 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hyper-network Based End-to-end Visual Servoing with Arbitrary Desired Poses
Apr 18, 2023



Recently, several works achieve end-to-end visual servoing (VS) for robotic manipulation by replacing traditional controller with differentiable neural networks, but lose the ability to servo arbitrary desired poses. This letter proposes a differentiable architecture for arbitrary pose servoing: a hyper-network based neural controller (HPN-NC). To achieve this, HPN-NC consists of a hyper net and a low-level controller, where the hyper net learns to generate the parameters of the low-level controller and the controller uses the 2D keypoints error for control like traditional image-based visual servoing (IBVS). HPN-NC can complete 6 degree of freedom visual servoing with large initial offset. Taking advantage of the fully differentiable nature of HPN-NC, we provide a three-stage training procedure to servo real world objects. With self-supervised end-to-end training, the performance of the integrated model can be further improved in unseen scenes and the amount of manual annotations can be significantly reduced.
FLYOVER: A Model-Driven Method to Generate Diverse Highway Interchanges for Autonomous Vehicle Testing
Jan 30, 2023



It has become a consensus that autonomous vehicles (AVs) will first be widely deployed on highways. However, the complexity of highway interchanges becomes the bottleneck for deploying AVs. An AV should be sufficiently tested under different highway interchanges, which is still challenging due to the lack of available datasets containing diverse highway interchanges. In this paper, we propose a model-driven method, FLYOVER, to generate a dataset consisting of diverse interchanges with measurable diversity coverage. First, FLYOVER proposes a labeled digraph to model the topology of an interchange. Second, FLYOVER takes real-world interchanges as input to guarantee topology practicality and extracts different topology equivalence classes by classifying the corresponding topology models. Third, for each topology class, FLYOVER identifies the corresponding geometrical features for the ramps and generates concrete interchanges using k-way combinatorial coverage and differential evolution. To illustrate the diversity and applicability of the generated interchange dataset, we test the built-in traffic flow control algorithm in SUMO and the fuel-optimization trajectory tracking algorithm deployed to Alibaba's autonomous trucks on the dataset. The results show that except for the geometrical difference, the interchanges are diverse in throughput and fuel consumption under the traffic flow control and trajectory tracking algorithms, respectively.
Hierarchical Point Cloud Encoding and Decoding with Lightweight Self-Attention based Model
Feb 13, 2022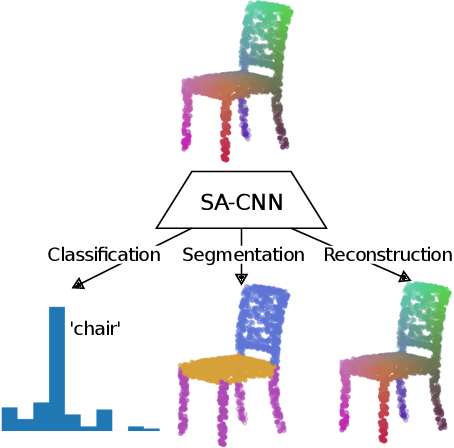
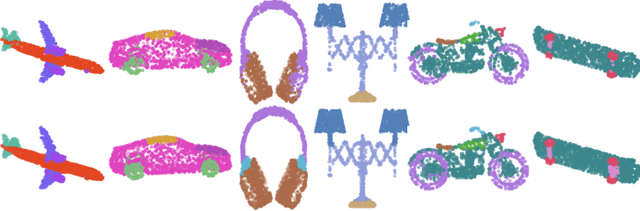

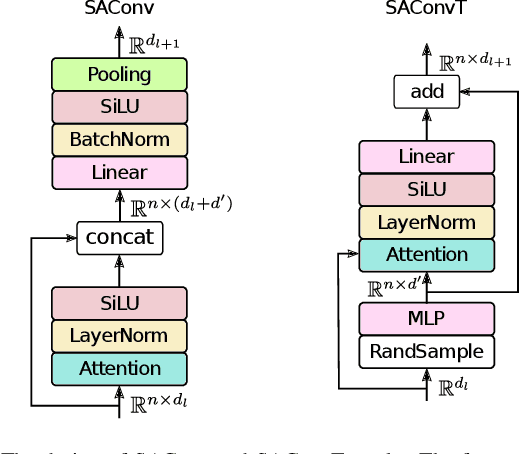
In this paper we present SA-CNN, a hierarchical and lightweight self-attention based encoding and decoding architecture for representation learning of point cloud data. The proposed SA-CNN introduces convolution and transposed convolution stacks to capture and generate contextual information among unordered 3D points. Following conventional hierarchical pipeline, the encoding process extracts feature in local-to-global manner, while the decoding process generates feature and point cloud in coarse-to-fine, multi-resolution stages. We demonstrate that SA-CNN is capable of a wide range of applications, namely classification, part segmentation, reconstruction, shape retrieval, and unsupervised classification. While achieving the state-of-the-art or comparable performance in the benchmarks, SA-CNN maintains its model complexity several order of magnitude lower than the others. In term of qualitative results, we visualize the multi-stage point cloud reconstructions and latent walks on rigid objects as well as deformable non-rigid human and robot models.
