 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarFormer: Multi-camera 3D Object Detection with Polar Transformers
Jul 12, 2022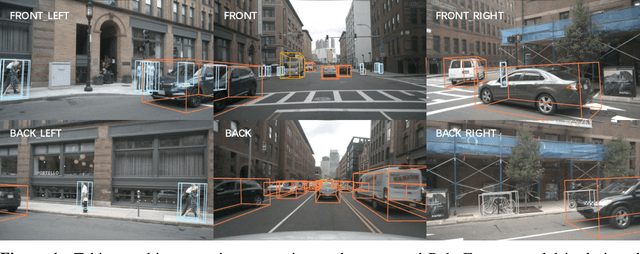
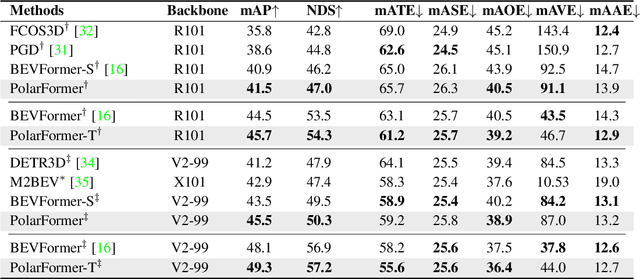
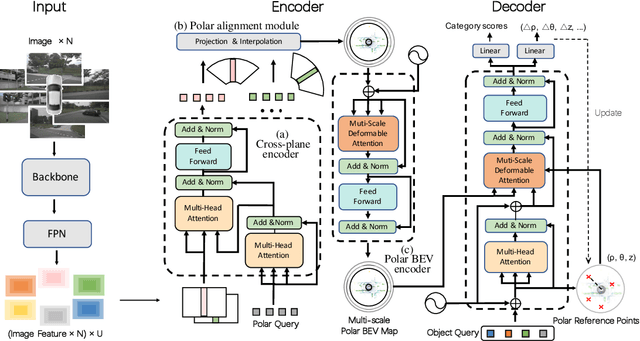
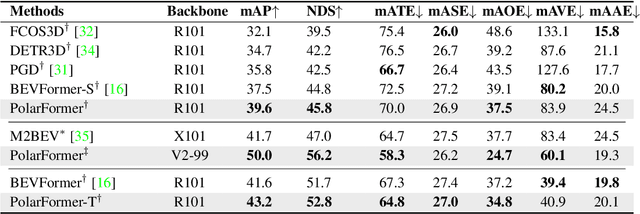
3D object detection in autonomous driving aims to reason "what" and "where" the objects of interest present in a 3D world. Following the conventional wisdom of previous 2D object detection, existing methods often adopt the canonical Cartesian coordinate system with perpendicular axis. However, we conjugate that this does not fit the nature of the ego car's perspective, as each onboard camera perceives the world in shape of wedge intrinsic to the imaging geometry with radical (non-perpendicular) axis. Hence, in this paper we advocate the exploitation of the Polar coordinate system and propose a new Polar Transformer (PolarFormer) for more accurate 3D object detection in the bird's-eye-view (BEV) taking as input only multi-camera 2D images. Specifically, we design a cross attention based Polar detection head without restriction to the shape of input structure to deal with irregular Polar grids. For tackling the unconstrained object scale variations along Polar's distance dimension, we further introduce a multi-scalePolar representation learning strategy. As a result, our model can make best use of the Polar representation rasterized via attending to the corresponding image observation in a sequence-to-sequence fashion subject to the geometric constraints. Thorough experiments on the nuScenes dataset demonstrate that our PolarFormer outperforms significantly state-of-the-art 3D object detection alternatives, as well as yielding competitive performance on BEV semantic segmentation task.
