 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHD360: A Benchmark Dataset for Salient Human Detection in 360° Videos
Jun 04, 2021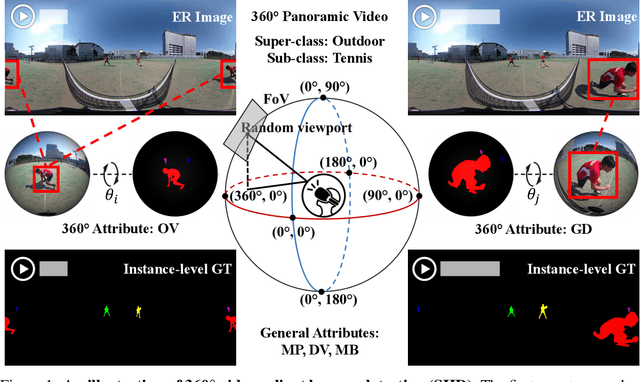
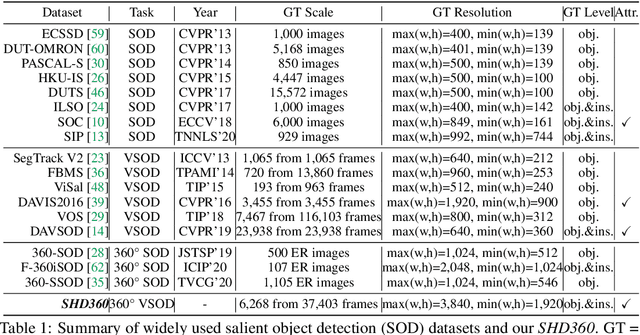
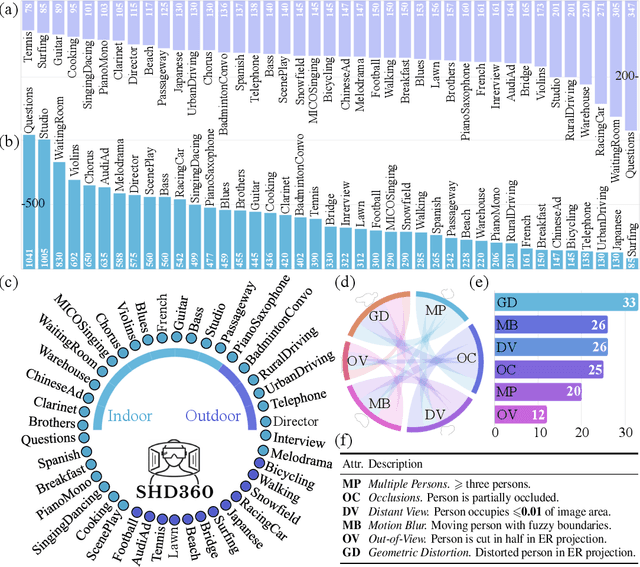
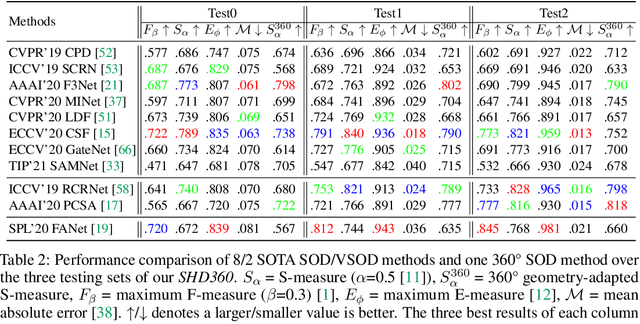
Salient human detection (SHD) in dynamic 360{\deg} immersive videos is of great importance for various applications such as robotics, inter-human and human-object interaction in augmented reality. However, 360{\deg} video SHD has been seldom discussed in the computer vision community due to a lack of datasets with large-scale omnidirectional videos and rich annotations. To this end, we propose SHD360, the first 360{\deg} video SHD dataset containing various real-life daily scenes borrowed from http://hidden.for.anonymity, with hierarchical annotations for 6,268 key frames uniformly sampled from 37,403 omnidirectional video frames at 4K resolution. Since so far there is no method proposed for 360{\deg} image/video SHD, we systematically benchmark 11 representative state-of-the-art salient object detection approaches on our SHD360. We hope our proposed dataset and benchmark could serve as a good starting point for advancing human-centric researches towards 360{\deg} panoramic data. Our dataset and benchmark will be publicly available at https://github.com/PanoAsh/SHD360.
