 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
Jul 28, 2023



This paper presents the development and evaluation of ChatHome, a domain-specific language model (DSLM) designed for the intricate field of home renovation. Considering the proven competencies of large language models (LLMs) like GPT-4 and the escalating fascination with home renovation, this study endeavors to reconcile these aspects by generating a dedicated model that can yield high-fidelity, precise outputs relevant to the home renovation arena. ChatHome's novelty rests on its methodology, fusing domain-adaptive pretraining and instruction-tuning over an extensive dataset. This dataset includes professional articles, standard documents, and web content pertinent to home renovation. This dual-pronged strategy is designed to ensure that our model can assimilate comprehensive domain knowledge and effectively address user inquiries. Via thorough experimentation on diverse datasets, both universal and domain-specific, including the freshly introduced "EvalHome" domain dataset, we substantiate that ChatHome not only amplifies domain-specific functionalities but also preserves its versatility.
Analyzing Robustness of End-to-End Neural Models for Automatic Speech Recognition
Aug 17, 2022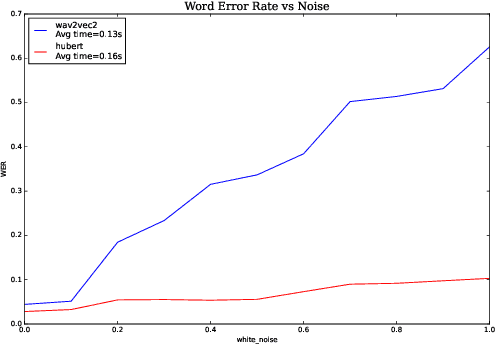
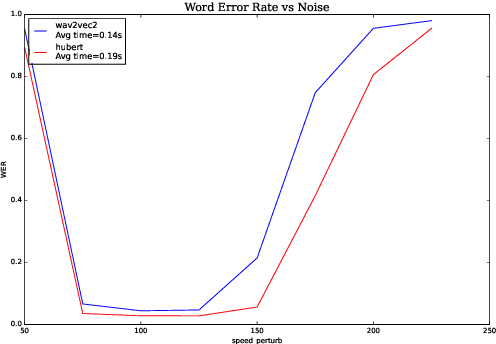
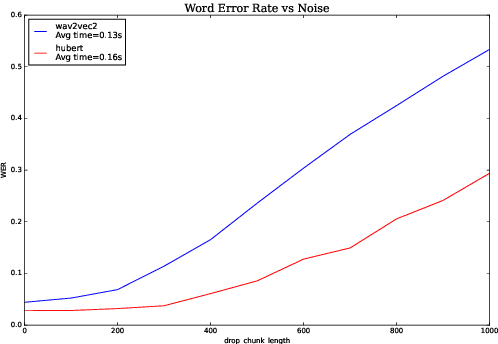
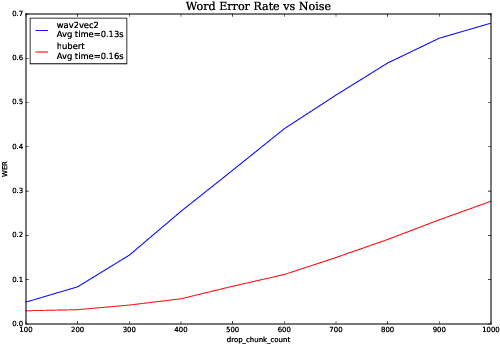
We investigate robustness properties of pre-trained neural models for automatic speech recognition. Real life data in machine learning is usually very noisy and almost never clean, which can be attributed to various factors depending on the domain, e.g. outliers, random noise and adversarial noise. Therefore, the models we develop for various tasks should be robust to such kinds of noisy data, which led to the thriving field of robust machine learning. We consider this important issue in the setting of automatic speech recognition. With the increasing popularity of pre-trained models, it's an important question to analyze and understand the robustness of such models to noise. In this work, we perform a robustness analysis of the pre-trained neural models wav2vec2, HuBERT and DistilHuBERT on the LibriSpeech and TIMIT datasets. We use different kinds of noising mechanisms and measure the model performances as quantified by the inference time and the standard Word Error Rate metric. We also do an in-depth layer-wise analysis of the wav2vec2 model when injecting noise in between layers, enabling us to predict at a high level what each layer learns. Finally for this model, we visualize the propagation of errors across the layers and compare how it behaves on clean versus noisy data. Our experiments conform the predictions of Pasad et al. [2021] and also raise interesting directions for future work.
