 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer for NeRF-Based View Synthesis from a Single Input Image
Jul 12, 2022

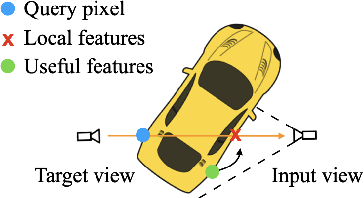
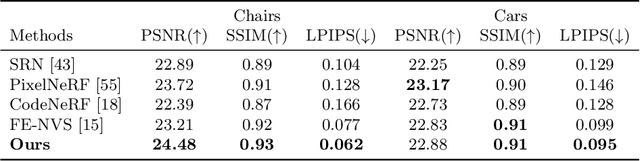
Although neural radiance fields (NeRF) have shown impressive advances for novel view synthesis, most methods typically require multiple input images of the same scene with accurate camera poses. In this work, we seek to substantially reduce the inputs to a single unposed image. Existing approaches condition on local image features to reconstruct a 3D object, but often render blurry predictions at viewpoints that are far away from the source view. To address this issue, we propose to leverage both the global and local features to form an expressive 3D representation. The global features are learned from a vision transformer, while the local features are extracted from a 2D convolutional network. To synthesize a novel view, we train a multilayer perceptron (MLP) network conditioned on the learned 3D representation to perform volume rendering. This novel 3D representation allows the network to reconstruct unseen regions without enforcing constraints like symmetry or canonical coordinate systems. Our method can render novel views from only a single input image and generalize across multiple object categories using a single model. Quantitative and qualitative evaluations demonstrate that the proposed method achieves state-of-the-art performance and renders richer details than existing approaches.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022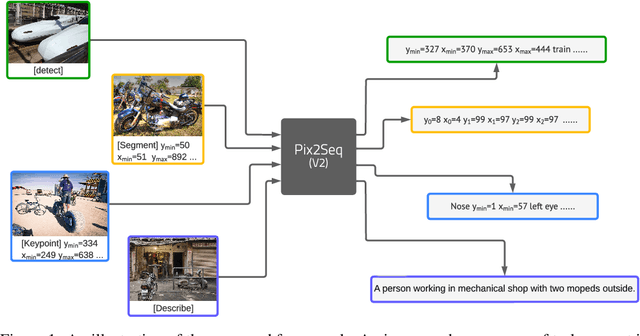
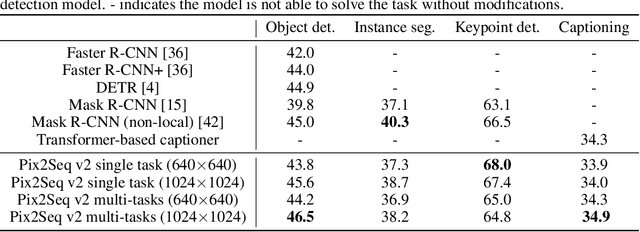
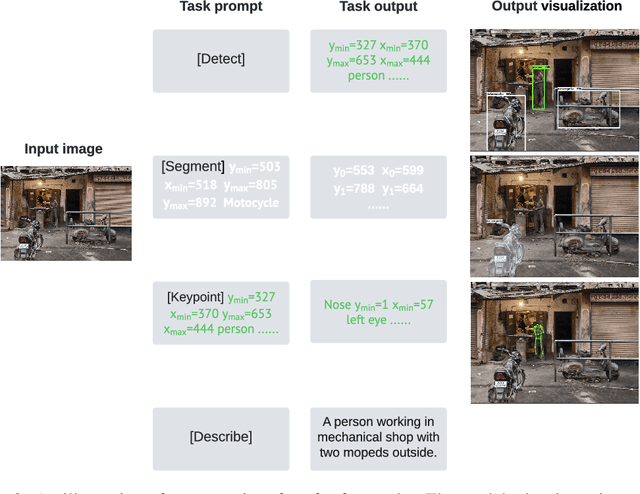

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
NeRF-Supervision: Learning Dense Object Descriptors from Neural Radiance Fields
Mar 03, 2022



Thin, reflective objects such as forks and whisks are common in our daily lives, but they are particularly challenging for robot perception because it is hard to reconstruct them using commodity RGB-D cameras or multi-view stereo techniques. While traditional pipelines struggle with objects like these, Neural Radiance Fields (NeRFs) have recently been shown to be remarkably effective for performing view synthesis on objects with thin structures or reflective materials. In this paper we explore the use of NeRF as a new source of supervision for robust robot vision systems. In particular, we demonstrate that a NeRF representation of a scene can be used to train dense object descriptors. We use an optimized NeRF to extract dense correspondences between multiple views of an object, and then use these correspondences as training data for learning a view-invariant representation of the object. NeRF's usage of a density field allows us to reformulate the correspondence problem with a novel distribution-of-depths formulation, as opposed to the conventional approach of using a depth map. Dense correspondence models supervised with our method significantly outperform off-the-shelf learned descriptors by 106% (PCK@3px metric, more than doubling performance) and outperform our baseline supervised with multi-view stereo by 29%. Furthermore, we demonstrate the learned dense descriptors enable robots to perform accurate 6-degree of freedom (6-DoF) pick and place of thin and reflective objects.
