 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Clients Clustering with Adaptation to Data Drifts
Nov 03, 2024



Federated Learning (FL) enables deep learning model training across edge devices and protects user privacy by retaining raw data locally. Data heterogeneity in client distributions slows model convergence and leads to plateauing with reduced precision. Clustered FL solutions address this by grouping clients with statistically similar data and training models for each cluster. However, maintaining consistent client similarity within each group becomes challenging when data drifts occur, significantly impacting model accuracy. In this paper, we introduce Fielding, a clustered FL framework that handles data drifts promptly with low overheads. Fielding detects drifts on all clients and performs selective label distribution-based re-clustering to balance cluster optimality and model performance, remaining robust to malicious clients and varied heterogeneity degrees. Our evaluations show that Fielding improves model final accuracy by 1.9%-5.9% and reaches target accuracies 1.16x-2.61x faster.
Assessing and Enhancing Large Language Models in Rare Disease Question-answering
Aug 15, 2024



Despite the impressive capabilities of Large Language Models (LLMs) in general medical domains, questions remain about their performance in diagnosing rare diseases. To answer this question, we aim to assess the diagnostic performance of LLMs in rare diseases, and explore methods to enhance their effectiveness in this area. In this work, we introduce a rare disease question-answering (ReDis-QA) dataset to evaluate the performance of LLMs in diagnosing rare diseases. Specifically, we collected 1360 high-quality question-answer pairs within the ReDis-QA dataset, covering 205 rare diseases. Additionally, we annotated meta-data for each question, facilitating the extraction of subsets specific to any given disease and its property. Based on the ReDis-QA dataset, we benchmarked several open-source LLMs, revealing that diagnosing rare diseases remains a significant challenge for these models. To facilitate retrieval augmentation generation for rare disease diagnosis, we collect the first rare diseases corpus (ReCOP), sourced from the National Organization for Rare Disorders (NORD) database. Specifically, we split the report of each rare disease into multiple chunks, each representing a different property of the disease, including their overview, symptoms, causes, effects, related disorders, diagnosis, and standard therapies. This structure ensures that the information within each chunk aligns consistently with a question. Experiment results demonstrate that ReCOP can effectively improve the accuracy of LLMs on the ReDis-QA dataset by an average of 8%. Moreover, it significantly guides LLMs to generate trustworthy answers and explanations that can be traced back to existing literature.
Learning-augmented Maximum Independent Set
Jul 16, 2024We study the Maximum Independent Set (MIS) problem on general graphs within the framework of learning-augmented algorithms. The MIS problem is known to be NP-hard and is also NP-hard to approximate to within a factor of $n^{1-\delta}$ for any $\delta>0$. We show that we can break this barrier in the presence of an oracle obtained through predictions from a machine learning model that answers vertex membership queries for a fixed MIS with probability $1/2+\varepsilon$. In the first setting we consider, the oracle can be queried once per vertex to know if a vertex belongs to a fixed MIS, and the oracle returns the correct answer with probability $1/2 + \varepsilon$. Under this setting, we show an algorithm that obtains an $\tilde{O}(\sqrt{\Delta}/\varepsilon)$-approximation in $O(m)$ time where $\Delta$ is the maximum degree of the graph. In the second setting, we allow multiple queries to the oracle for a vertex, each of which is correct with probability $1/2 + \varepsilon$. For this setting, we show an $O(1)$-approximation algorithm using $O(n/\varepsilon^2)$ total queries and $\tilde{O}(m)$ runtime.
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Feb 05, 2024



Efficiently serving large language models (LLMs) requires batching many requests together to reduce the cost per request. Yet, the key-value (KV) cache, which stores attention keys and values to avoid re-computations, significantly increases memory demands and becomes the new bottleneck in speed and memory usage. This memory demand increases with larger batch sizes and longer context lengths. Additionally, the inference speed is limited by the size of KV cache, as the GPU's SRAM must load the entire KV cache from the main GPU memory for each token generated, causing the computational core to be idle during this process. A straightforward and effective solution to reduce KV cache size is quantization, which decreases the total bytes taken by KV cache. However, there is a lack of in-depth studies that explore the element distribution of KV cache to understand the hardness and limitation of KV cache quantization. To fill the gap, we conducted a comprehensive study on the element distribution in KV cache of popular LLMs. Our findings indicate that the key cache should be quantized per-channel, i.e., group elements along the channel dimension and quantize them together. In contrast, the value cache should be quantized per-token. From this analysis, we developed a tuning-free 2bit KV cache quantization algorithm, named KIVI. With the hardware-friendly implementation, KIVI can enable Llama (Llama-2), Falcon, and Mistral models to maintain almost the same quality while using $\mathbf{2.6\times}$ less peak memory usage (including the model weight). This reduction in memory usage enables up to $\mathbf{4\times}$ larger batch size, bringing $\mathbf{2.35\times \sim 3.47\times}$ throughput on real LLM inference workload. The source code is available at https://github.com/jy-yuan/KIVI.