DSLA: Dynamic smooth label assignment for efficient anchor-free object detection
Aug 01, 2022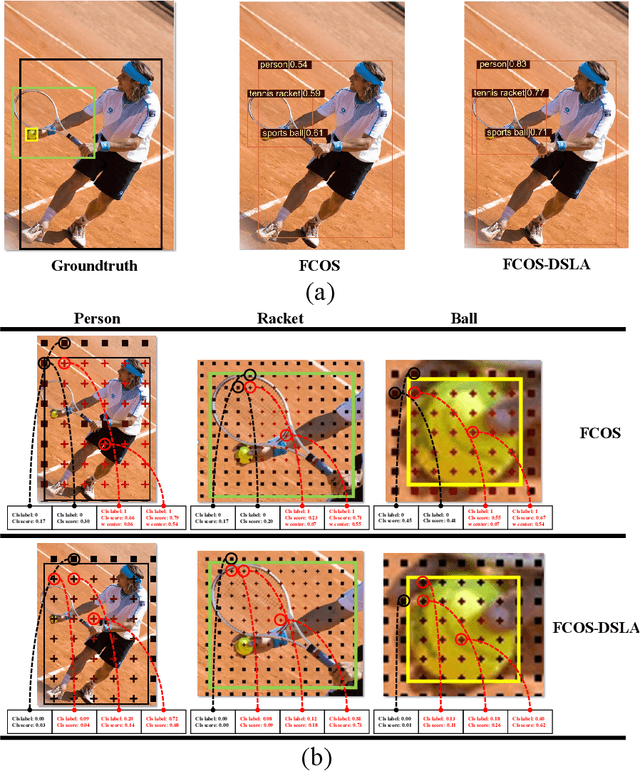
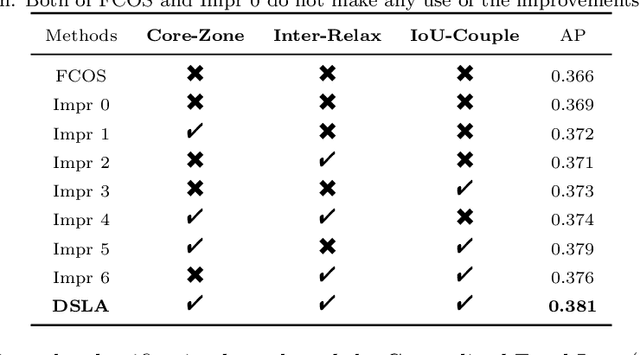

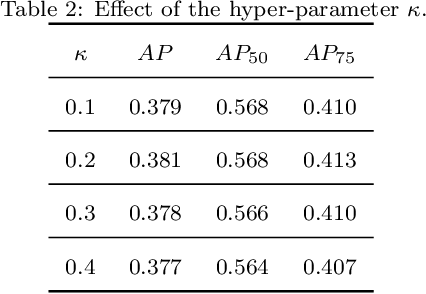
Anchor-free detectors basically formulate object detection as dense classification and regression. For popular anchor-free detectors, it is common to introduce an individual prediction branch to estimate the quality of localization. The following inconsistencies are observed when we delve into the practices of classification and quality estimation. Firstly, for some adjacent samples which are assigned completely different labels, the trained model would produce similar classification scores. This violates the training objective and leads to performance degradation. Secondly, it is found that detected bounding boxes with higher confidences contrarily have smaller overlaps with the corresponding ground-truth. Accurately localized bounding boxes would be suppressed by less accurate ones in the Non-Maximum Suppression (NMS) procedure. To address the inconsistency problems, the Dynamic Smooth Label Assignment (DSLA) method is proposed. Based on the concept of centerness originally developed in FCOS, a smooth assignment strategy is proposed. The label is smoothed to a continuous value in [0, 1] to make a steady transition between positive and negative samples. Intersection-of-Union (IoU) is predicted dynamically during training and is coupled with the smoothed label. The dynamic smooth label is assigned to supervise the classification branch. Under such supervision, quality estimation branch is naturally merged into the classification branch, which simplifies the architecture of anchor-free detector. Comprehensive experiments are conducted on the MS COCO benchmark. It is demonstrated that, DSLA can significantly boost the detection accuracy by alleviating the above inconsistencies for anchor-free detectors. Our codes are released at https://github.com/YonghaoHe/DSLA.
