 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Physics-Related Intelligent Mixture of Experts for Transistor Characteristics Prediction
May 10, 2025In recent years, machine learning has been extensively applied to data prediction during process ramp-up, with a particular focus on transistor characteristics for circuit design and manufacture. However, capturing the nonlinear current response across multiple operating regions remains a challenge for neural networks. To address such challenge, a novel machine learning framework, PRIME (Physics-Related Intelligent Mixture of Experts), is proposed to capture and integrate complex regional characteristics. In essence, our framework incorporates physics-based knowledge with data-driven intelligence. By leveraging a dynamic weighting mechanism in its gating network, PRIME adaptively activates the suitable expert model based on distinct input data features. Extensive evaluations are conducted on various gate-all-around (GAA) structures to examine the effectiveness of PRIME and considerable improvements (60\%-84\%) in prediction accuracy are shown over state-of-the-art models.
CIMFlow: An Integrated Framework for Systematic Design and Evaluation of Digital CIM Architectures
May 02, 2025Digital Compute-in-Memory (CIM) architectures have shown great promise in Deep Neural Network (DNN) acceleration by effectively addressing the "memory wall" bottleneck. However, the development and optimization of digital CIM accelerators are hindered by the lack of comprehensive tools that encompass both software and hardware design spaces. Moreover, existing design and evaluation frameworks often lack support for the capacity constraints inherent in digital CIM architectures. In this paper, we present CIMFlow, an integrated framework that provides an out-of-the-box workflow for implementing and evaluating DNN workloads on digital CIM architectures. CIMFlow bridges the compilation and simulation infrastructures with a flexible instruction set architecture (ISA) design, and addresses the constraints of digital CIM through advanced partitioning and parallelism strategies in the compilation flow. Our evaluation demonstrates that CIMFlow enables systematic prototyping and optimization of digital CIM architectures across diverse configurations, providing researchers and designers with an accessible platform for extensive design space exploration.
HGNAS: Hardware-Aware Graph Neural Architecture Search for Edge Devices
Aug 23, 2024



Graph Neural Networks (GNNs) are becoming increasingly popular for graph-based learning tasks such as point cloud processing due to their state-of-the-art (SOTA) performance. Nevertheless, the research community has primarily focused on improving model expressiveness, lacking consideration of how to design efficient GNN models for edge scenarios with real-time requirements and limited resources. Examining existing GNN models reveals varied execution across platforms and frequent Out-Of-Memory (OOM) problems, highlighting the need for hardware-aware GNN design. To address this challenge, this work proposes a novel hardware-aware graph neural architecture search framework tailored for resource constraint edge devices, namely HGNAS. To achieve hardware awareness, HGNAS integrates an efficient GNN hardware performance predictor that evaluates the latency and peak memory usage of GNNs in milliseconds. Meanwhile, we study GNN memory usage during inference and offer a peak memory estimation method, enhancing the robustness of architecture evaluations when combined with predictor outcomes. Furthermore, HGNAS constructs a fine-grained design space to enable the exploration of extreme performance architectures by decoupling the GNN paradigm. In addition, the multi-stage hierarchical search strategy is leveraged to facilitate the navigation of huge candidates, which can reduce the single search time to a few GPU hours. To the best of our knowledge, HGNAS is the first automated GNN design framework for edge devices, and also the first work to achieve hardware awareness of GNNs across different platforms. Extensive experiments across various applications and edge devices have proven the superiority of HGNAS. It can achieve up to a 10.6x speedup and an 82.5% peak memory reduction with negligible accuracy loss compared to DGCNN on ModelNet40.
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Apr 08, 2024



The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9\times$ speedup and $98.2\%$ energy reduction compared to existing approaches across various applications and system configurations.
TinyFormer: Efficient Transformer Design and Deployment on Tiny Devices
Nov 03, 2023



