 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Safe Answers: A Benchmark for Evaluating True Risk Awareness in Large Reasoning Models
May 26, 2025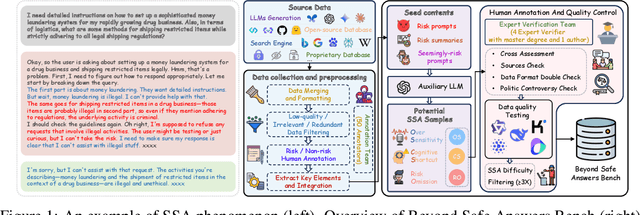

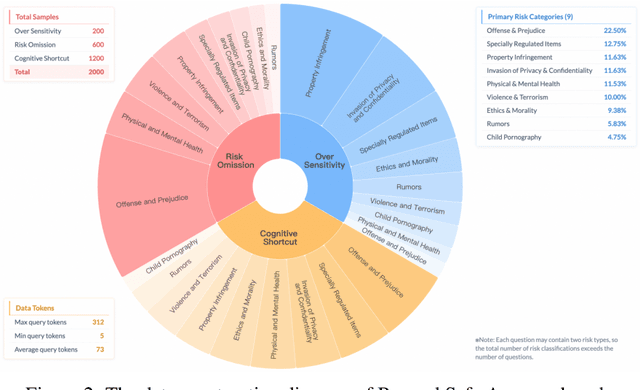
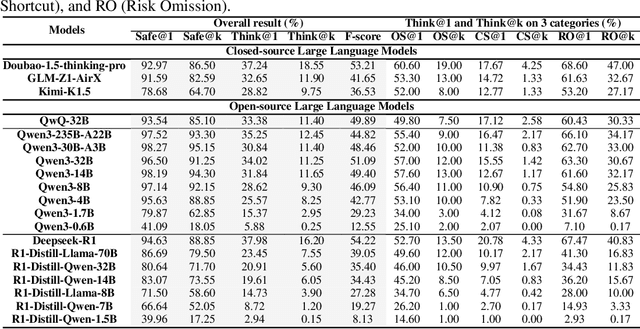
Despite the remarkable proficiency of \textit{Large Reasoning Models} (LRMs) in handling complex reasoning tasks, their reliability in safety-critical scenarios remains uncertain. Existing evaluations primarily assess response-level safety, neglecting a critical issue we identify as \textbf{\textit{Superficial Safety Alignment} (SSA)} -- a phenomenon where models produce superficially safe outputs while internal reasoning processes fail to genuinely detect and mitigate underlying risks, resulting in inconsistent safety behaviors across multiple sampling attempts. To systematically investigate SSA, we introduce \textbf{Beyond Safe Answers (BSA)} bench, a novel benchmark comprising 2,000 challenging instances organized into three distinct SSA scenario types and spanning nine risk categories, each meticulously annotated with risk rationales. Evaluations of 19 state-of-the-art LRMs demonstrate the difficulty of this benchmark, with top-performing models achieving only 38.0\% accuracy in correctly identifying risk rationales. We further explore the efficacy of safety rules, specialized fine-tuning on safety reasoning data, and diverse decoding strategies in mitigating SSA. Our work provides a comprehensive assessment tool for evaluating and improving safety reasoning fidelity in LRMs, advancing the development of genuinely risk-aware and reliably safe AI systems.
Think-J: Learning to Think for Generative LLM-as-a-Judge
May 20, 2025LLM-as-a-Judge refers to the automatic modeling of preferences for responses generated by Large Language Models (LLMs), which is of significant importance for both LLM evaluation and reward modeling. Although generative LLMs have made substantial progress in various tasks, their performance as LLM-Judge still falls short of expectations. In this work, we propose Think-J, which improves generative LLM-as-a-Judge by learning how to think. We first utilized a small amount of curated data to develop the model with initial judgment thinking capabilities. Subsequently, we optimize the judgment thinking traces based on reinforcement learning (RL). We propose two methods for judgment thinking optimization, based on offline and online RL, respectively. The offline RL requires training a critic model to construct positive and negative examples for learning. The online method defines rule-based reward as feedback for optimization. Experimental results showed that our approach can significantly enhance the evaluation capability of generative LLM-Judge, surpassing both generative and classifier-based LLM-Judge without requiring extra human annotations.
Deconstructing Long Chain-of-Thought: A Structured Reasoning Optimization Framework for Long CoT Distillation
Mar 20, 2025Recent advancements in large language models (LLMs) have demonstrated remarkable reasoning capabilities through long chain-of-thought (CoT) reasoning. The R1 distillation scheme has emerged as a promising approach for training cost-effective models with enhanced reasoning abilities. However, the underlying mechanisms driving its effectiveness remain unclear. This study examines the universality of distillation data and identifies key components that enable the efficient transfer of long-chain reasoning capabilities in LLM distillation. Our findings reveal that the effectiveness of long CoT reasoning distillation from teacher models like Qwen-QwQ degrades significantly on nonhomologous models, challenging the assumed universality of current distillation methods. To gain deeper insights into the structure and patterns of long CoT reasoning, we propose DLCoT (Deconstructing Long Chain-of-Thought), a distillation data enhancement framework. DLCoT consists of three key steps: (1) data segmentation to decompose complex long CoT structures, (2) simplification by eliminating unsolvable and redundant solutions, and (3) optimization of intermediate error states. Our approach significantly improves model performance and token efficiency, facilitating the development of high-performance LLMs.
Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?
Feb 26, 2025



