 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacing Changes: Continual Entity Alignment for Growing Knowledge Graphs
Jul 23, 2022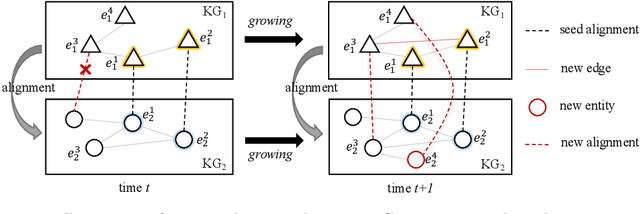
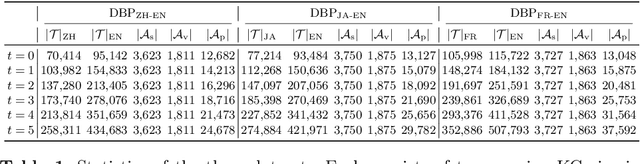
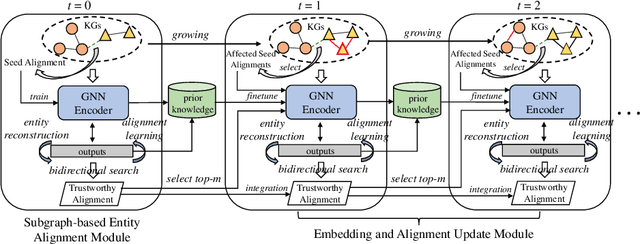
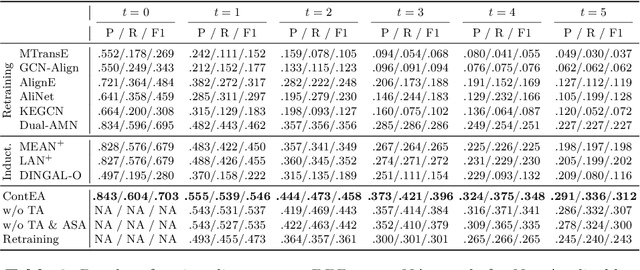
Entity alignment is a basic and vital technique in knowledge graph (KG) integration. Over the years, research on entity alignment has resided on the assumption that KGs are static, which neglects the nature of growth of real-world KGs. As KGs grow, previous alignment results face the need to be revisited while new entity alignment waits to be discovered. In this paper, we propose and dive into a realistic yet unexplored setting, referred to as continual entity alignment. To avoid retraining an entire model on the whole KGs whenever new entities and triples come, we present a continual alignment method for this task. It reconstructs an entity's representation based on entity adjacency, enabling it to generate embeddings for new entities quickly and inductively using their existing neighbors. It selects and replays partial pre-aligned entity pairs to train only parts of KGs while extracting trustworthy alignment for knowledge augmentation. As growing KGs inevitably contain non-matchable entities, different from previous works, the proposed method employs bidirectional nearest neighbor matching to find new entity alignment and update old alignment. Furthermore, we also construct new datasets by simulating the growth of multilingual DBpedia. Extensive experiments demonstrate that our continual alignment method is more effective than baselines based on retraining or inductive learning.