Cross-Architecture Knowledge Distillation
Jul 12, 2022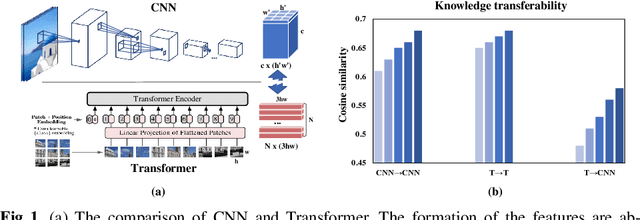
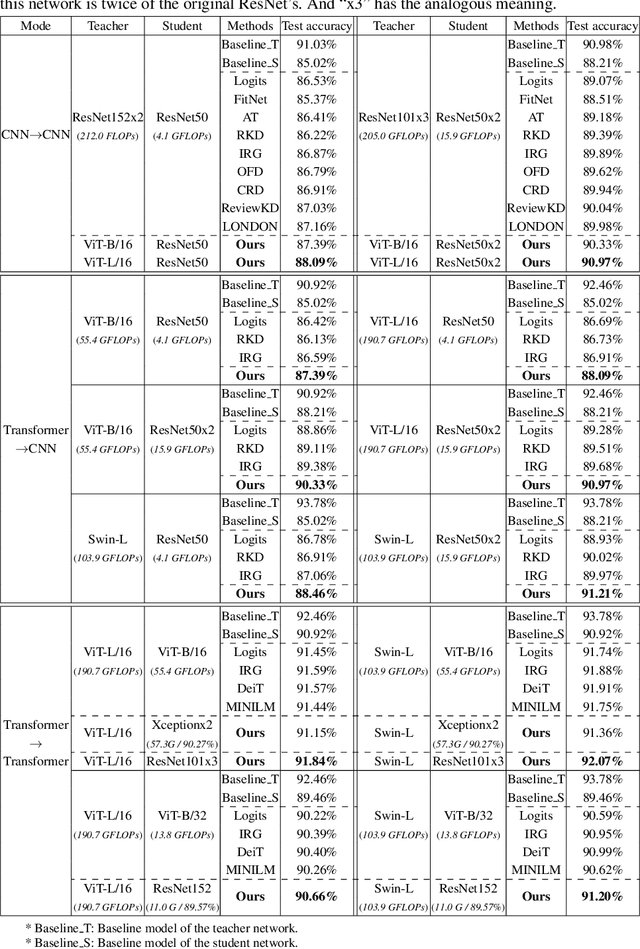
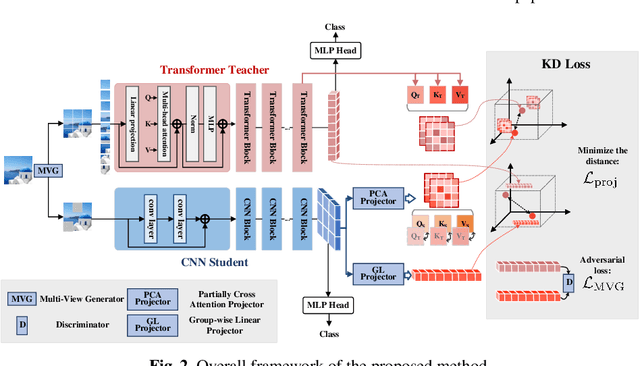
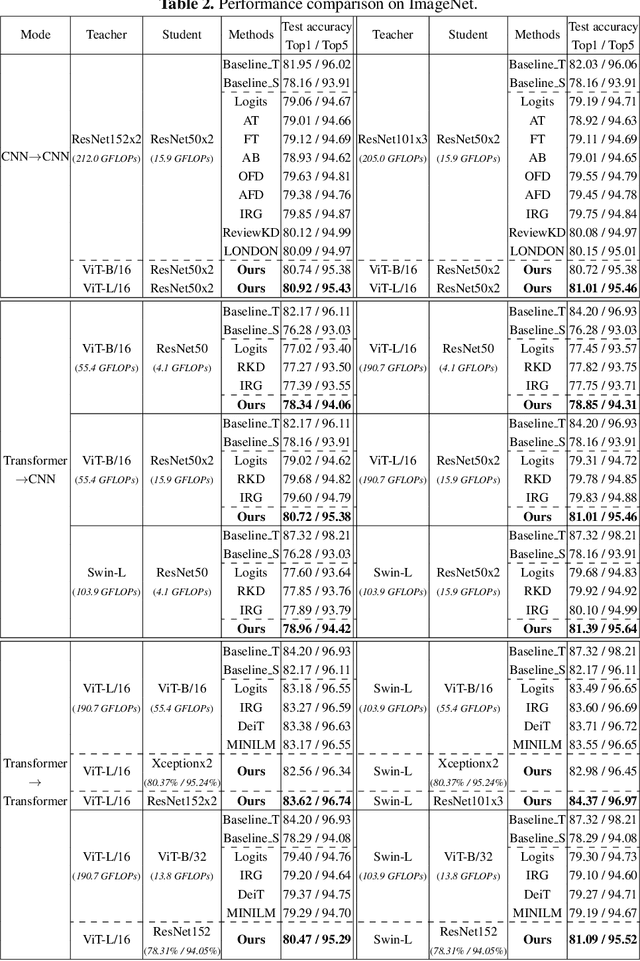
Transformer attracts much attention because of its ability to learn global relations and superior performance. In order to achieve higher performance, it is natural to distill complementary knowledge from Transformer to convolutional neural network (CNN). However, most existing knowledge distillation methods only consider homologous-architecture distillation, such as distilling knowledge from CNN to CNN. They may not be suitable when applying to cross-architecture scenarios, such as from Transformer to CNN. To deal with this problem, a novel cross-architecture knowledge distillation method is proposed. Specifically, instead of directly mimicking output/intermediate features of the teacher, a partially cross attention projector and a group-wise linear projector are introduced to align the student features with the teacher's in two projected feature spaces. And a multi-view robust training scheme is further presented to improve the robustness and stability of the framework. Extensive experiments show that the proposed method outperforms 14 state-of-the-arts on both small-scale and large-scale datasets.