Audio-Visual Wake Word Spotting System For MISP Challenge 2021
Apr 20, 2022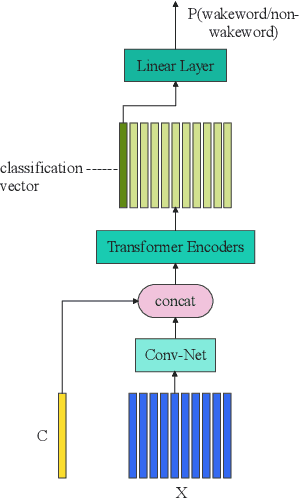
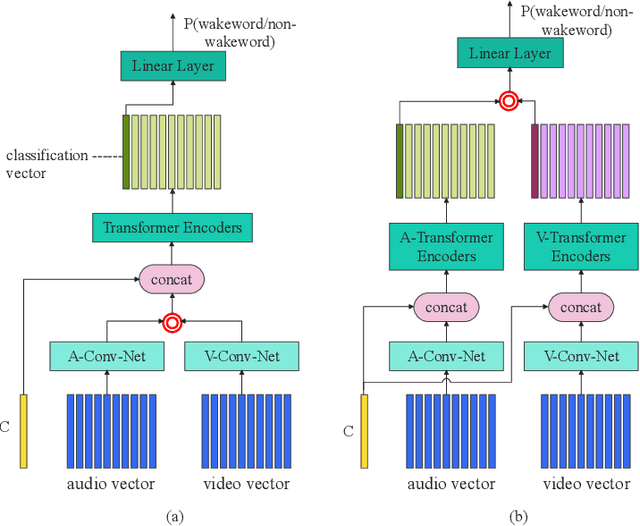

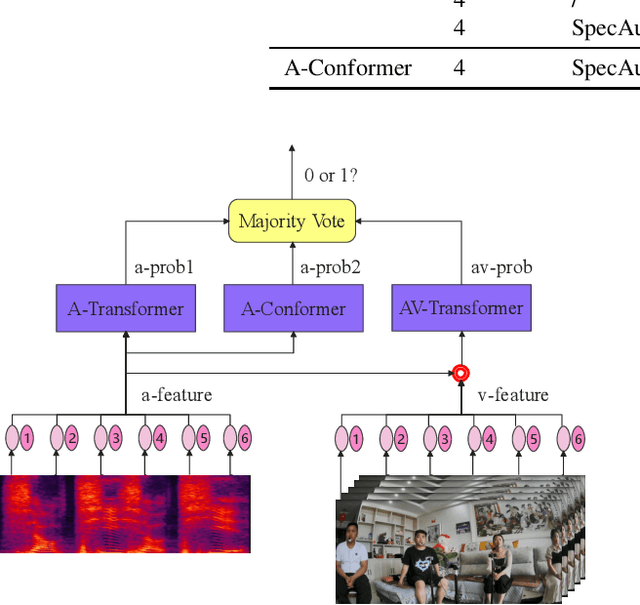
This paper presents the details of our system designed for the Task 1 of Multimodal Information Based Speech Processing (MISP) Challenge 2021. The purpose of Task 1 is to leverage both audio and video information to improve the environmental robustness of far-field wake word spotting. In the proposed system, firstly, we take advantage of speech enhancement algorithms such as beamforming and weighted prediction error (WPE) to address the multi-microphone conversational audio. Secondly, several data augmentation techniques are applied to simulate a more realistic far-field scenario. For the video information, the provided region of interest (ROI) is used to obtain visual representation. Then the multi-layer CNN is proposed to learn audio and visual representations, and these representations are fed into our two-branch attention-based network which can be employed for fusion, such as transformer and conformed. The focal