 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing for GOAL: A Resource for Grounded Football Commentaries
Nov 08, 2022



Recent video+language datasets cover domains where the interaction is highly structured, such as instructional videos, or where the interaction is scripted, such as TV shows. Both of these properties can lead to spurious cues to be exploited by models rather than learning to ground language. In this paper, we present GrOunded footbAlL commentaries (GOAL), a novel dataset of football (or `soccer') highlights videos with transcribed live commentaries in English. As the course of a game is unpredictable, so are commentaries, which makes them a unique resource to investigate dynamic language grounding. We also provide state-of-the-art baselines for the following tasks: frame reordering, moment retrieval, live commentary retrieval and play-by-play live commentary generation. Results show that SOTA models perform reasonably well in most tasks. We discuss the implications of these results and suggest new tasks for which GOAL can be used. Our codebase is available at: https://gitlab.com/grounded-sport-convai/goal-baselines.
Exploring Multi-Modal Representations for Ambiguity Detection & Coreference Resolution in the SIMMC 2.0 Challenge
Feb 25, 2022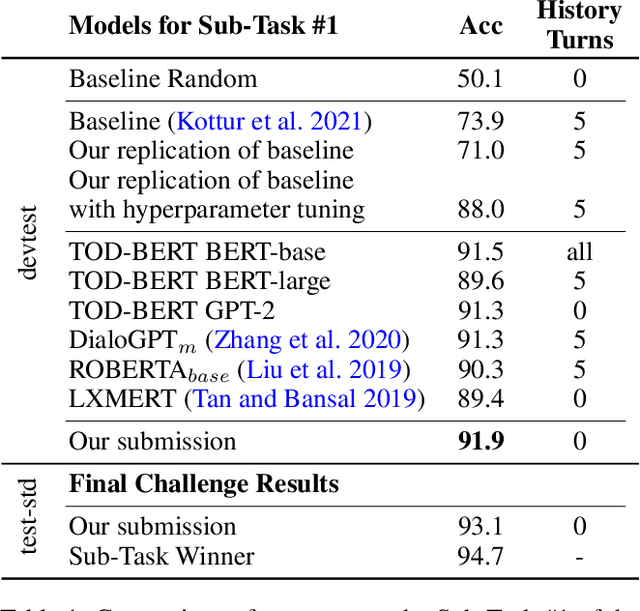
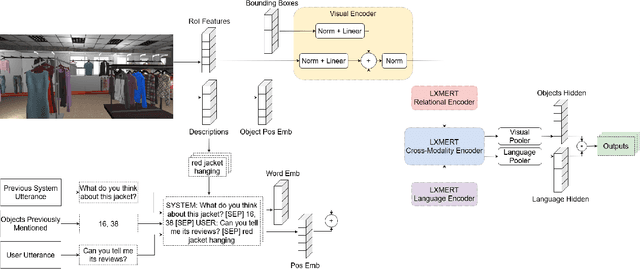
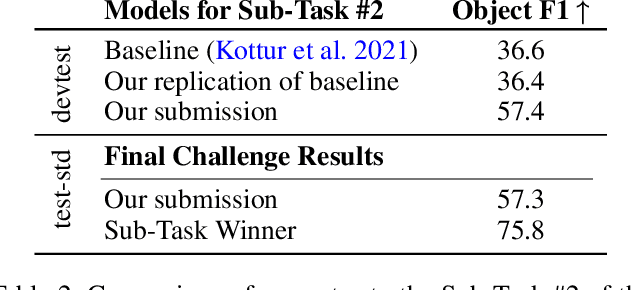
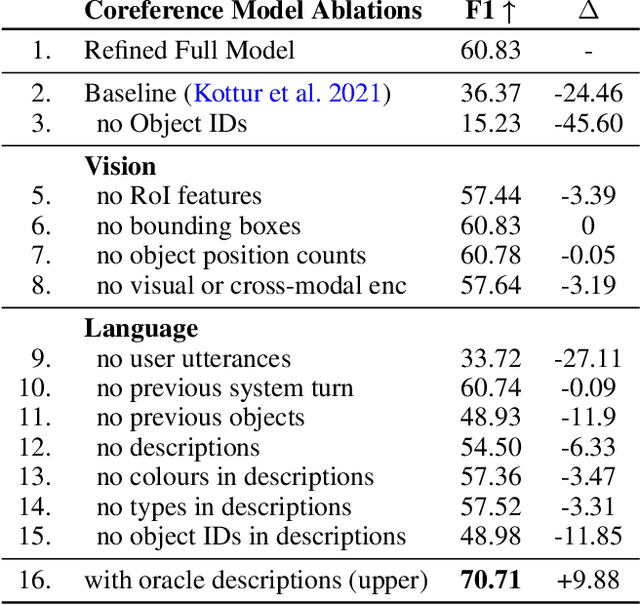
Anaphoric expressions, such as pronouns and referential descriptions, are situated with respect to the linguistic context of prior turns, as well as, the immediate visual environment. However, a speaker's referential descriptions do not always uniquely identify the