Open-Vocabulary Image Segmentation
Dec 22, 2021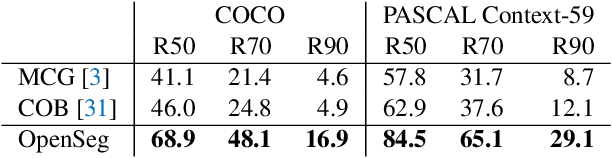

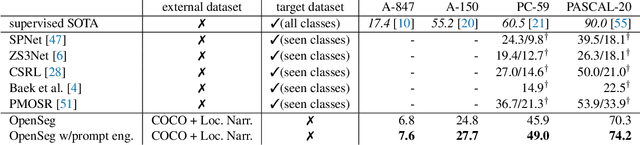
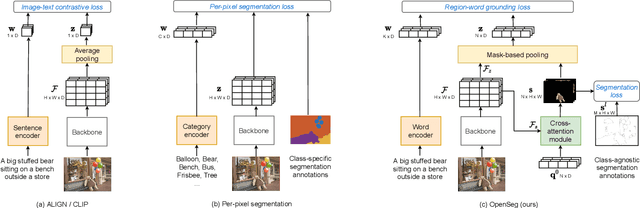
We design an open-vocabulary image segmentation model to organize an image into meaningful regions indicated by arbitrary texts. We identify that recent open-vocabulary models can not localize visual concepts well despite recognizing what are in an image. We argue that these models miss an important step of visual grouping, which organizes pixels into groups before learning visual-semantic alignments. We propose OpenSeg to address the above issue. First, it learns to propose segmentation masks for possible organizations. Then it learns visual-semantic alignments by aligning each word in a caption to one or a few predicted masks. We find the mask representations are the key to support learning from captions, making it possible to scale up the dataset and vocabulary sizes. Our work is the first to perform zero-shot transfer on holdout segmentation datasets. We set up two strong baselines by applying class activation maps or fine-tuning with pixel-wise labels on a pre-trained ALIGN model. OpenSeg outperforms these baselines by 3.4 mIoU on PASCAL-Context (459 classes) and 2.7 mIoU on ADE-20k (847 classes).
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021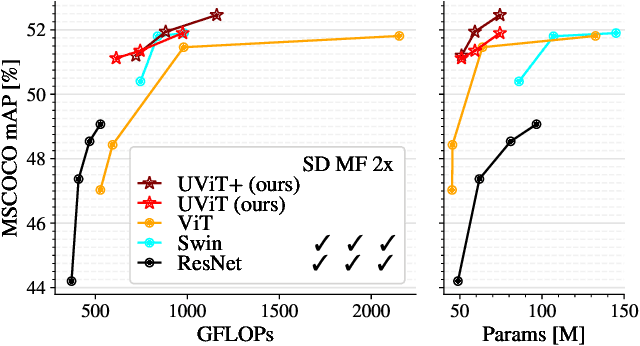

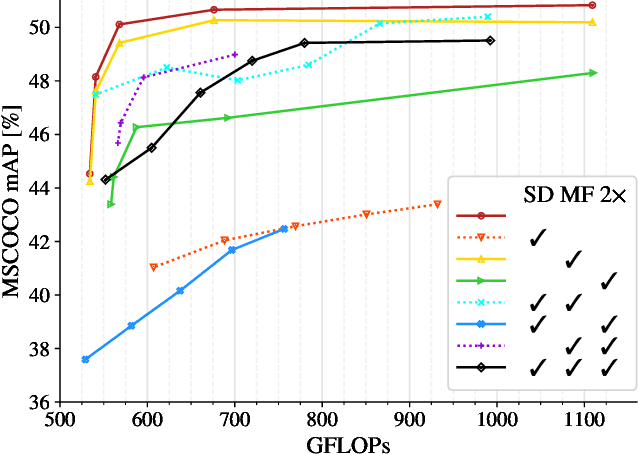

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
Multi-Task Self-Training for Learning General Representations
Aug 25, 2021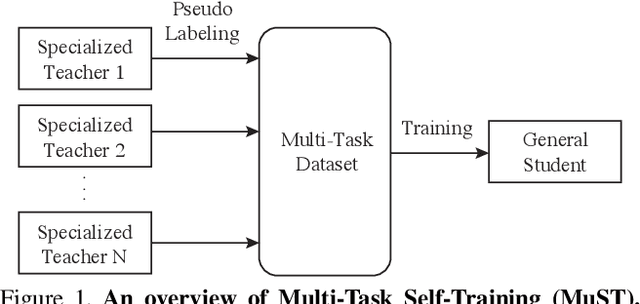
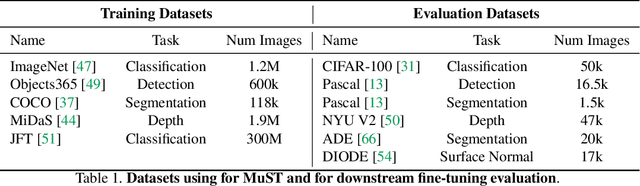

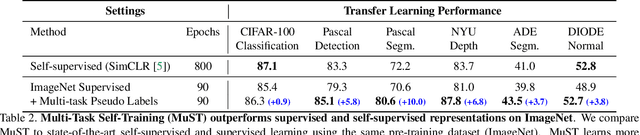
