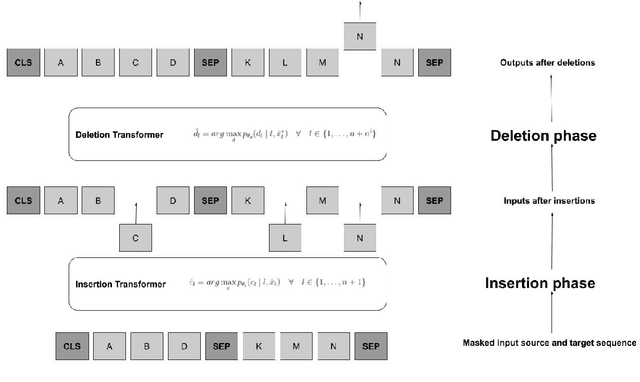



We propose the Insertion-Deletion Transformer, a novel transformer-based neural architecture and training method for sequence generation. The model consists of two phases that are executed iteratively, 1) an insertion phase and 2) a deletion phase. The insertion phase parameterizes a distribution of insertions on the current output hypothesis, while the deletion phase parameterizes a distribution of deletions over the current output hypothesis. The training method is a principled and simple algorithm, where the deletion model obtains its signal directly on-policy from the insertion model output. We demonstrate the effectiveness of our Insertion-Deletion Transformer on synthetic translation tasks, obtaining significant BLEU score improvement over an insertion-only model.
SpecAugment on Large Scale Datasets
Dec 11, 2019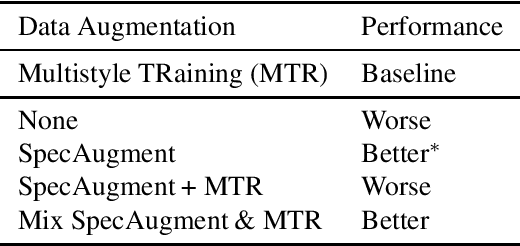
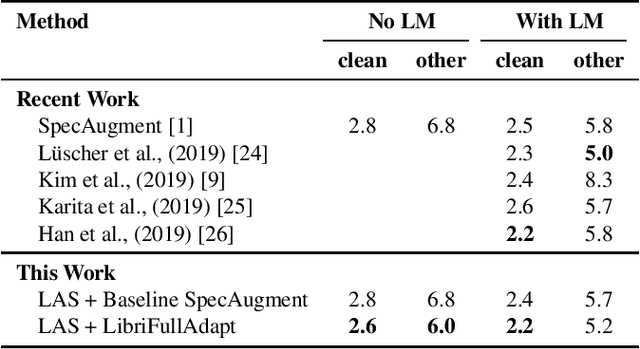
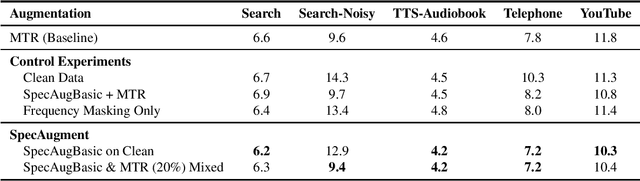
Recently, SpecAugment, an augmentation scheme for automatic speech recognition that acts directly on the spectrogram of input utterances, has shown to be highly effective in enhancing the performance of end-to-end networks on public datasets. In this paper, we demonstrate its effectiveness on tasks with large scale datasets by investigating its application to the Google Multidomain Dataset (Narayanan et al., 2018). We achieve improvement across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model. We also introduce a modification of SpecAugment that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks. By using adaptive masking, we are able to further improve the performance of the Listen, Attend and Spell model on LibriSpeech to 2.2% WER on test-clean and 5.2% WER on test-other.