referent, leading to ambiguities in need of resolution through subsequent clarificational exchanges. Thus, effective Ambiguity Detection and Coreference Resolution are key to task success in Conversational AI. In this paper, we present models for these two tasks as part of the SIMMC 2.0 Challenge (Kottur et al. 2021). Specifically, we use TOD-BERT and LXMERT based models, compare them to a number of baselines and provide ablation experiments. Our results show that (1) language models are able to exploit correlations in the data to detect ambiguity; and (2) unimodal coreference resolution models can avoid the need for a vision component, through the use of smart object representations.
Domain Adaptation in Dialogue Systems using Transfer and Meta-Learning
Feb 22, 2021
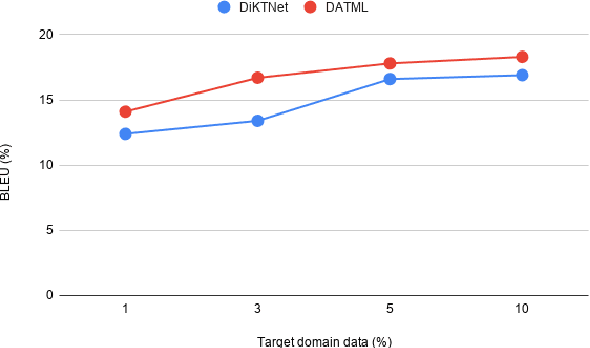
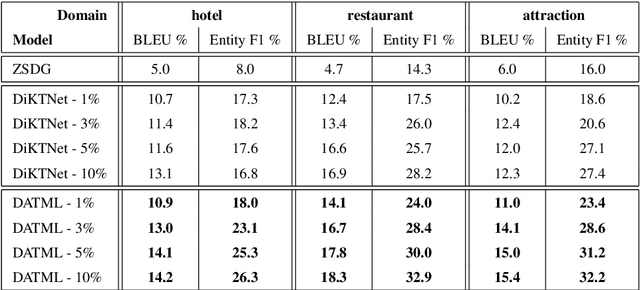
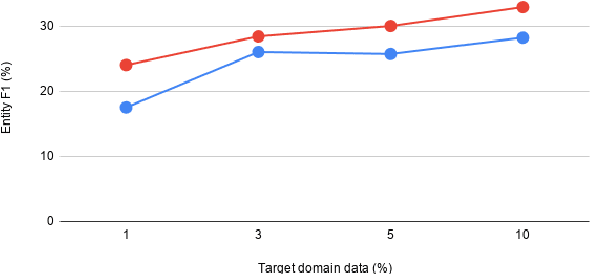
Current generative-based dialogue systems are data-hungry and fail to adapt to new unseen domains when only a small amount of target data is available. Additionally, in real-world applications, most domains are underrepresented, so there is a need to create a system capable of generalizing to these domains using minimal data. In this paper, we propose a method that adapts to unseen domains by combining both transfer and meta-learning (DATML). DATML improves the previous state-of-the-art dialogue model, DiKTNet, by introducing a different learning technique: meta-learning. We use Reptile, a first-order optimization-based meta-learning algorithm as our improved training method. We evaluated our model on the MultiWOZ dataset and outperformed DiKTNet in both BLEU and Entity F1 scores when the same amount of data is available.