PIC 4th Challenge: Semantic-Assisted Multi-Feature Encoding and Multi-Head Decoding for Dense Video Captioning
Jul 11, 2022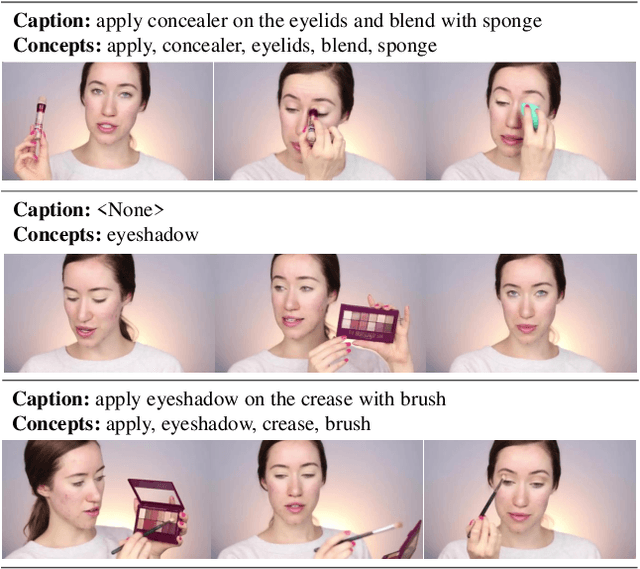
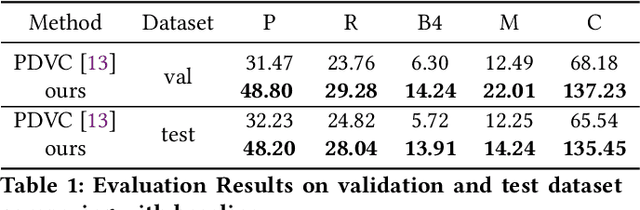
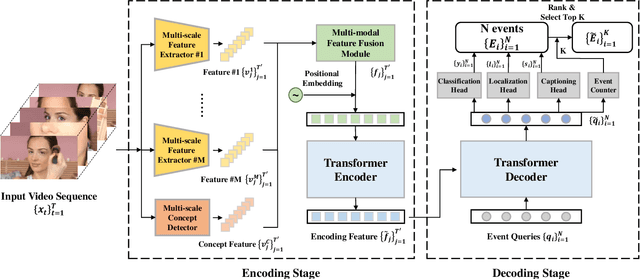
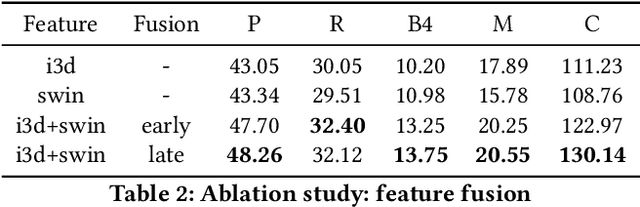
The task of Dense Video Captioning (DVC) aims to generate captions with timestamps for multiple events in one video. Semantic information plays an important role for both localization and description of DVC. We present a semantic-assisted dense video captioning model based on the encoding-decoding framework. In the encoding stage, we design a concept detector to extract semantic information, which is then fused with multi-modal visual features to sufficiently represent the input video. In the decoding stage, we design a classification head, paralleled with the localization and captioning heads, to provide semantic supervision. Our method achieves significant improvements on the YouMakeup dataset under DVC evaluation metrics and achieves high performance in the Makeup Dense Video Captioning (MDVC) task of PIC 4th Challenge.
SiamMask: A Framework for Fast Online Object Tracking and Segmentation
Jul 05, 2022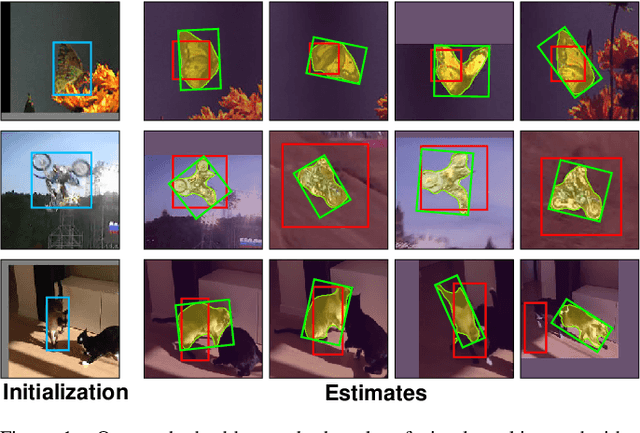
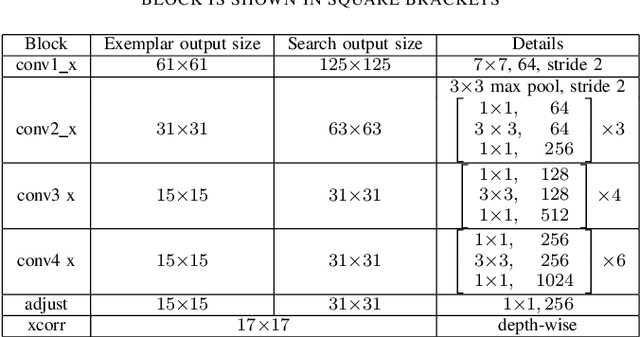
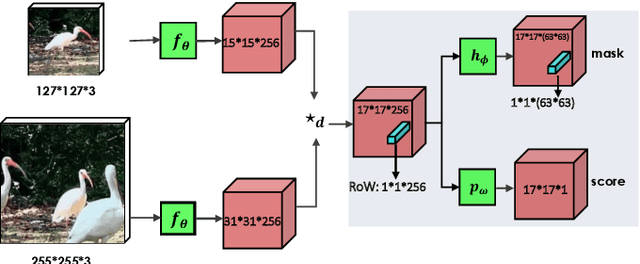
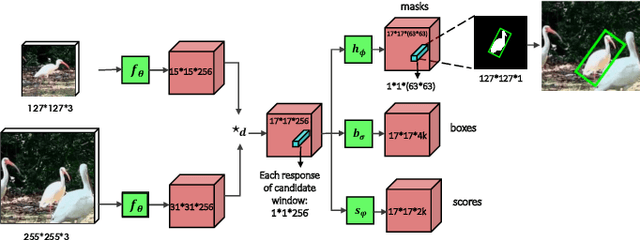
In this paper we introduce SiamMask, a framework to perform both visual object tracking and video object segmentation, in real-time, with the same simple method. We improve the offline training procedure of popular fully-convolutional Siamese approaches by augmenting their losses with a binary segmentation task. Once the offline training is completed, SiamMask only requires a single bounding box for initialization and can simultaneously carry out visual object tracking and segmentation at high frame-rates. Moreover, we show that it is possible to extend the framework to handle multiple object tracking and segmentation by simply re-using the multi-task