End-to-end Reinforcement Learning of Robotic Manipulation with Robust Keypoints Representation
Feb 12, 2022



We present an end-to-end Reinforcement Learning(RL) framework for robotic manipulation tasks, using a robust and efficient keypoints representation. The proposed method learns keypoints from camera images as the state representation, through a self-supervised autoencoder architecture. The keypoints encode the geometric information, as well as the relationship of the tool and target in a compact representation to ensure efficient and robust learning. After keypoints learning, the RL step then learns the robot motion from the extracted keypoints state representation. The keypoints and RL learning processes are entirely done in the simulated environment. We demonstrate the effectiveness of the proposed method on robotic manipulation tasks including grasping and pushing, in different scenarios. We also investigate the generalization capability of the trained model. In addition to the robust keypoints representation, we further apply domain randomization and adversarial training examples to achieve zero-shot sim-to-real transfer in real-world robotic manipulation tasks.
The Elements of Temporal Sentence Grounding in Videos: A Survey and Future Directions
Jan 20, 2022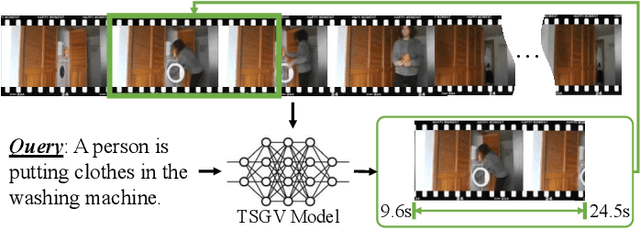
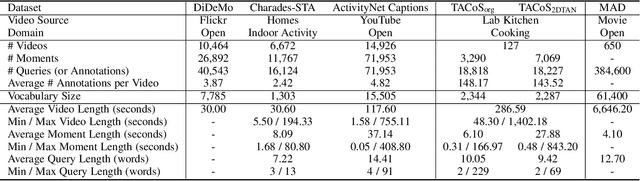
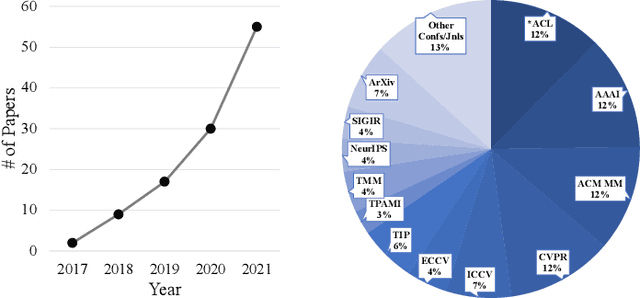
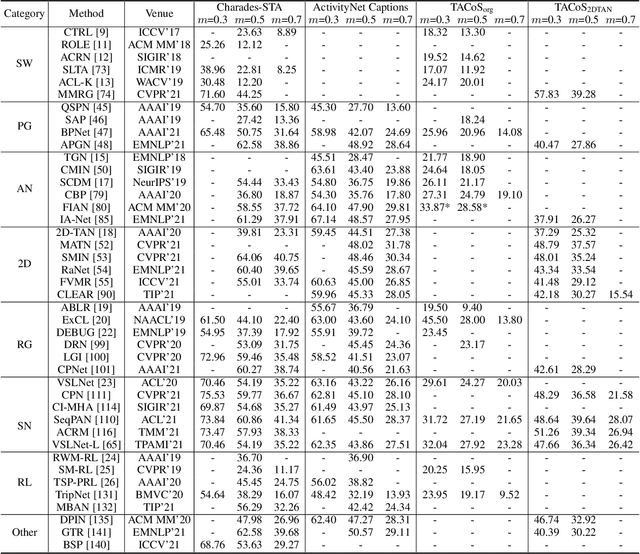
Temporal sentence grounding in videos (TSGV), a.k.a., natural language video localization (NLVL) or video moment retrieval (VMR), aims to retrieve a temporal moment that semantically corresponds to a language query from an untrimmed video. Connecting computer vision and natural language, TSGV has drawn significant attention from researchers in both communities. This survey attempts to provide a summary of fundamental concepts in TSGV and current research status, as well as future research directions. As the background, we present a common structure of functional components in TSGV, in a tutorial style: from feature extraction from raw video and language query, to answer prediction of the target moment. Then we review the techniques for multimodal understanding and interaction, which is the key focus of TSGV for effective alignment between the two modalities. We construct a taxonomy of TSGV techniques and elaborate methods in different categories with their strengths and weaknesses. Lastly, we discuss issues with the current TSGV research and share our insights about promising research directions.
