 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022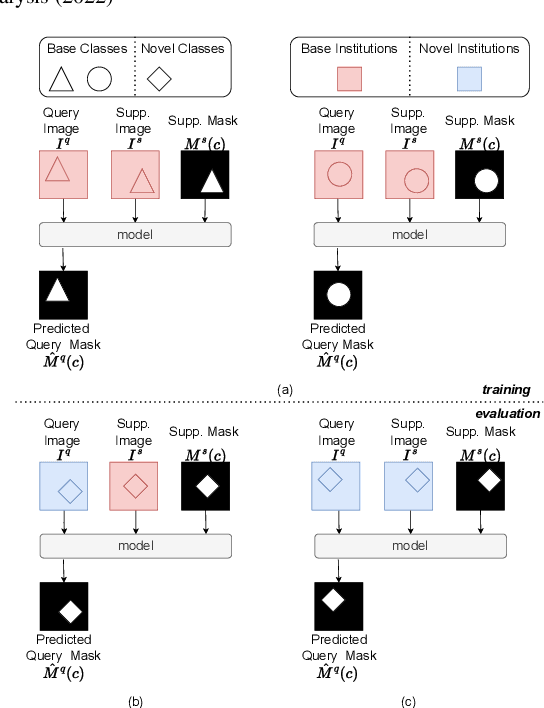

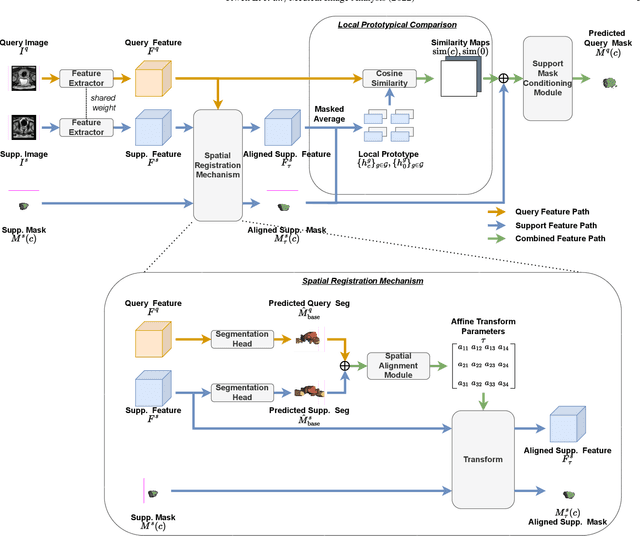

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.
DFNet: Enhance Absolute Pose Regression with Direct Feature Matching
Apr 04, 2022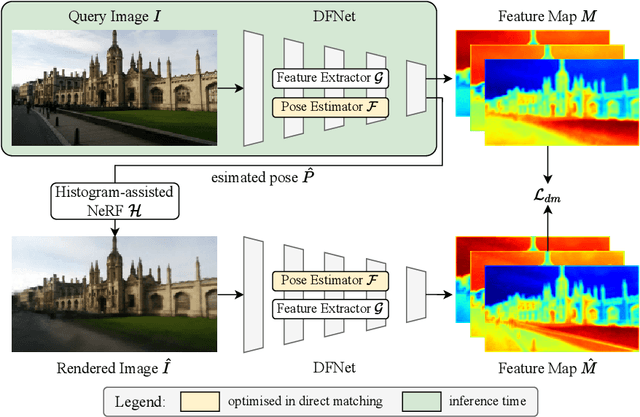
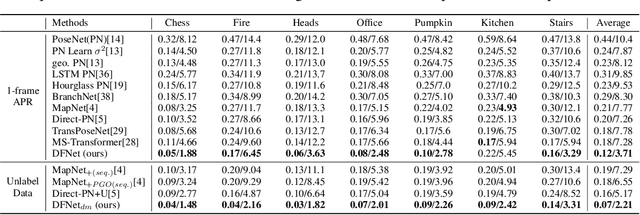
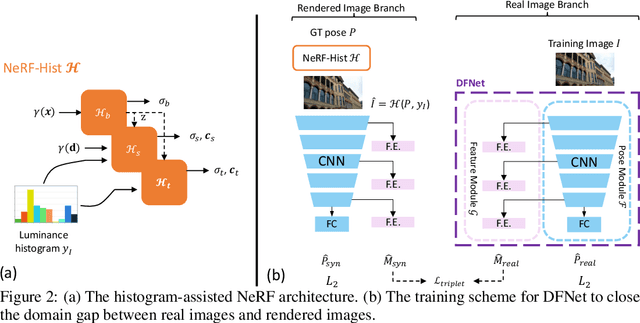
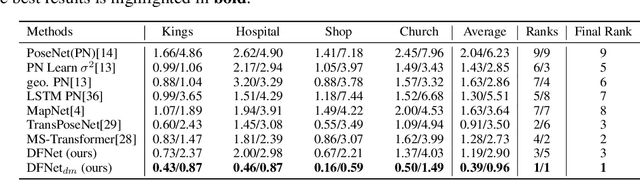
We introduce a camera relocalization pipeline that combines absolute pose regression (APR) and direct feature matching. Existing photometric-based methods have trouble on scenes with large photometric distortions, e.g. outdoor environments. By incorporating an exposure-adaptive novel view synthesis, our methods can successfully address the challenges. Moreover, by introducing domain-invariant feature matching, our solution can improve pose regression accuracy while using semi-supervised learning on unlabeled data. In particular, the pipeline consists of two components, Novel View Synthesizer and FeatureNet (DFNet). The former synthesizes novel views compensating for changes in exposure and the latter regresses camera poses and extracts robust features that bridge the domain gap between real images and synthetic ones. We show that domain invariant