 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Mar 10, 2024



Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
GraphEdit: Large Language Models for Graph Structure Learning
Mar 05, 2024

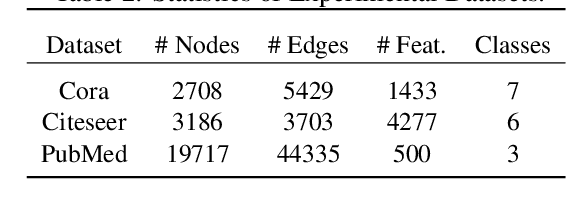

Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
HiGPT: Heterogeneous Graph Language Model
Feb 25, 2024



Heterogeneous graph learning aims to capture complex relationships and diverse relational semantics among entities in a heterogeneous graph to obtain meaningful representations for nodes and edges. Recent advancements in heterogeneous graph neural networks (HGNNs) have achieved state-of-the-art performance by considering relation heterogeneity and using specialized message functions and aggregation rules. However, existing frameworks for heterogeneous graph learning have limitations in generalizing across diverse heterogeneous graph datasets. Most of these frameworks follow the "pre-train" and "fine-tune" paradigm on the same dataset, which restricts their capacity to adapt to new and unseen data. This raises the question: "Can we generalize heterogeneous graph models to be well-adapted to diverse downstream learning tasks with distribution shifts in both node token sets and relation type heterogeneity?'' To tackle those challenges, we propose HiGPT, a general large graph model with Heterogeneous graph instruction-tuning paradigm. Our framework enables learning from arbitrary heterogeneous graphs without the need for any fine-tuning process from downstream datasets. To handle distribution shifts in heterogeneity, we introduce an in-context heterogeneous graph tokenizer that captures semantic relationships in different heterogeneous graphs, facilitating model adaptation. We incorporate a large corpus of heterogeneity-aware graph instructions into our HiGPT, enabling the model to effectively comprehend complex relation heterogeneity and distinguish between various types of graph tokens. Furthermore, we introduce the Mixture-of-Thought (MoT) instruction augmentation paradigm to mitigate data scarcity by generating diverse and informative instructions. Through comprehensive evaluations, our proposed framework demonstrates exceptional performance in terms of generalization performance.
BBox-Adapter: Lightweight Adapting for Black-Box Large Language Models
Feb 13, 2024Adapting state-of-the-art Large Language Models (LLMs) like GPT-4 and Gemini for specific tasks is challenging. Due to the opacity in their parameters, embeddings, and even output probabilities, existing fine-tuning adaptation methods are inapplicable. Consequently, adapting these black-box LLMs is only possible through their API services, raising concerns about transparency, privacy, and cost. To address these challenges, we introduce BBox-Adapter, a novel lightweight adapter for black-box LLMs. BBox-Adapter distinguishes target and source domain data by treating target data as positive and source data as negative. It employs a ranking-based Noise Contrastive Estimation (NCE) loss to promote the likelihood of target domain data while penalizing that of the source domain. Furthermore, it features an online adaptation mechanism, which incorporates real-time positive data sampling from ground-truth, human, or AI feedback, coupled with negative data from previous adaptations. Extensive experiments demonstrate BBox-Adapter's effectiveness and cost efficiency. It improves model performance by up to 6.77% across diverse tasks and domains, while reducing training and inference costs by 31.30x and 1.84x, respectively.
PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models
Feb 13, 2024



Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference. However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts. Our key innovation is the Reward Difference Prediction (RDP) objective that has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories. We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective. In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.
Hierarchical Continual Reinforcement Learning via Large Language Model
Feb 01, 2024



The ability to learn continuously in dynamic environments is a crucial requirement for reinforcement learning (RL) agents applying in the real world. Despite the progress in continual reinforcement learning (CRL), existing methods often suffer from insufficient knowledge transfer, particularly when the tasks are diverse. To address this challenge, we propose a new framework, Hierarchical Continual reinforcement learning via large language model (Hi-Core), designed to facilitate the transfer of high-level knowledge. Hi-Core orchestrates a twolayer structure: high-level policy formulation by a large language model (LLM), which represents agenerates a sequence of goals, and low-level policy learning that closely aligns with goal-oriented RL practices, producing the agent's actions in response to the goals set forth. The framework employs feedback to iteratively adjust and verify highlevel policies, storing them along with low-level policies within a skill library. When encountering a new task, Hi-Core retrieves relevant experience from this library to help to learning. Through experiments on Minigrid, Hi-Core has demonstrated its effectiveness in handling diverse CRL tasks, which outperforms popular baselines.
Benchmarking Sensitivity of Continual Graph Learning for Skeleton-Based Action Recognition
Jan 31, 2024



