 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep sprite-based image models: An analysis
Apr 21, 2026While foundation models drive steady progress in image segmentation and diffusion algorithms compose always more realistic images, the seemingly simple problem of identifying recurrent patterns in a collection of images remains very much open. In this paper, we focus on sprite-based image decomposition models, which have shown some promise for clustering and image decomposition and are appealing because of their high interpretability. These models come in different flavors, need to be tailored to specific datasets, and struggle to scale to images with many objects. We dive into the details of their design, identify their core components, and perform an extensive analysis on clustering benchmarks. We leverage this analysis to propose a deep sprite-based image decomposition method that performs on par with state-of-the-art unsupervised class-aware image segmentation methods on the standard CLEVR benchmark, scales linearly with the number of objects, identifies explicitly object categories, and fully models images in an easily interpretable way.
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024



Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
Learnable Earth Parser: Discovering 3D Prototypes in Aerial Scans
Apr 19, 2023



We propose an unsupervised method for parsing large 3D scans of real-world scenes into interpretable parts. Our goal is to provide a practical tool for analyzing 3D scenes with unique characteristics in the context of aerial surveying and mapping, without relying on application-specific user annotations. Our approach is based on a probabilistic reconstruction model that decomposes an input 3D point cloud into a small set of learned prototypical shapes. Our model provides an interpretable reconstruction of complex scenes and leads to relevant instance and semantic segmentations. To demonstrate the usefulness of our results, we introduce a novel dataset of seven diverse aerial LiDAR scans. We show that our method outperforms state-of-the-art