feature matching effectively enhances camera pose estimation both in indoor and outdoor scenes. Hence, our method achieves a state-of-the-art accuracy by outperforming existing single-image APR methods by as much as 56%, comparable to 3D structure-based methods.
BNV-Fusion: Dense 3D Reconstruction using Bi-level Neural Volume Fusion
Apr 03, 2022
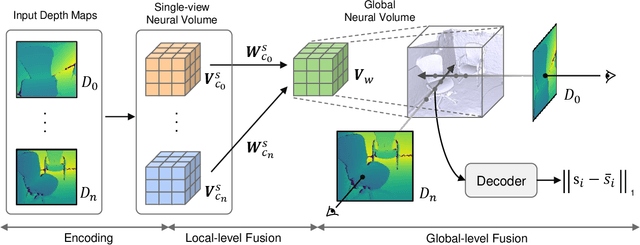

Dense 3D reconstruction from a stream of depth images is the key to many mixed reality and robotic applications. Although methods based on Truncated Signed Distance Function (TSDF) Fusion have advanced the field over the years, the TSDF volume representation is confronted with striking a balance between the robustness to noisy measurements and maintaining the level of detail. We present Bi-level Neural Volume Fusion (BNV-Fusion), which leverages recent advances in neural implicit representations and neural rendering for dense 3D reconstruction. In order to incrementally integrate new depth maps into a global neural implicit representation, we propose a novel bi-level fusion strategy that considers both efficiency and reconstruction quality by design. We evaluate the proposed method on multiple datasets quantitatively and qualitatively, demonstrating a significant improvement over existing methods.