Enhancing Document-level Relation Extraction by Entity Knowledge Injection
Jul 23, 2022
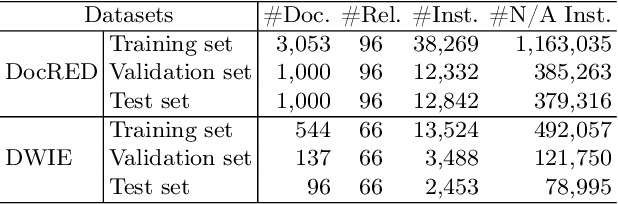
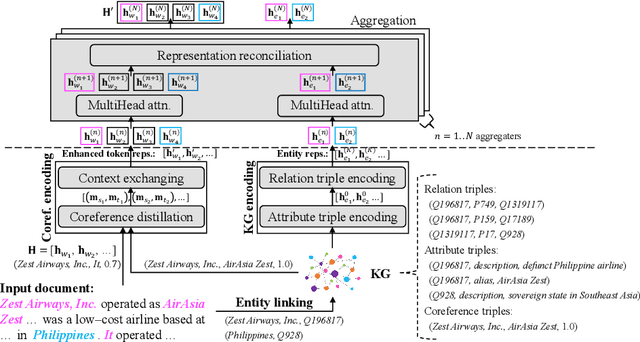
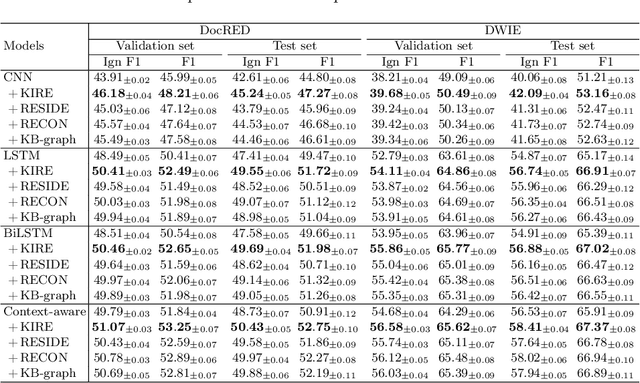
Document-level relation extraction (RE) aims to identify the relations between entities throughout an entire document. It needs complex reasoning skills to synthesize various knowledge such as coreferences and commonsense. Large-scale knowledge graphs (KGs) contain a wealth of real-world facts, and can provide valuable knowledge to document-level RE. In this paper, we propose an entity knowledge injection framework to enhance current document-level RE models. Specifically, we introduce coreference distillation to inject coreference knowledge, endowing an RE model with the more general capability of coreference reasoning. We also employ representation reconciliation to inject factual knowledge and aggregate KG representations and document representations into a unified space. The experiments on two benchmark datasets validate the generalization of our entity knowledge injection framework and the consistent improvement to several document-level RE models.
Brief Industry Paper: The Necessity of Adaptive Data Fusion in Infrastructure-Augmented Autonomous Driving System
Jul 02, 2022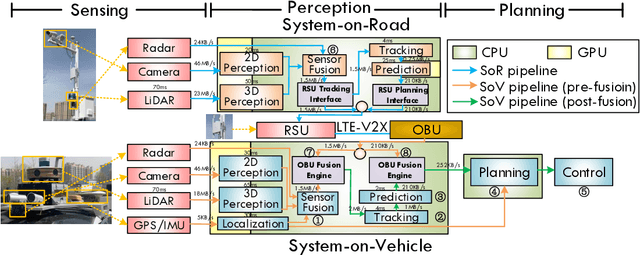
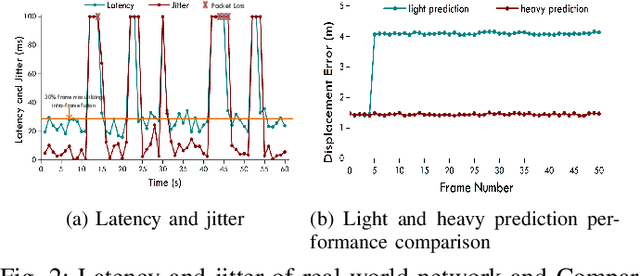
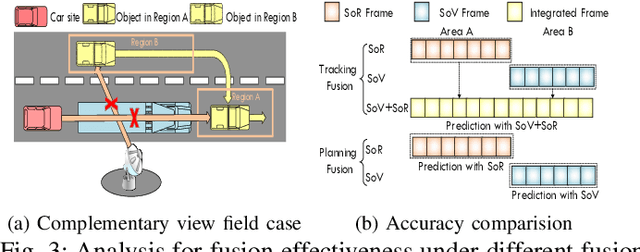

This paper is the first to provide a thorough system design overview along with the fusion methods selection criteria of a real-world cooperative autonomous driving system, named Infrastructure-Augmented Autonomous Driving or IAAD. We present an in-depth introduction of the IAAD hardware and software on both road-side and vehicle-side computing and communication platforms. We extensively characterize the IAAD system in the context of real-world deployment scenarios and observe that the network condition that fluctuates along the road is currently the main technical roadblock for cooperative autonomous driving. To address this challenge, we propose new fusion methods, dubbed "inter-frame fusion" and "planning fusion" to complement the current state-of-the-art "intra-frame fusion". We demonstrate that each fusion method has its own benefit and constraint.
