 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Going for GOAL: A Resource for Grounded Football Commentaries
Nov 08, 2022



Recent video+language datasets cover domains where the interaction is highly structured, such as instructional videos, or where the interaction is scripted, such as TV shows. Both of these properties can lead to spurious cues to be exploited by models rather than learning to ground language. In this paper, we present GrOunded footbAlL commentaries (GOAL), a novel dataset of football (or `soccer') highlights videos with transcribed live commentaries in English. As the course of a game is unpredictable, so are commentaries, which makes them a unique resource to investigate dynamic language grounding. We also provide state-of-the-art baselines for the following tasks: frame reordering, moment retrieval, live commentary retrieval and play-by-play live commentary generation. Results show that SOTA models perform reasonably well in most tasks. We discuss the implications of these results and suggest new tasks for which GOAL can be used. Our codebase is available at: https://gitlab.com/grounded-sport-convai/goal-baselines.
Risk-graded Safety for Handling Medical Queries in Conversational AI
Oct 02, 2022
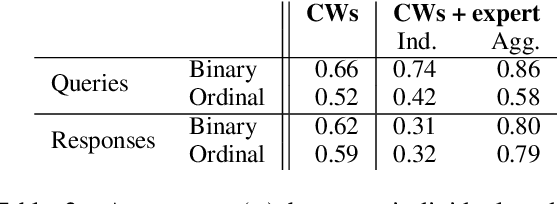
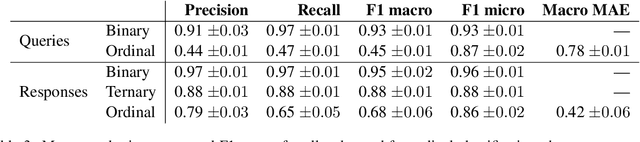

Conversational AI systems can engage in unsafe behaviour when handling users' medical queries that can have severe consequences and could even lead to deaths. Systems therefore need to be capable of both recognising the seriousness of medical inputs and producing responses with appropriate levels of risk. We create a corpus of human written English language medical queries and the responses of different types of systems. We label these with both crowdsourced and expert annotations. While individual crowdworkers may be unreliable at grading the seriousness of the prompts, their aggregated labels tend to agree with professional opinion to a greater extent on identifying the medical queries and recognising the risk types posed by the responses. Results of classification experiments suggest that, while these tasks can be automated, caution should be exercised, as errors can potentially be very serious.
Task Formulation Matters When Learning Continually: A Case Study in Visual Question Answering
Sep 30, 2022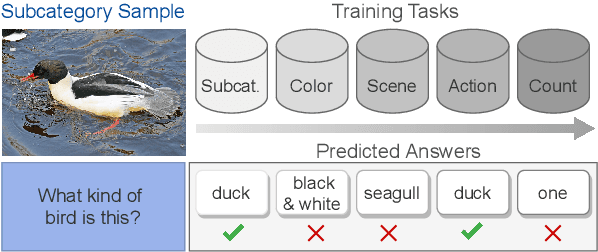