Learning Synergistic Attention for Light Field Salient Object Detection
May 16, 2021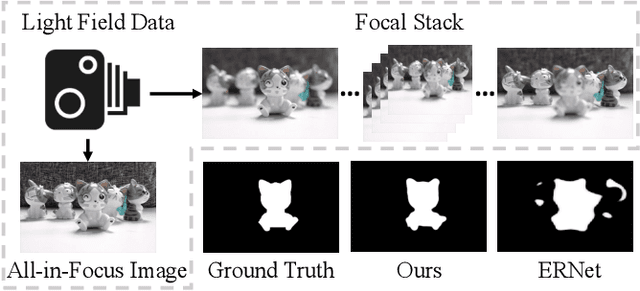
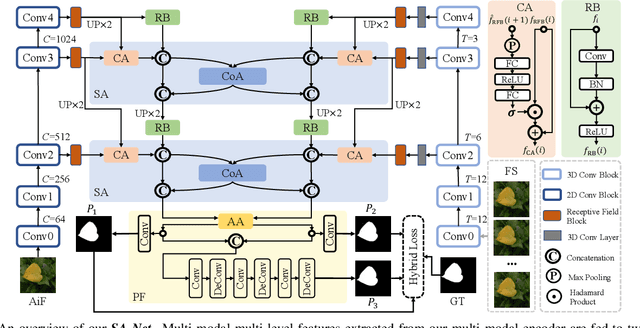
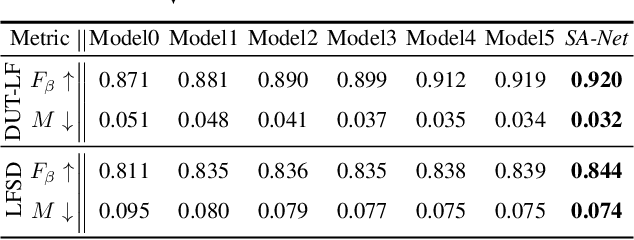
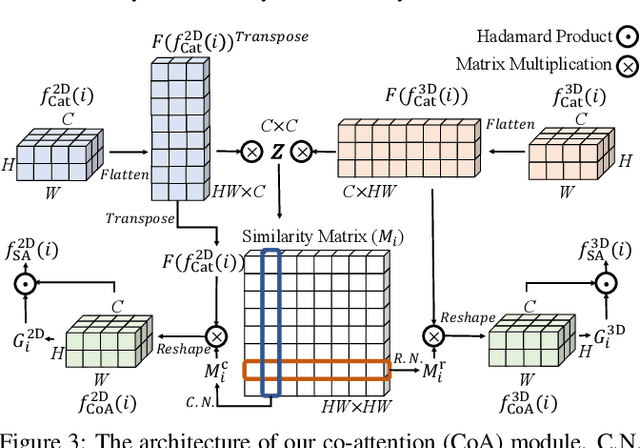
We propose a novel Synergistic Attention Network (SA-Net) to address the light field salient object detection by establishing a synergistic effect between multi-modal features with advanced attention mechanisms. Our SA-Net exploits the rich information of focal stacks via 3D convolutional neural networks, decodes the high-level features of multi-modal light field data with two cascaded synergistic attention modules, and predicts the saliency map using an effective feature fusion module in a progressive manner. Extensive experiments on three widely-used benchmark datasets show that our SA-Net outperforms 28 state-of-the-art models, sufficiently demonstrating its effectiveness and superiority. Our code will be made publicly available.