The Lab vs The Crowd: An Investigation into Data Quality for Neural Dialogue Models
Dec 07, 2020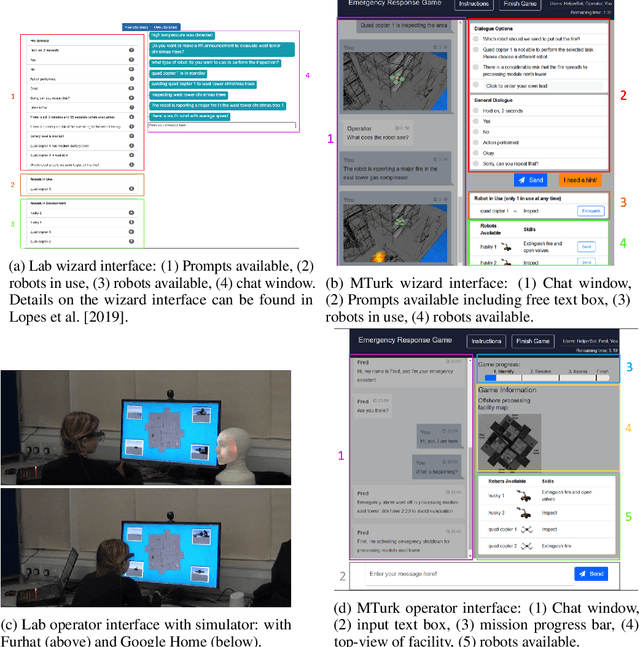
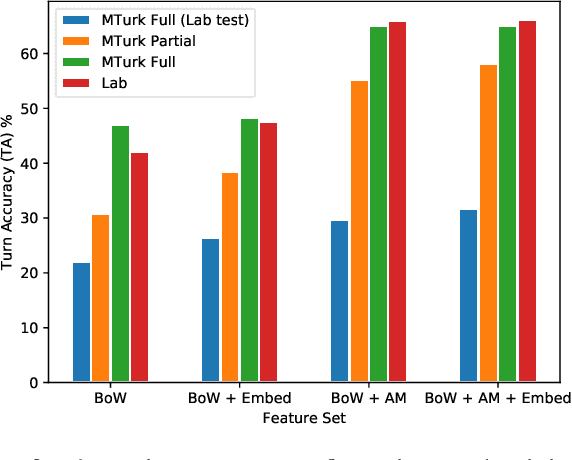
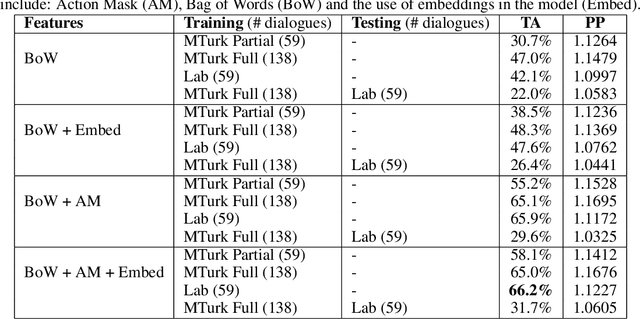

Challenges around collecting and processing quality data have hampered progress in data-driven dialogue models. Previous approaches are moving away from costly, resource-intensive lab settings, where collection is slow but where the data is deemed of high quality. The advent of crowd-sourcing platforms, such as Amazon Mechanical Turk, has provided researchers with an alternative cost-effective and rapid way to collect data. However, the collection of fluid, natural spoken or textual interaction can be challenging, particularly between two crowd-sourced workers. In this study, we compare the performance of dialogue models for the same interaction task but collected in two different settings: in the lab vs. crowd-sourced. We find that fewer lab dialogues are needed to reach similar accuracy, less than half the amount of lab data as crowd-sourced data. We discuss the advantages and disadvantages of each data collection method.
