 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness
Jan 21, 2023



Neural text-to-SQL models have achieved remarkable performance in translating natural language questions into SQL queries. However, recent studies reveal that text-to-SQL models are vulnerable to task-specific perturbations. Previous curated robustness test sets usually focus on individual phenomena. In this paper, we propose a comprehensive robustness benchmark based on Spider, a cross-domain text-to-SQL benchmark, to diagnose the model robustness. We design 17 perturbations on databases, natural language questions, and SQL queries to measure the robustness from different angles. In order to collect more diversified natural question perturbations, we utilize large pretrained language models (PLMs) to simulate human behaviors in creating natural questions. We conduct a diagnostic study of the state-of-the-art models on the robustness set. Experimental results reveal that even the most robust model suffers from a 14.0% performance drop overall and a 50.7% performance drop on the most challenging perturbation. We also present a breakdown analysis regarding text-to-SQL model designs and provide insights for improving model robustness.
Importance of Synthesizing High-quality Data for Text-to-SQL Parsing
Dec 17, 2022



Recently, there has been increasing interest in synthesizing data to improve downstream text-to-SQL tasks. In this paper, we first examined the existing synthesized datasets and discovered that state-of-the-art text-to-SQL algorithms did not further improve on popular benchmarks when trained with augmented synthetic data. We observed two shortcomings: illogical synthetic SQL queries from independent column sampling and arbitrary table joins. To address these issues, we propose a novel synthesis framework that incorporates key relationships from schema, imposes strong typing, and conducts schema-distance-weighted column sampling. We also adopt an intermediate representation (IR) for the SQL-to-text task to further improve the quality of the generated natural language questions. When existing powerful semantic parsers are pre-finetuned on our high-quality synthesized data, our experiments show that these models have significant accuracy boosts on popular benchmarks, including new state-of-the-art performance on Spider.
Novel Chapter Abstractive Summarization using Spinal Tree Aware Sub-Sentential Content Selection
Nov 09, 2022



Summarizing novel chapters is a difficult task due to the input length and the fact that sentences that appear in the desired summaries draw content from multiple places throughout the chapter. We present a pipelined extractive-abstractive approach where the extractive step filters the content that is passed to the abstractive component. Extremely lengthy input also results in a highly skewed dataset towards negative instances for extractive summarization; we thus adopt a margin ranking loss for extraction to encourage separation between positive and negative examples. Our extraction component operates at the constituent level; our approach to this problem enriches the text with spinal tree information which provides syntactic context (in the form of constituents) to the extraction model. We show an improvement of 3.71 Rouge-1 points over best results reported in prior work on an existing novel chapter dataset.
Synthetic Target Domain Supervision for Open Retrieval QA
Apr 20, 2022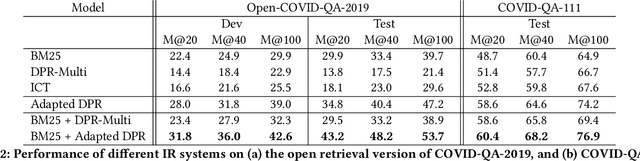
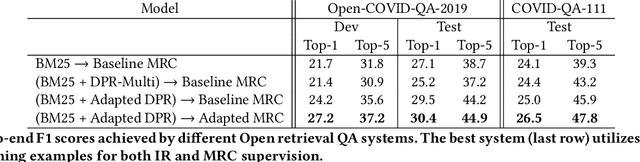
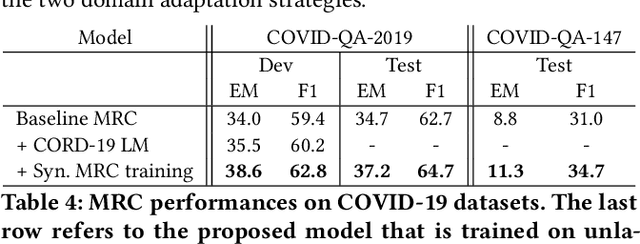
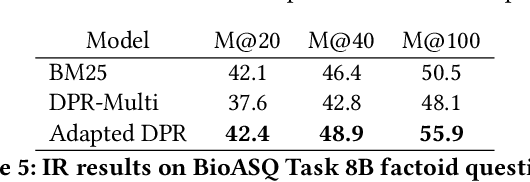
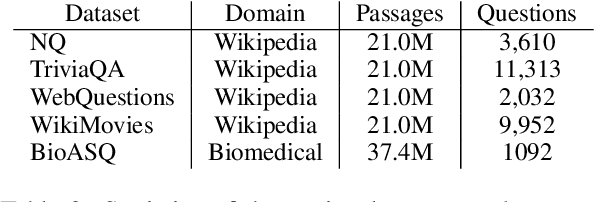
Neural passage retrieval is a new and promising approach in open retrieval question answering. In this work, we stress-test the Dense Passage Retriever (DPR) -- a state-of-the-art (SOTA) open domain neural retrieval model -- on closed and specialized target domains such as COVID-19, and find that it lags behind standard BM25 in this important real-world setting. To make DPR more robust under domain shift, we explore its fine-tuning with synthetic training examples, which we generate from unlabeled target domain text using a text-to-text generator. In our experiments, this noisy but fully automated target domain supervision gives DPR a sizable advantage over BM25 in out-of-domain settings, making it a more viable model in practice. Finally, an ensemble of BM25 and our improved DPR model yields the best results, further pushing the SOTA for open retrieval QA on multiple out-of-domain test sets.
Towards Robust Neural Retrieval Models with Synthetic Pre-Training
Apr 15, 2021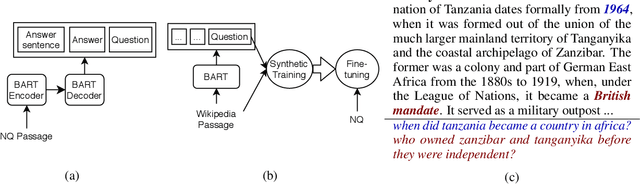