model in a cascaded fashion. Experimental results show that our approach has high processing efficiency, at around 55 frames per second. It yields real-time state-of-the-art results on visual-object tracking benchmarks, while at the same time demonstrating competitive performance at a high speed for video object segmentation benchmarks.
* 17 pages, Accepted by TPAMI 2022. arXiv admin note: substantial text overlap with arXiv:1812.05050
Narrowing the Gap: Improved Detector Training with Noisy Location Annotations
Jun 12, 2022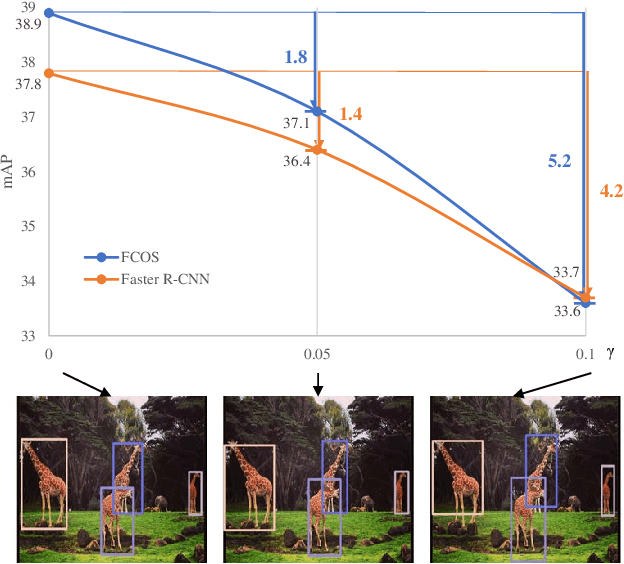
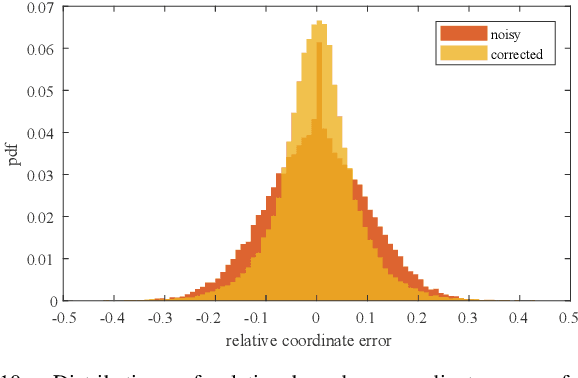

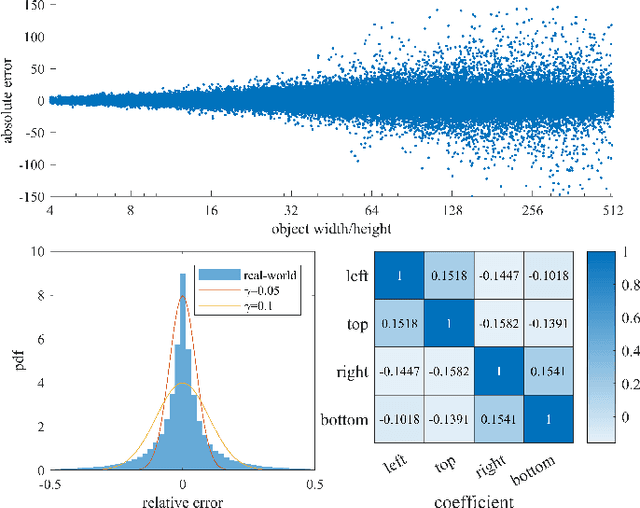
Deep learning methods require massive of annotated data for optimizing parameters. For example, datasets attached with accurate bounding box annotations are essential for modern object detection tasks. However, labeling with such pixel-wise accuracy is laborious and time-consuming, and elaborate labeling procedures are indispensable for reducing man-made noise, involving annotation review and acceptance testing. In this paper, we focus on the impact of noisy location annotations on the performance of object detection approaches and aim to, on the user side, reduce the adverse effect of the noise. First, noticeable performance degradation is experimentally observed for both one-stage and two-stage detectors when noise is introduced to the bounding box annotations. For instance, our synthesized noise results in performance decrease from 38.9% AP to 33.6% AP for FCOS detector on COCO test split, and 37.8%AP to 33.7%AP for Faster R-CNN. Second, a self-correction technique based on a Bayesian filter for prediction ensemble is proposed to better exploit the noisy location annotations following a Teacher-Student learning paradigm. Experiments for both synthesized and real-world scenarios consistently demonstrate the effectiveness of our approach, e.g., our method increases the degraded performance of the FCOS detector from 33.6% AP to 35.6% AP on COCO.
IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach
Jun 07, 2022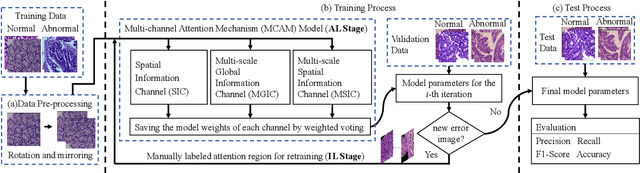
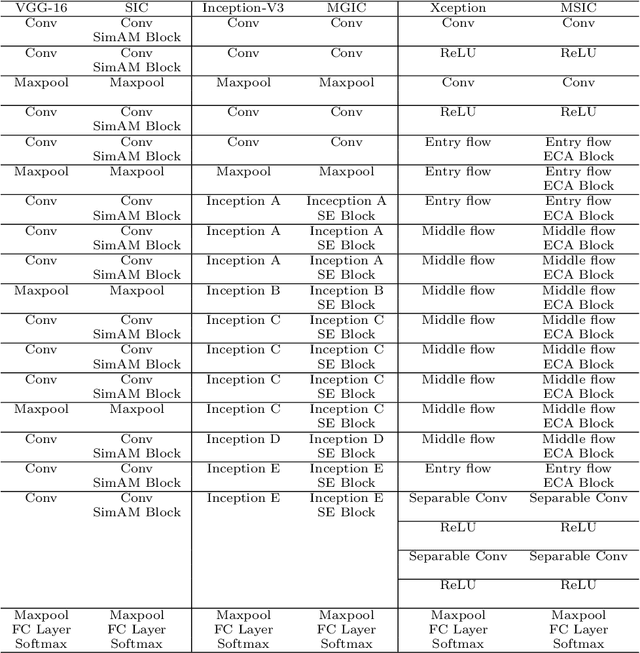
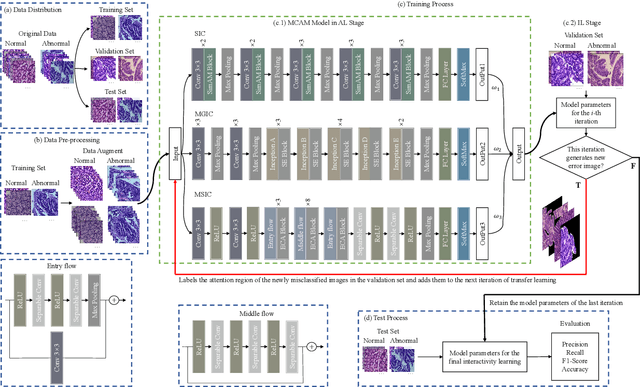
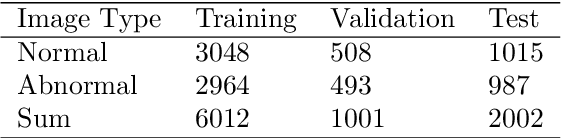
In recent years, colorectal cancer has become one of the most significant diseases that endanger human health. Deep learning methods are increasingly important for the classification of colorectal histopathology images. However, existing approaches focus more on end-to-end automatic classification using computers rather than human-computer interaction. In this paper, we propose an IL-MCAM framework. It is based on attention mechanisms and interactive learning. The proposed IL-MCAM framework includes two stages: automatic learning (AL) and interactivity learning (IL). In the AL stage, a multi-channel attention mechanism model containing three different attention mechanism channels and convolutional neural networks is used to extract multi-channel features for classification. In the IL stage, the proposed IL-MCAM framework continuously adds misclassified images to the training set in an interactive approach, which improves the classification ability of the MCAM model. We carried out a comparison experiment on our dataset and an extended experiment on the HE-NCT-CRC-100K dataset to verify the performance of the proposed IL-MCAM framework, achieving classification accuracies of 98.98% and 99.77%, respectively. In addition, we conducted an ablation experiment and an interchangeability experiment to verify the ability and interchangeability of the three channels. The experimental results show that the proposed IL-MCAM framework has excellent performance in the colorectal histopathological image classification tasks.