unsupervised methods in terms of decomposition accuracy while remaining visually interpretable. Our method offers significant advantage over existing approaches, as it does not require any manual annotations, making it a practical and efficient tool for 3D scene analysis. Our code and dataset are available at https://imagine.enpc.fr/~loiseaur/learnable-earth-parser
A Model You Can Hear: Audio Identification with Playable Prototypes
Aug 05, 2022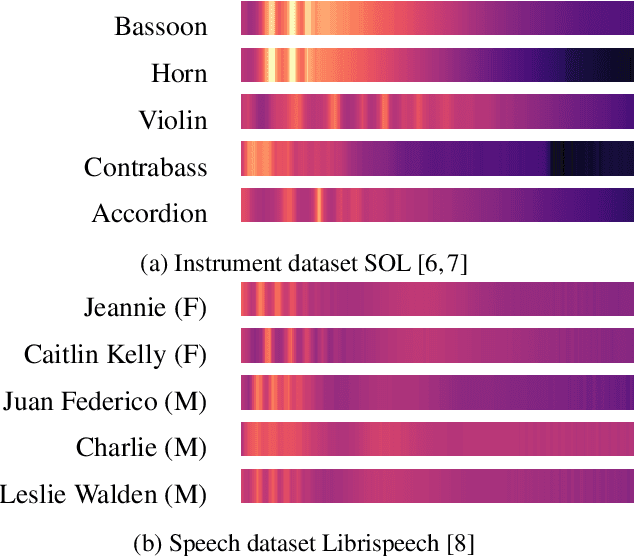
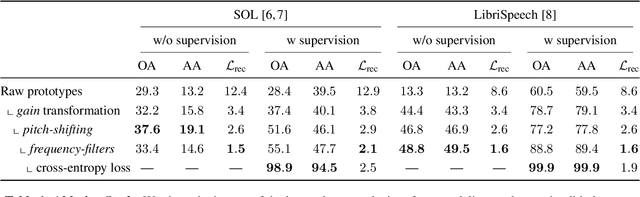
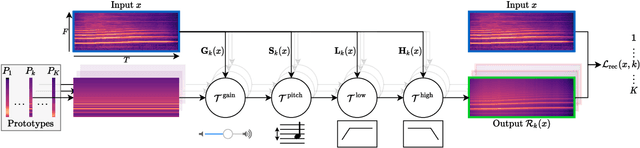
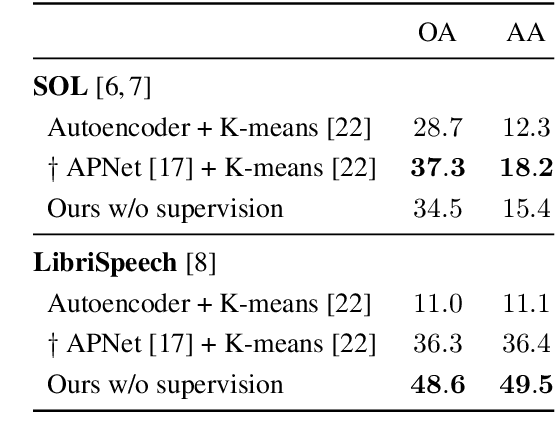
Machine learning techniques have proved useful for classifying and analyzing audio content. However, recent methods typically rely on abstract and high-dimensional representations that are difficult to interpret. Inspired by transformation-invariant approaches developed for image and 3D data, we propose an audio identification model based on learnable spectral prototypes. Equipped with dedicated transformation networks, these prototypes can be used to cluster and classify input audio samples from large collections of sounds. Our model can be trained with or without supervision and reaches state-of-the-art results for speaker and instrument identification, while remaining easily interpretable. The code is available at: https://github.com/romainloiseau/a-model-you-can-hear
Online Segmentation of LiDAR Sequences: Dataset and Algorithm
Jun 16, 2022
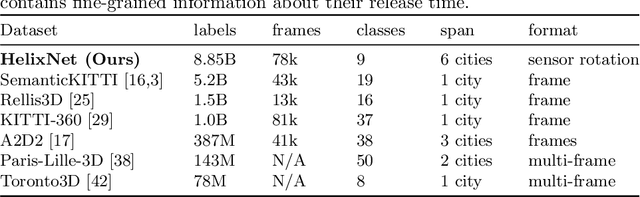
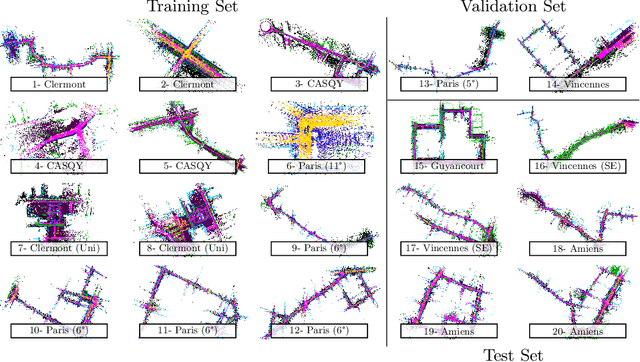
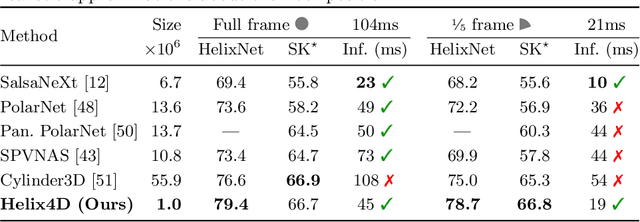
Roof-mounted spinning LiDAR sensors are widely used by autonomous vehicles, driving the need for real-time processing of 3D point sequences. However, most LiDAR semantic segmentation datasets and algorithms split these acquisitions into $360^\circ$ frames, leading to acquisition latency that is incompatible with realistic real-time applications and evaluations. We address this issue with two key contributions. First, we introduce HelixNet, a $10$ billion point dataset with fine-grained labels, timestamps, and