An Empirical Study of Generation Order for Machine Translation
Oct 29, 2019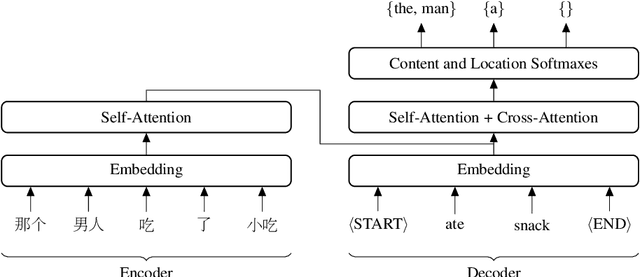


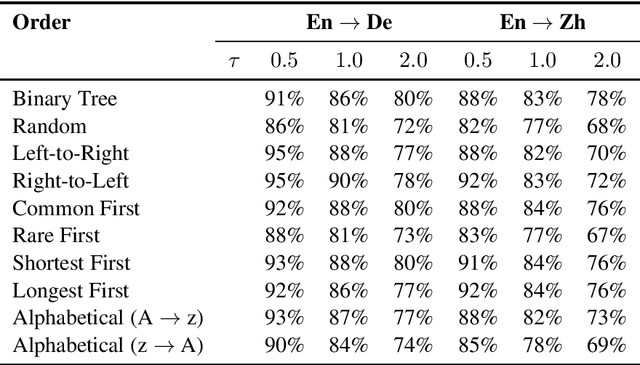
In this work, we present an empirical study of generation order for machine translation. Building on recent advances in insertion-based modeling, we first introduce a soft order-reward framework that enables us to train models to follow arbitrary oracle generation policies. We then make use of this framework to explore a large variety of generation orders, including uninformed orders, location-based orders, frequency-based orders, content-based orders, and model-based orders. Curiously, we find that for the WMT'14 English $\to$ German translation task, order does not have a substantial impact on output quality, with unintuitive orderings such as alphabetical and shortest-first matching the performance of a standard Transformer. This demonstrates that traditional left-to-right generation is not strictly necessary to achieve high performance. On the other hand, results on the WMT'18 English $\to$ Chinese task tend to vary more widely, suggesting that translation for less well-aligned language pairs may be more sensitive to generation order.
Big Bidirectional Insertion Representations for Documents
Oct 29, 2019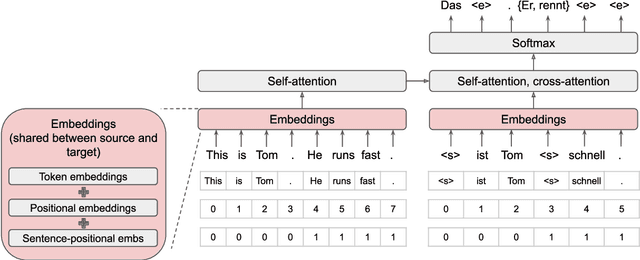
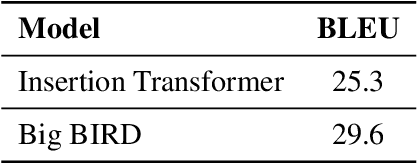

The Insertion Transformer is well suited for long form text generation due to its parallel generation capabilities, requiring $O(\log_2 n)$ generation steps to generate $n$ tokens. However, modeling long sequences is difficult, as there is more ambiguity captured in the attention mechanism. This work proposes the Big Bidirectional Insertion Representations for Documents (Big BIRD), an insertion-based model for document-level translation tasks. We scale up the insertion-based models to long form documents. Our