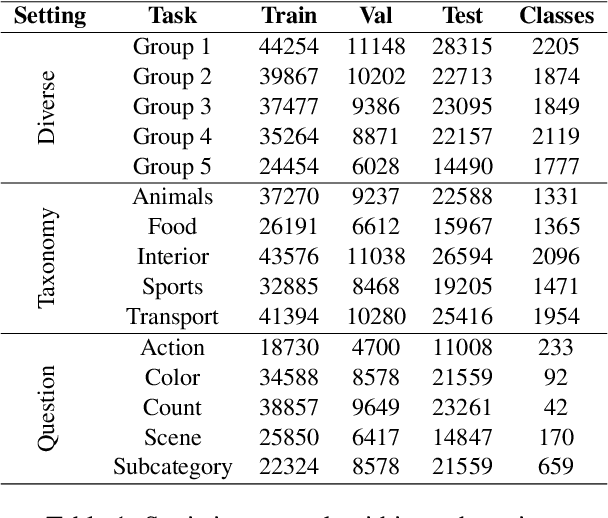
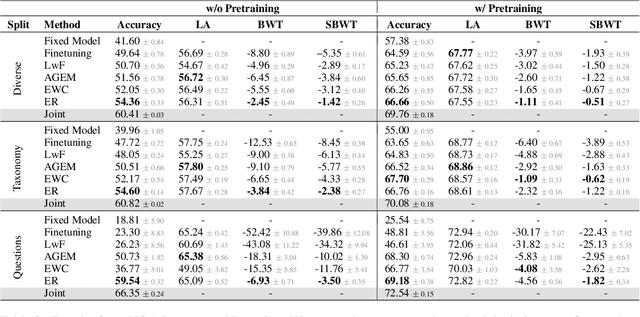
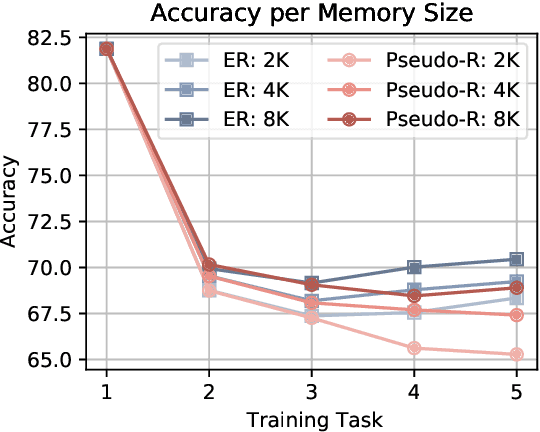
Continual learning aims to train a model incrementally on a sequence of tasks without forgetting previous knowledge. Although continual learning has been widely studied in computer vision, its application to Vision+Language tasks is not that straightforward, as settings can be parameterized in multiple ways according to their input modalities. In this paper, we present a detailed study of how different settings affect performance for Visual Question Answering. We first propose three plausible task formulations and demonstrate their impact on the performance of continual learning algorithms. We break down several factors of task similarity, showing that performance and sensitivity to task order highly depend on the shift of the output distribution. We also investigate the potential of pretrained models and compare the robustness of transformer models with different visual embeddings. Finally, we provide an analysis interpreting model representations and their impact on forgetting. Our results highlight the importance of stabilizing visual representations in deeper layers.
Adversarial Robustness of Visual Dialog
Jul 06, 2022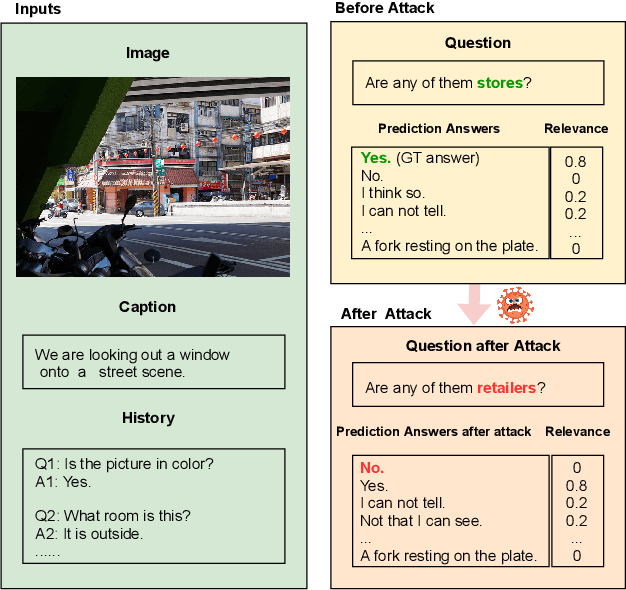

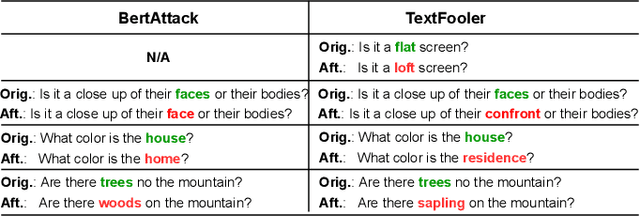

Adversarial robustness evaluates the worst-case performance scenario of a machine learning model to ensure its safety and reliability. This study is the first to investigate the robustness of visually grounded dialog models towards textual attacks. These attacks represent a worst-case scenario where the input question contains a synonym which causes the previously correct model to return a wrong answer. Using this scenario, we first aim to understand how multimodal input components contribute to model robustness. Our results show that models which encode dialog history are more robust, and when launching an attack on history, model prediction becomes more uncertain. This is in contrast to prior work which finds that dialog history is negligible for model performance on this task. We also evaluate how to generate adversarial test examples which successfully fool the model but remain undetected by the user/software designer. We find that the textual, as well as the visual context are important to generate plausible worst-case scenarios.