ORBSLAM3-Enhanced Autonomous Toy Drones: Pioneering Indoor Exploration
Dec 20, 2023Navigating toy drones through uncharted GPS-denied indoor spaces poses significant difficulties due to their reliance on GPS for location determination. In such circumstances, the necessity for achieving proper navigation is a primary concern. In response to this formidable challenge, we introduce a real-time autonomous indoor exploration system tailored for drones equipped with a monocular \emph{RGB} camera. Our system utilizes \emph{ORB-SLAM3}, a state-of-the-art vision feature-based SLAM, to handle both the localization of toy drones and the mapping of unmapped indoor terrains. Aside from the practicability of \emph{ORB-SLAM3}, the generated maps are represented as sparse point clouds, making them prone to the presence of outlier data. To address this challenge, we propose an outlier removal algorithm with provable guarantees. Furthermore, our system incorporates a novel exit detection algorithm, ensuring continuous exploration by the toy drone throughout the unfamiliar indoor environment. We also transform the sparse point to ensure proper path planning using existing path planners. To validate the efficacy and efficiency of our proposed system, we conducted offline and real-time experiments on the autonomous exploration of indoor spaces. The results from these endeavors demonstrate the effectiveness of our methods.
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
Oct 12, 2023Transformers pretrained on diverse tasks exhibit remarkable in-context learning (ICL) capabilities, enabling them to solve unseen tasks solely based on input contexts without adjusting model parameters. In this paper, we study ICL in one of its simplest setups: pretraining a linearly parameterized single-layer linear attention model for linear regression with a Gaussian prior. We establish a statistical task complexity bound for the attention model pretraining, showing that effective pretraining only requires a small number of independent tasks. Furthermore, we prove that the pretrained model closely matches the Bayes optimal algorithm, i.e., optimally tuned ridge regression, by achieving nearly Bayes optimal risk on unseen tasks under a fixed context length. These theoretical findings complement prior experimental research and shed light on the statistical foundations of ICL.
Scaling Distributed Multi-task Reinforcement Learning with Experience Sharing
Jul 11, 2023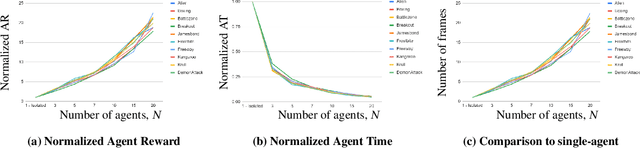
Recently, DARPA launched the ShELL program, which aims to explore how experience sharing can benefit distributed lifelong learning agents in adapting to new challenges. In this paper, we address this issue by conducting both theoretical and empirical research on distributed multi-task reinforcement learning (RL), where a group of $N$ agents collaboratively solves $M$ tasks without prior knowledge of their identities. We approach the problem by formulating it as linearly parameterized contextual Markov decision processes (MDPs), where each task is represented by a context that specifies the transition dynamics and rewards. To tackle this problem, we propose an algorithm called DistMT-LSVI. First, the agents identify the tasks, and then they exchange information through a central server to derive $\epsilon$-optimal policies for the tasks. Our research demonstrates that to achieve $\epsilon$-optimal policies for all $M$ tasks, a single agent using DistMT-LSVI needs to run a total number of episodes that is at most $\tilde{\mathcal{O}}({d^3H^6(\epsilon^{-2}+c_{\rm sep}^{-2})}\cdot M/N)$, where $c_{\rm sep}>0$ is a constant representing task separability, $H$ is the horizon of each episode, and $d$ is the feature dimension of the dynamics and rewards. Notably, DistMT-LSVI improves the sample complexity of non-distributed settings by a factor of $1/N$, as each agent independently learns $\epsilon$-optimal policies for all $M$ tasks using $\tilde{\mathcal{O}}(d^3H^6M\epsilon^{-2})$ episodes. Additionally, we provide numerical experiments conducted on OpenAI Gym Atari environments that validate our theoretical findings.