Towards Debiasing Temporal Sentence Grounding in Video
Nov 08, 2021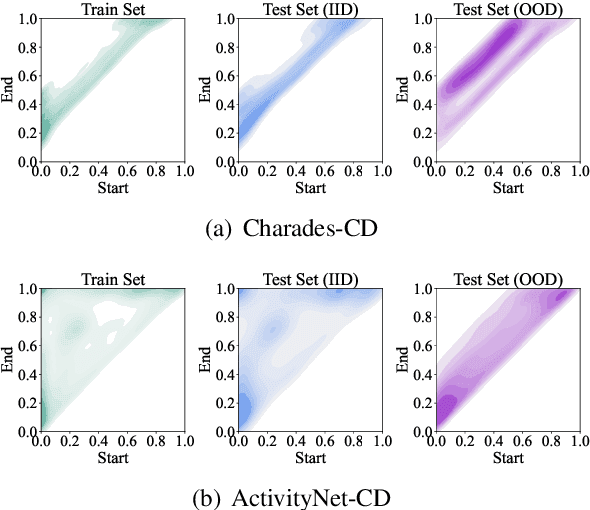
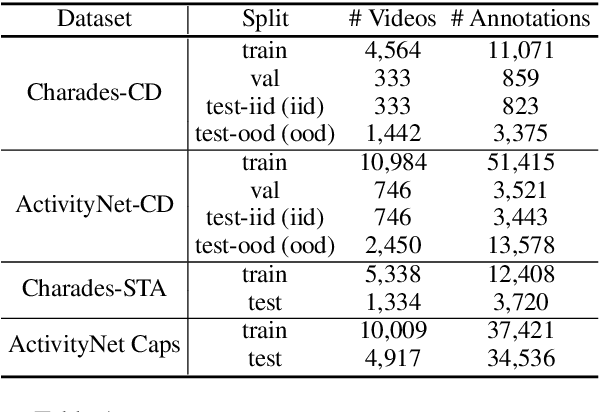
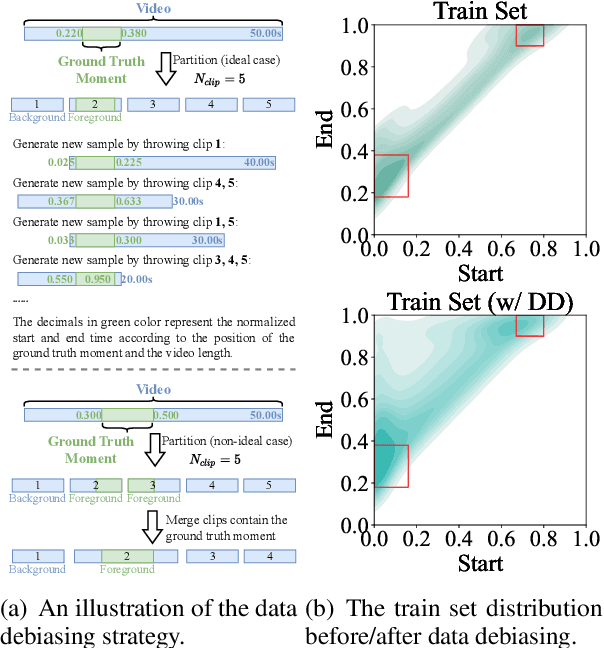
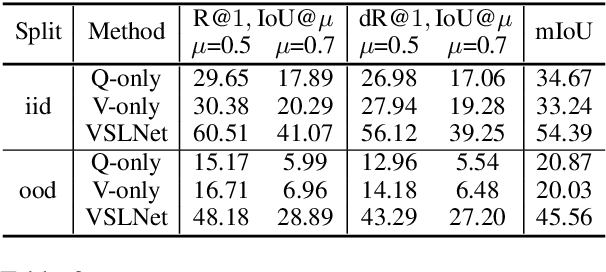
The temporal sentence grounding in video (TSGV) task is to locate a temporal moment from an untrimmed video, to match a language query, i.e., a sentence. Without considering bias in moment annotations (e.g., start and end positions in a video), many models tend to capture statistical regularities of the moment annotations, and do not well learn cross-modal reasoning between video and language query. In this paper, we propose two debiasing strategies, data debiasing and model debiasing, to "force" a TSGV model to capture cross-modal interactions. Data debiasing performs data oversampling through video truncation to balance moment temporal distribution in train set. Model debiasing leverages video-only and query-only models to capture the distribution bias, and forces the model to learn cross-modal interactions. Using VSLNet as the base model, we evaluate impact of the two strategies on two datasets that contain out-of-distribution test instances. Results show that both strategies are effective in improving model generalization capability. Equipped with both debiasing strategies, VSLNet achieves best results on both datasets.
