 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
Apr 07, 2022
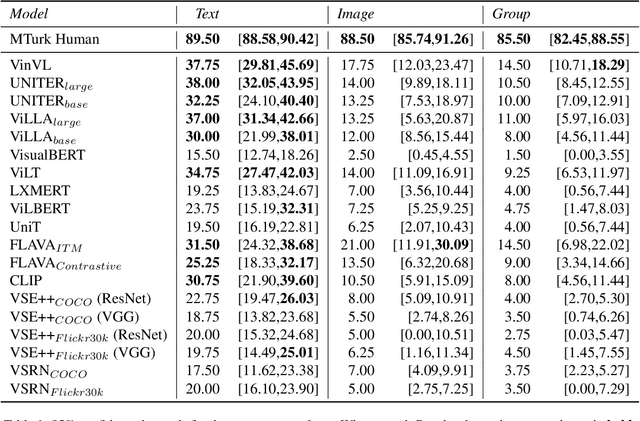
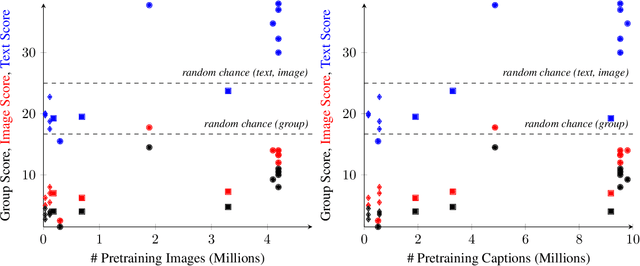
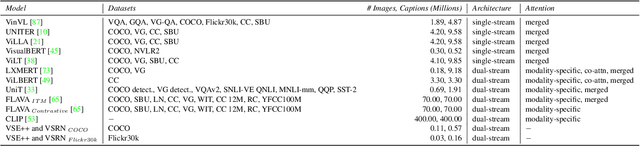
We present a novel task and dataset for evaluating the ability of vision and language models to conduct visio-linguistic compositional reasoning, which we call Winoground. Given two images and two captions, the goal is to match them correctly - but crucially, both captions contain a completely identical set of words, only in a different order. The dataset was carefully hand-curated by expert annotators and is labeled with a rich set of fine-grained tags to assist in analyzing model performance. We probe a diverse range of state-of-the-art vision and language models and find that, surprisingly, none of them do much better than chance. Evidently, these models are not as skilled at visio-linguistic compositional reasoning as we might have hoped. We perform an extensive analysis to obtain insights into how future work might try to mitigate these models' shortcomings. We aim for Winoground to serve as a useful evaluation set for advancing the state of the art and driving further progress in the field. The dataset is available at https://huggingface.co/datasets/facebook/winoground.
Dynatask: A Framework for Creating Dynamic AI Benchmark Tasks
Apr 05, 2022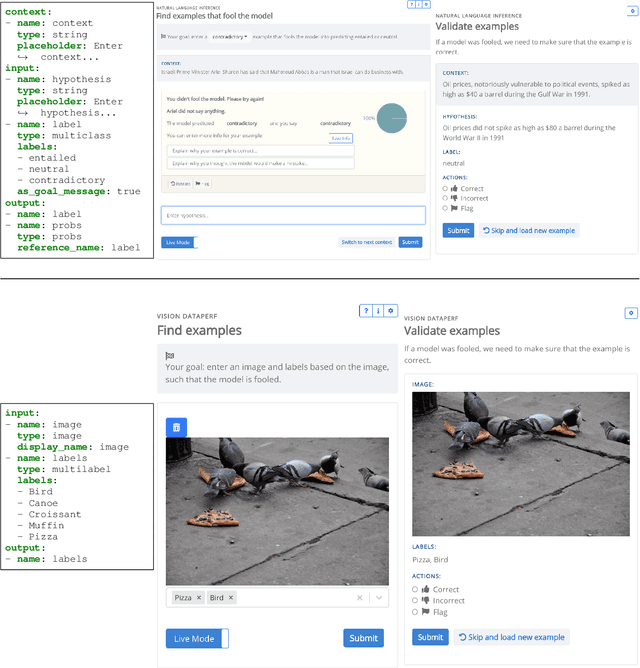
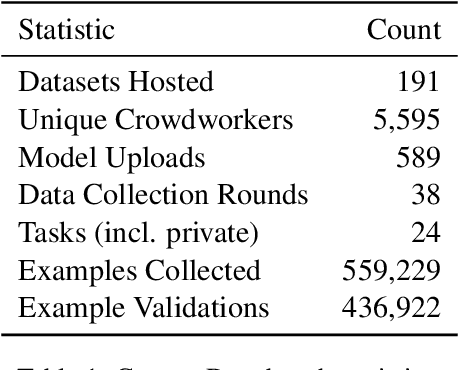
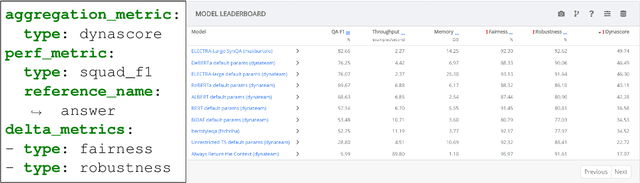
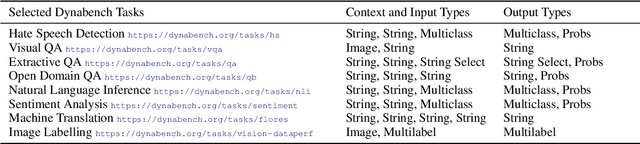
We introduce Dynatask: an open source system for setting up custom NLP tasks that aims to greatly lower the technical knowledge and effort required for hosting and evaluating state-of-the-art NLP models, as well as for conducting model in the loop data collection with