loss is used to fine-tune the model and improve the performance significantly. Finally, multiple trained models are integrated by casting vote to achieve our final 0.091 score.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022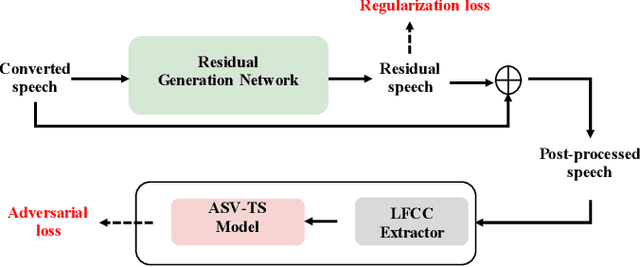

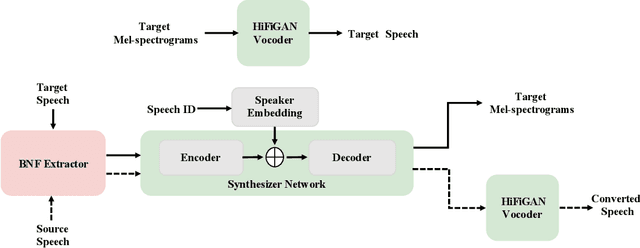
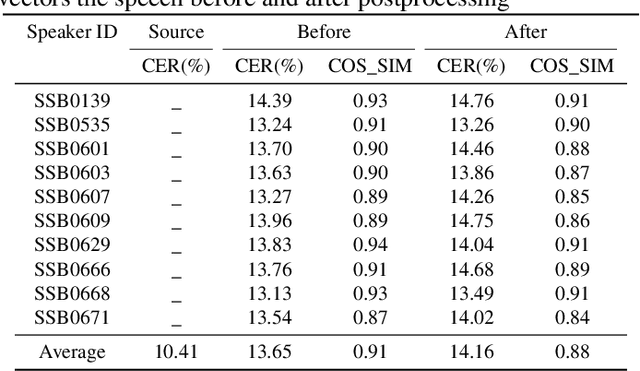
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.
Audio Deep Fake Detection System with Neural Stitching for ADD 2022
Apr 20, 2022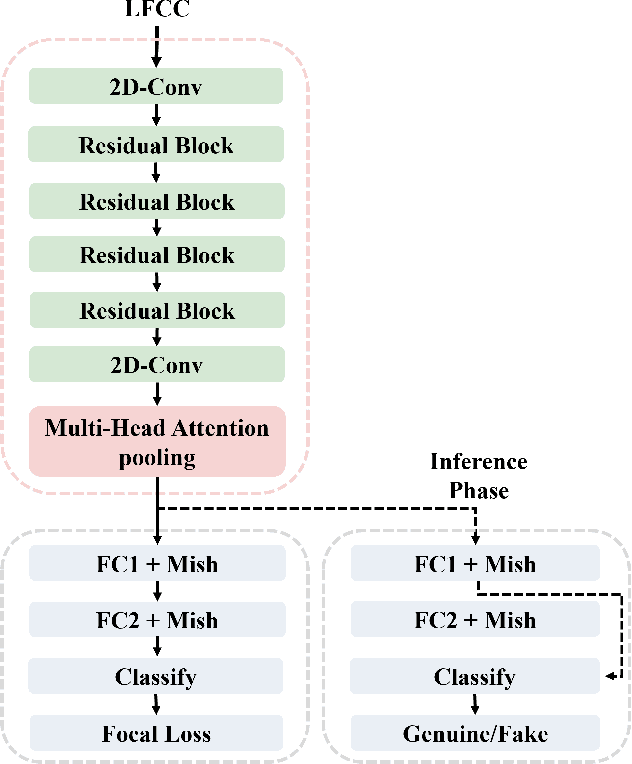
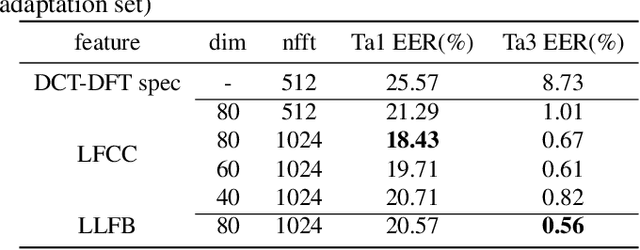


This paper describes our best system and methodology for ADD 2022: The First Audio Deep Synthesis Detection Challenge\cite{Yi2022ADD}. The very same system was used for both two rounds of evaluation in Track 3.2 with a similar training methodology. The first round of Track 3.2 data is generated from Text-to-Speech(TTS) or voice conversion (VC) algorithms, while the second round of data consists of generated fake audio from other participants in Track 3.1, aiming to spoof our systems. Our systems use a standard 34-layer ResNet, with multi-head attention