 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025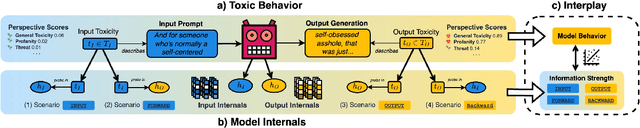

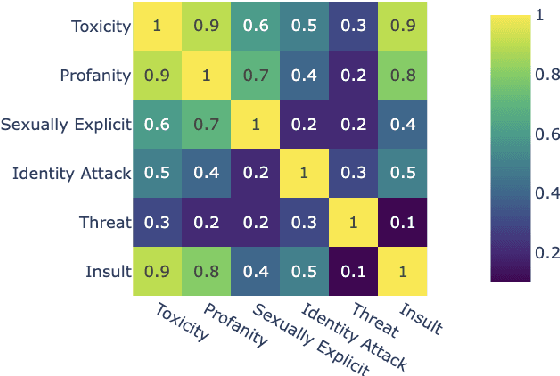
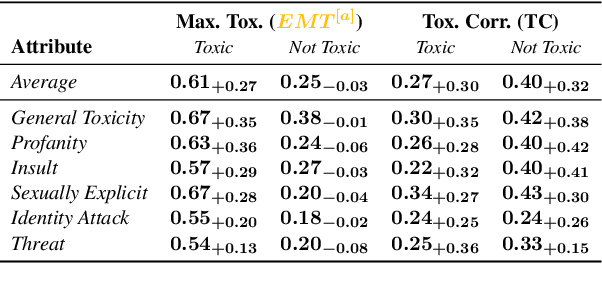
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
The Lou Dataset -- Exploring the Impact of Gender-Fair Language in German Text Classification
Sep 26, 2024



Gender-fair language, an evolving German linguistic variation, fosters inclusion by addressing all genders or using neutral forms. Nevertheless, there is a significant lack of resources to assess the impact of this linguistic shift on classification using language models (LMs), which are probably not trained on such variations. To address this gap, we present Lou, the first dataset featuring high-quality reformulations for German text classification covering seven tasks, like stance detection and toxicity classification. Evaluating 16 mono- and multi-lingual LMs on Lou shows that gender-fair language substantially impacts predictions by flipping labels, reducing certainty, and altering attention patterns. However, existing evaluations remain valid, as LM rankings of original and reformulated instances do not significantly differ. While we offer initial insights on the effect on German text classification, the findings likely apply to other languages, as consistent patterns were observed in multi-lingual and English LMs.
Overview of PerpectiveArg2024: The First Shared Task on Perspective Argument Retrieval
Jul 29, 2024



Argument retrieval is the task of finding relevant arguments for a given query. While existing approaches rely solely on the semantic alignment of queries and arguments, this first shared task on perspective argument retrieval incorporates perspectives during retrieval, accounting for latent influences in argumentation. We present a novel multilingual dataset covering demographic and socio-cultural (socio) variables, such as age, gender, and political attitude, representing minority and majority groups in society. We distinguish between three scenarios to explore how retrieval systems consider explicitly (in both query and corpus) and implicitly (only in query) formulated perspectives. This paper provides an overview of this shared task and summarizes the results of the six submitted systems. We find substantial challenges in incorporating perspectivism, especially when aiming for personalization based solely on the text of arguments without explicitly providing socio profiles. Moreover, retrieval systems tend to be biased towards the majority group but partially mitigate bias for the female gender. While we bootstrap perspective argument retrieval, further research is essential to optimize retrieval systems to facilitate personalization and reduce polarization.
Holmes: Benchmark the Linguistic Competence of Language Models
Apr 29, 2024



We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
ScamSpot: Fighting Financial Fraud in Instagram Comments
Feb 14, 2024



The long-standing problem of spam and fraudulent messages in the comment sections of Instagram pages in the financial sector claims new victims every day. Instagram's current spam filter proves inadequate, and existing research approaches are primarily confined to theoretical concepts. Practical implementations with evaluated results are missing. To solve this problem, we propose ScamSpot, a comprehensive system that includes a browser extension, a fine-tuned BERT model and a REST API. This approach ensures public accessibility of our results for Instagram users using the Chrome browser. Furthermore, we conduct a data annotation study, shedding light on the reasons and causes of the problem and evaluate the system through user feedback and comparison with existing models. ScamSpot is an open-source project and is publicly available at https://scamspot.github.io/.
Dive into the Chasm: Probing the Gap between In- and Cross-Topic Generalization
Feb 02, 2024Pre-trained language models (LMs) perform well in In-Topic setups, where training and testing data come from the same topics. However, they face challenges in Cross-Topic scenarios where testing data is derived from distinct topics -- such as Gun Control. This study analyzes various LMs with three probing-based experiments to shed light on the reasons behind the In- vs. Cross-Topic generalization gap. Thereby, we demonstrate, for the first time, that generalization gaps and the robustness of the embedding space vary significantly across LMs. Additionally, we assess larger LMs and underscore the relevance of our analysis for recent models. Overall, diverse pre-training objectives, architectural regularization, or data deduplication contribute to more robust LMs and diminish generalization gaps. Our research contributes to a deeper understanding and comparison of language models across different generalization scenarios.
Bridging Topic, Domain, and Language Shifts: An Evaluation of Comprehensive Out-of-Distribution Scenarios
Sep 15, 2023