Dynamic Point Cloud Denoising via Gradient Fields
Apr 19, 2022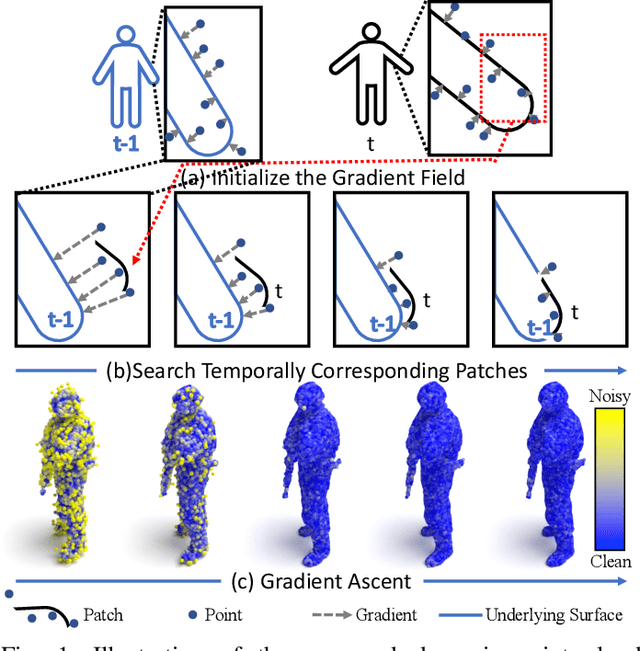
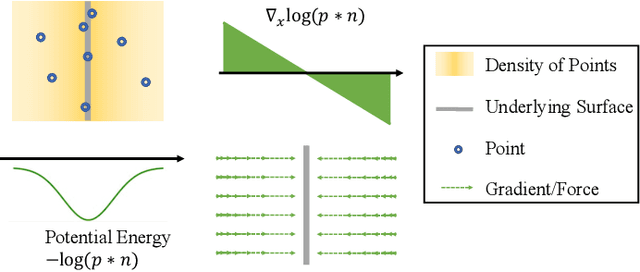
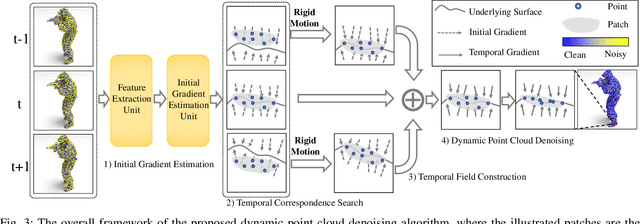
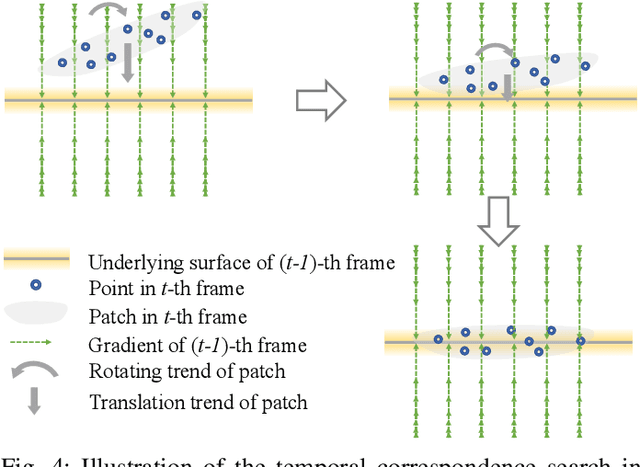
3D dynamic point clouds provide a discrete representation of real-world objects or scenes in motion, which have been widely applied in immersive telepresence, autonomous driving, surveillance, etc. However, point clouds acquired from sensors are usually perturbed by noise, which affects downstream tasks such as surface reconstruction and analysis. Although many efforts have been made for static point cloud denoising, dynamic point cloud denoising remains under-explored. In this paper, we propose a novel gradient-field-based dynamic point cloud denoising method, exploiting the temporal correspondence via the estimation of gradient fields -- a fundamental problem in dynamic point cloud processing and analysis. The gradient field is the gradient of the log-probability function of the noisy point cloud, based on which we perform gradient ascent so as to converge each point to the underlying clean surface. We estimate the gradient of each surface patch and exploit the temporal correspondence, where the temporally corresponding patches are searched leveraging on rigid motion in classical mechanics. In particular, we treat each patch as a rigid object, which moves in the gradient field of an adjacent frame via force until reaching a balanced state, i.e., when the sum of gradients over the patch reaches 0. Since the gradient would be smaller when the point is closer to the underlying surface, the balanced patch would fit the underlying surface well, thus leading to the temporal correspondence. Finally, the position of each point in the patch is updated along the direction of the gradient averaged from corresponding patches in adjacent frames. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods under both synthetic noise and simulated real-world noise.