key contribution is introducing sentence alignment via sentence-positional embeddings between the source and target document. We show an improvement of +4.3 BLEU on the WMT'19 English$\rightarrow$German document-level translation task compared with the Insertion Transformer baseline.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019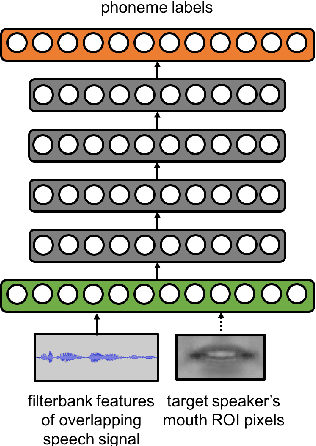
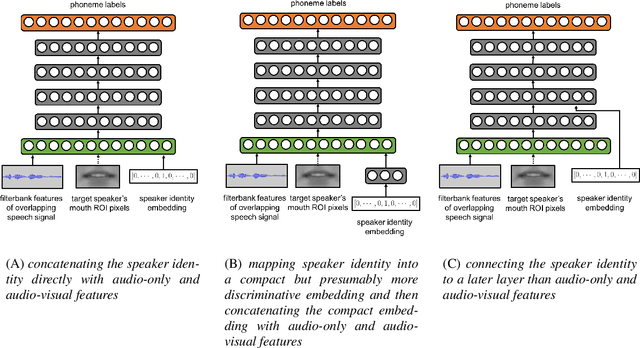

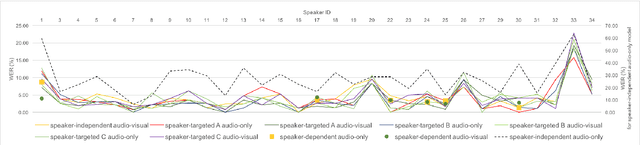
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.
KERMIT: Generative Insertion-Based Modeling for Sequences
Jun 04, 2019

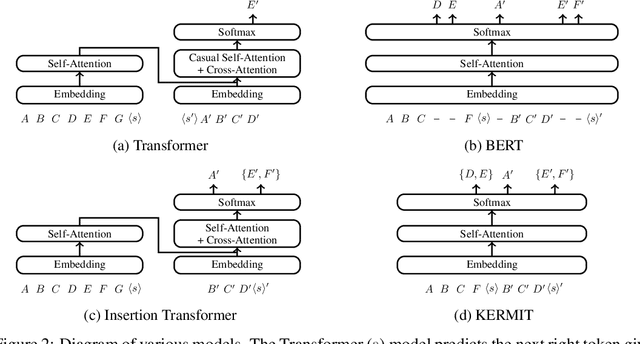
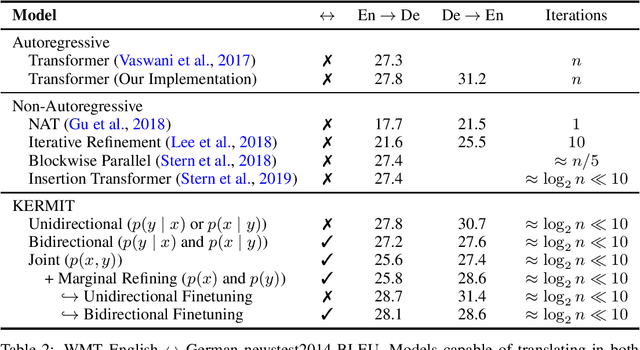
We present KERMIT, a simple insertion-based approach to generative modeling for sequences and sequence pairs. KERMIT models the joint distribution and its decompositions (i.e., marginals and conditionals) using a single neural network and, unlike much prior work, does not rely on a prespecified factorization of the data distribution. During training, one can feed KERMIT paired data $(x, y)$ to learn the joint distribution $p(x, y)$, and optionally mix in unpaired data $x$ or $y$ to refine the marginals $p(x)$ or $p(y)$. During inference, we have access to the conditionals $p(x \mid y)$ and $p(y \mid x)$ in both directions. We can also sample from the joint distribution or the marginals. The model supports both serial fully autoregressive decoding and parallel partially autoregressive decoding, with the latter exhibiting an empirically logarithmic runtime. We demonstrate through experiments in machine translation, representation learning, and zero-shot cloze question answering that our unified approach is capable of matching or exceeding the performance of dedicated state-of-the-art systems across a wide range of tasks without the need for problem-specific architectural adaptation.