pooling \cite{india2019self} to learn the discriminative embedding for fake audio and spoof detection. We further utilize neural stitching to boost the model's generalization capability in order to perform equally well in different tasks, and more details will be explained in the following sessions. The experiments show that our proposed method outperforms all other systems with a 10.1% equal error rate(EER) in Track 3.2.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021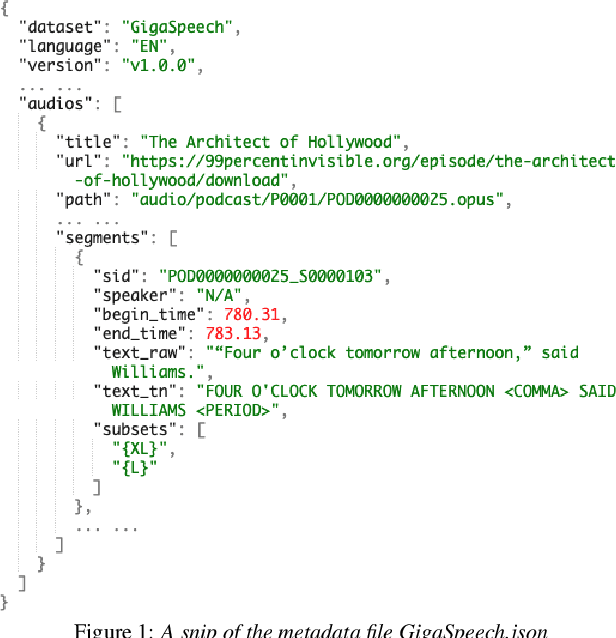
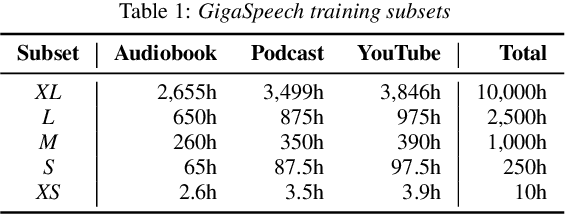
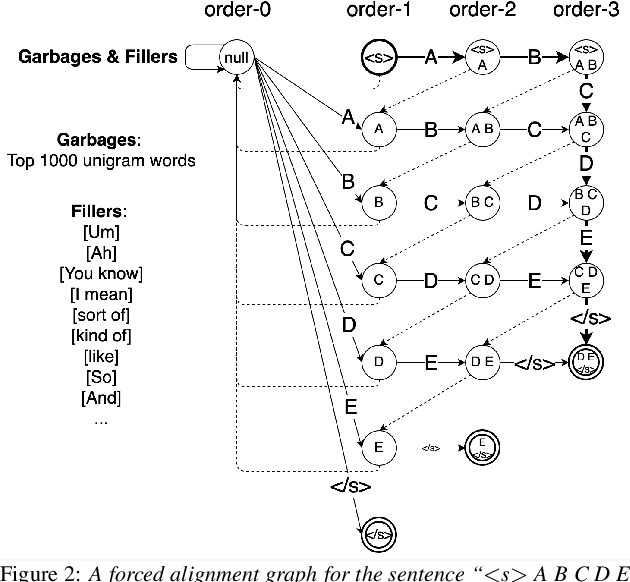
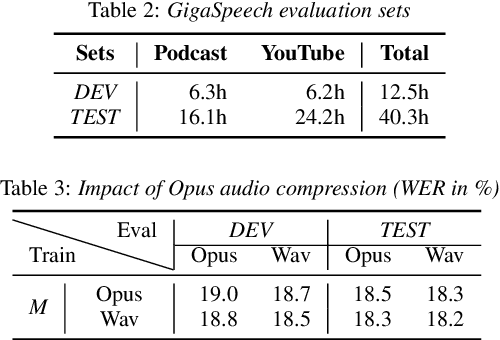
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Semantic Data Augmentation for End-to-End Mandarin Speech Recognition
Apr 26, 2021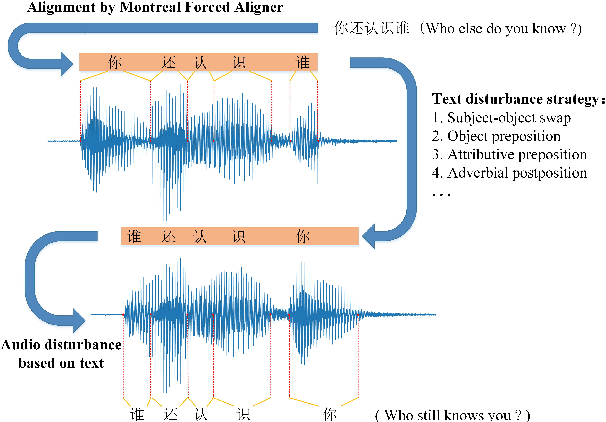


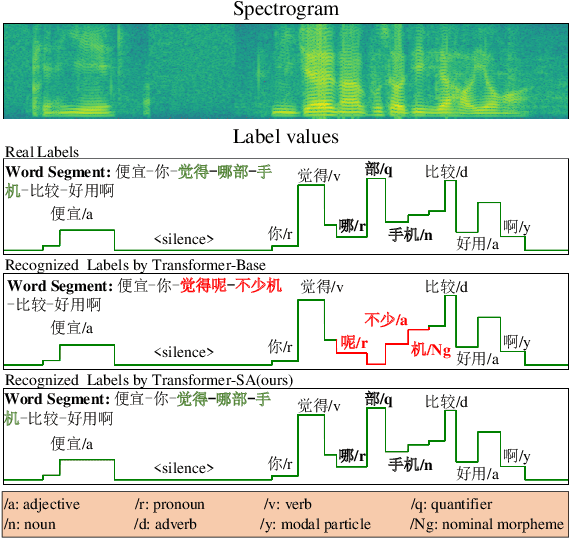
End-to-end models have gradually become the preferred option for automatic speech recognition (ASR) applications. During the training of end-to-end ASR, data augmentation is a quite effective technique for regularizing the neural networks. This paper proposes a novel