Unsupervised Manga Character Re-identification via Face-body and Spatial-temporal Associated Clustering
Apr 10, 2022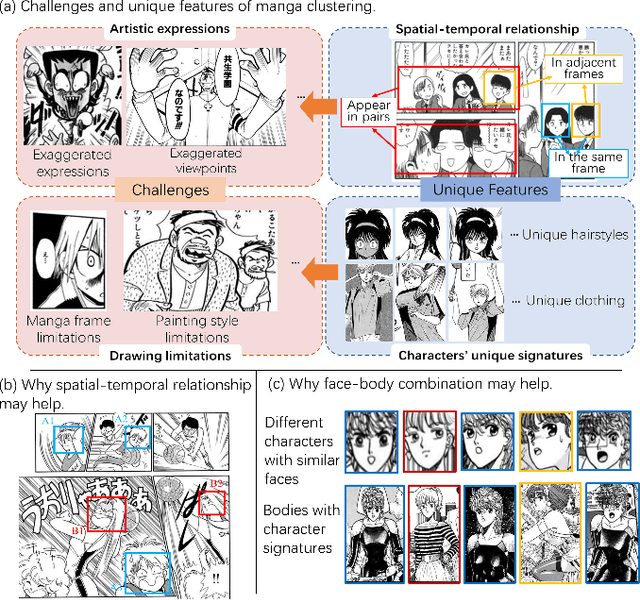

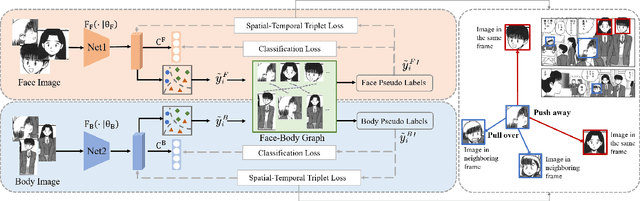

In the past few years, there has been a dramatic growth in e-manga (electronic Japanese-style comics). Faced with the booming demand for manga research and the large amount of unlabeled manga data, we raised a new task, called unsupervised manga character re-identification. However, the artistic expression and stylistic limitations of manga pose many challenges to the re-identification problem. Inspired by the idea that some content-related features may help clustering, we propose a Face-body and Spatial-temporal Associated Clustering method (FSAC). In the face-body combination module, a face-body graph is constructed to solve problems such as exaggeration and deformation in artistic creation by using the integrity of the image. In the spatial-temporal relationship correction module, we analyze the appearance features of characters and design a temporal-spatial-related triplet loss to fine-tune the clustering. Extensive experiments on a manga book dataset with 109 volumes validate the superiority of our method in unsupervised manga character re-identification.
SAD: A Large-scale Dataset towards Airport Detection in Synthetic Aperture Radar Images
Apr 07, 2022
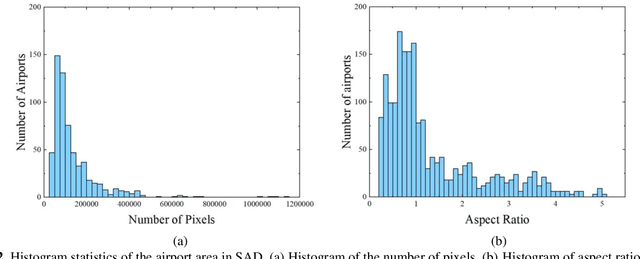
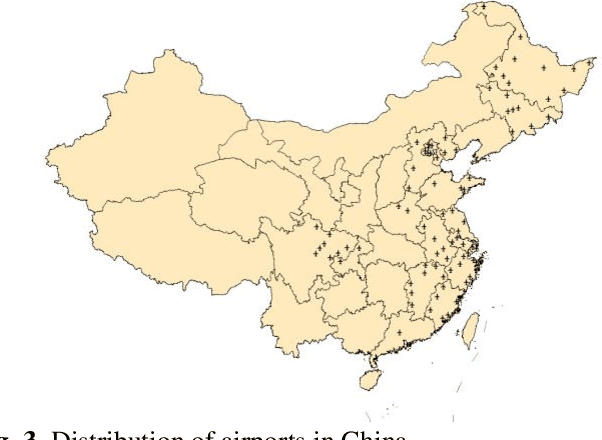
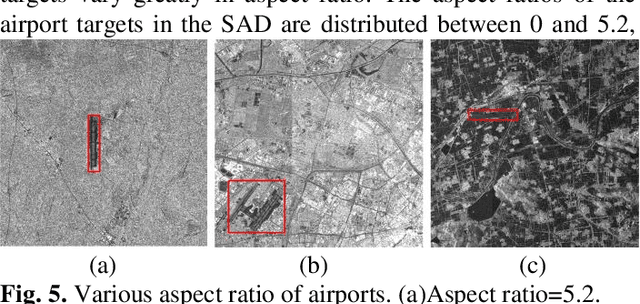
Airports have an important role in both military and civilian domains. The synthetic aperture radar (SAR) based airport detection has received increasing attention in recent years. However, due to the high cost of SAR imaging and annotation process, there is no publicly available SAR dataset for airport detection. As a result, deep learning methods have not been fully used in airport detection tasks. To provide a benchmark for airport detection research in SAR images, this paper introduces a large-scale SAR Airport Dataset (SAD). In order to adequately