Few-shot image segmentation for cross-institution male pelvic organs using registration-assisted prototypical learning
Jan 17, 2022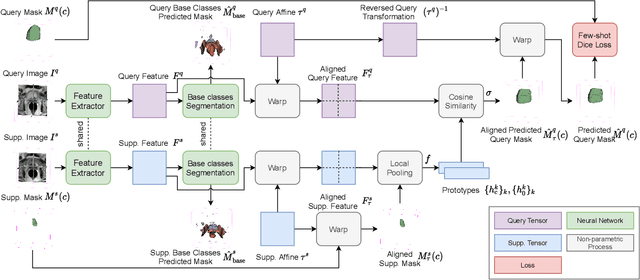
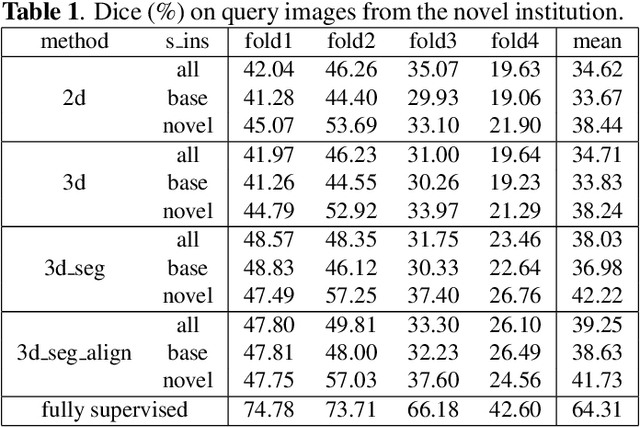
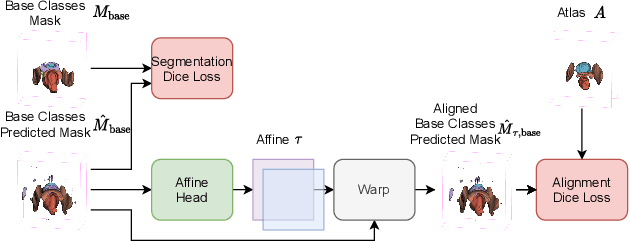
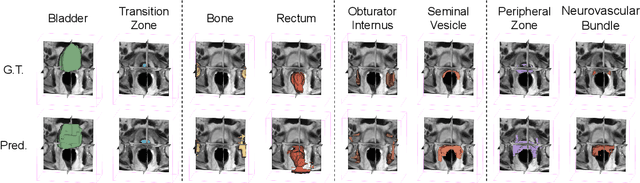
The ability to adapt medical image segmentation networks for a novel class such as an unseen anatomical or pathological structure, when only a few labelled examples of this class are available from local healthcare providers, is sought-after. This potentially addresses two widely recognised limitations in deploying modern deep learning models to clinical practice, expertise-and-labour-intensive labelling and cross-institution generalisation. This work presents the first 3D few-shot interclass segmentation network for medical images, using a labelled multi-institution dataset from prostate cancer patients with eight regions of interest. We propose an image alignment module registering the predicted segmentation of both query and support data, in a standard prototypical learning algorithm, to a reference atlas space. The built-in registration mechanism can effectively utilise the prior knowledge of consistent anatomy between subjects, regardless whether they are from the same institution or not. Experimental results demonstrated that the proposed registration-assisted prototypical learning significantly improved segmentation accuracy (p-values<0.01) on query data from a holdout institution, with varying availability of support data from multiple institutions. We also report the additional benefits of the proposed 3D networks with 75% fewer parameters and an arguably simpler implementation, compared with existing 2D few-shot approaches that segment 2D slices of volumetric medical images.
Few-shot Semantic Segmentation with Self-supervision from Pseudo-classes