Recent work has shown that commonly available machine reading comprehension (MRC) datasets can be used to train high-performance neural information retrieval (IR) systems. However, the evaluation of neural IR has so far been limited to standard supervised learning settings, where they have outperformed traditional term matching baselines. We conduct in-domain and out-of-domain evaluations of neural IR, and seek to improve its robustness across different scenarios, including zero-shot settings. We show that synthetic training examples generated using a sequence-to-sequence generator can be effective towards this goal: in our experiments, pre-training with synthetic examples improves retrieval performance in both in-domain and out-of-domain evaluation on five different test sets.
End-to-End QA on COVID-19: Domain Adaptation with Synthetic Training
Dec 02, 2020
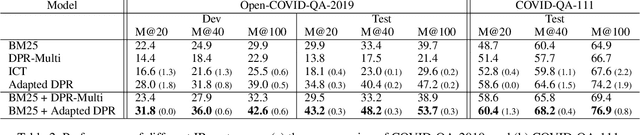


End-to-end question answering (QA) requires both information retrieval (IR) over a large document collection and machine reading comprehension (MRC) on the retrieved passages. Recent work has successfully trained neural IR systems using only supervised question answering (QA) examples from open-domain datasets. However, despite impressive performance on Wikipedia, neural IR lags behind traditional term matching approaches such as BM25 in more specific and specialized target domains such as COVID-19. Furthermore, given little or no labeled data, effective adaptation of QA systems can also be challenging in such target domains. In this work, we explore the application of synthetically generated QA examples to improve performance on closed-domain retrieval and MRC. We combine our neural IR and MRC systems and show significant improvements in end-to-end QA on the CORD-19 collection over a state-of-the-art open-domain QA baseline.
Answer Span Correction in Machine Reading Comprehension
Nov 06, 2020