reflect the demands of real world applications, it contains 624 SAR images from Sentinel 1B and covers 104 airfield instances with different scales, orientations and shapes. The experiments of multiple deep learning approach on this dataset proves its effectiveness. It developing state-of-the-art airport area detection algorithms or other relevant tasks.
Ensemble Semi-supervised Entity Alignment via Cycle-teaching
Mar 12, 2022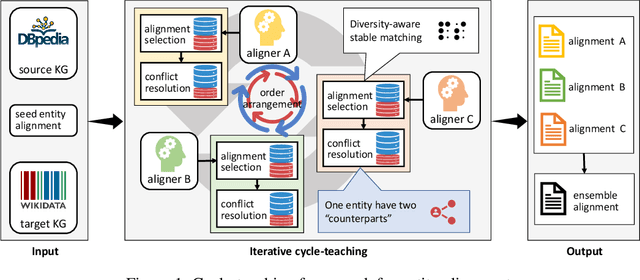
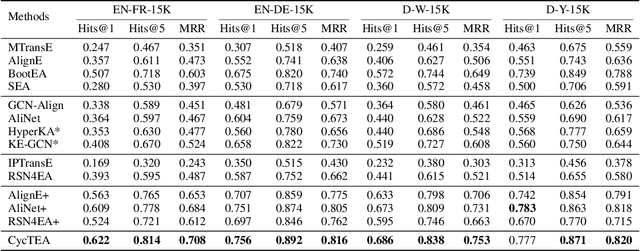
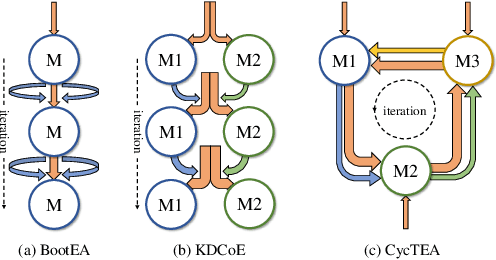
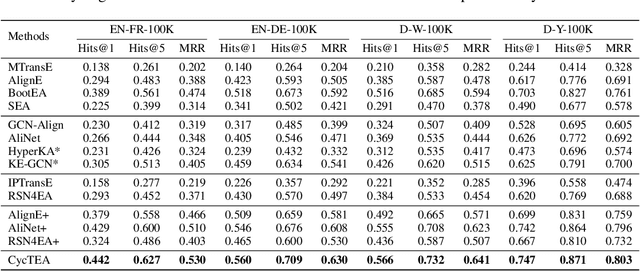
Entity alignment is to find identical entities in different knowledge graphs. Although embedding-based entity alignment has recently achieved remarkable progress, training data insufficiency remains a critical challenge. Conventional semi-supervised methods also suffer from the incorrect entity alignment in newly proposed training data. To resolve these issues, we design an iterative cycle-teaching framework for semi-supervised entity alignment. The key idea is to train multiple entity alignment models (called aligners) simultaneously and let each aligner iteratively teach its successor the proposed new entity alignment. We propose a diversity-aware alignment selection method to choose reliable entity alignment for each aligner. We also design a conflict resolution mechanism to resolve the alignment conflict when combining the new alignment of an aligner and that from its teacher. Besides, considering the influence of cycle-teaching order, we elaborately design a strategy to arrange the optimal order that can maximize the overall performance of multiple aligners. The cycle-teaching process can break the limitations of each model's learning capability and reduce the noise in new training data, leading to improved performance. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed cycle-teaching framework, which significantly outperforms the state-of-the-art models when the training data is insufficient and the new entity alignment has much noise.