Oct 22, 2021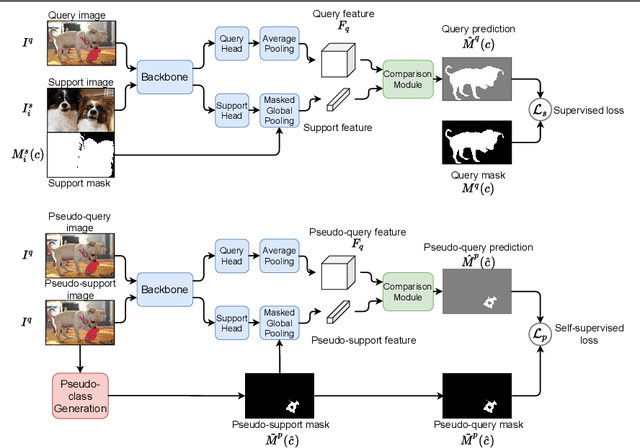
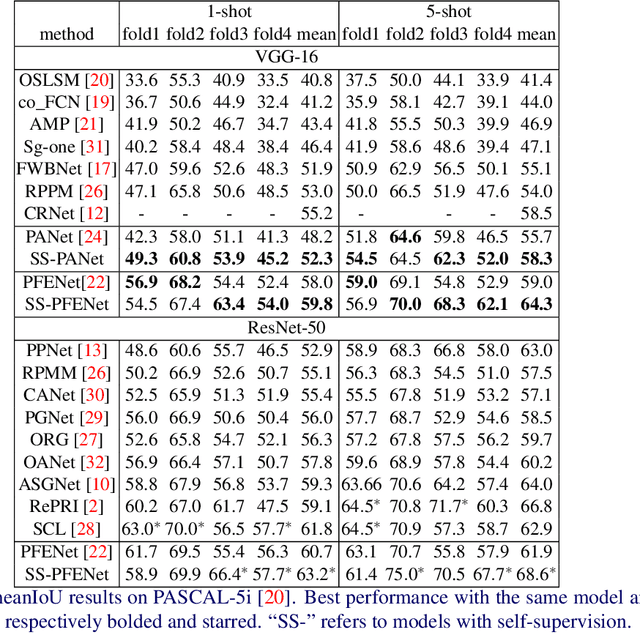

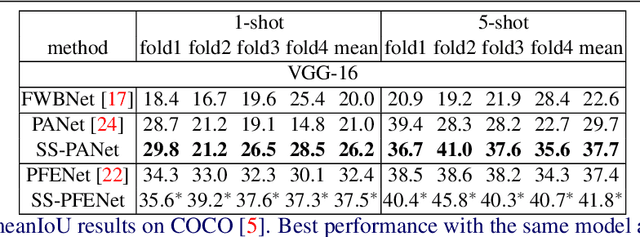
Despite the success of deep learning methods for semantic segmentation, few-shot semantic segmentation remains a challenging task due to the limited training data and the generalisation requirement for unseen classes. While recent progress has been particularly encouraging, we discover that existing methods tend to have poor performance in terms of meanIoU when query images contain other semantic classes besides the target class. To address this issue, we propose a novel self-supervised task that generates random pseudo-classes in the background of the query images, providing extra training data that would otherwise be unavailable when predicting individual target classes. To that end, we adopted superpixel segmentation for generating the pseudo-classes. With this extra supervision, we improved the meanIoU performance of the state-of-the-art method by 2.5% and 5.1% on the one-shot tasks, as well as 6.7% and 4.4% on the five-shot tasks, on the PASCAL-5i and COCO benchmarks, respectively.
Ray-ONet: Efficient 3D Reconstruction From A Single RGB Image
Jul 05, 2021
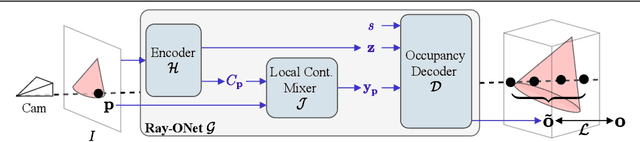

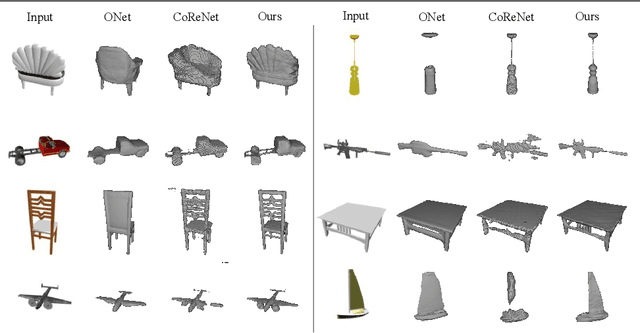
We propose Ray-ONet to reconstruct detailed 3D models from monocular images efficiently. By predicting a series of occupancy probabilities along a ray that is back-projected from a pixel in the camera coordinate, our method Ray-ONet improves the reconstruction accuracy in comparison with Occupancy Networks (ONet), while reducing the network inference complexity to O($N^2$). As a result, Ray-ONet achieves state-of-the-art performance on the ShapeNet benchmark with more than 20$\times$ speed-up at $128^3$ resolution and maintains a similar memory footprint during inference.