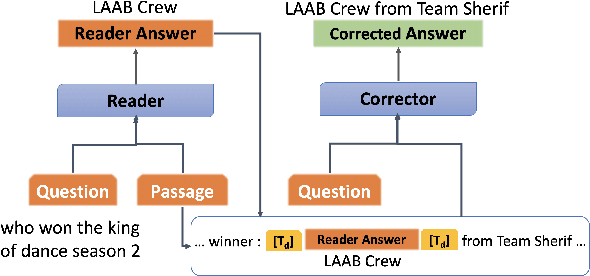

Answer validation in machine reading comprehension (MRC) consists of verifying an extracted answer against an input context and question pair. Previous work has looked at re-assessing the "answerability" of the question given the extracted answer. Here we address a different problem: the tendency of existing MRC systems to produce partially correct answers when presented with answerable questions. We explore the nature of such errors and propose a post-processing correction method that yields statistically significant performance improvements over state-of-the-art MRC systems in both monolingual and multilingual evaluation.
Improved Synthetic Training for Reading Comprehension
Oct 24, 2020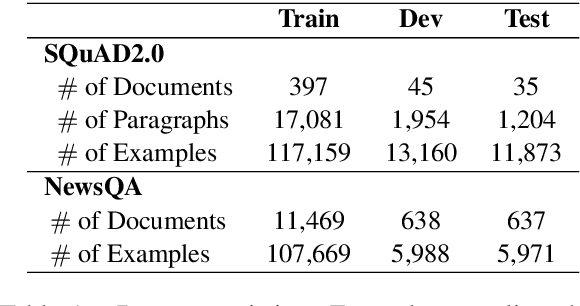
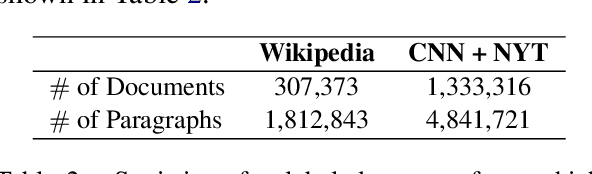
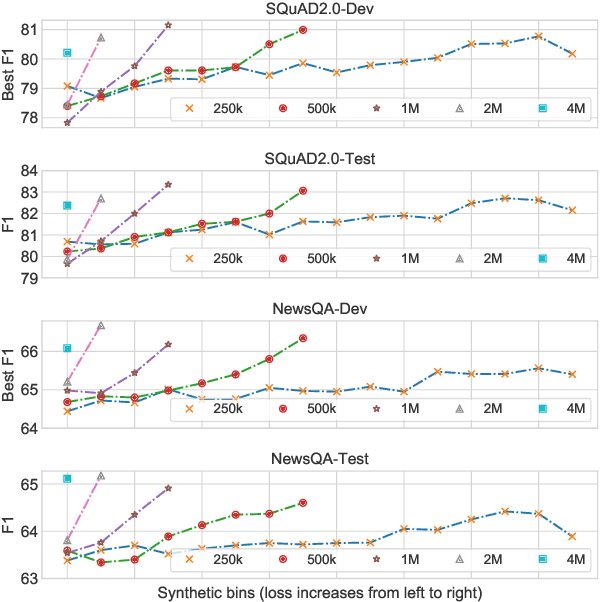
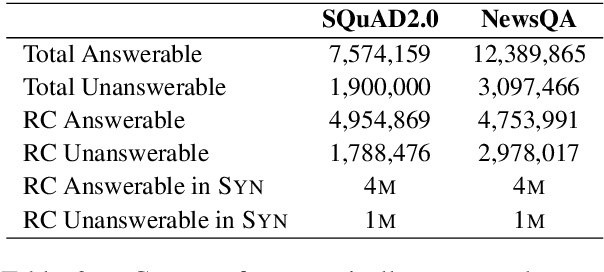
Automatically generated synthetic training examples have been shown to improve performance in machine reading comprehension (MRC). Compared to human annotated gold standard data, synthetic training data has unique properties, such as high availability at the possible expense of quality. In view of such differences, in this paper, we explore novel applications of synthetic examples to MRC. Our proposed pre-training and knowledge distillation strategies show significant improvements over existing methods. In a particularly surprising discovery, we observe that synthetic distillation often yields students that can outperform the teacher model.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
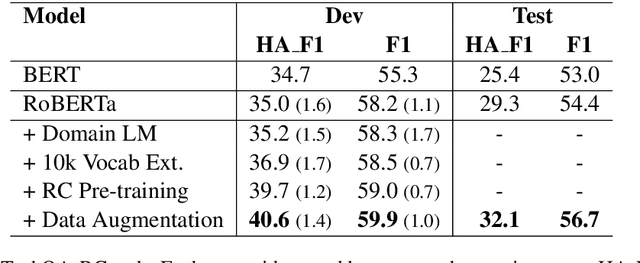
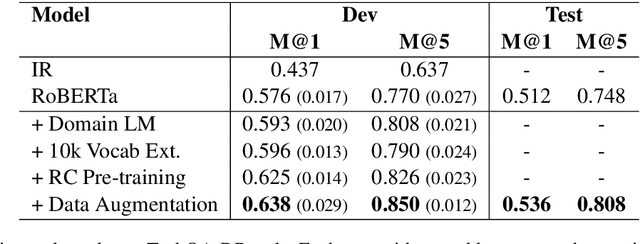
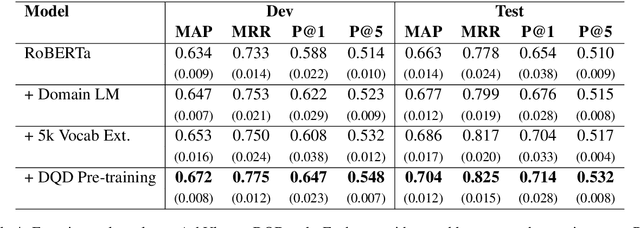
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.
The TechQA Dataset
Nov 08, 2019

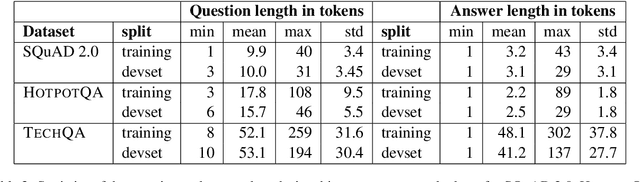
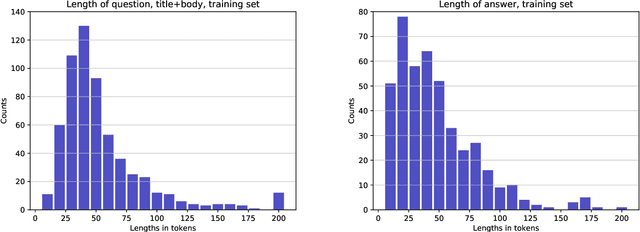
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.