Despite the fast progress in training specialized models for various tasks, learning a single general model that works well for many tasks is still challenging for computer vision. Here we introduce multi-task self-training (MuST), which harnesses the knowledge in independent specialized teacher models (e.g., ImageNet model on classification) to train a single general student model. Our approach has three steps. First, we train specialized teachers independently on labeled datasets. We then use the specialized teachers to label an unlabeled dataset to create a multi-task pseudo labeled dataset. Finally, the dataset, which now contains pseudo labels from teacher models trained on different datasets/tasks, is then used to train a student model with multi-task learning. We evaluate the feature representations of the student model on 6 vision tasks including image recognition (classification, detection, segmentation)and 3D geometry estimation (depth and surface normal estimation). MuST is scalable with unlabeled or partially labeled datasets and outperforms both specialized supervised models and self-supervised models when training on large scale datasets. Lastly, we show MuST can improve upon already strong checkpoints trained with billions of examples. The results suggest self-training is a promising direction to aggregate labeled and unlabeled training data for learning general feature representations.
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Aug 20, 2021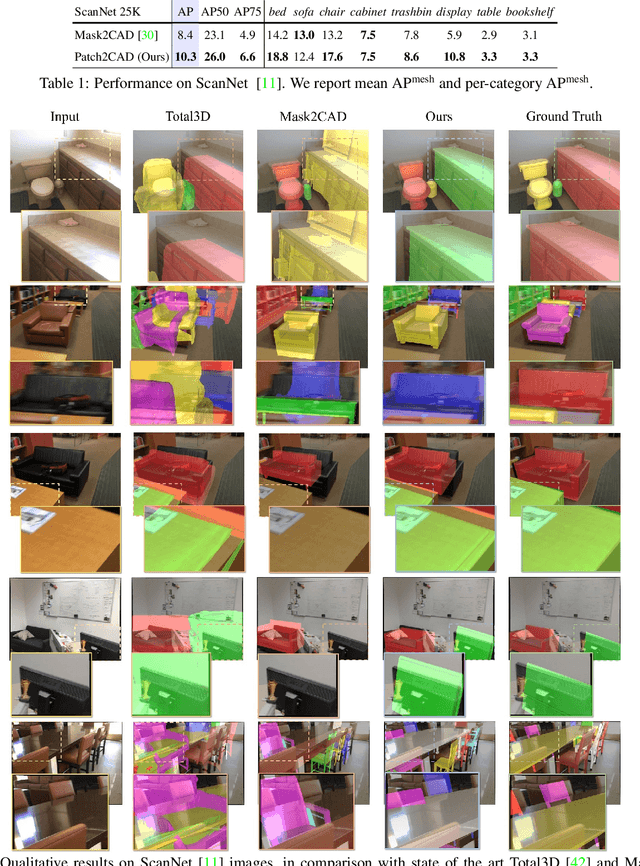
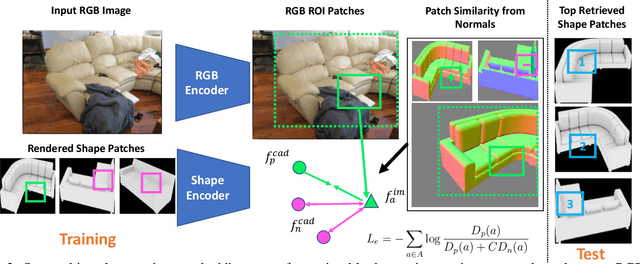
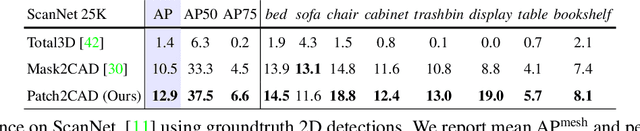
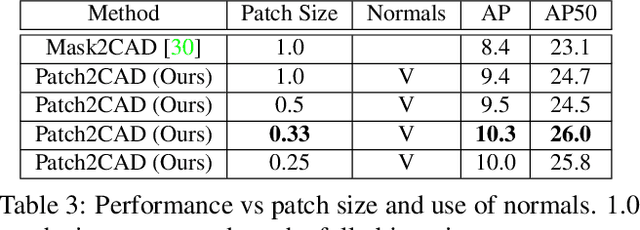
3D perception of object shapes from RGB image input is fundamental towards semantic scene understanding, grounding image-based perception in our spatially 3-dimensional real-world environments. To achieve a mapping between image views of objects and 3D shapes, we leverage CAD model priors from existing large-scale