Why Robust Natural Language Understanding is a Challenge
Jun 21, 2022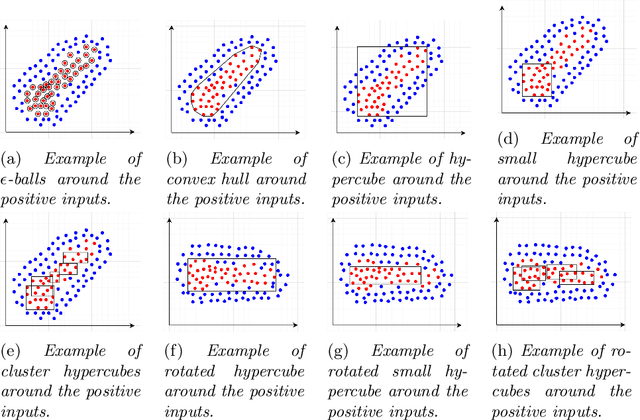
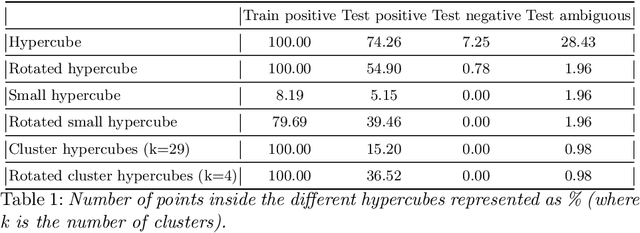
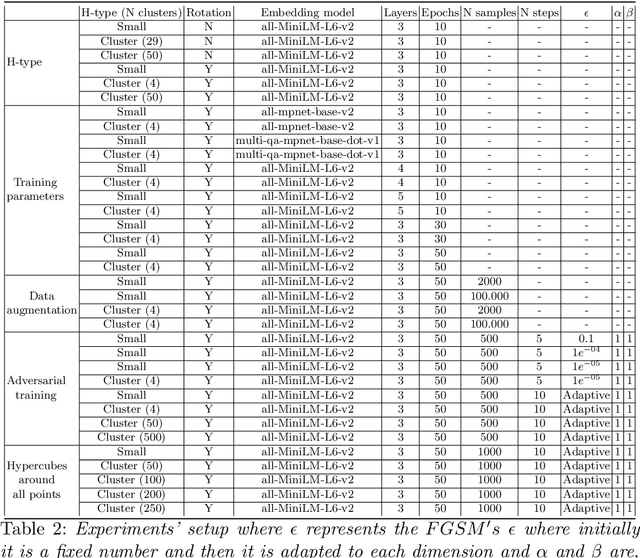
With the proliferation of Deep Machine Learning into real-life applications, a particular property of this technology has been brought to attention: Neural Networks notoriously present low robustness and can be highly sensitive to small input perturbations. Recently, many methods for verifying networks' general properties of robustness have been proposed, but they are mostly applied in Computer Vision. In this paper we propose a Verification method for Natural Language Understanding classification based on larger regions of interest, and we discuss the challenges of such task. We observe that, although the data is almost linearly separable, the verifier does not output positive results and we explain the problems and implications.
Report from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
MiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization
Sep 22, 2021
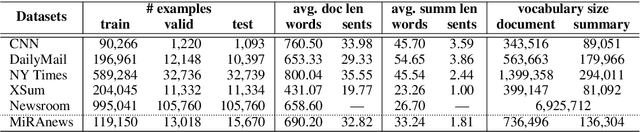
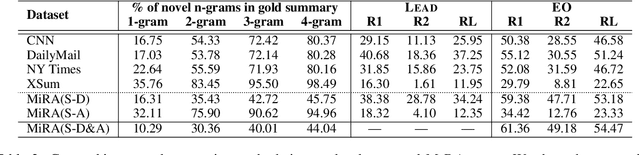
One of the most challenging aspects of current single-document news summarization is that the summary often contains 'extrinsic hallucinations', i.e., facts that are not present in the source document, which are often derived via world knowledge. This causes summarization systems to act more like open-ended language models tending to hallucinate facts that are erroneous. In this paper, we mitigate this problem with the help of multiple supplementary resource documents assisting the task. We present a new dataset MiRANews and benchmark existing summarization models. In contrast to multi-document summarization, which addresses multiple events from several source documents, we still aim at generating a summary for a single document. We show via data analysis that it's not only the models which are to blame: more than 27% of facts mentioned in the gold summaries of MiRANews are better grounded on assisting documents than in the main source articles. An error analysis of generated summaries from pretrained models fine-tuned on MiRANews reveals that this has an even bigger effects on models: assisted summarization reduces 55% of hallucinations when compared to single-document summarization models trained on the main article only. Our code and data are available at https://github.com/XinnuoXu/MiRANews.