CVM-Cervix: A Hybrid Cervical Pap-Smear Image Classification Framework Using CNN, Visual Transformer and Multilayer Perceptron
Jun 02, 2022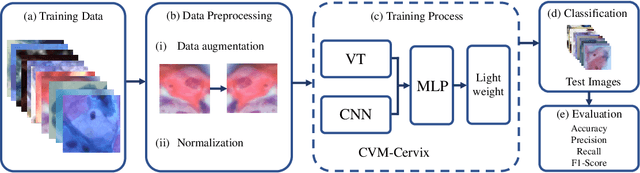
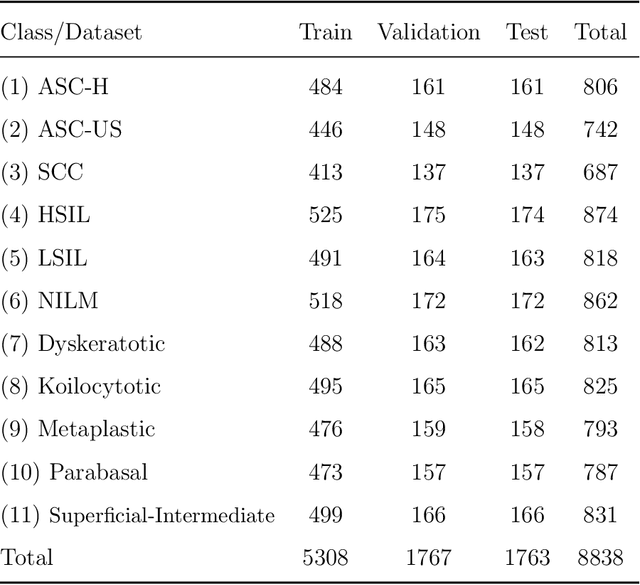
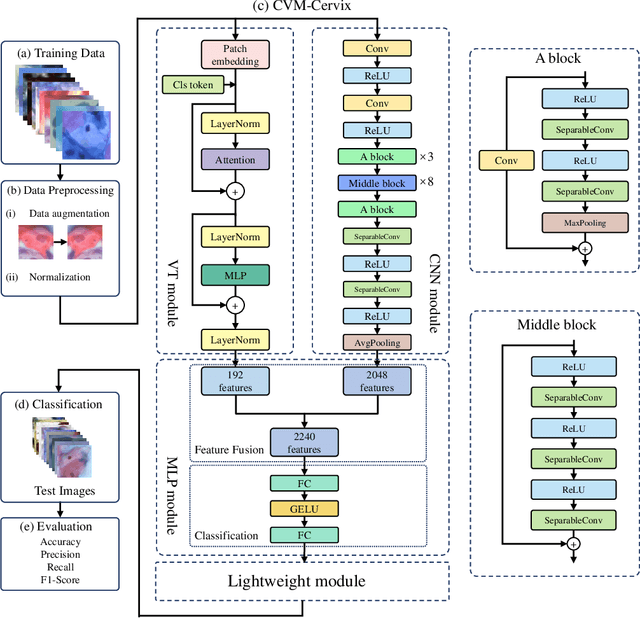
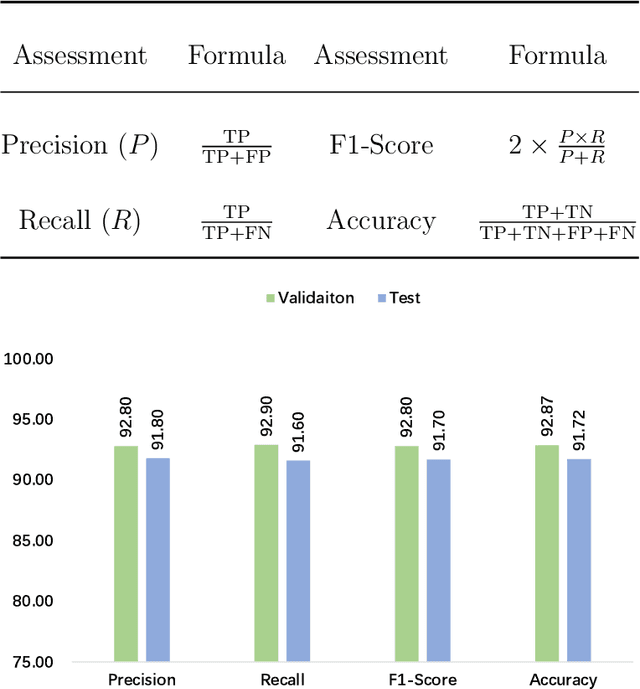
Cervical cancer is the seventh most common cancer among all the cancers worldwide and the fourth most common cancer among women. Cervical cytopathology image classification is an important method to diagnose cervical cancer. Manual screening of cytopathology images is time-consuming and error-prone. The emergence of the automatic computer-aided diagnosis system solves this problem. This paper proposes a framework called CVM-Cervix based on deep learning to perform cervical cell classification tasks. It can analyze pap slides quickly and accurately. CVM-Cervix first proposes a Convolutional Neural Network module and a Visual Transformer module for local and global feature extraction respectively, then a Multilayer Perceptron module is designed to fuse the local and global features for the final classification. Experimental results show the effectiveness and potential of the proposed CVM-Cervix in the field of cervical Pap smear image classification. In addition, according to the practical needs of clinical work, we perform a lightweight post-processing to compress the model.