Private Federated Frequency Estimation: Adapting to the Hardness of the Instance
Jun 15, 2023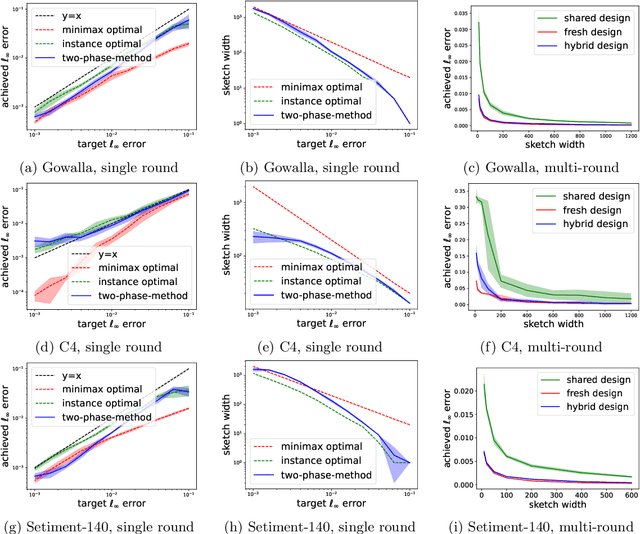
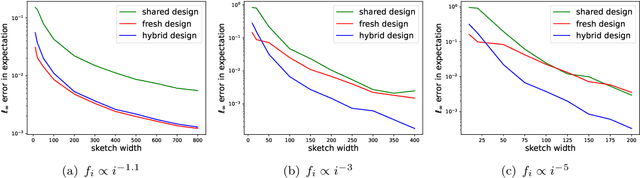
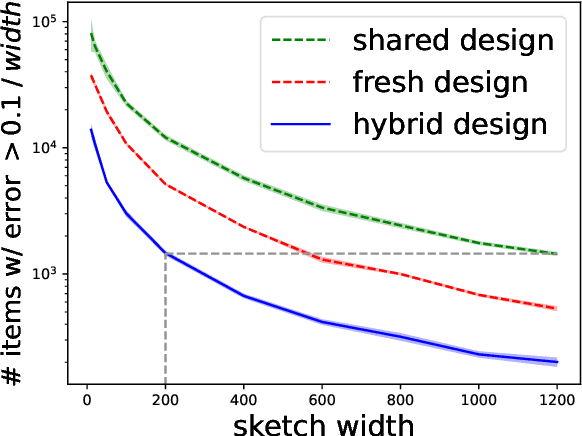
In federated frequency estimation (FFE), multiple clients work together to estimate the frequencies of their collective data by communicating with a server that respects the privacy constraints of Secure Summation (SecSum), a cryptographic multi-party computation protocol that ensures that the server can only access the sum of client-held vectors. For single-round FFE, it is known that count sketching is nearly information-theoretically optimal for achieving the fundamental accuracy-communication trade-offs [Chen et al., 2022]. However, we show that under the more practical multi-round FEE setting, simple adaptations of count sketching are strictly sub-optimal, and we propose a novel hybrid sketching algorithm that is provably more accurate. We also address the following fundamental question: how should a practitioner set the sketch size in a way that adapts to the hardness of the underlying problem? We propose a two-phase approach that allows for the use of a smaller sketch size for simpler problems (e.g. near-sparse or light-tailed distributions). We conclude our work by showing how differential privacy can be added to our algorithm and verifying its superior performance through extensive experiments conducted on large-scale datasets.