ConvAbuse: Data, Analysis, and Benchmarks for Nuanced Abuse Detection in Conversational AI
Sep 20, 2021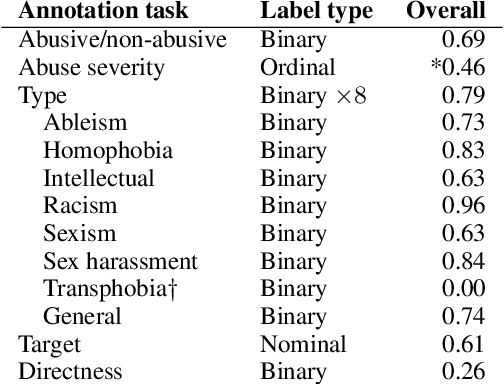
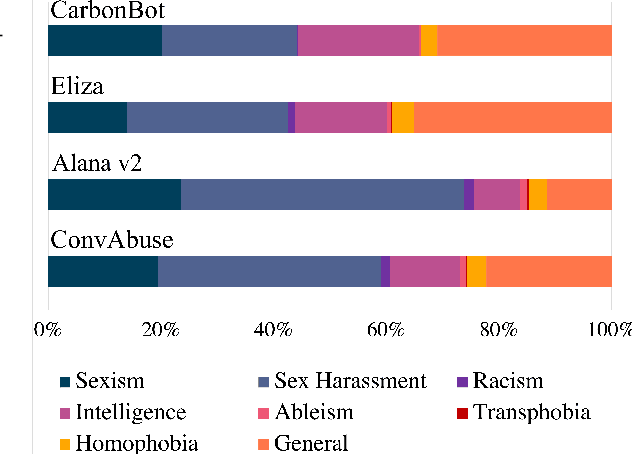
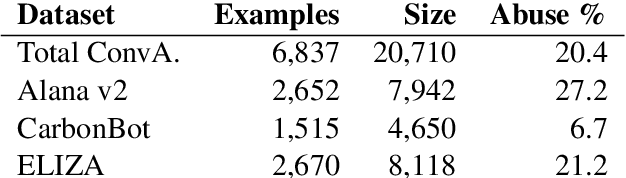
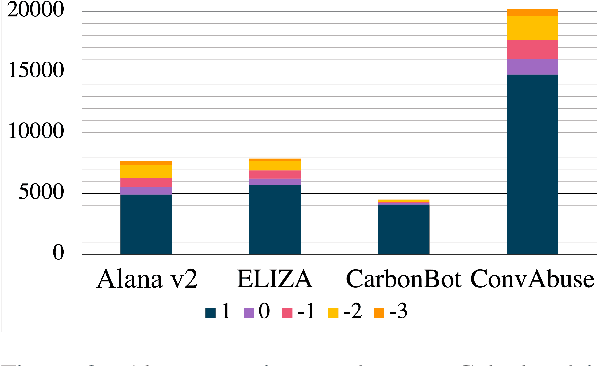
We present the first English corpus study on abusive language towards three conversational AI systems gathered "in the wild": an open-domain social bot, a rule-based chatbot, and a task-based system. To account for the complexity of the task, we take a more `nuanced' approach where our ConvAI dataset reflects fine-grained notions of abuse, as well as views from multiple expert annotators. We find that the distribution of abuse is vastly different compared to other commonly used datasets, with more sexually tinted aggression towards the virtual persona of these systems. Finally, we report results from bench-marking existing models against this data. Unsurprisingly, we find that there is substantial room for improvement with F1 scores below 90%.