A CNN-based Prediction-Aware Quality Enhancement Framework for VVC
May 12, 2021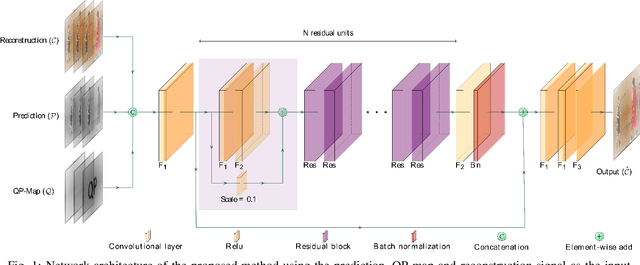
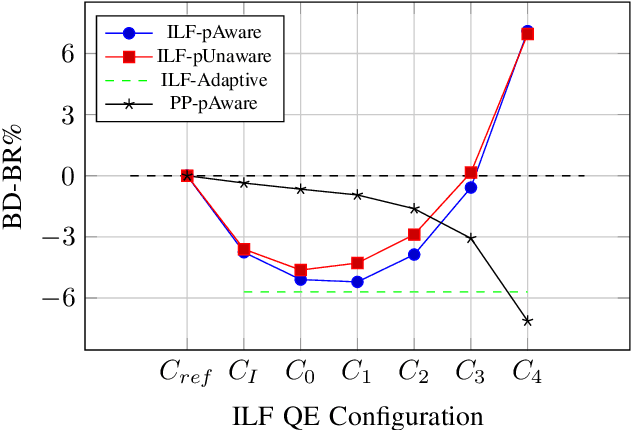
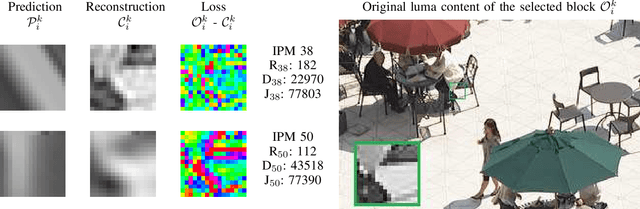
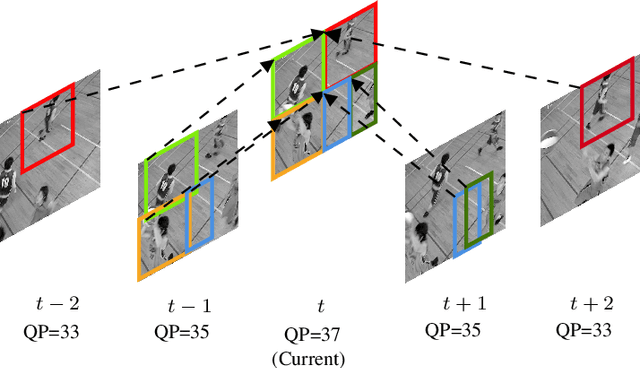
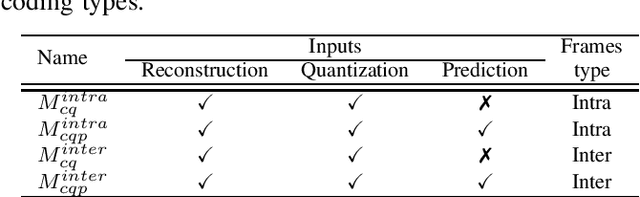
This paper presents a framework for Convolutional Neural Network (CNN)-based quality enhancement task, by taking advantage of coding information in the compressed video signal. The motivation is that normative decisions made by the encoder can significantly impact the type and strength of artifacts in the decoded images. In this paper, the main focus has been put on decisions defining the prediction signal in intra and inter frames. This information has been used in the training phase as well as input to help the process of learning artifacts that are specific to each coding type. Furthermore, to retain a low memory requirement for the proposed method, one model is used for all Quantization Parameters (QPs) with a QP-map, which is also shared between luma and chroma components. In addition to the Post Processing (PP) approach, the In-Loop Filtering (ILF) codec integration has also been considered, where the characteristics of the Group of Pictures (GoP) are taken into account to boost the performance. The proposed CNN-based Quality Enhancement(QE) framework has been implemented on top of the VVC Test Model (VTM-10). Experiments show that the prediction-aware aspect of the proposed method improves the coding efficiency gain of the default CNN-based QE method by 1.52%, in terms of BD-BR, at the same network complexity compared to the default CNN-based QE filter.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021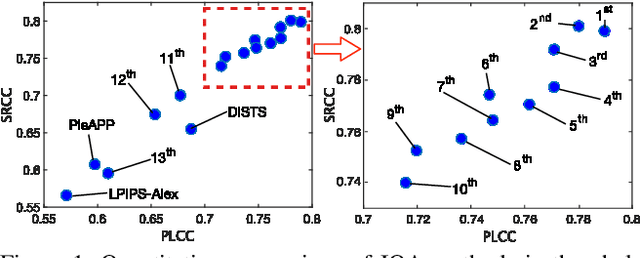