CRWIZ: A Framework for Crowdsourcing Real-Time Wizard-of-Oz Dialogues
Mar 12, 2020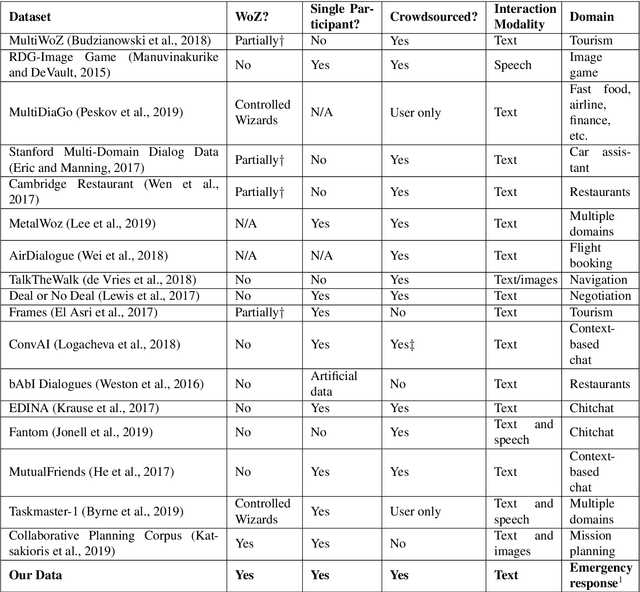
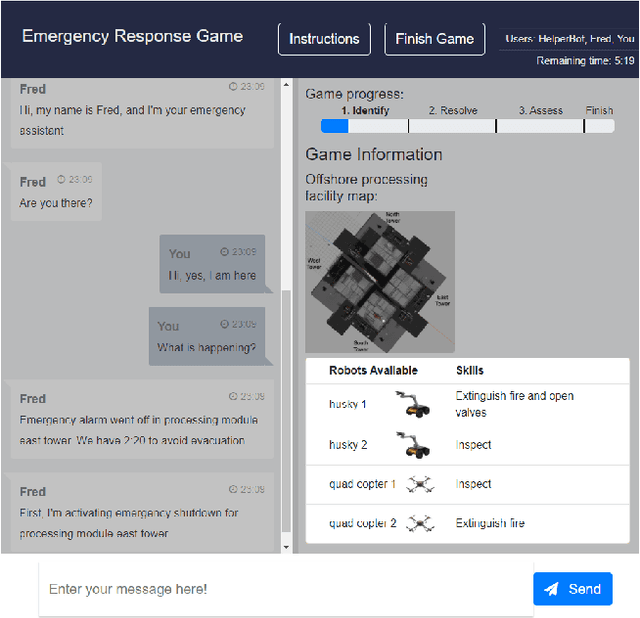
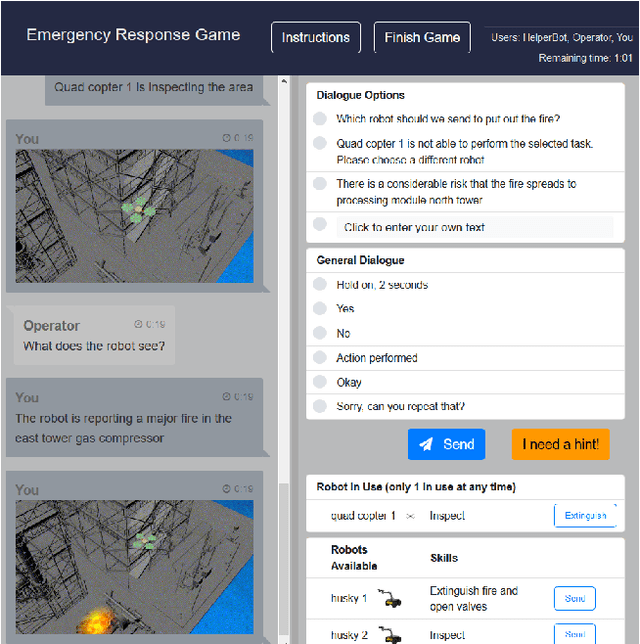
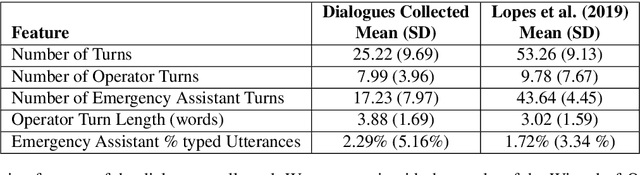
Large corpora of task-based and open-domain conversational dialogues are hugely valuable in the field of data-driven dialogue systems. Crowdsourcing platforms, such as Amazon Mechanical Turk, have been an effective method for collecting such large amounts of data. However, difficulties arise when task-based dialogues require expert domain knowledge or rapid access to domain-relevant information, such as databases for tourism. This will become even more prevalent as dialogue systems become increasingly ambitious, expanding into tasks with high levels of complexity that require collaboration and forward planning, such as in our domain of emergency response. In this paper, we propose CRWIZ: a framework for collecting real-time Wizard of Oz dialogues through crowdsourcing for collaborative, complex tasks. This framework uses semi-guided dialogue to avoid interactions that breach procedures and processes only known to experts, while enabling the capture of a wide variety of interactions. The framework is available at https://github.com/JChiyah/crwiz
Natural Language Interaction to Facilitate Mental Models of Remote Robots
Mar 12, 2020

Increasingly complex and autonomous robots are being deployed in real-world environments with far-reaching consequences. High-stakes scenarios, such as emergency response or offshore energy platform and nuclear inspections, require robot operators to have clear mental models of what the robots can and can't do. However, operators are often not the original designers of the robots and thus, they