crowdworkers. Dynatask is integrated with Dynabench, a research platform for rethinking benchmarking in AI that facilitates human and model in the loop data collection and evaluation. To create a task, users only need to write a short task configuration file from which the relevant web interfaces and model hosting infrastructure are automatically generated. The system is available at https://dynabench.org/ and the full library can be found at https://github.com/facebookresearch/dynabench.
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
Dec 16, 2021

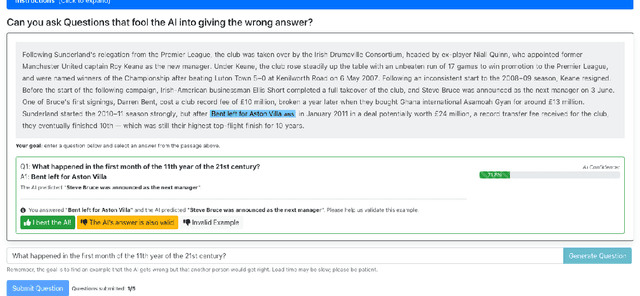

In Dynamic Adversarial Data Collection (DADC), human annotators are tasked with finding examples that models struggle to predict correctly. Models trained on DADC-collected training data have been shown to be more robust in adversarial and out-of-domain settings, and are considerably harder for humans to fool. However, DADC is more time-consuming than traditional data collection and thus more costly per example. In this work, we examine if we can maintain the advantages of DADC, without suffering the additional cost. To that end, we introduce Generative Annotation Assistants (GAAs), generator-in-the-loop models that provide real-time suggestions that annotators can either approve, modify, or reject entirely. We collect training datasets in twenty experimental settings and perform a detailed analysis of this approach for the task of extractive question answering (QA) for both standard and adversarial data collection. We demonstrate that GAAs provide significant efficiency benefits in terms of annotation speed, while leading to improved model fooling rates. In addition, we show that GAA-assisted data leads to higher downstream model performance on a variety of question answering tasks.