data augmentation technique based on semantic transposition of the transcriptions via syntax rules for end-to-end Mandarin ASR. Specifically, we first segment the transcriptions based on part-of-speech tags. Then transposition strategies, such as placing the object in front of the subject or swapping the subject and the object, are applied on the segmented sentences. Finally, the acoustic features corresponding to the transposed transcription are reassembled based on the audio-to-text forced-alignment produced by a pre-trained ASR system. The combination of original data and augmented one is used for training a new ASR system. The experiments are conducted on the Transformer[2] and Conformer[3] based ASR. The results show that the proposed method can give consistent performance gain to the system. Augmentation related issues, such as comparison of different strategies and ratios for data combination are also investigated.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020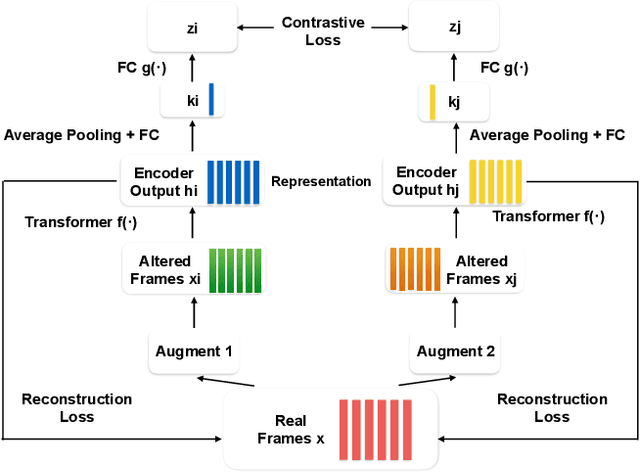

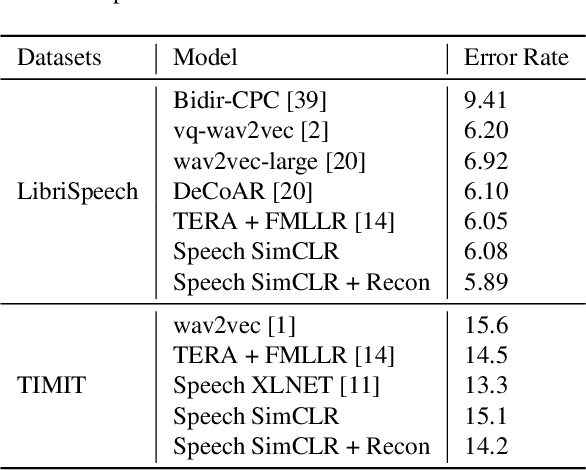

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.