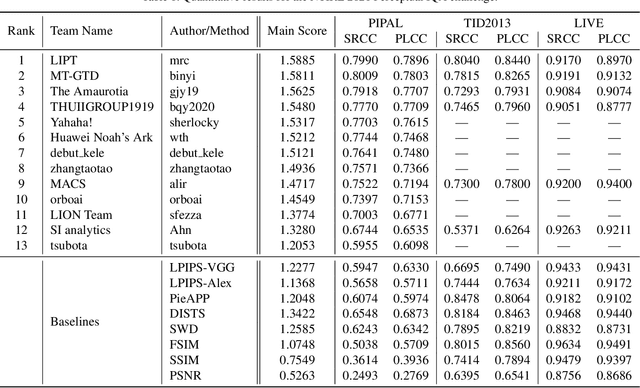

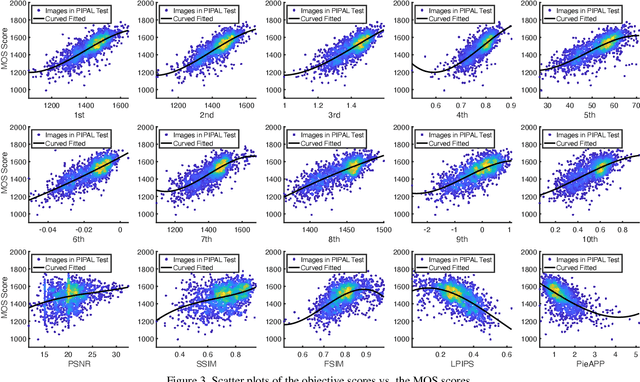
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Model Selection CNN-based VVC QualityEnhancement
May 07, 2021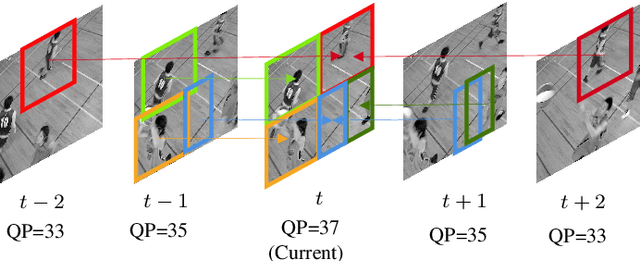
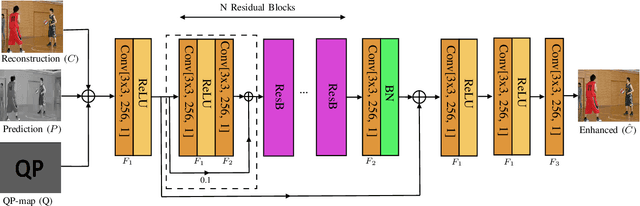

Artifact removal and filtering methods are inevitable parts of video coding. On one hand, new codecs and compression standards come with advanced in-loop filters and on the other hand, displays are equipped with high capacity processing units for post-treatment of decoded videos. This paper proposes a Convolutional Neural Network (CNN)-based post-processing algorithm for intra and inter frames of Versatile Video Coding (VVC) coded streams. Depending on the frame type, this method benefits from normative prediction signal by feeding it as an additional input along with reconstructed signal and a Quantization Parameter (QP)-map to the CNN. Moreover, an optional Model Selection (MS) strategy is adopted to pick the best trained model among available ones at the encoder side and signal it to the decoder side. This MS strategy is applicable at both frame level and block level. The experiments under the Random Access (RA) configuration of the VVC Test Model (VTM-10.0) show that the proposed prediction-aware algorithm can bring an additional BD-BR gain of -1.3% compared to the method without the prediction information. Furthermore, the proposed MS scheme brings -0.5% more BD-BR gain on top of the prediction-aware method.