sensor rotation information that allows an accurate assessment of real-time readiness of segmentation algorithms. Second, we propose Helix4D, a compact and efficient spatio-temporal transformer architecture specifically designed for rotating LiDAR point sequences. Helix4D operates on acquisition slices that correspond to a fraction of a full rotation of the sensor, significantly reducing the total latency. We present an extensive benchmark of the performance and real-time readiness of several state-of-the-art models on HelixNet and SemanticKITTI. Helix4D reaches accuracy on par with the best segmentation algorithms with a reduction of more than $5\times$ in terms of latency and $50\times$ in model size. Code and data are available at: https://romainloiseau.fr/helixnet
Representing Shape Collections with Alignment-Aware Linear Models
Sep 03, 2021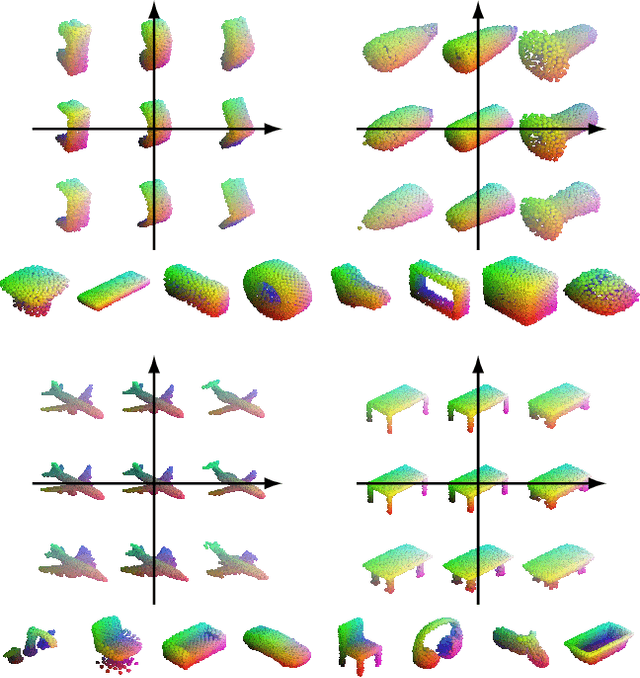
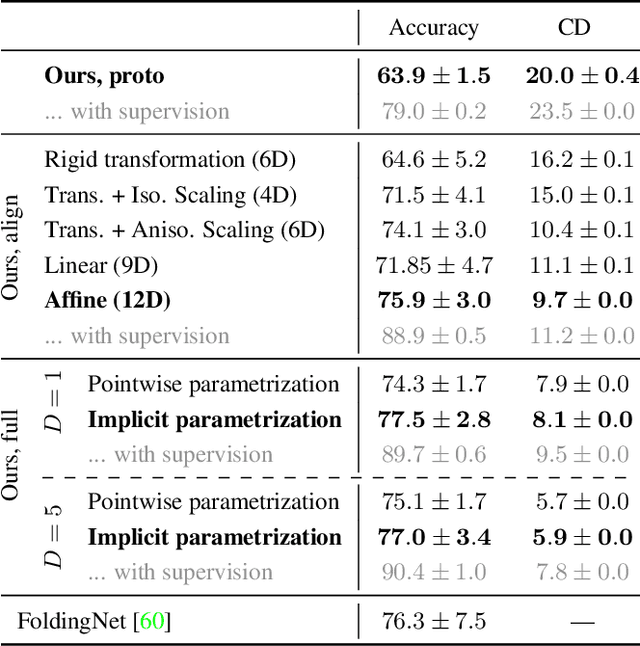
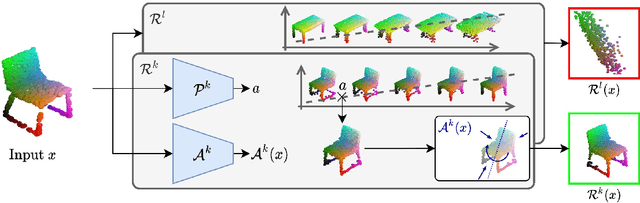

In this paper, we revisit the classical representation of 3D point clouds as linear shape models. Our key insight is to leverage deep learning to represent a collection of shapes as affine transformations of low-dimensional linear shape models. Each linear model is characterized by a shape prototype, a low-dimensional shape basis and two neural networks. The networks take as input a point cloud and predict the coordinates of a shape in the linear basis and the affine transformation which best approximate the input. Both linear models and neural networks are learned end-to-end using a single reconstruction loss. The main advantage of our approach is that, in contrast to many recent deep approaches which learn feature-based complex shape representations, our model is explicit and every operation occurs in 3D space. As a result, our linear shape models can be easily visualized and annotated, and failure cases can be visually understood. While our main goal is to introduce a compact and interpretable representation of shape collections, we show it leads to state of the art results for few-shot segmentation.