Hatemoji: A Test Suite and Adversarially-Generated Dataset for Benchmarking and Detecting Emoji-based Hate
Aug 31, 2021



Detecting online hate is a complex task, and low-performing models have harmful consequences when used for sensitive applications such as content moderation. Emoji-based hate is a key emerging challenge for automated detection. We present HatemojiCheck, a test suite of 3,930 short-form statements that allows us to evaluate performance on hateful language expressed with emoji. Using the test suite, we expose weaknesses in existing hate detection models. To address these weaknesses, we create the HatemojiTrain dataset using a human-and-model-in-the-loop approach. Models trained on these 5,912 adversarial examples perform substantially better at detecting emoji-based hate, while retaining strong performance on text-only hate. Both HatemojiCheck and HatemojiTrain are made publicly available.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021
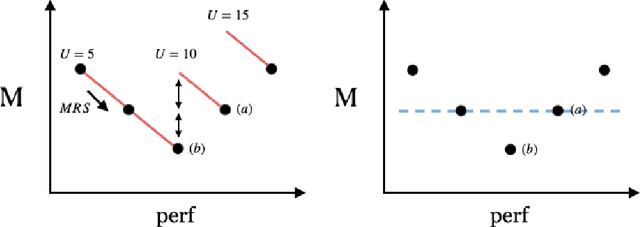
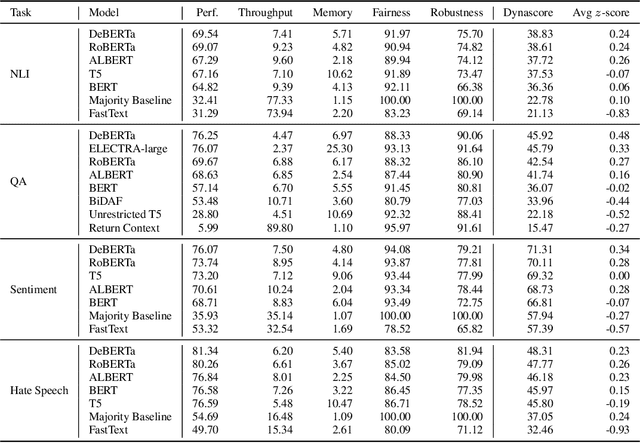
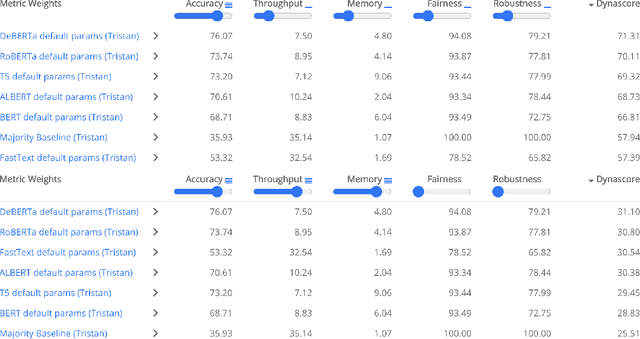
We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.
Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation
Apr 18, 2021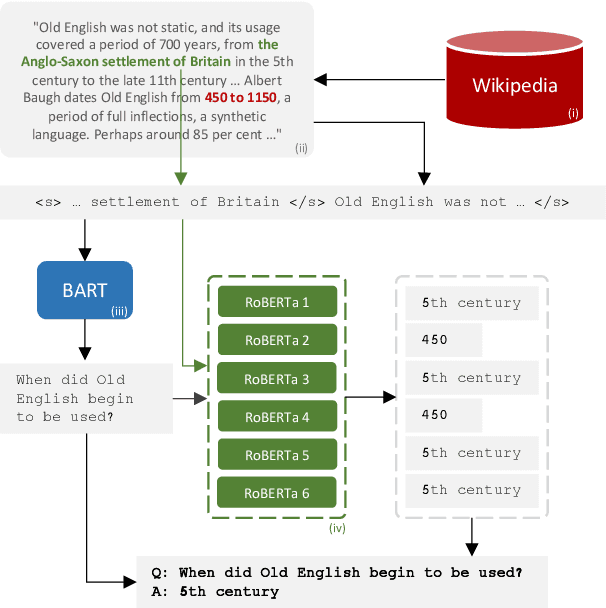
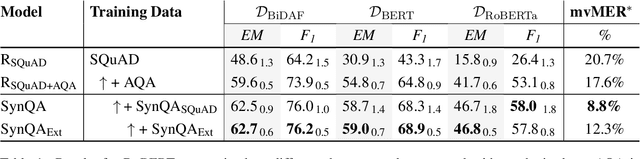
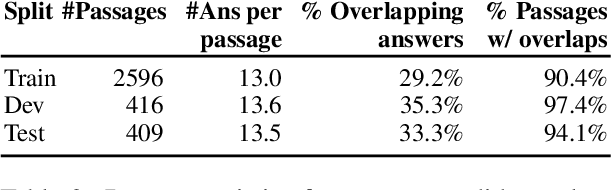
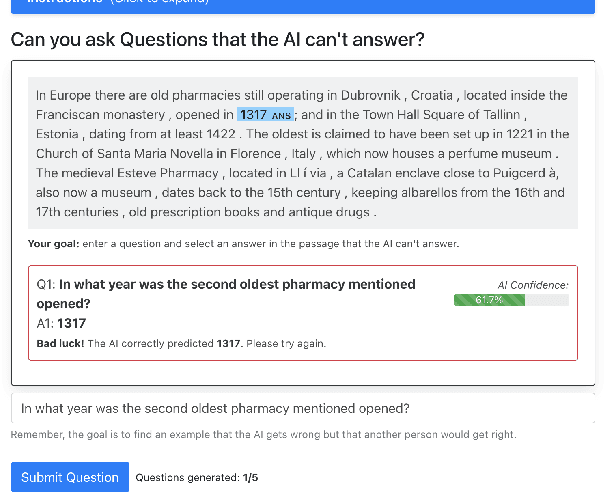