TMT: A Transformer-based Modal Translator for Improving Multimodal Sequence Representations in Audio Visual Scene-aware Dialog
Oct 21, 2020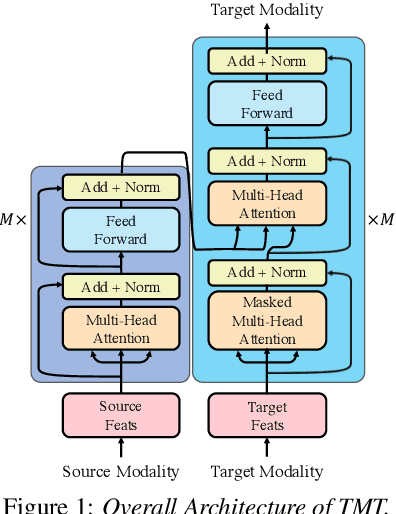
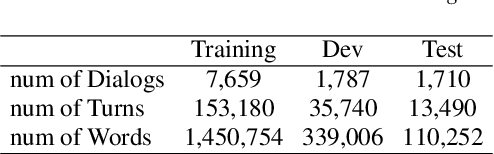
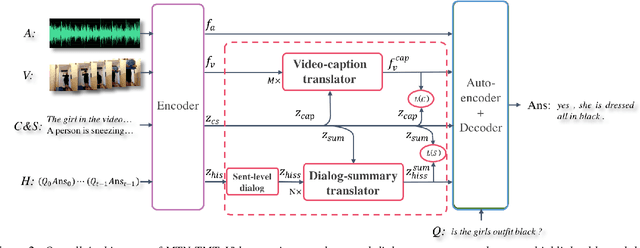
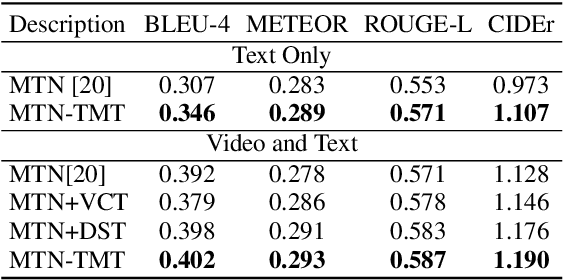
Audio Visual Scene-aware Dialog (AVSD) is a task to generate responses when discussing about a given video. The previous state-of-the-art model shows superior performance for this task using Transformer-based architecture. However, there remain some limitations in learning better representation of modalities. Inspired by Neural Machine Translation (NMT), we propose the Transformer-based Modal Translator (TMT) to learn the representations of the source modal sequence by translating the source modal sequence to the related target modal sequence in a supervised manner. Based on Multimodal Transformer Networks (MTN), we apply TMT to video and dialog, proposing MTN-TMT for the video-grounded dialog system. On the AVSD track of the Dialog System Technology Challenge 7, MTN-TMT outperforms the MTN and other submission models in both Video and Text task and Text Only task. Compared with MTN, MTN-TMT improves all metrics, especially, achieving relative improvement up to 14.1% on CIDEr. Index Terms: multimodal learning, audio-visual scene-aware dialog, neural machine translation, multi-task learning