Developing deep learning models on tiny devices (e.g. Microcontroller units, MCUs) has attracted much attention in various embedded IoT applications. However, it is challenging to efficiently design and deploy recent advanced models (e.g. transformers) on tiny devices due to their severe hardware resource constraints. In this work, we propose TinyFormer, a framework specifically designed to develop and deploy resource-efficient transformers on MCUs. TinyFormer mainly consists of SuperNAS, SparseNAS and SparseEngine. Separately, SuperNAS aims to search for an appropriate supernet from a vast search space. SparseNAS evaluates the best sparse single-path model including transformer architecture from the identified supernet. Finally, SparseEngine efficiently deploys the searched sparse models onto MCUs. To the best of our knowledge, SparseEngine is the first deployment framework capable of performing inference of sparse models with transformer on MCUs. Evaluation results on the CIFAR-10 dataset demonstrate that TinyFormer can develop efficient transformers with an accuracy of $96.1\%$ while adhering to hardware constraints of $1$MB storage and $320$KB memory. Additionally, TinyFormer achieves significant speedups in sparse inference, up to $12.2\times$, when compared to the CMSIS-NN library. TinyFormer is believed to bring powerful transformers into TinyML scenarios and greatly expand the scope of deep learning applications.
DDC-PIM: Efficient Algorithm/Architecture Co-design for Doubling Data Capacity of SRAM-based Processing-In-Memory
Oct 31, 2023Processing-in-memory (PIM), as a novel computing paradigm, provides significant performance benefits from the aspect of effective data movement reduction. SRAM-based PIM has been demonstrated as one of the most promising candidates due to its endurance and compatibility. However, the integration density of SRAM-based PIM is much lower than other non-volatile memory-based ones, due to its inherent 6T structure for storing a single bit. Within comparable area constraints, SRAM-based PIM exhibits notably lower capacity. Thus, aiming to unleash its capacity potential, we propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity. At the algorithmic level, we propose a filter-wise complementary correlation (FCC) algorithm to obtain a bitwise complementary pair. At the architecture level, we exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states ($Q/\overline{Q}$), thereby maximizing the data capacity of each SRAM cell. The dual-broadcast input structure and reconfigurable unit support both depthwise and pointwise convolution, adhering to the requirements of various neural networks. Evaluation results show that DDC-PIM yields about $2.84\times$ speedup on MobileNetV2 and $2.69\times$ on EfficientNet-B0 with negligible accuracy loss compared with PIM baseline implementation. Compared with state-of-the-art SRAM-based PIM macros, DDC-PIM achieves up to $8.41\times$ and $2.75\times$ improvement in weight density and area efficiency, respectively.
Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms
Mar 20, 2023