Despite the availability of very large datasets and pretrained models, state-of-the-art question answering models remain susceptible to a variety of adversarial attacks and are still far from obtaining human-level language understanding. One proposed way forward is dynamic adversarial data collection, in which a human annotator attempts to create examples for which a model-in-the-loop fails. However, this approach comes at a higher cost per sample and slower pace of annotation, as model-adversarial data requires more annotator effort to generate. In this work, we investigate several answer selection, question generation, and filtering methods that form a synthetic adversarial data generation pipeline that takes human-generated adversarial samples and unannotated text to create synthetic question-answer pairs. Models trained on both synthetic and human-generated data outperform models not trained on synthetic adversarial data, and obtain state-of-the-art results on the AdversarialQA dataset with overall performance gains of 3.7F1. Furthermore, we find that training on the synthetic adversarial data improves model generalisation across domains for non-adversarial data, demonstrating gains on 9 of the 12 datasets for MRQA. Lastly, we find that our models become considerably more difficult to beat by human adversaries, with a drop in macro-averaged validated model error rate from 17.6% to 8.8% when compared to non-augmented models.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021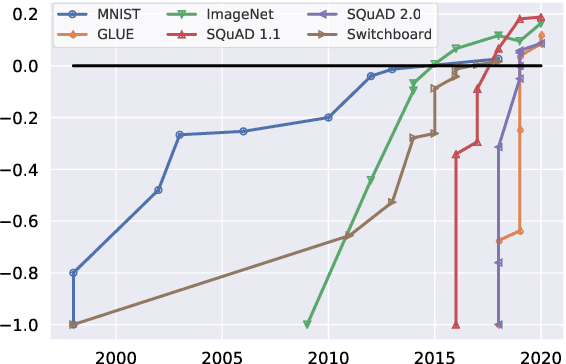
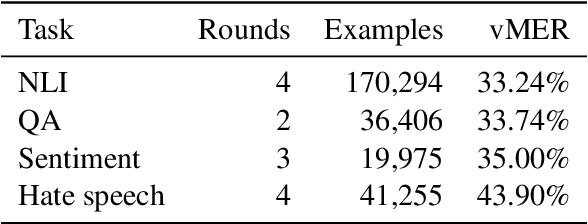