Fault-Tolerant Federated Reinforcement Learning with Theoretical Guarantee
Oct 26, 2021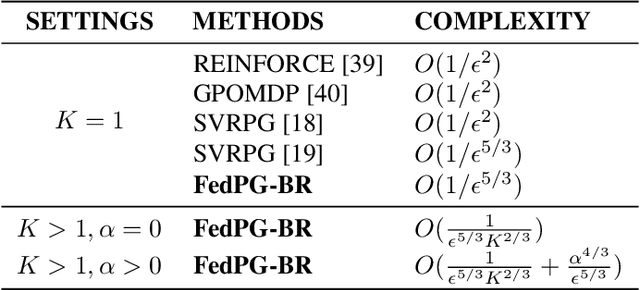
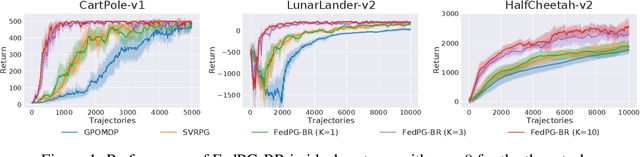
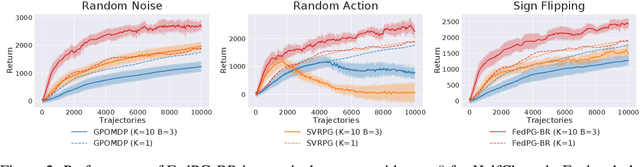
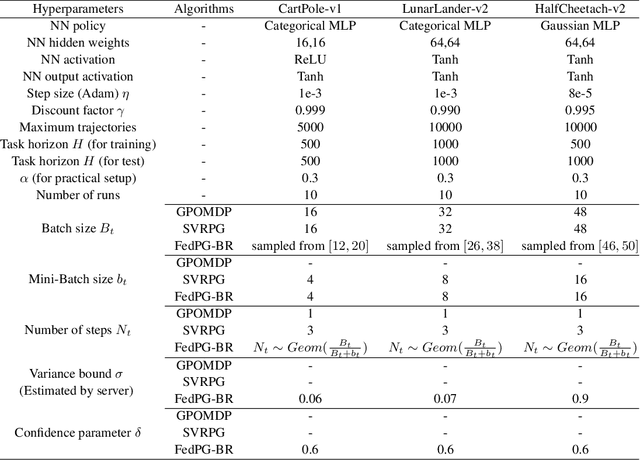
The growing literature of Federated Learning (FL) has recently inspired Federated Reinforcement Learning (FRL) to encourage multiple agents to federatively build a better decision-making policy without sharing raw trajectories. Despite its promising applications, existing works on FRL fail to I) provide theoretical analysis on its convergence, and II) account for random system failures and adversarial attacks. Towards this end, we propose the first FRL framework the convergence of which is guaranteed and tolerant to less than half of the participating agents being random system failures or adversarial attackers. We prove that the sample efficiency of the proposed framework is guaranteed to improve with the number of agents and is able to account for such potential failures or attacks. All theoretical results are empirically verified on various RL benchmark tasks.