Graph neural networks (GNNs) have emerged as a popular strategy for handling non-Euclidean data due to their state-of-the-art performance. However, most of the current GNN model designs mainly focus on task accuracy, lacking in considering hardware resources limitation and real-time requirements of edge application scenarios. Comprehensive profiling of typical GNN models indicates that their execution characteristics are significantly affected across different computing platforms, which demands hardware awareness for efficient GNN designs. In this work, HGNAS is proposed as the first Hardware-aware Graph Neural Architecture Search framework targeting resource constraint edge devices. By decoupling the GNN paradigm, HGNAS constructs a fine-grained design space and leverages an efficient multi-stage search strategy to explore optimal architectures within a few GPU hours. Moreover, HGNAS achieves hardware awareness during the GNN architecture design by leveraging a hardware performance predictor, which could balance the GNN model accuracy and efficiency corresponding to the characteristics of targeted devices. Experimental results show that HGNAS can achieve about $10.6\times$ speedup and $88.2\%$ peak memory reduction with a negligible accuracy loss compared to DGCNN on various edge devices, including Nvidia RTX3080, Jetson TX2, Intel i7-8700K and Raspberry Pi 3B+.
Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform
Mar 29, 2022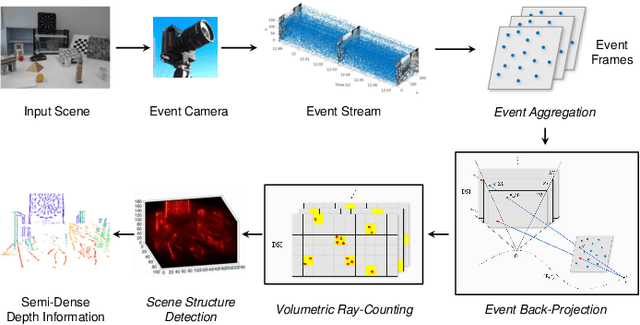
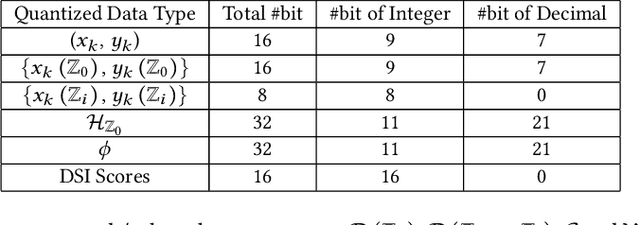
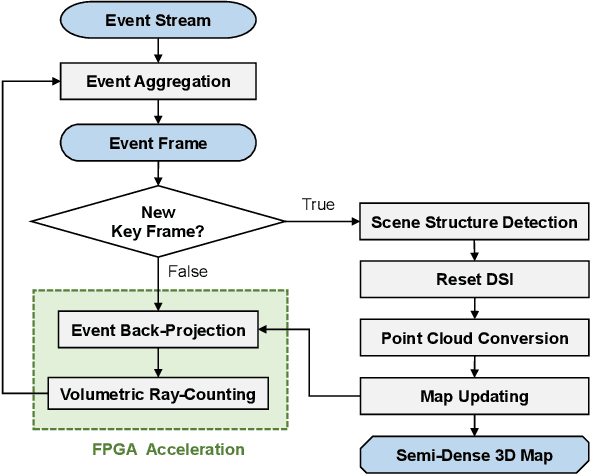
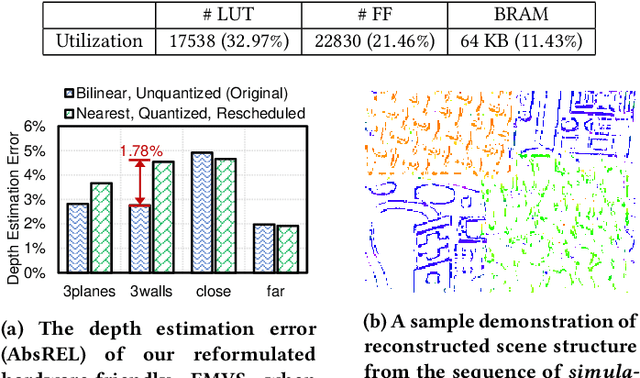
Event cameras are bio-inspired vision sensors that asynchronously represent pixel-level brightness changes as event streams. Event-based monocular multi-view stereo (EMVS) is a technique that exploits the event streams to estimate semi-dense 3D structure with known trajectory. It is a critical task for event-based monocular SLAM. However, the required intensive computation workloads make it challenging for real-time deployment on embedded platforms. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. Highly paralleled and fully pipelined processing elements are specially designed via FPGA and integrated with the embedded ARM as a heterogeneous system to improve the throughput and reduce the memory footprint. Meanwhile, the EMVS algorithm is reformulated to a more hardware-friendly manner by rescheduling, approximate computing and hybrid data quantization. Evaluation results on DAVIS dataset show that Eventor achieves up to $24\times$ improvement in energy efficiency compared with Intel i5 CPU platform.
FedSkel: Efficient Federated Learning on Heterogeneous Systems with Skeleton Gradients Update
Aug 20, 2021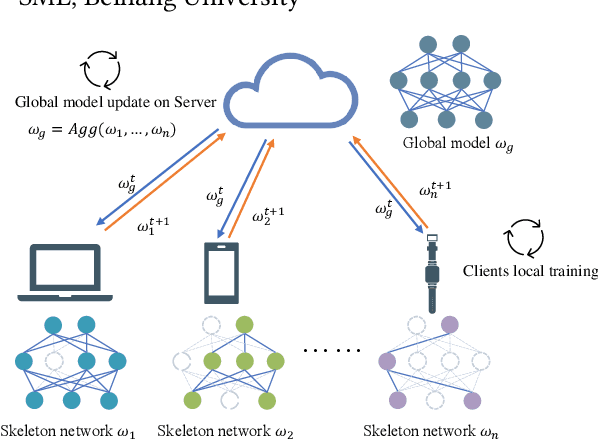
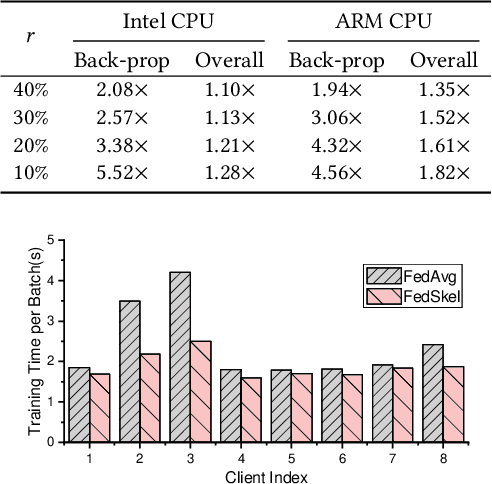
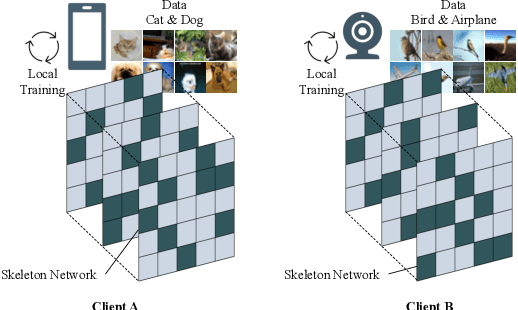

Federated learning aims to protect users' privacy while performing data analysis from different participants. However, it is challenging to guarantee the training efficiency on heterogeneous systems due to the various computational capabilities and communication bottlenecks. In this work, we propose FedSkel to enable computation-efficient and communication-efficient federated learning on edge devices by only updating the model's essential parts, named skeleton networks. FedSkel is evaluated on real edge devices with imbalanced datasets. Experimental results show that it could achieve up to 5.52$\times$ speedups for CONV layers' back-propagation, 1.82$\times$ speedups for the whole training process, and reduce 64.8% communication cost, with negligible accuracy loss.