LaLaLoc: Latent Layout Localisation in Dynamic, Unvisited Environments
Apr 19, 2021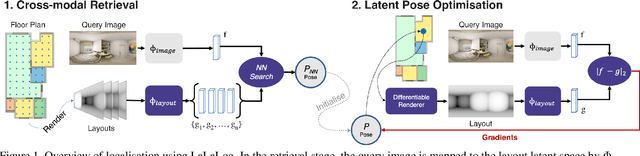
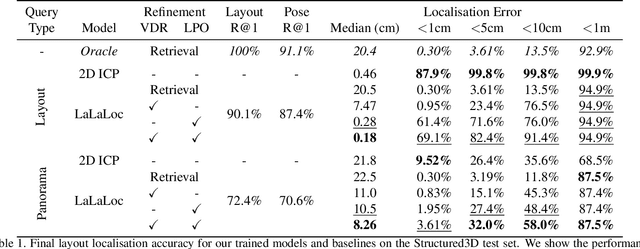
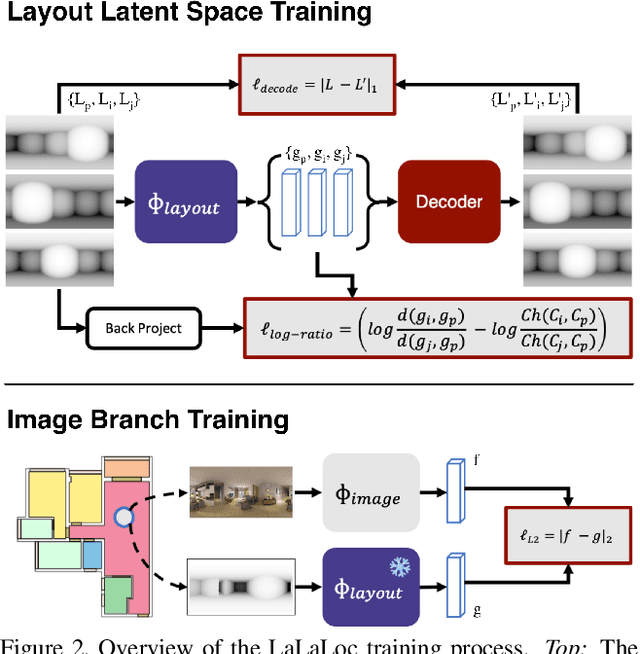
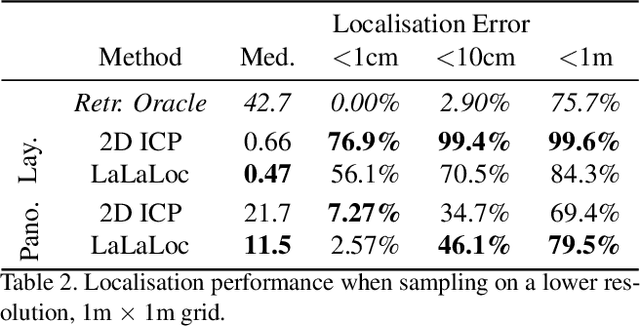
We present LaLaLoc to localise in environments without the need for prior visitation, and in a manner that is robust to large changes in scene appearance, such as a full rearrangement of furniture. Specifically, LaLaLoc performs localisation through latent representations of room layout. LaLaLoc learns a rich embedding space shared between RGB panoramas and layouts inferred from a known floor plan that encodes the structural similarity between locations. Further, LaLaLoc introduces direct, cross-modal pose optimisation in its latent space. Thus, LaLaLoc enables fine-grained pose estimation in a scene without the need for prior visitation, as well as being robust to dynamics, such as a change in furniture configuration. We show that in a domestic environment LaLaLoc is able to accurately localise a single RGB panorama image to within 8.3cm, given only a floor plan as a prior.