Domain Generalization for Vision-based Driving Trajectory Generation
Sep 22, 2021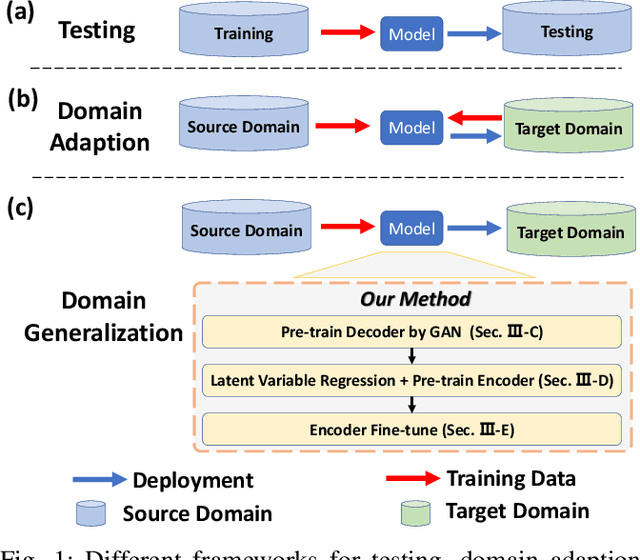
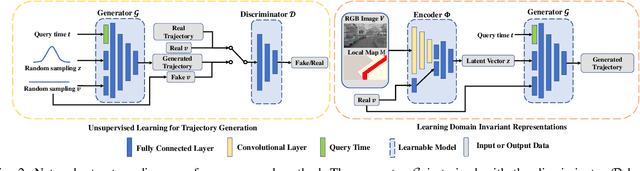
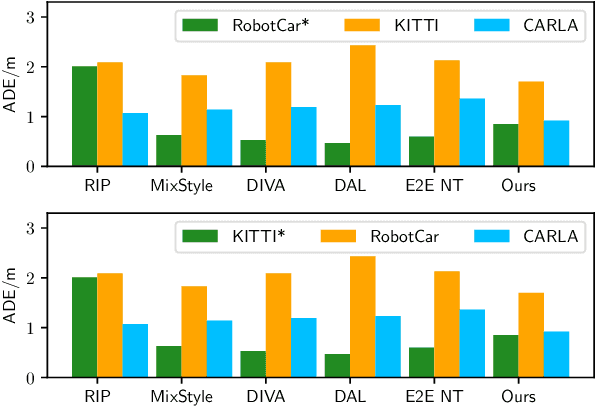

One of the challenges in vision-based driving trajectory generation is dealing with out-of-distribution scenarios. In this paper, we propose a domain generalization method for vision-based driving trajectory generation for autonomous vehicles in urban environments, which can be seen as a solution to extend the Invariant Risk Minimization (IRM) method in complex problems. We leverage an adversarial learning approach to train a trajectory generator as the decoder. Based on the pre-trained decoder, we infer the latent variables corresponding to the trajectories, and pre-train the encoder by regressing the inferred latent variable. Finally, we fix the decoder but fine-tune the encoder with the final trajectory loss. We compare our proposed method with the state-of-the-art trajectory generation method and some recent domain generalization methods on both datasets and simulation, demonstrating that our method has better generalization ability.
Parallel Attention Network with Sequence Matching for Video Grounding
May 18, 2021
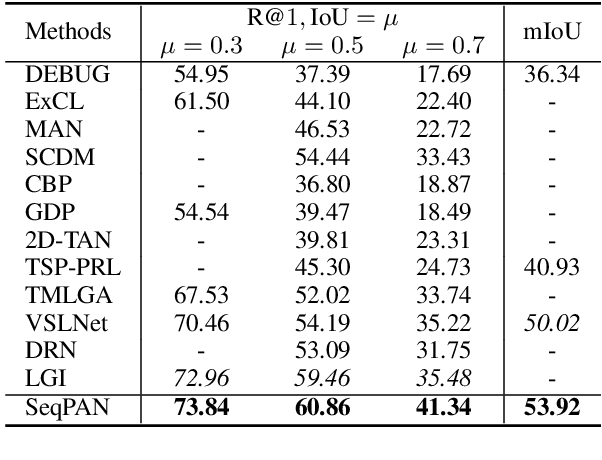

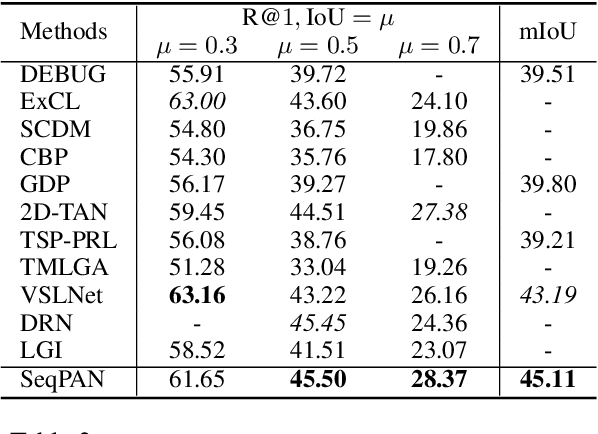
Given a video, video grounding aims to retrieve a temporal moment that semantically corresponds to a language query. In this work, we propose a Parallel Attention Network with Sequence matching (SeqPAN) to address the challenges in this task: multi-modal representation learning, and target moment boundary prediction. We design a self-guided parallel attention module to effectively capture self-modal contexts and cross-modal attentive information between video and text. Inspired by sequence labeling tasks in natural language processing, we split the ground truth moment into begin, inside, and end regions. We then propose a sequence matching strategy to guide start/end boundary predictions using region labels. Experimental results on three datasets show that SeqPAN is superior to state-of-the-art methods. Furthermore, the effectiveness of the self-guided parallel attention module and the sequence matching module is verified.