A Closer Look at Self-supervised Lightweight Vision Transformers
May 28, 2022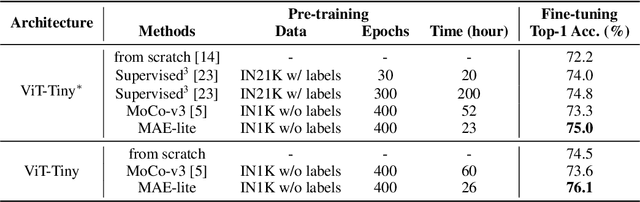
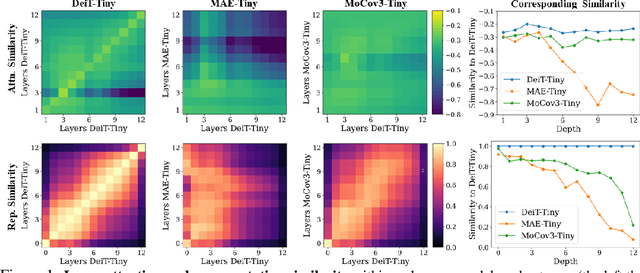
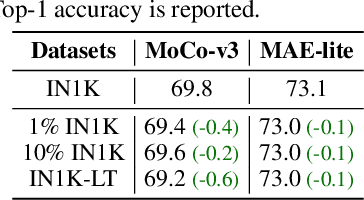
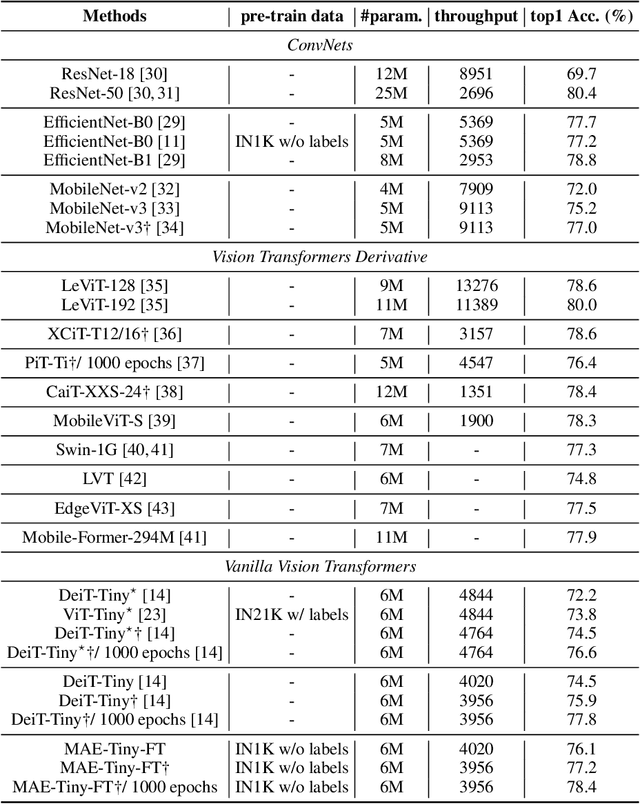
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.
A Comparative Study of Gastric Histopathology Sub-size Image Classification: from Linear Regression to Visual Transformer
May 25, 2022
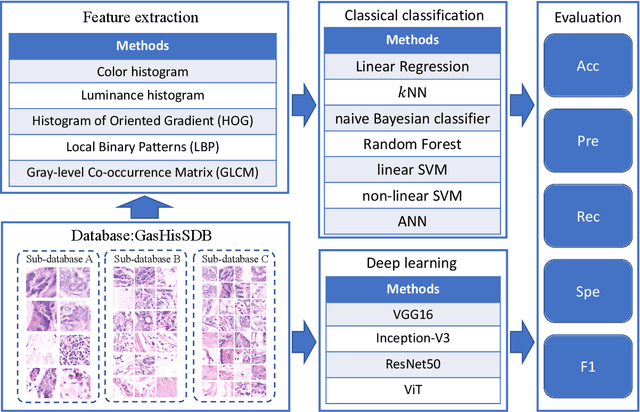

Gastric cancer is the fifth most common cancer in the world. At the same time, it is also the fourth most deadly cancer. Early detection of cancer exists as a guide for the treatment of gastric cancer. Nowadays, computer technology has advanced rapidly to assist physicians in the diagnosis of pathological pictures of gastric cancer. Ensemble learning is a way to improve the accuracy of algorithms, and finding multiple learning models with complementarity types is the basis of ensemble learning. The complementarity of sub-size pathology image classifiers when machine performance is insufficient is explored in this experimental platform. We choose seven classical machine learning classifiers and four deep learning classifiers for classification experiments on the GasHisSDB database. Among them, classical machine learning algorithms extract five different image virtual features to match multiple classifier algorithms. For deep learning, we choose three convolutional neural network classifiers. In addition, we also choose a novel Transformer-based classifier. The experimental platform, in which a large number of classical machine learning and deep learning methods are performed, demonstrates that there are differences in the performance of different classifiers on GasHisSDB. Classical machine learning models exist for classifiers that classify Abnormal categories very well, while classifiers that excel in classifying Normal categories also exist. Deep learning models also exist with multiple models that can be complementarity. Suitable classifiers are selected for ensemble learning, when machine performance is insufficient. This experimental platform demonstrates that multiple classifiers are indeed complementarity and can improve the efficiency of ensemble learning. This can better assist doctors in diagnosis, improve the detection of gastric cancer, and increase the cure rate.