Language models (LMs) excel in in-distribution (ID) scenarios where train and test data are independent and identically distributed. However, their performance often degrades in real-world applications like argument mining. Such degradation happens when new topics emerge, or other text domains and languages become relevant. To assess LMs' generalization abilities in such out-of-distribution (OOD) scenarios, we simulate such distribution shifts by deliberately withholding specific instances for testing, as from the social media domain or the topic Solar Energy. Unlike prior studies focusing on specific shifts and metrics in isolation, we comprehensively analyze OOD generalization. We define three metrics to pinpoint generalization flaws and propose eleven classification tasks covering topic, domain, and language shifts. Overall, we find superior performance of prompt-based fine-tuning, notably when train and test splits primarily differ semantically. Simultaneously, in-context learning is more effective than prompt-based or vanilla fine-tuning for tasks when training data embodies heavy discrepancies in label distribution compared to testing data. This reveals a crucial drawback of gradient-based learning: it biases LMs regarding such structural obstacles.
Contextual information integration for stance detection via cross-attention
Nov 03, 2022Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
Nested and Balanced Entity Recognition using Multi-Task Learning
Jun 11, 2021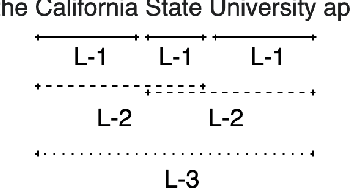
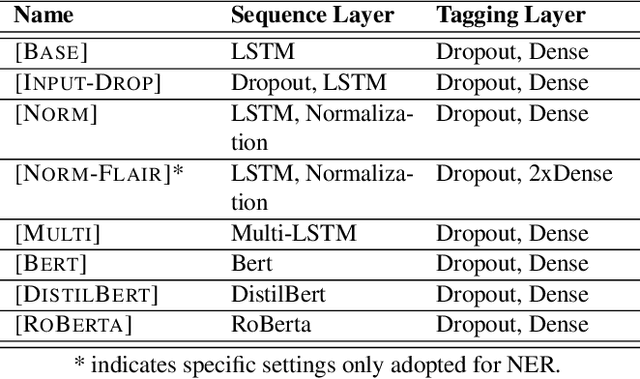
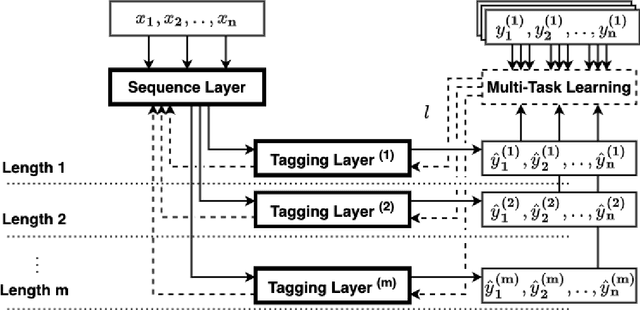
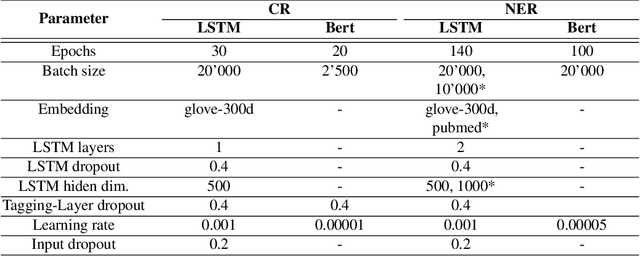
Entity Recognition (ER) within a text is a fundamental exercise in Natural Language Processing, enabling further depending tasks such as Knowledge Extraction, Text Summarisation, or Keyphrase Extraction. An entity consists of single words or of a consecutive sequence of terms, constituting the basic building blocks for communication. Mainstream ER approaches are mainly limited to flat structures, concentrating on the outermost entities while ignoring the inner ones. This paper introduces a partly-layered network architecture that deals with the complexity of overlapping and nested cases. The proposed architecture consists of two parts: (1) a shared Sequence Layer and (2) a stacked component with multiple Tagging Layers. The adoption of such an architecture has the advantage of preventing overfit to a specific word-length, thus maintaining performance for longer entities despite their lower frequency. To verify the proposed architecture's effectiveness, we train and evaluate this architecture to recognise two kinds of entities - Concepts (CR) and Named Entities (NER). Our approach achieves state-of-the-art NER performances, while it outperforms previous CR approaches. Considering these promising results, we see the possibility to evolve the architecture for other cases such as the extraction of events or the detection of argumentative components.