NeRF--: Neural Radiance Fields Without Known Camera Parameters
Feb 19, 2021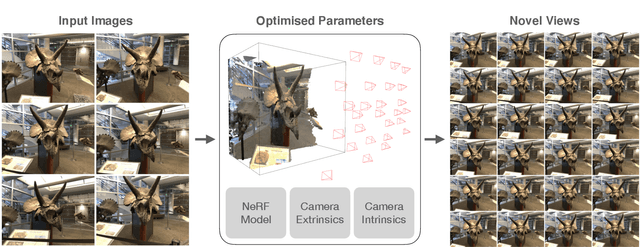
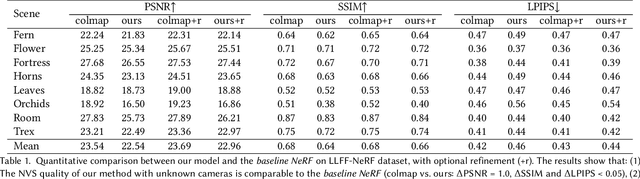
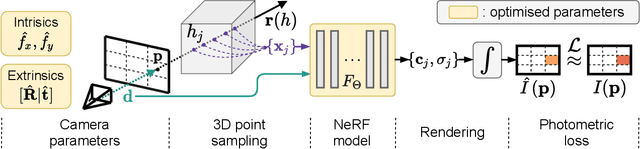
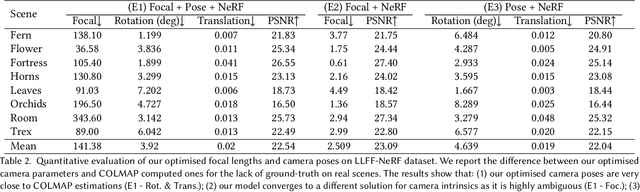
This paper tackles the problem of novel view synthesis (NVS) from 2D images without known camera poses and intrinsics. Among various NVS techniques, Neural Radiance Field (NeRF) has recently gained popularity due to its remarkable synthesis quality. Existing NeRF-based approaches assume that the camera parameters associated with each input image are either directly accessible at training, or can be accurately estimated with conventional techniques based on correspondences, such as Structure-from-Motion. In this work, we propose an end-to-end framework, termed NeRF--, for training NeRF models given only RGB images, without pre-computed camera parameters. Specifically, we show that the camera parameters, including both intrinsics and extrinsics, can be automatically discovered via joint optimisation during the training of the NeRF model. On the standard LLFF benchmark, our model achieves comparable novel view synthesis results compared to the baseline trained with COLMAP pre-computed camera parameters. We also conduct extensive analyses to understand the model behaviour under different camera trajectories, and show that in scenarios where COLMAP fails, our model still produces robust results.
Towards Generalising Neural Implicit Representations
Jan 29, 2021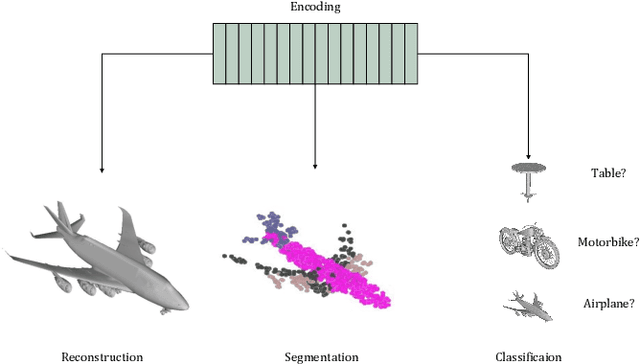
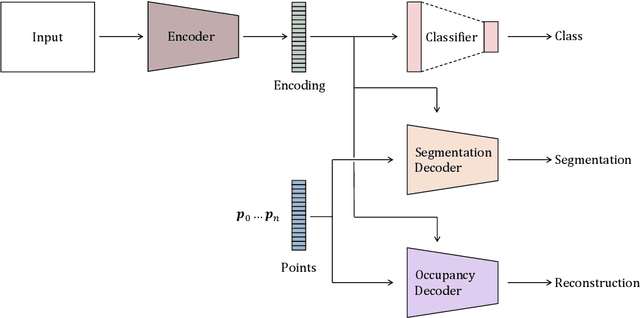
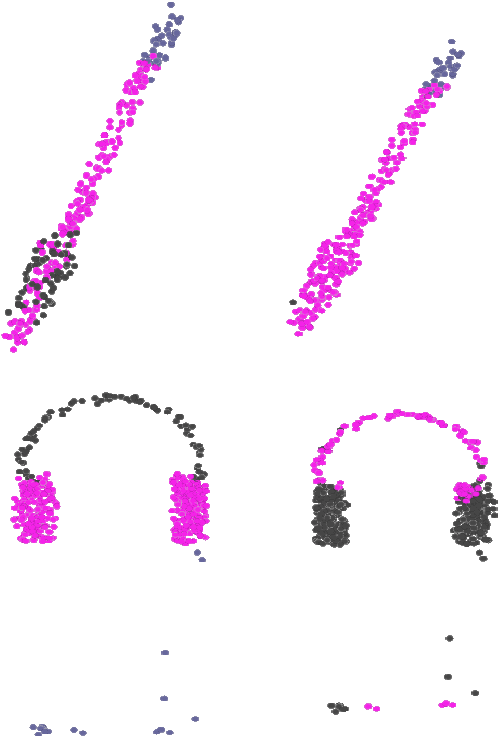
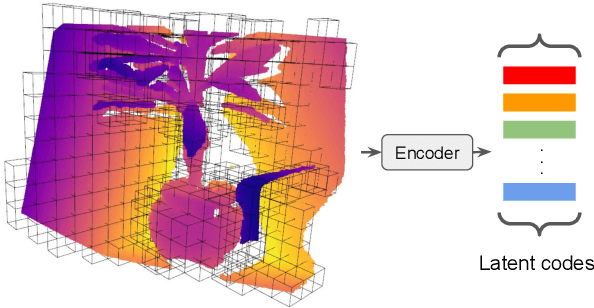