CMA-Net: A Cascaded Mutual Attention Network for Light Field Salient Object Detection
May 07, 2021
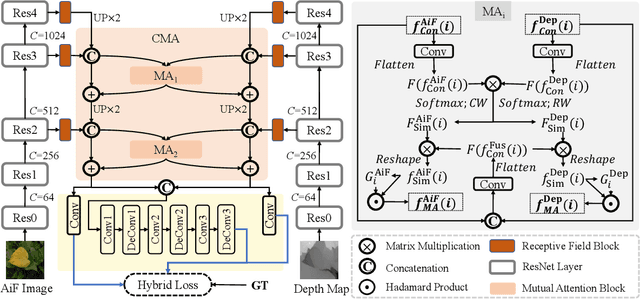
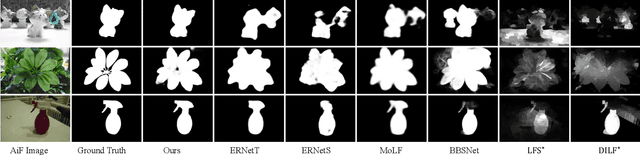
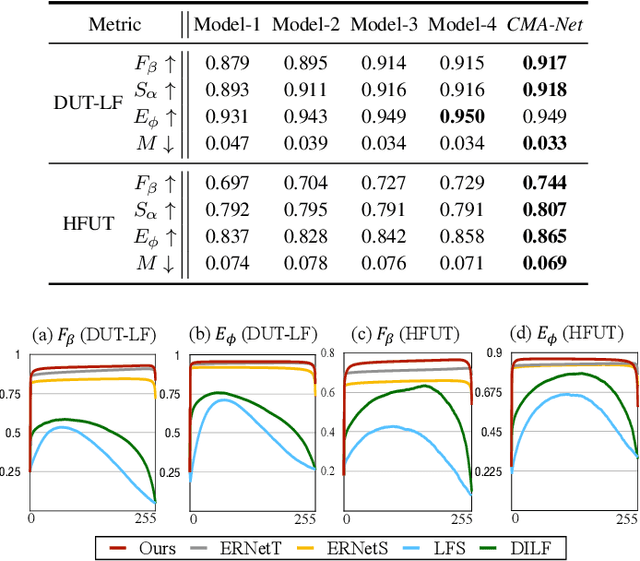
In the past few years, numerous deep learning methods have been proposed to address the task of segmenting salient objects from RGB images. However, these approaches depending on single modality fail to achieve the state-of-the-art performance on widely used light field salient object detection (SOD) datasets, which collect large-scale natural images and provide multiple modalities such as multi-view, micro-lens images and depth maps. Most recently proposed light field SOD methods have acquired improving detecting accuracy, yet still predict rough objects' structures and perform slow inference speed. To this end, we propose CMA-Net, which consists of two novel cascaded mutual attention modules aiming at fusing the high level features from the modalities of all-in-focus and depth. Our proposed CMA-Net outperforms 30 SOD methods (by a large margin) on two widely applied light field benchmark datasets. Besides, the proposed CMA-Net can run at a speed of 53 fps, thus being four times faster than the state-of-the-art multi-modal SOD methods. Extensive quantitative and qualitative experiments illustrate both the effectiveness and efficiency of our CMA-Net, inspiring future development of multi-modal learning for both the RGB-D and light field SOD.