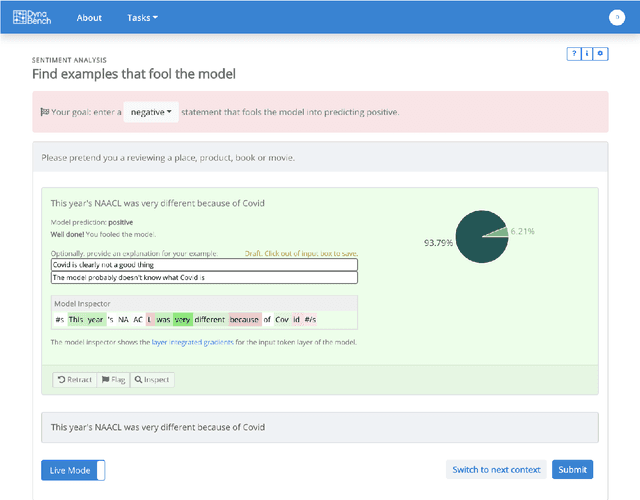
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
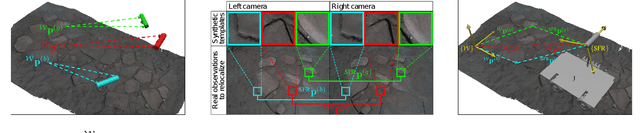

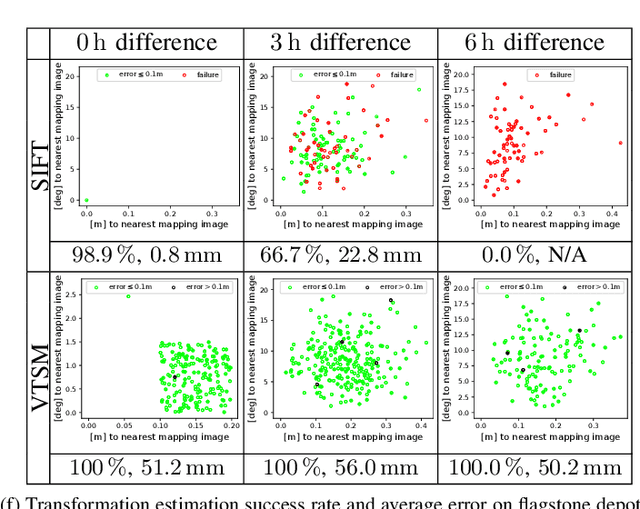
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
Dec 31, 2020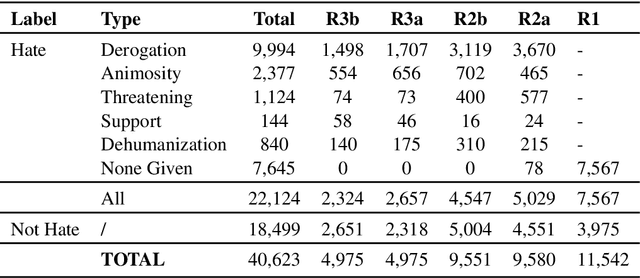
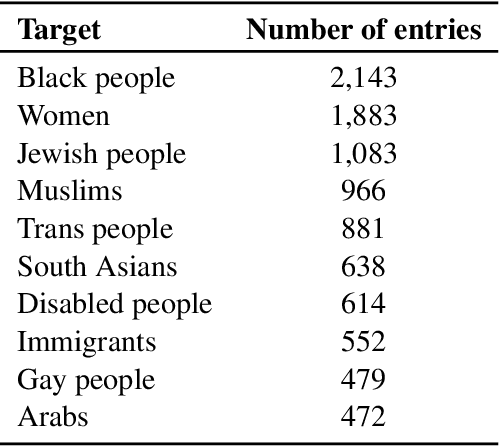
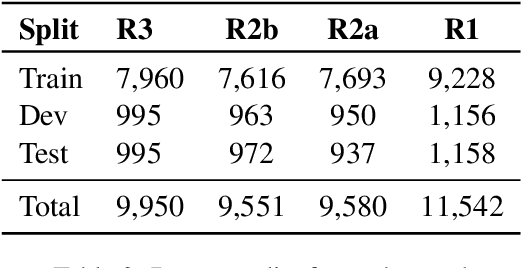
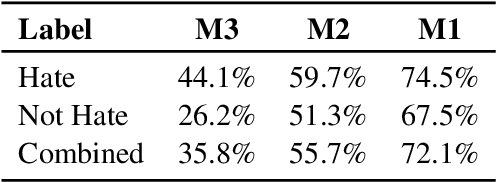
We present a first-of-its-kind large synthetic training dataset for online hate classification, created from scratch with trained annotators over multiple rounds of dynamic data collection. We provide a 40,623 example dataset with annotations for fine-grained labels, including a large number of challenging contrastive perturbation examples. Unusually for an abusive content dataset, it comprises 54% hateful and 46% not hateful entries. We show that model performance and robustness can be greatly improved using the dynamic data collection paradigm. The model error rate decreased across rounds, from 72.1% in the first round to 35.8% in the last round, showing that models became increasingly harder to trick -- even though content become progressively more adversarial as annotators became more experienced. Hate speech detection is an important and subtle problem that is still very challenging for existing AI methods. We hope that the models, dataset and dynamic system that we present here will help improve current approaches, having a positive social impact.