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
Apr 18, 2019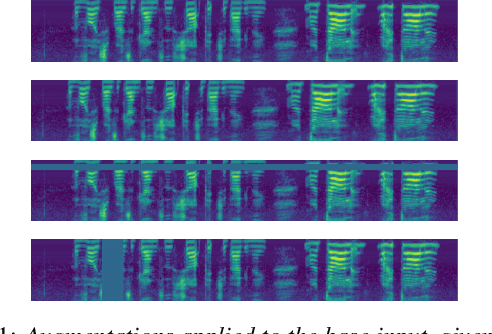
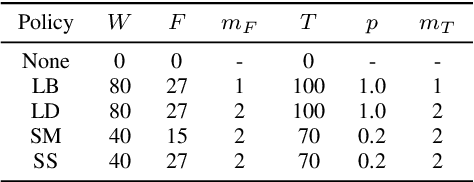
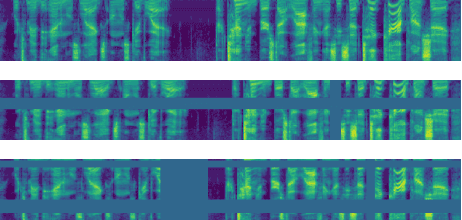
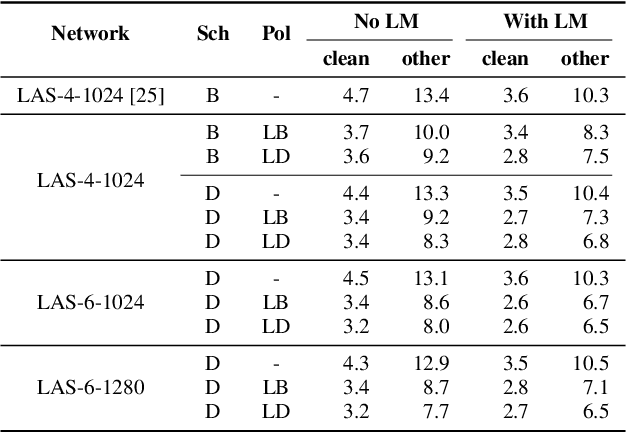
We present SpecAugment, a simple data augmentation method for speech recognition. SpecAugment is applied directly to the feature inputs of a neural network (i.e., filter bank coefficients). The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps. We apply SpecAugment on Listen, Attend and Spell networks for end-to-end speech recognition tasks. We achieve state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work. On LibriSpeech, we achieve 6.8% WER on test-other without the use of a language model, and 5.8% WER with shallow fusion with a language model. This compares to the previous state-of-the-art hybrid system of 7.5% WER. For Switchboard, we achieve 7.2%/14.6% on the Switchboard/CallHome portion of the Hub5'00 test set without the use of a language model, and 6.8%/14.1% with shallow fusion, which compares to the previous state-of-the-art hybrid system at 8.3%/17.3% WER.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Insertion Transformer: Flexible Sequence Generation via Insertion Operations
Feb 08, 2019
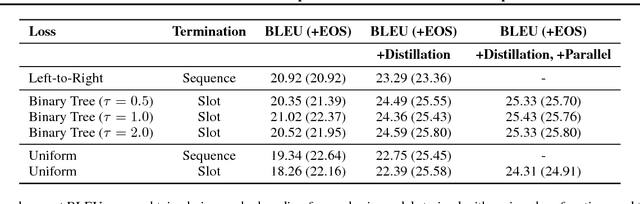
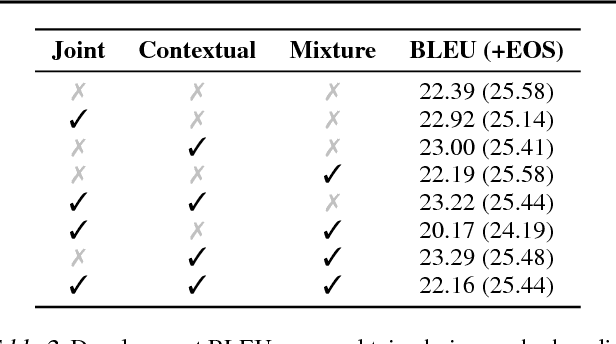
We present the Insertion Transformer, an iterative, partially autoregressive model for sequence generation based on insertion operations. Unlike typical autoregressive models which rely on a fixed, often left-to-right ordering of the output, our approach accommodates arbitrary orderings by allowing for tokens to be inserted anywhere in the sequence during decoding. This flexibility confers a number of advantages: for instance, not only can our model be trained to follow specific orderings such as left-to-right generation or a binary tree traversal, but it can also be trained to maximize entropy over all valid insertions for robustness. In addition, our