A framework for dynamically training and adapting deep reinforcement learning models to different, low-compute, and continuously changing radiology deployment environments
Jun 08, 2023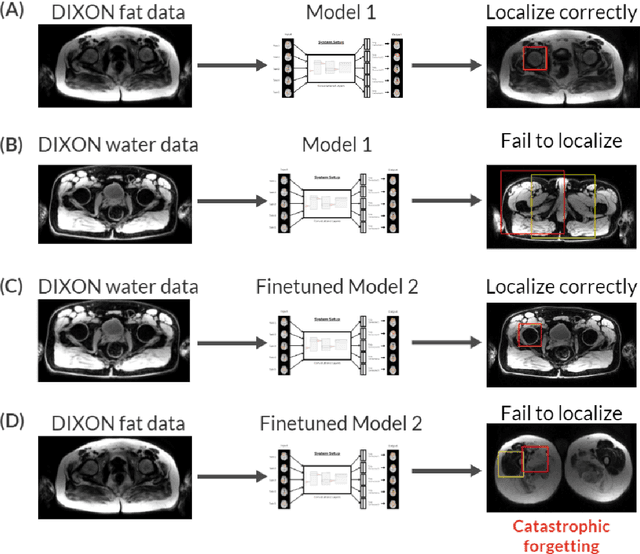
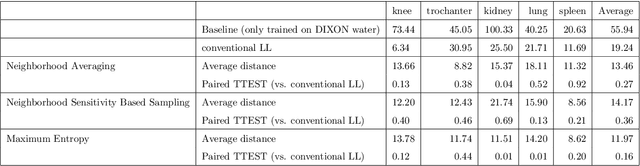
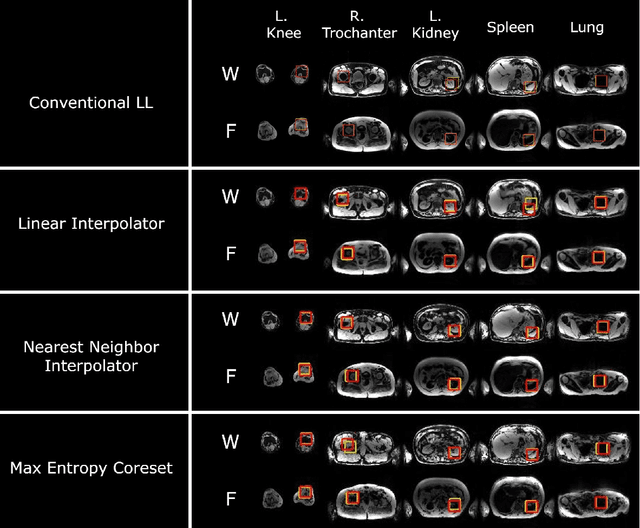
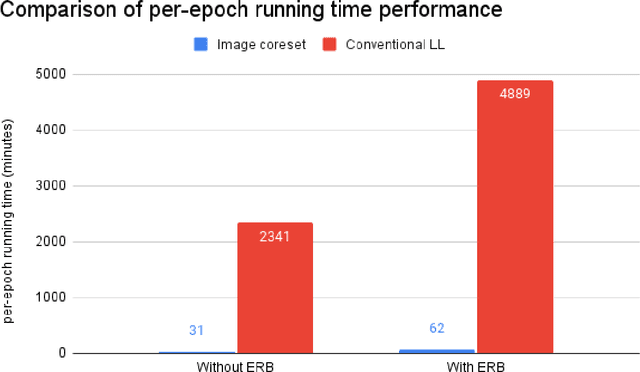
While Deep Reinforcement Learning has been widely researched in medical imaging, the training and deployment of these models usually require powerful GPUs. Since imaging environments evolve rapidly and can be generated by edge devices, the algorithm is required to continually learn and adapt to changing environments, and adjust to low-compute devices. To this end, we developed three image coreset algorithms to compress and denoise medical images for selective experience replayed-based lifelong reinforcement learning. We implemented neighborhood averaging coreset, neighborhood sensitivity-based sampling coreset, and maximum entropy coreset on full-body DIXON water and DIXON fat MRI images. All three coresets produced 27x compression with excellent performance in localizing five anatomical landmarks: left knee, right trochanter, left kidney, spleen, and lung across both imaging environments. Maximum entropy coreset obtained the best performance of $11.97\pm 12.02$ average distance error, compared to the conventional lifelong learning framework's $19.24\pm 50.77$.
Multi-environment lifelong deep reinforcement learning for medical imaging
May 31, 2023Deep reinforcement learning(DRL) is increasingly being explored in medical imaging. However, the environments for medical imaging tasks are constantly evolving in terms of imaging orientations, imaging sequences, and pathologies. To that end, we developed a Lifelong DRL framework, SERIL to continually learn new tasks in changing imaging environments without catastrophic forgetting. SERIL was developed using selective experience replay based lifelong learning technique for the localization of five anatomical landmarks in brain MRI on a sequence of twenty-four different imaging environments. The performance of SERIL, when compared to two baseline setups: MERT(multi-environment-best-case) and SERT(single-environment-worst-case) demonstrated excellent performance with an average distance of $9.90\pm7.35$ pixels from the desired landmark across all 120 tasks, compared to $10.29\pm9.07$ for MERT and $36.37\pm22.41$ for SERT($p<0.05$), demonstrating the excellent potential for continuously learning multiple tasks across dynamically changing imaging environments.