databases, and propose a novel approach towards constructing a joint embedding space between 2D images and 3D CAD models in a patch-wise fashion -- establishing correspondences between patches of an image view of an object and patches of CAD geometry. This enables part similarity reasoning for retrieving similar CADs to a new image view without exact matches in the database. Our patch embedding provides more robust CAD retrieval for shape estimation in our end-to-end estimation of CAD model shape and pose for detected objects in a single input image. Experiments on in-the-wild, complex imagery from ScanNet show that our approach is more robust than state of the art in real-world scenarios without any exact CAD matches.
Learning Open-World Object Proposals without Learning to Classify
Aug 15, 2021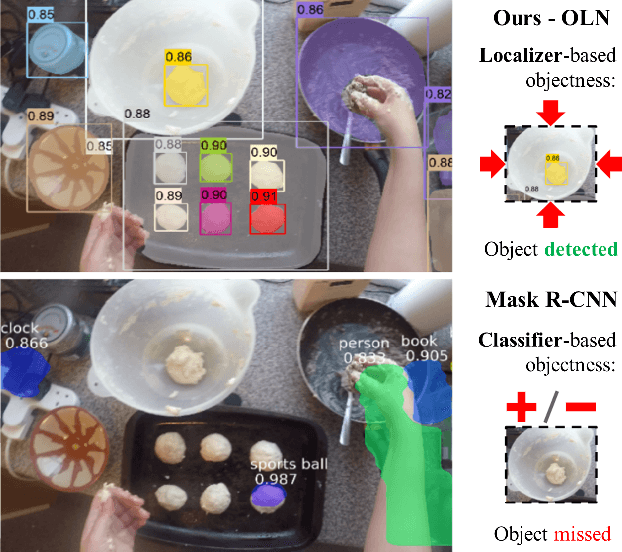
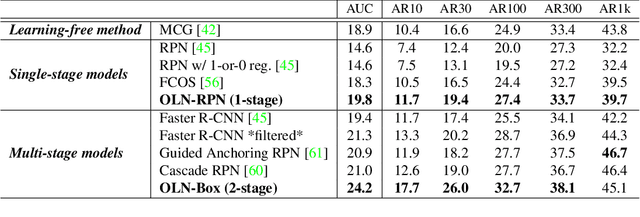
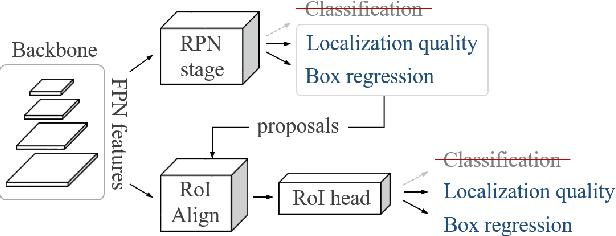
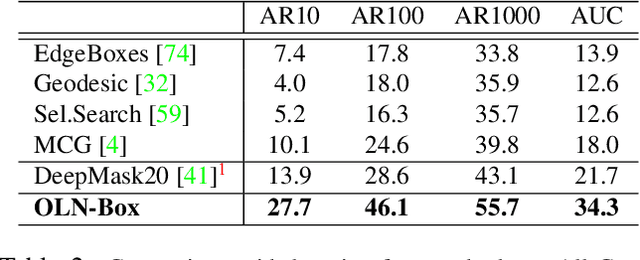
Object proposals have become an integral preprocessing steps of many vision pipelines including object detection, weakly supervised detection, object discovery, tracking, etc. Compared to the learning-free methods, learning-based proposals have become popular recently due to the growing interest in object detection. The common paradigm is to learn object proposals from data labeled with a set of object regions and their corresponding categories. However, this approach often struggles with novel objects in the open world that are absent in the training set. In this paper, we identify that the problem is that the binary classifiers in existing proposal methods tend to overfit to the training categories. Therefore, we propose a classification-free Object Localization Network (OLN) which estimates the objectness of each region purely by how well the