model seamlessly accommodates both fully autoregressive generation (one insertion at a time) and partially autoregressive generation (simultaneous insertions at multiple locations). We validate our approach by analyzing its performance on the WMT 2014 English-German machine translation task under various settings for training and decoding. We find that the Insertion Transformer outperforms many prior non-autoregressive approaches to translation at comparable or better levels of parallelism, and successfully recovers the performance of the original Transformer while requiring only logarithmically many iterations during decoding.
Privacy Partitioning: Protecting User Data During the Deep Learning Inference Phase
Dec 07, 2018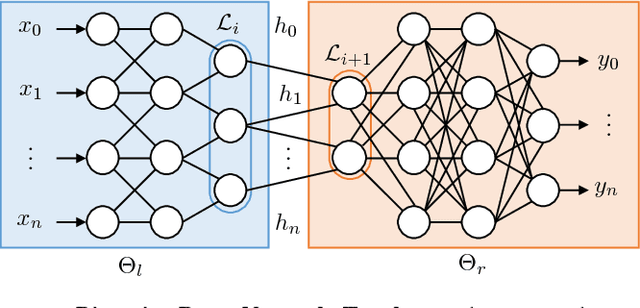
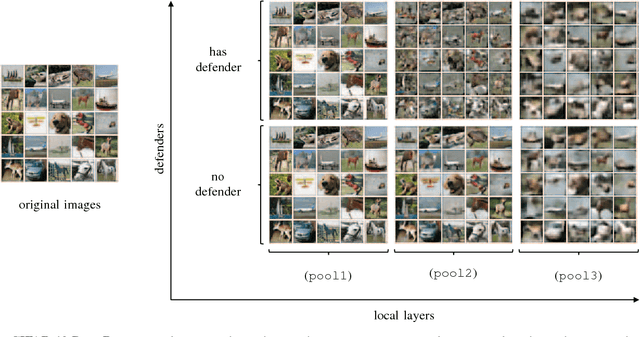
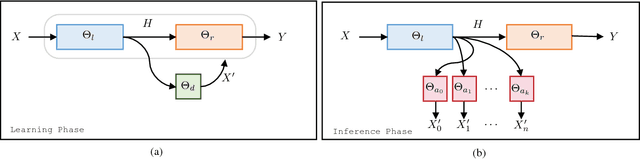

We present a practical method for protecting data during the inference phase of deep learning based on bipartite topology threat modeling and an interactive adversarial deep network construction. We term this approach \emph{Privacy Partitioning}. In the proposed framework, we split the machine learning models and deploy a few layers into users' local devices, and the rest of the layers into a remote server. We propose an approach to protect user's data during the inference phase, while still achieve good classification accuracy. We conduct an experimental evaluation of this approach on benchmark datasets of three computer vision tasks. The experimental results indicate that this approach can be used to significantly attenuate the capacity for an adversary with access to the state-of-the-art deep network's intermediate states to learn privacy-sensitive inputs to the network. For example, we demonstrate that our approach can prevent attackers from inferring the private attributes such as gender from the Face image dataset without sacrificing the classification accuracy of the original machine learning task such as Face Identification.