do not necessarily have such clear mental models, especially if they are novice users. This lack of mental model clarity can slow adoption and can negatively impact human-machine teaming. We propose that interaction with a conversational assistant, who acts as a mediator, can help the user with understanding the functionality of remote robots and increase transparency through natural language explanations, as well as facilitate the evaluation of operators' mental models.
Challenges in Collaborative HRI for Remote Robot Teams
May 17, 2019


Collaboration between human supervisors and remote teams of robots is highly challenging, particularly in high-stakes, distant, hazardous locations, such as off-shore energy platforms. In order for these teams of robots to truly be beneficial, they need to be trusted to operate autonomously, performing tasks such as inspection and emergency response, thus reducing the number of personnel placed in harm's way. As remote robots are generally trusted less than robots in close-proximity, we present a solution to instil trust in the operator through a `mediator robot' that can exhibit social skills, alongside sophisticated visualisation techniques. In this position paper, we present general challenges and then take a closer look at one challenge in particular, discussing an initial study, which investigates the relationship between the level of control the supervisor hands over to the mediator robot and how this affects their trust. We show that the supervisor is more likely to have higher trust overall if their initial experience involves handing over control of the emergency situation to the robotic assistant. We discuss this result, here, as well as other challenges and interaction techniques for human-robot collaboration.