Neural implicit representations have shown substantial improvements in efficiently storing 3D data, when compared to conventional formats. However, the focus of existing work has mainly been on storage and subsequent reconstruction. In this work, we argue that training neural representations for both reconstruction tasks, alongside conventional tasks, can produce more general encodings that admit equal quality reconstructions to single task training, whilst providing improved results on conventional tasks when compared to single task encodings. Through multi-task experiments on reconstruction, classification, and segmentation our approach learns feature rich encodings that produce high quality results for each task. We also reformulate the segmentation task, creating a more representative challenge for implicit representation contexts.
Neighbourhood-Insensitive Point Cloud Normal Estimation Network
Aug 25, 2020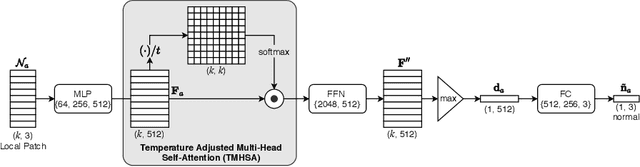
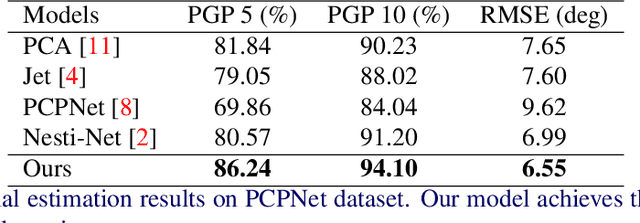
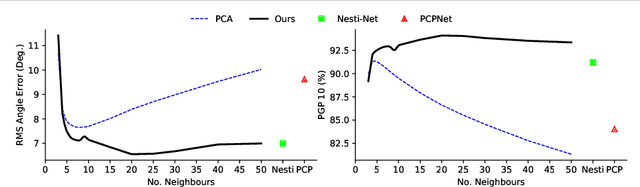
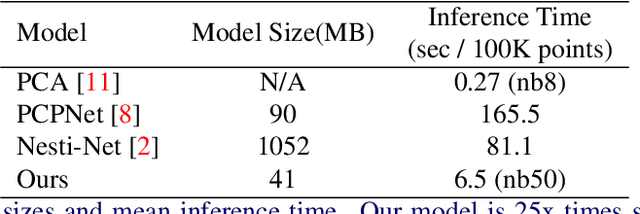
We introduce a novel self-attention-based normal estimation network that is able to focus softly on relevant points and adjust the softness by learning a temperature parameter, making it able to work naturally and effectively within a large neighbourhood range. As a result, our model outperforms all existing normal estimation algorithms by a large margin, achieving 94.1% accuracy in comparison with the previous state of the art of 91.2%, with a 25x smaller model and 12x faster inference time. We also use point-to-plane Iterative Closest Point (ICP) as an application case to show that our normal estimations lead to faster convergence than normal estimations from other methods, without manually fine-tuning neighbourhood range parameters. Code available at https://code.active.vision.