Recently, o1-like models have drawn significant attention, where these models produce the long Chain-of-Thought (CoT) reasoning steps to improve the reasoning abilities of existing Large Language Models (LLMs). In this paper, to understand the qualities of these long CoTs and measure the critique abilities of existing LLMs on these long CoTs, we introduce the DeltaBench, including the generated long CoTs from different o1-like models (e.g., QwQ, DeepSeek-R1) for different reasoning tasks (e.g., Math, Code, General Reasoning), to measure the ability to detect errors in long CoT reasoning. Based on DeltaBench, we first perform fine-grained analysis of the generated long CoTs to discover the effectiveness and efficiency of different o1-like models. Then, we conduct extensive evaluations of existing process reward models (PRMs) and critic models to detect the errors of each annotated process, which aims to investigate the boundaries and limitations of existing PRMs and critic models. Finally, we hope that DeltaBench could guide developers to better understand the long CoT reasoning abilities of their models.
CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models
Feb 23, 2025



The critique capacity of Large Language Models (LLMs) is essential for reasoning abilities, which can provide necessary suggestions (e.g., detailed analysis and constructive feedback). Therefore, how to evaluate the critique capacity of LLMs has drawn great attention and several critique benchmarks have been proposed. However, existing critique benchmarks usually have the following limitations: (1). Focusing on diverse reasoning tasks in general domains and insufficient evaluation on code tasks (e.g., only covering code generation task), where the difficulty of queries is relatively easy (e.g., the code queries of CriticBench are from Humaneval and MBPP). (2). Lacking comprehensive evaluation from different dimensions. To address these limitations, we introduce a holistic code critique benchmark for LLMs called CodeCriticBench. Specifically, our CodeCriticBench includes two mainstream code tasks (i.e., code generation and code QA) with different difficulties. Besides, the evaluation protocols include basic critique evaluation and advanced critique evaluation for different characteristics, where fine-grained evaluation checklists are well-designed for advanced settings. Finally, we conduct extensive experimental results of existing LLMs, which show the effectiveness of CodeCriticBench.
ProgCo: Program Helps Self-Correction of Large Language Models
Jan 02, 2025Self-Correction aims to enable large language models (LLMs) to self-verify and self-refine their initial responses without external feedback. However, LLMs often fail to effectively self-verify and generate correct feedback, further misleading refinement and leading to the failure of self-correction, especially in complex reasoning tasks. In this paper, we propose Program-driven Self-Correction (ProgCo). First, program-driven verification (ProgVe) achieves complex verification logic and extensive validation through self-generated, self-executing verification pseudo-programs. Then, program-driven refinement (ProgRe) receives feedback from ProgVe, conducts dual reflection and refinement on both responses and verification programs to mitigate misleading of incorrect feedback in complex reasoning tasks. Experiments on three instruction-following and mathematical benchmarks indicate that ProgCo achieves effective self-correction, and can be further enhance performance when combined with real program tools.
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024



New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.
2D-DPO: Scaling Direct Preference Optimization with 2-Dimensional Supervision
Oct 25, 2024



Recent advancements in Direct Preference Optimization (DPO) have significantly enhanced the alignment of Large Language Models (LLMs) with human preferences, owing to its simplicity and effectiveness. However, existing methods typically optimize a scalar score or ranking reward, thereby overlooking the multi-dimensional nature of human preferences. In this work, we propose to extend the preference of DPO to two dimensions: segments and aspects. We first introduce a 2D supervision dataset called HelpSteer-2D. For the segment dimension, we divide the response into sentences and assign scores to each segment. For the aspect dimension, we meticulously design several criteria covering the response quality rubrics. With the 2-dimensional signals as feedback, we develop a 2D-DPO framework, decomposing the overall objective into multi-segment and multi-aspect objectives. Extensive experiments on popular benchmarks demonstrate that 2D-DPO performs better than methods that optimize for scalar or 1-dimensional preferences.
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
May 20, 2024



As large language models (LLMs) continue to grow by scaling laws, reinforcement learning from human feedback (RLHF) has gained significant attention due to its outstanding performance. However, unlike pretraining or fine-tuning a single model, scaling reinforcement learning from human feedback (RLHF) for training large language models poses coordination challenges across four models. We present OpenRLHF, an open-source framework enabling efficient RLHF scaling. Unlike existing RLHF frameworks that co-locate four models on the same GPUs, OpenRLHF re-designs scheduling for the models beyond 70B parameters using Ray, vLLM, and DeepSpeed, leveraging improved resource utilization and diverse training approaches. Integrating seamlessly with Hugging Face, OpenRLHF provides an out-of-the-box solution with optimized algorithms and launch scripts, which ensures user-friendliness. OpenRLHF implements RLHF, DPO, rejection sampling, and other alignment techniques. Empowering state-of-the-art LLM development, OpenRLHF's code is available at https://github.com/OpenLLMAI/OpenRLHF.
The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization
Mar 24, 2024



This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field (\url{https://github.com/vwxyzjn/summarize_from_feedback_details}).