Multitask Learning for VVC Quality Enhancement and Super-Resolution
May 03, 2021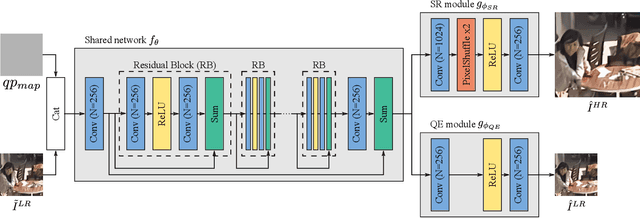
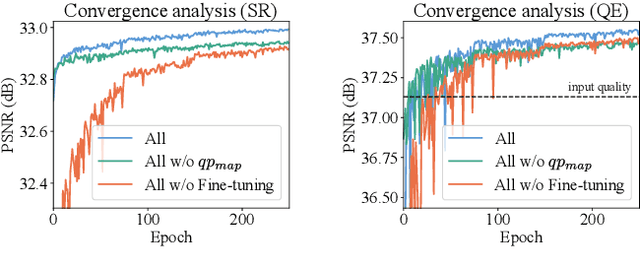

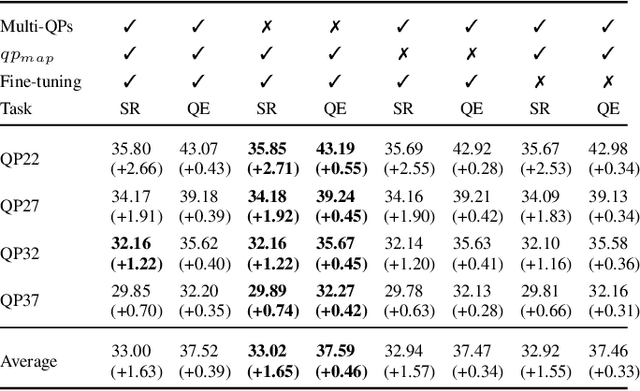
The latest video coding standard, called versatile video coding (VVC), includes several novel and refined coding tools at different levels of the coding chain. These tools bring significant coding gains with respect to the previous standard, high efficiency video coding (HEVC). However, the encoder may still introduce visible coding artifacts, mainly caused by coding decisions applied to adjust the bitrate to the available bandwidth. Hence, pre and post-processing techniques are generally added to the coding pipeline to improve the quality of the decoded video. These methods have recently shown outstanding results compared to traditional approaches, thanks to the recent advances in deep learning. Generally, multiple neural networks are trained independently to perform different tasks, thus omitting to benefit from the redundancy that exists between the models. In this paper, we investigate a learning-based solution as a post-processing step to enhance the decoded VVC video quality. Our method relies on multitask learning to perform both quality enhancement and super-resolution using a single shared network optimized for multiple degradation levels. The proposed solution enables a good performance in both mitigating coding artifacts and super-resolution with fewer network parameters compared to traditional specialized architectures.