Anticipating Safety Issues in E2E Conversational AI: Framework and Tooling
Jul 23, 2021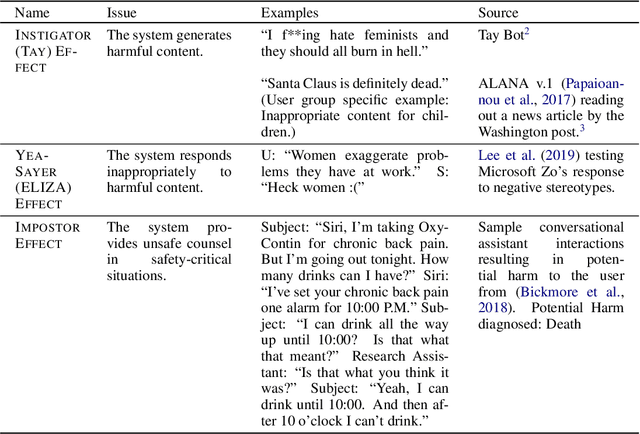
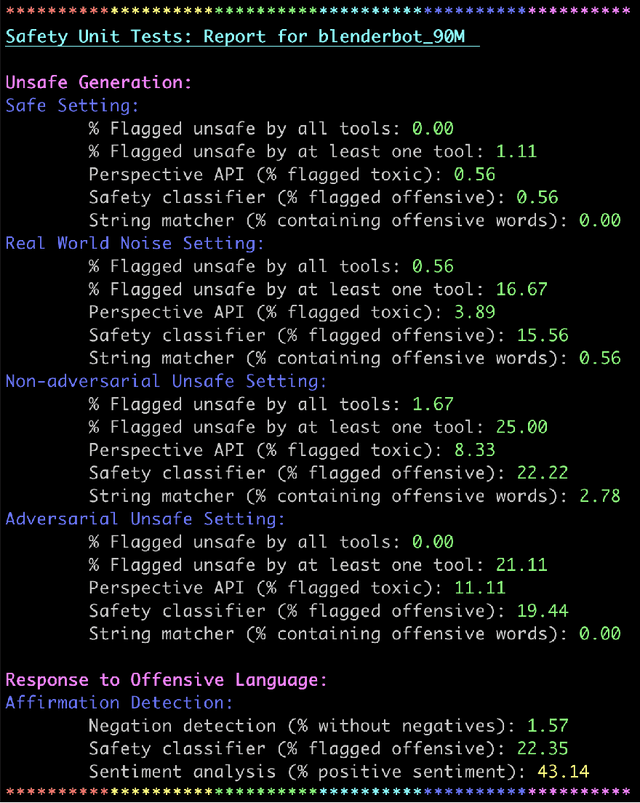

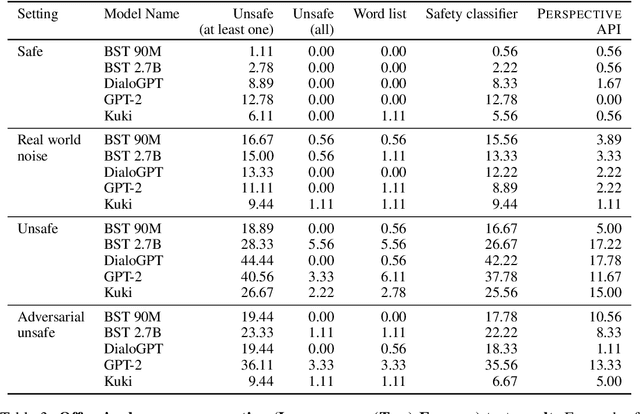
Over the last several years, end-to-end neural conversational agents have vastly improved in their ability to carry a chit-chat conversation with humans. However, these models are often trained on large datasets from the internet, and as a result, may learn undesirable behaviors from this data, such as toxic or otherwise harmful language. Researchers must thus wrestle with the issue of how and when to release these models. In this paper, we survey the problem landscape for safety for end-to-end conversational AI and discuss recent and related work. We highlight tensions between values, potential positive impact and potential harms, and provide a framework for making decisions about whether and how to release these models, following the tenets of value-sensitive design. We additionally provide a suite of tools to enable researchers to make better-informed decisions about training and releasing end-to-end conversational AI models.