The Spot the Difference corpus: a multi-modal corpus of spontaneous task oriented spoken interactions
May 14, 2018
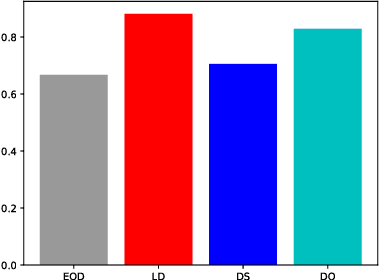
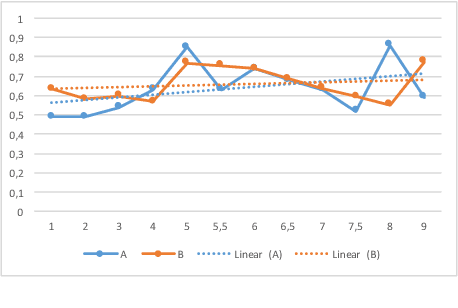
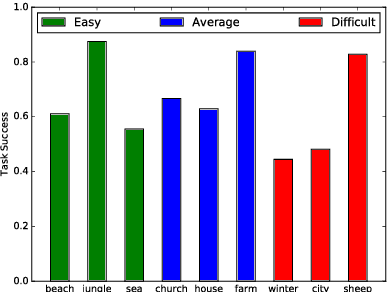
This paper describes the Spot the Difference Corpus which contains 54 interactions between pairs of subjects interacting to find differences in two very similar scenes. The setup used, the participants' metadata and details about collection are described. We are releasing this corpus of task-oriented spontaneous dialogues. This release includes rich transcriptions, annotations, audio and video. We believe that this dataset constitutes a valuable resource to study several dimensions of human communication that go from turn-taking to the study of referring expressions. In our preliminary analyses we have looked at task success (how many differences were found out of the total number of differences) and how it evolves over time. In addition we have looked at scene complexity provided by the RGB components' entropy and how it could relate to speech overlaps, interruptions and the expression of uncertainty. We found there is a tendency that more complex scenes have more competitive interruptions.
Assessing User Expertise in Spoken Dialog System Interactions
Jan 18, 2017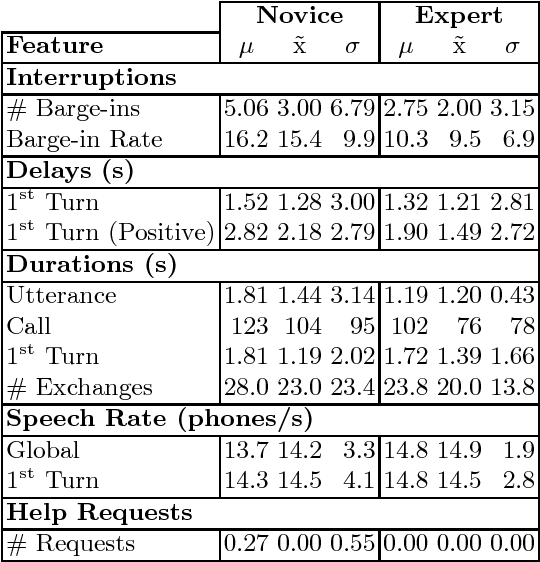
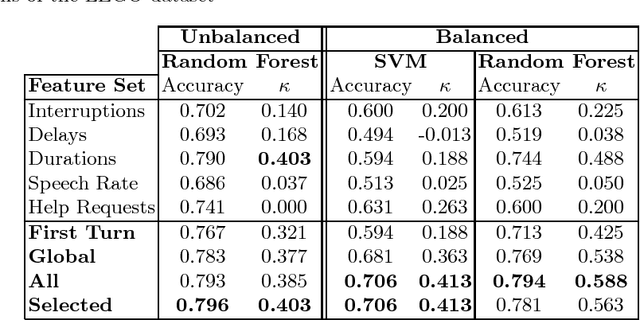
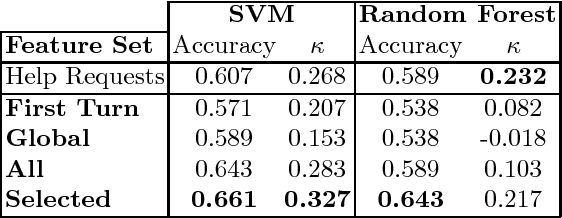
Identifying the level of expertise of its users is important for a system since it can lead to a better interaction through adaptation techniques. Furthermore, this information can be used in offline processes of root cause analysis. However, not much effort has been put into automatically identifying the level of expertise of an user, especially in dialog-based interactions. In this paper we present an approach based on a specific set of task related features. Based on the distribution of the features among the two classes - Novice and Expert - we used Random Forests as a classification approach. Furthermore, we used a Support Vector Machine classifier, in order to perform a result comparison. By applying these approaches on data from a real system, Let's Go, we obtained preliminary results that we consider positive, given the difficulty of the task and the lack of competing approaches for comparison.
* 10 pages