Video Corpus Moment Retrieval with Contrastive Learning
May 13, 2021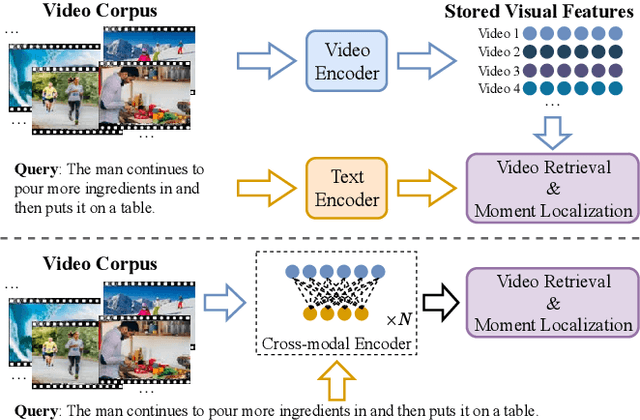
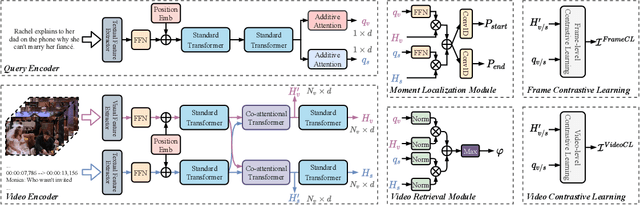
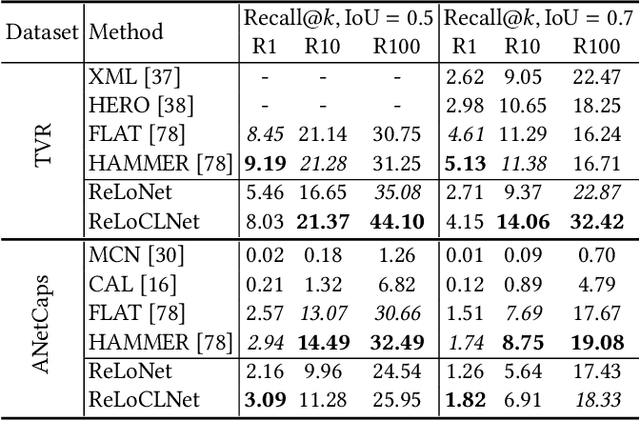
Given a collection of untrimmed and unsegmented videos, video corpus moment retrieval (VCMR) is to retrieve a temporal moment (i.e., a fraction of a video) that semantically corresponds to a given text query. As video and text are from two distinct feature spaces, there are two general approaches to address VCMR: (i) to separately encode each modality representations, then align the two modality representations for query processing, and (ii) to adopt fine-grained cross-modal interaction to learn multi-modal representations for query processing. While the second approach often leads to better retrieval accuracy, the first approach is far more efficient. In this paper, we propose a Retrieval and Localization Network with Contrastive Learning (ReLoCLNet) for VCMR. We adopt the first approach and introduce two contrastive learning objectives to refine video encoder and text encoder to learn video and text representations separately but with better alignment for VCMR. The video contrastive learning (VideoCL) is to maximize mutual information between query and candidate video at video-level. The frame contrastive learning (FrameCL) aims to highlight the moment region corresponds to the query at frame-level, within a video. Experimental results show that, although ReLoCLNet encodes text and video separately for efficiency, its retrieval accuracy is comparable with baselines adopting cross-modal interaction learning.