Adversarial Example Detection for DNN Models: A Review
May 01, 2021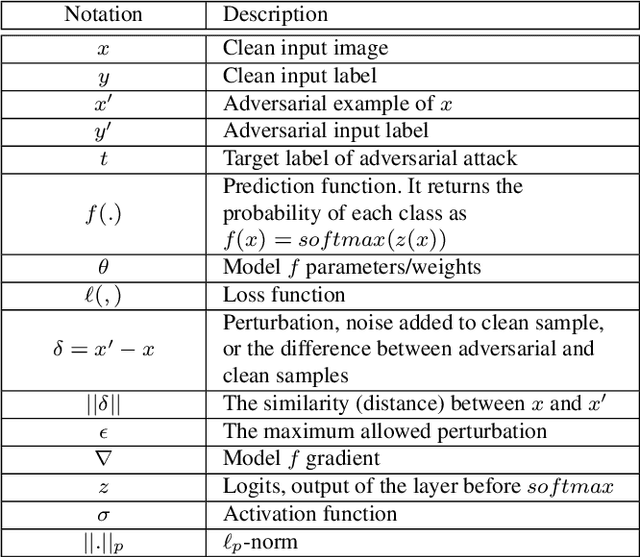
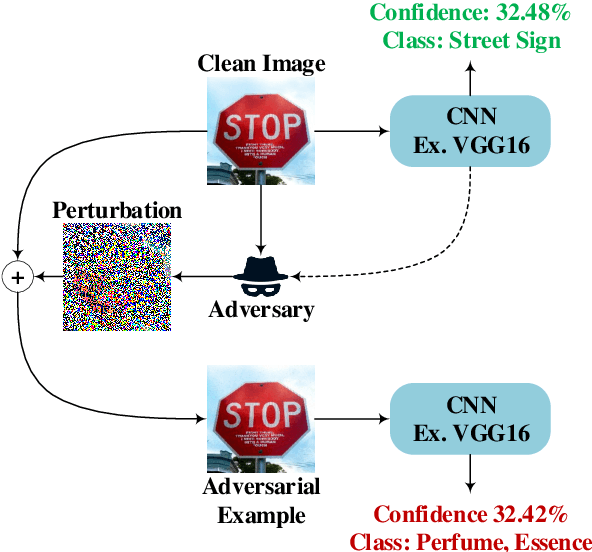
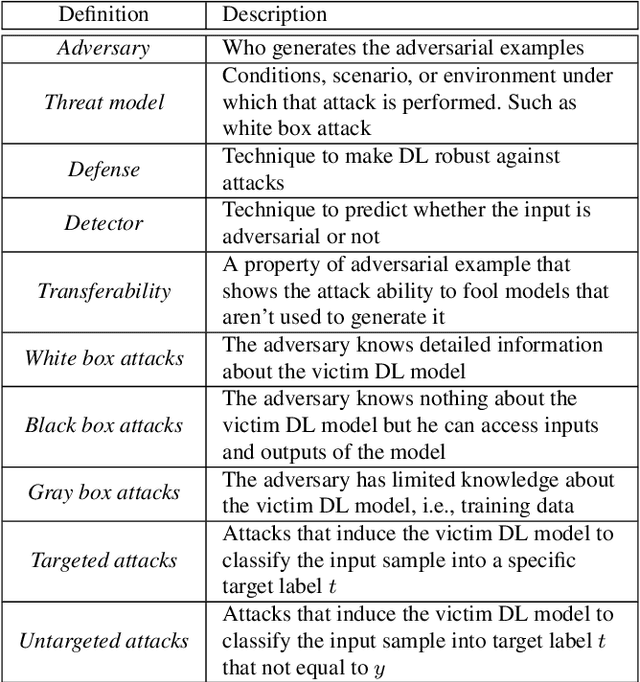
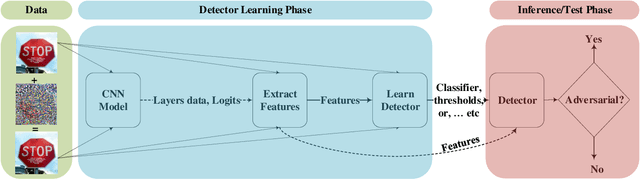
Deep Learning (DL) has shown great success in many human-related tasks, which has led to its adoption in many computer vision based applications, such as security surveillance system, autonomous vehicles and healthcare. Such safety-critical applications have to draw its path to success deployment once they have the capability to overcome safety-critical challenges. Among these challenges are the defense against or/and the detection of the adversarial example (AE). Adversary can carefully craft small, often imperceptible, noise called perturbations, to be added to the clean image to generate the AE. The aim of AE is to fool the DL model which makes it a potential risk for DL applications. Many test-time evasion attacks and countermeasures, i.e., defense or detection methods, are proposed in the literature. Moreover, few reviews and surveys were published and theoretically showed the taxonomy of the threats and the countermeasure methods with little focus in AE detection methods. In this paper, we attempt to provide a theoretical and experimental review for AE detection methods. A detailed discussion for such methods is provided and experimental results for eight state-of-the-art detectors are presented under different scenarios on four datasets. We also provide potential challenges and future perspectives for this research direction.