More Than a Toy: Random Matrix Models Predict How Real-World Neural Representations Generalize
Mar 11, 2022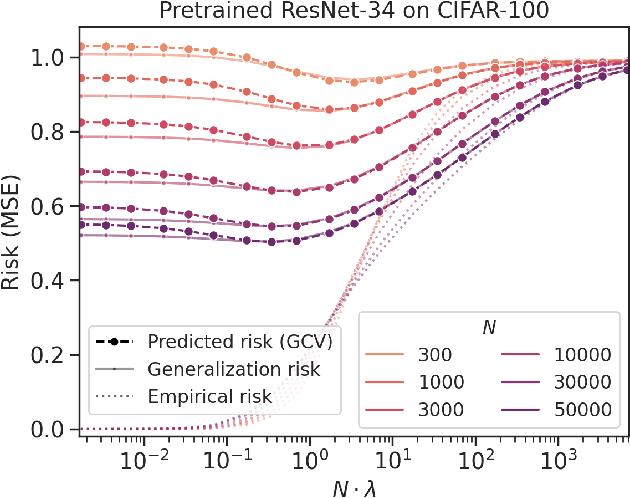
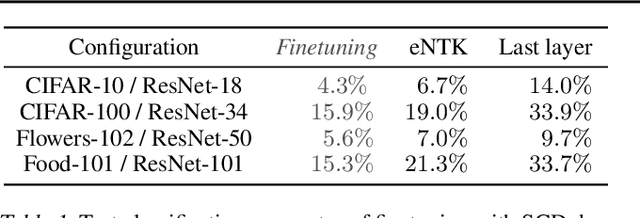
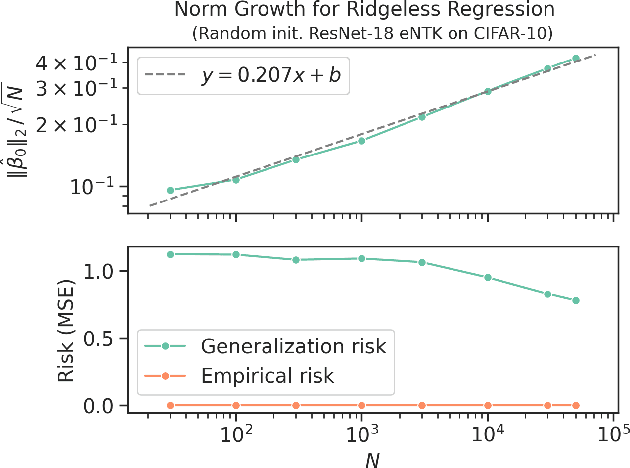
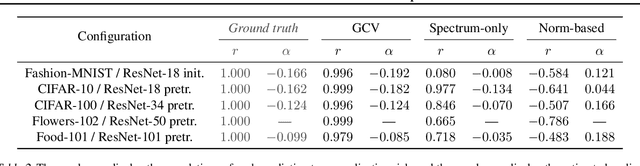
Of theories for why large-scale machine learning models generalize despite being vastly overparameterized, which of their assumptions are needed to capture the qualitative phenomena of generalization in the real world? On one hand, we find that most theoretical analyses fall short of capturing these qualitative phenomena even for kernel regression, when applied to kernels derived from large-scale neural networks (e.g., ResNet-50) and real data (e.g., CIFAR-100). On the other hand, we find that the classical GCV estimator (Craven and Wahba, 1978) accurately predicts generalization risk even in such overparameterized settings. To bolster this empirical finding, we prove that the GCV estimator converges to the generalization risk whenever a local random matrix law holds. Finally, we apply this random matrix theory lens to explain why pretrained representations generalize better as well as what factors govern scaling laws for kernel regression. Our findings suggest that random matrix theory, rather than just being a toy model, may be central to understanding the properties of neural representations in practice.
