 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplicability and Limitation Analysis of PMU Data and Phasor Concept for Low- and High- Frequency Oscillations
Jan 21, 2026Phasor Measurement Units (PMUs) convert high-speed waveform data into low-speed phasor data, which are fundamental to wide-area monitoring and control in power systems, with oscillation detection and localization among their most prominent applications. However, representing electrical waveform signals with oscillations using PMU phasors is effective only for low-frequency oscillations. This paper investigates the root causes of this limitation, focusing on errors introduced by Discrete Fourier Transform (DFT)-based signal processing, in addition to the attenuation effects of anti-aliasing filters, and the impact of low reporting rates. To better represent and estimate waveform signals with oscillations, we propose a more general signal model and a multi-step estimation method that leverages one-cycle DFT, the Matrix Pencil Method, and the Least Squares Method. Numerical experiments demonstrate the superior performance of the proposed signal model and estimation method. Furthermore, this paper reveals that the phasor concept, let alone PMU phasors, can become invalid for waveform signals with high-frequency oscillations characterized by asymmetric sub- and super-synchronous components. These findings highlight the fundamental limitations of PMU data and phasor concept, and emphasize the need to rely on waveform data for analyzing high-frequency oscillations in modern power systems.
WorkTeam: Constructing Workflows from Natural Language with Multi-Agents
Mar 28, 2025



Workflows play a crucial role in enhancing enterprise efficiency by orchestrating complex processes with multiple tools or components. However, hand-crafted workflow construction requires expert knowledge, presenting significant technical barriers. Recent advancements in Large Language Models (LLMs) have improved the generation of workflows from natural language instructions (aka NL2Workflow), yet existing single LLM agent-based methods face performance degradation on complex tasks due to the need for specialized knowledge and the strain of task-switching. To tackle these challenges, we propose WorkTeam, a multi-agent NL2Workflow framework comprising a supervisor, orchestrator, and filler agent, each with distinct roles that collaboratively enhance the conversion process. As there are currently no publicly available NL2Workflow benchmarks, we also introduce the HW-NL2Workflow dataset, which includes 3,695 real-world business samples for training and evaluation. Experimental results show that our approach significantly increases the success rate of workflow construction, providing a novel and effective solution for enterprise NL2Workflow services.
Recovering Complete Actions for Cross-dataset Skeleton Action Recognition
Oct 31, 2024



Despite huge progress in skeleton-based action recognition, its generalizability to different domains remains a challenging issue. In this paper, to solve the skeleton action generalization problem, we present a recover-and-resample augmentation framework based on a novel complete action prior. We observe that human daily actions are confronted with temporal mismatch across different datasets, as they are usually partial observations of their complete action sequences. By recovering complete actions and resampling from these full sequences, we can generate strong augmentations for unseen domains. At the same time, we discover the nature of general action completeness within large datasets, indicated by the per-frame diversity over time. This allows us to exploit two assets of transferable knowledge that can be shared across action samples and be helpful for action completion: boundary poses for determining the action start, and linear temporal transforms for capturing global action patterns. Therefore, we formulate the recovering stage as a two-step stochastic action completion with boundary pose-conditioned extrapolation followed by smooth linear transforms. Both the boundary poses and linear transforms can be efficiently learned from the whole dataset via clustering. We validate our approach on a cross-dataset setting with three skeleton action datasets, outperforming other domain generalization approaches by a considerable margin.
Programmable Motion Generation for Open-Set Motion Control Tasks
May 29, 2024Character animation in real-world scenarios necessitates a variety of constraints, such as trajectories, key-frames, interactions, etc. Existing methodologies typically treat single or a finite set of these constraint(s) as separate control tasks. They are often specialized, and the tasks they address are rarely extendable or customizable. We categorize these as solutions to the close-set motion control problem. In response to the complexity of practical motion control, we propose and attempt to solve the open-set motion control problem. This problem is characterized by an open and fully customizable set of motion control tasks. To address this, we introduce a new paradigm, programmable motion generation. In this paradigm, any given motion control task is broken down into a combination of atomic constraints. These constraints are then programmed into an error function that quantifies the degree to which a motion sequence adheres to them. We utilize a pre-trained motion generation model and optimize its latent code to minimize the error function of the generated motion. Consequently, the generated motion not only inherits the prior of the generative model but also satisfies the required constraints. Experiments show that we can generate high-quality motions when addressing a wide range of unseen tasks. These tasks encompass motion control by motion dynamics, geometric constraints, physical laws, interactions with scenes, objects or the character own body parts, etc. All of these are achieved in a unified approach, without the need for ad-hoc paired training data collection or specialized network designs. During the programming of novel tasks, we observed the emergence of new skills beyond those of the prior model. With the assistance of large language models, we also achieved automatic programming. We hope that this work will pave the way for the motion control of general AI agents.
A Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024



Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Super-resolution of spatiotemporal event-stream image captured by the asynchronous temporal contrast vision sensor
Mar 16, 2018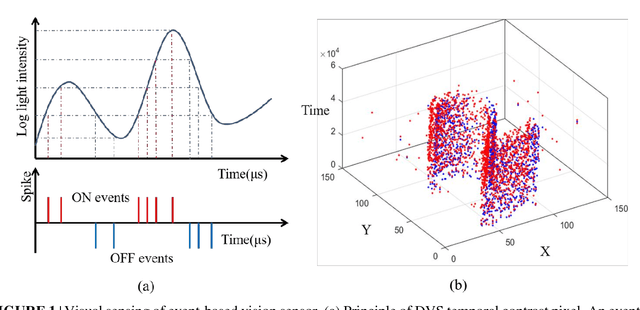
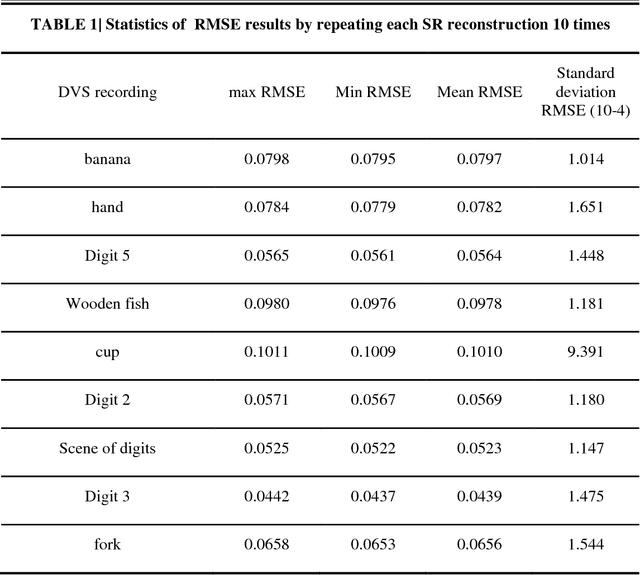
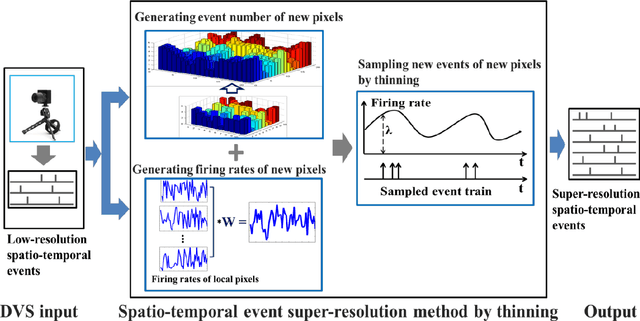
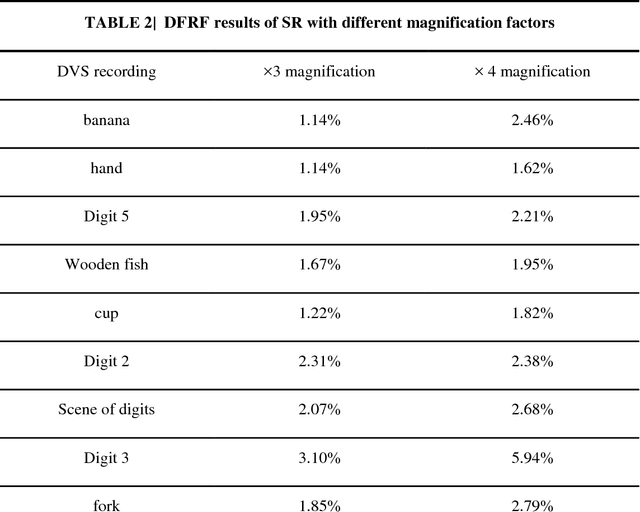
Super-resolution (SR) is a useful technology to generate a high-resolution (HR) visual output from the low-resolution (LR) visual inputs overcoming the physical limitations of the cameras. However, SR has not been applied to enhance the resolution of spatiotemporal event-stream images captured by the frame-free dynamic vision sensors (DVSs). SR of event-stream image is fundamentally different from existing frame-based schemes since basically each pixel value of DVS images is an event sequence. In this work, a two-stage scheme is proposed to solve the SR problem of the spatiotemporal event-stream image. We use a nonhomogeneous Poisson point process to model the event sequence, and sample the events of each pixel by simulating a nonhomogeneous Poisson process according to the specified event number and rate function. Firstly, the event number of each pixel of the HR DVS image is determined with a sparse signal representation based method to obtain the HR event-count map from that of the LR DVS recording. The rate function over time line of the point process of each HR pixel is computed using a spatiotemporal filter on the corresponding LR neighbor pixels. Secondly, the event sequence of each new pixel is generated with a thinning based event sampling algorithm. Two metrics are proposed to assess the event-stream SR results. The proposed method is demonstrated through obtaining HR event-stream images from a series of DVS recordings with the proposed method. Results show that the upscaled HR event streams has perceptually higher spatial texture detail than the LR DVS images. Besides, the temporal properties of the upscaled HR event streams match that of the original input very well. This work enables many potential applications of event-based vision.