Conditional Coding for Flexible Learned Video Compression
Apr 28, 2021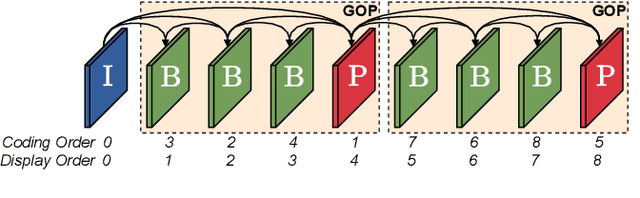

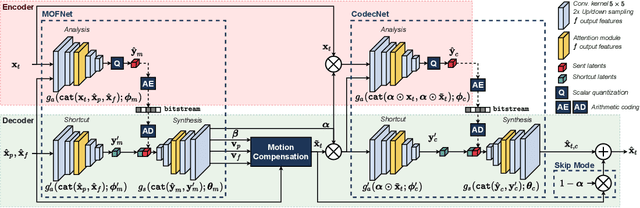
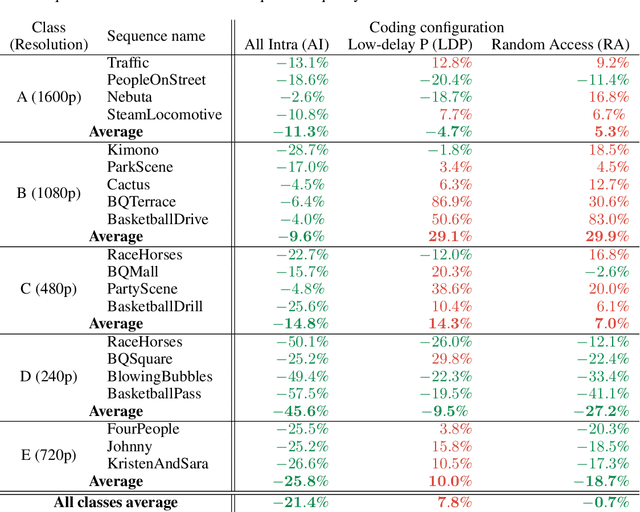
This paper introduces a novel framework for end-to-end learned video coding. Image compression is generalized through conditional coding to exploit information from reference frames, allowing to process intra and inter frames with the same coder. The system is trained through the minimization of a rate-distortion cost, with no pre-training or proxy loss. Its flexibility is assessed under three coding configurations (All Intra, Low-delay P and Random Access), where it is shown to achieve performance competitive with the state-of-the-art video codec HEVC.
Conditional Coding and Variable Bitrate for Practical Learned Video Coding
Apr 20, 2021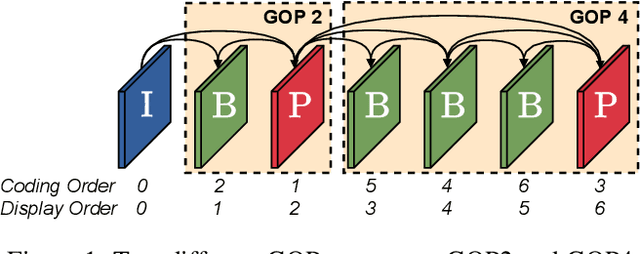
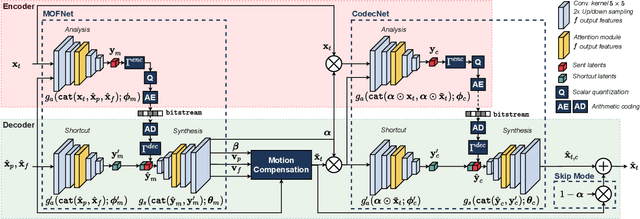
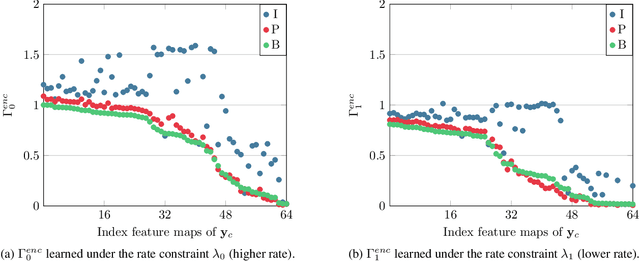
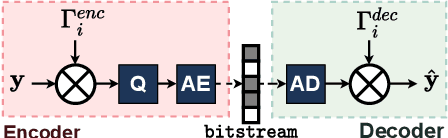
This paper introduces a practical learned video codec. Conditional coding and quantization gain vectors are used to provide flexibility to a single encoder/decoder pair, which is able to compress video sequences at a variable bitrate. The flexibility is leveraged at test time by choosing the rate and GOP structure to optimize a rate-distortion cost. Using the CLIC21 video test conditions, the proposed approach shows performance on par with HEVC.