Continual learning (CL) is the research field that aims to build machine learning models that can accumulate knowledge continuously over different tasks without retraining from scratch. Previous studies have shown that pre-training graph neural networks (GNN) may lead to negative transfer (Hu et al., 2020) after fine-tuning, a setting which is closely related to CL. Thus, we focus on studying GNN in the continual graph learning (CGL) setting. We propose the first continual graph learning benchmark for spatio-temporal graphs and use it to benchmark well-known CGL methods in this novel setting. The benchmark is based on the N-UCLA and NTU-RGB+D datasets for skeleton-based action recognition. Beyond benchmarking for standard performance metrics, we study the class and task-order sensitivity of CGL methods, i.e., the impact of learning order on each class/task's performance, and the architectural sensitivity of CGL methods with backbone GNN at various widths and depths. We reveal that task-order robust methods can still be class-order sensitive and observe results that contradict previous empirical observations on architectural sensitivity in CL.
Improving Low-resource Prompt-based Relation Representation with Multi-view Decoupling Learning
Jan 15, 2024



Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (\underline{M}ulti-\underline{V}iew \underline{R}elation \underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
A Temporal-Spectral Fusion Transformer with Subject-specific Adapter for Enhancing RSVP-BCI Decoding
Jan 12, 2024The Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an efficient technology for target retrieval using electroencephalography (EEG) signals. The performance improvement of traditional decoding methods relies on a substantial amount of training data from new test subjects, which increases preparation time for BCI systems. Several studies introduce data from existing subjects to reduce the dependence of performance improvement on data from new subjects, but their optimization strategy based on adversarial learning with extensive data increases training time during the preparation procedure. Moreover, most previous methods only focus on the single-view information of EEG signals, but ignore the information from other views which may further improve performance. To enhance decoding performance while reducing preparation time, we propose a Temporal-Spectral fusion transformer with Subject-specific Adapter (TSformer-SA). Specifically, a cross-view interaction module is proposed to facilitate information transfer and extract common representations across two-view features extracted from EEG temporal signals and spectrogram images. Then, an attention-based fusion module fuses the features of two views to obtain comprehensive discriminative features for classification. Furthermore, a multi-view consistency loss is proposed to maximize the feature similarity between two views of the same EEG signal. Finally, we propose a subject-specific adapter to rapidly transfer the knowledge of the model trained on data from existing subjects to decode data from new subjects. Experimental results show that TSformer-SA significantly outperforms comparison methods and achieves outstanding performance with limited training data from new subjects. This facilitates efficient decoding and rapid deployment of BCI systems in practical use.
Joint Multi-Facts Reasoning Network For Complex Temporal Question Answering Over Knowledge Graph
Jan 04, 2024Temporal Knowledge Graph (TKG) is an extension of regular knowledge graph by attaching the time scope. Existing temporal knowledge graph question answering (TKGQA) models solely approach simple questions, owing to the prior assumption that each question only contains a single temporal fact with explicit/implicit temporal constraints. Hence, they perform poorly on questions which own multiple temporal facts. In this paper, we propose \textbf{\underline{J}}oint \textbf{\underline{M}}ulti \textbf{\underline{F}}acts \textbf{\underline{R}}easoning \textbf{\underline{N}}etwork (JMFRN), to jointly reasoning multiple temporal facts for accurately answering \emph{complex} temporal questions. Specifically, JMFRN first retrieves question-related temporal facts from TKG for each entity of the given complex question. For joint reasoning, we design two different attention (\ie entity-aware and time-aware) modules, which are suitable for universal settings, to aggregate entities and timestamps information of retrieved facts. Moreover, to filter incorrect type answers, we introduce an additional answer type discrimination task. Extensive experiments demonstrate our proposed method significantly outperforms the state-of-art on the well-known complex temporal question benchmark TimeQuestions.