location and shape of a region overlap with any ground-truth object (e.g., centerness and IoU). This simple strategy learns generalizable objectness and outperforms existing proposals on cross-category generalization on COCO, as well as cross-dataset evaluation on RoboNet, Object365, and EpicKitchens. Finally, we demonstrate the merit of OLN for long-tail object detection on large vocabulary dataset, LVIS, where we notice clear improvement in rare and common categories.
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Jul 01, 2021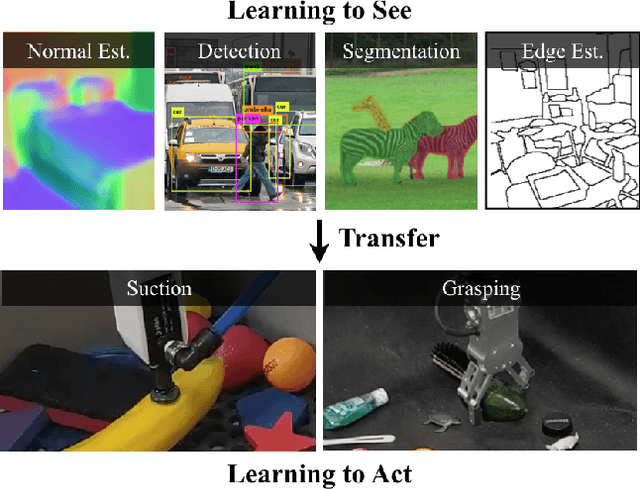

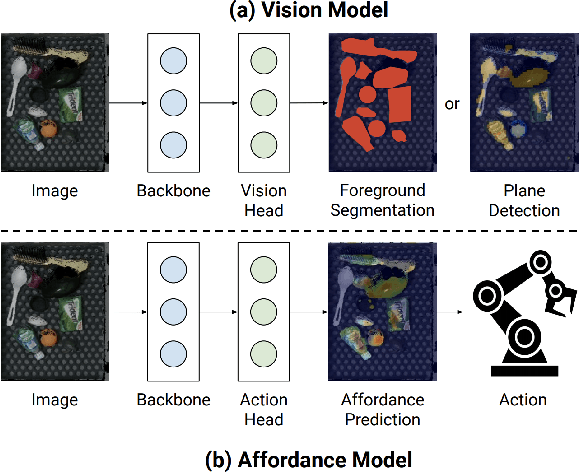

Does having visual priors (e.g. the ability to detect objects) facilitate learning to perform vision-based manipulation (e.g. picking up objects)? We study this problem under the framework of transfer learning, where the model is first trained on a passive vision task, and adapted to perform an active manipulation task. We find that pre-training on vision tasks significantly improves generalization and sample efficiency for learning to manipulate objects. However, realizing these gains requires careful selection of which parts of the model to transfer. Our key insight is that outputs of standard vision models highly correlate with affordance maps commonly used in manipulation. Therefore, we explore directly transferring model parameters from vision networks to affordance prediction networks, and show that this can result in successful zero-shot adaptation, where a robot can pick up certain objects with zero robotic experience. With just a small amount of robotic experience, we can further fine-tune the affordance model to achieve better results. With just 10 minutes of suction experience or 1 hour of grasping experience, our method achieves ~80% success rate at picking up novel objects.