Multi-Scale Self-Contrastive Learning with Hard Negative Mining for Weakly-Supervised Query-based Video Grounding
Mar 08, 2022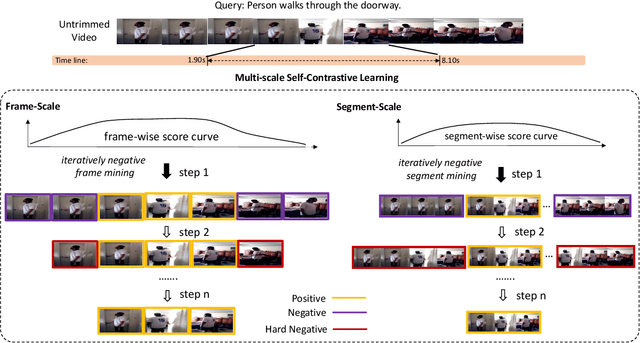
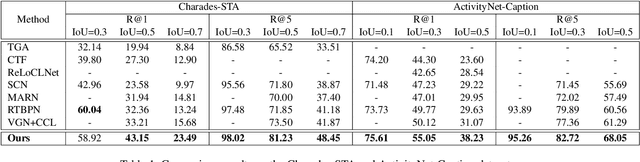
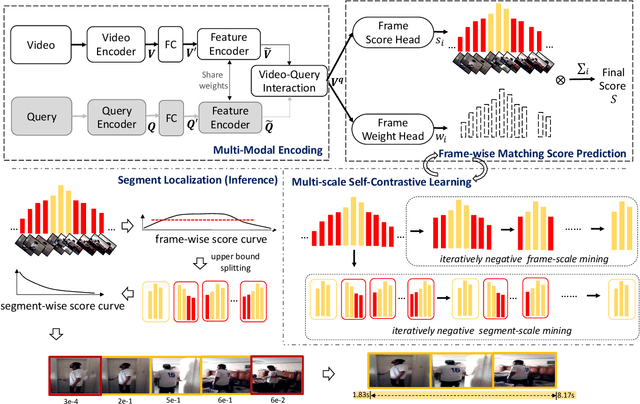

Query-based video grounding is an important yet challenging task in video understanding, which aims to localize the target segment in an untrimmed video according to a sentence query. Most previous works achieve significant progress by addressing this task in a fully-supervised manner with segment-level labels, which require high labeling cost. Although some recent efforts develop weakly-supervised methods that only need the video-level knowledge, they generally match multiple pre-defined segment proposals with query and select the best one, which lacks fine-grained frame-level details for distinguishing frames with high repeatability and similarity within the entire video. To alleviate the above limitations, we propose a self-contrastive learning framework to address the query-based video grounding task under a weakly-supervised setting. Firstly, instead of utilizing redundant segment proposals, we propose a new grounding scheme that learns frame-wise matching scores referring to the query semantic to predict the possible foreground frames by only using the video-level annotations. Secondly, since some predicted frames (i.e., boundary frames) are relatively coarse and exhibit similar appearance to their adjacent frames, we propose a coarse-to-fine contrastive learning paradigm to learn more discriminative frame-wise representations for distinguishing the false positive frames. In particular, we iteratively explore multi-scale hard negative samples that are close to positive samples in the representation space for distinguishing fine-grained frame-wise details, thus enforcing more accurate segment grounding. Extensive experiments on two challenging benchmarks demonstrate the superiority of our proposed method compared with the state-of-the-art methods.