Improving Visual Grounding with Visual-Linguistic Verification and Iterative Reasoning
Apr 30, 2022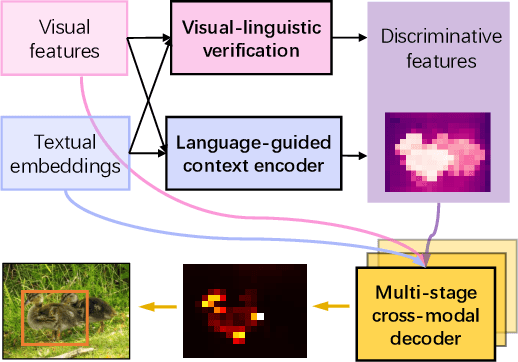
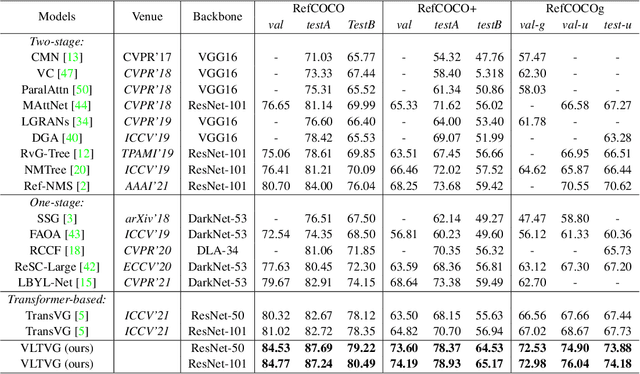
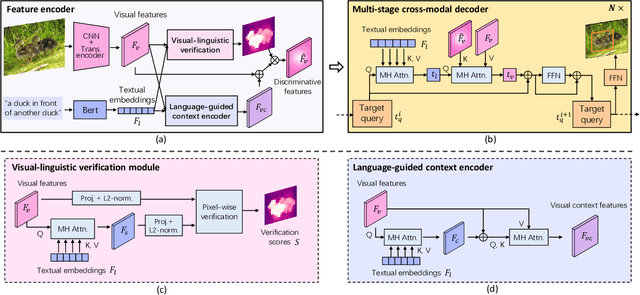
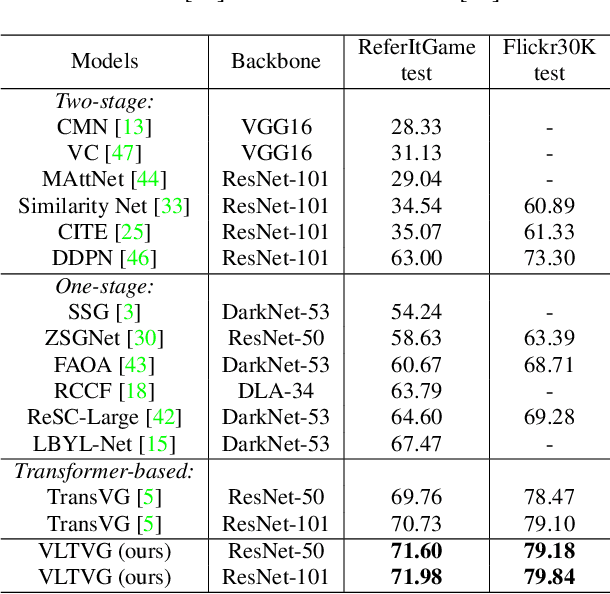
Visual grounding is a task to locate the target indicated by a natural language expression. Existing methods extend the generic object detection framework to this problem. They base the visual grounding on the features from pre-generated proposals or anchors, and fuse these features with the text embeddings to locate the target mentioned by the text. However, modeling the visual features from these predefined locations may fail to fully exploit the visual context and attribute information in the text query, which limits their performance. In this paper, we propose a transformer-based framework for accurate visual grounding by establishing text-conditioned discriminative features and performing multi-stage cross-modal reasoning. Specifically, we develop a visual-linguistic verification module to focus the visual features on regions relevant to the textual descriptions while suppressing the unrelated areas. A language-guided feature encoder is also devised to aggregate the visual contexts of the target object to improve the object's distinctiveness. To retrieve the target from the encoded visual features, we further propose a multi-stage cross-modal decoder to iteratively speculate on the correlations between the image and text for accurate target localization. Extensive experiments on five widely used datasets validate the efficacy of our proposed components and demonstrate state-of-the-art performance. Our code is public at https://github.com/yangli18/VLTVG.