Simple Training Strategies and Model Scaling for Object Detection
Jun 30, 2021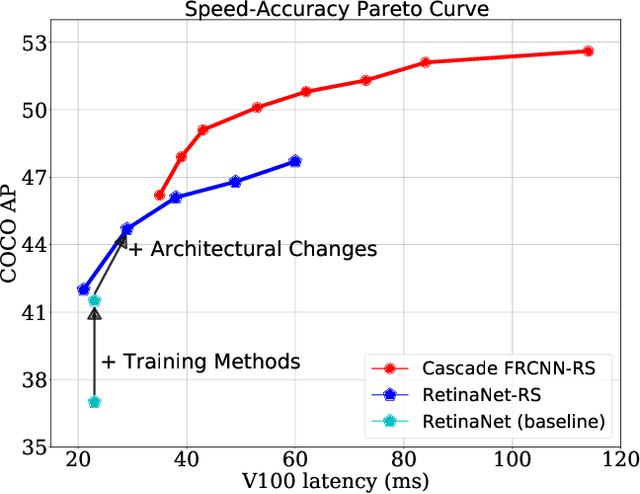
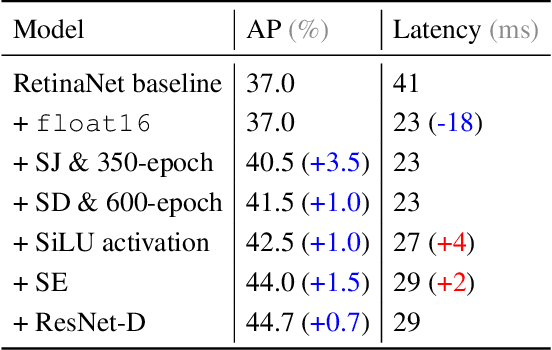
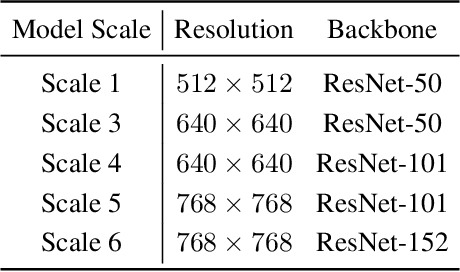
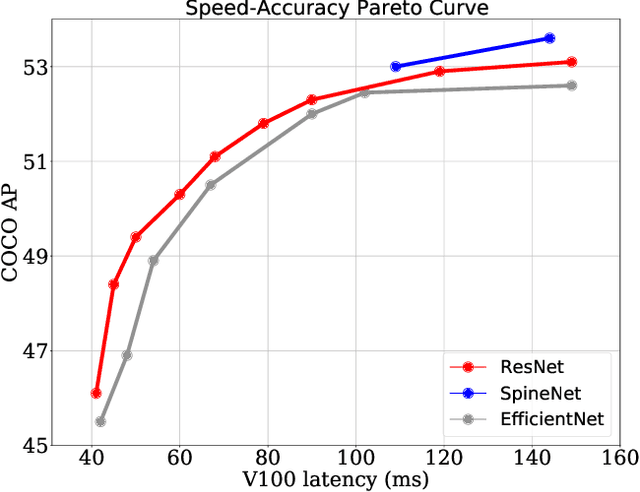
The speed-accuracy Pareto curve of object detection systems have advanced through a combination of better model architectures, training and inference methods. In this paper, we methodically evaluate a variety of these techniques to understand where most of the improvements in modern detection systems come from. We benchmark these improvements on the vanilla ResNet-FPN backbone with RetinaNet and RCNN detectors. The vanilla detectors are improved by 7.7% in accuracy while being 30% faster in speed. We further provide simple scaling strategies to generate family of models that form two Pareto curves, named RetinaNet-RS and Cascade RCNN-RS. These simple rescaled detectors explore the speed-accuracy trade-off between the one-stage RetinaNet detectors and two-stage RCNN detectors. Our largest Cascade RCNN-RS models achieve 52.9% AP with a ResNet152-FPN backbone and 53.6% with a SpineNet143L backbone. Finally, we show the ResNet architecture, with three minor architectural changes, outperforms EfficientNet as the backbone for object detection and instance segmentation systems.