Exploring Optical-Flow-Guided Motion and Detection-Based Appearance for Temporal Sentence Grounding
Mar 06, 2022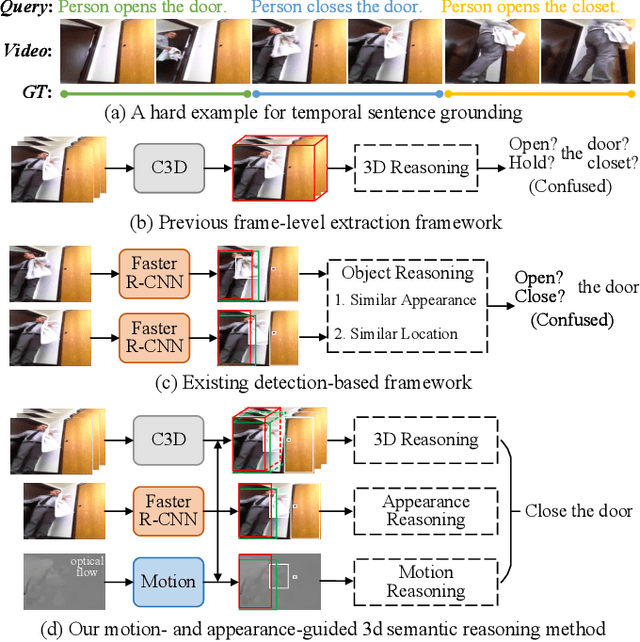
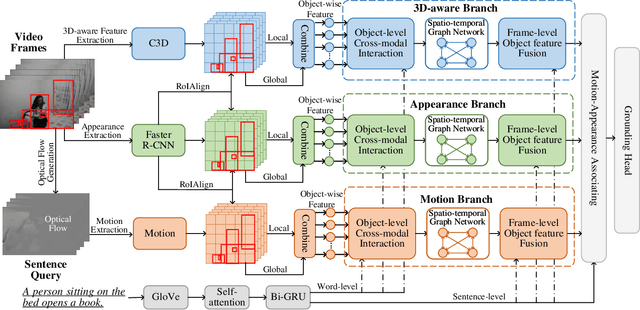
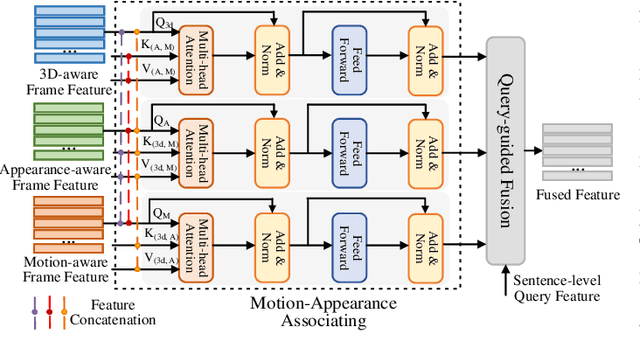
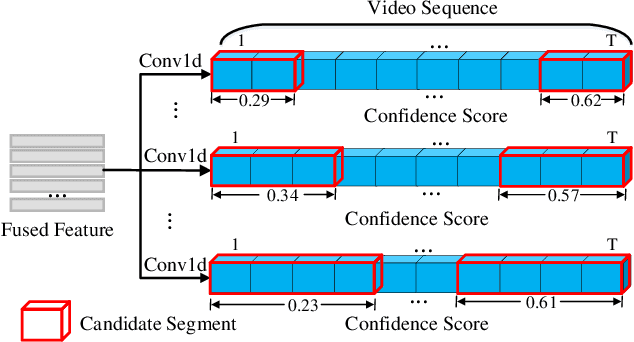
Temporal sentence grounding aims to localize a target segment in an untrimmed video semantically according to a given sentence query. Most previous works focus on learning frame-level features of each whole frame in the entire video, and directly match them with the textual information. Such frame-level feature extraction leads to the obstacles of these methods in distinguishing ambiguous video frames with complicated contents and subtle appearance differences, thus limiting their performance. In order to differentiate fine-grained appearance similarities among consecutive frames, some state-of-the-art methods additionally employ a detection model like Faster R-CNN to obtain detailed object-level features in each frame for filtering out the redundant background contents. However, these methods suffer from missing motion analysis since the object detection module in Faster R-CNN lacks temporal modeling. To alleviate the above limitations, in this paper, we propose a novel Motion- and Appearance-guided 3D Semantic Reasoning Network (MA3SRN), which incorporates optical-flow-guided motion-aware, detection-based appearance-aware, and 3D-aware object-level features to better reason the spatial-temporal object relations for accurately modelling the activity among consecutive frames. Specifically, we first develop three individual branches for motion, appearance, and 3D encoding separately to learn fine-grained motion-guided, appearance-guided, and 3D-aware object features, respectively. Then, both motion and appearance information from corresponding branches are associated to enhance the 3D-aware features for the final precise grounding. Extensive experiments on three challenging datasets (ActivityNet Caption, Charades-STA and TACoS) demonstrate that the proposed MA3SRN model achieves a new state-of-the-art.