Investigating Novel Verb Learning in BERT: Selectional Preference Classes and Alternation-Based Syntactic Generalization
Nov 04, 2020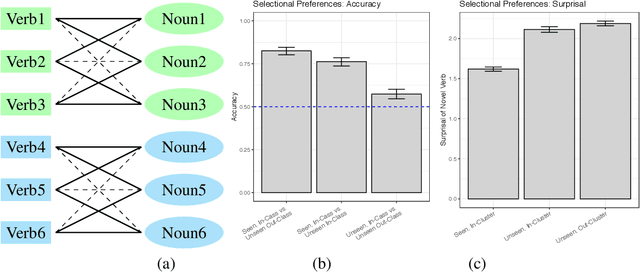
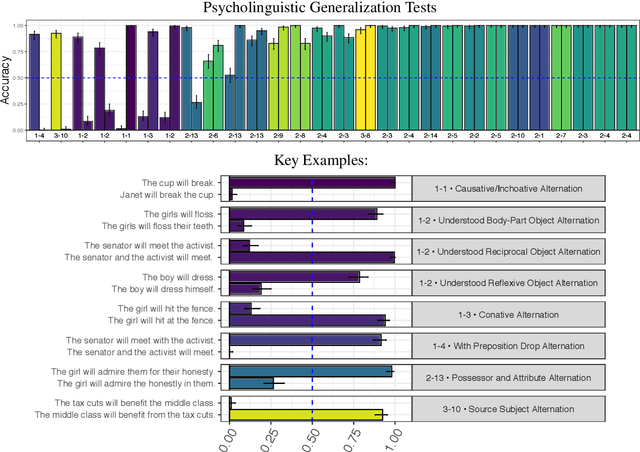
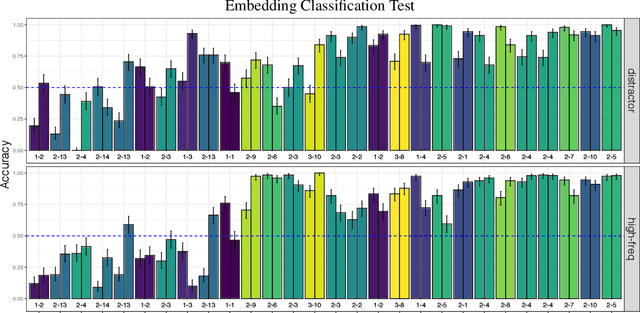
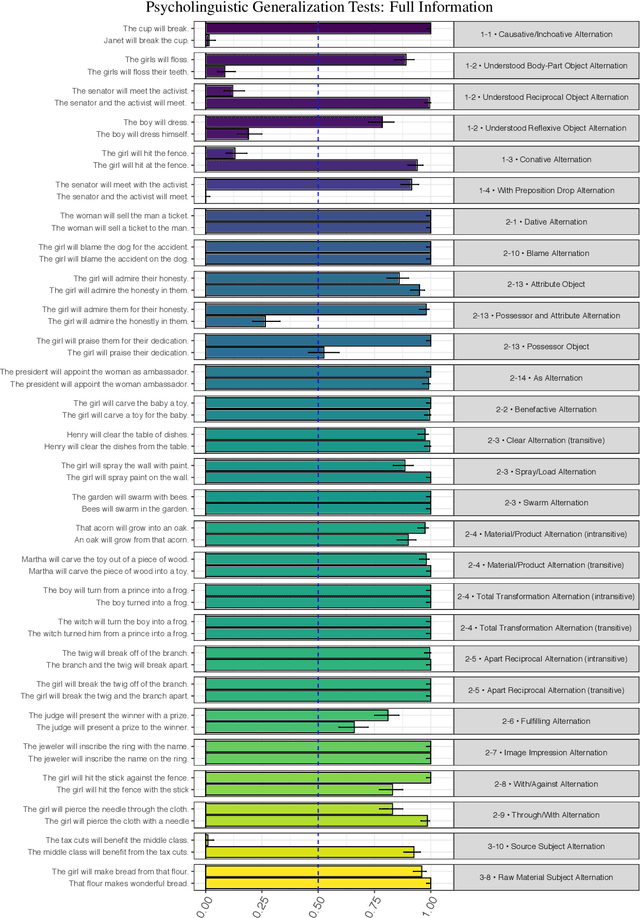
Previous studies investigating the syntactic abilities of deep learning models have not targeted the relationship between the strength of the grammatical generalization and the amount of evidence to which the model is exposed during training. We address this issue by deploying a novel word-learning paradigm to test BERT's few-shot learning capabilities for two aspects of English verbs: alternations and classes of selectional preferences. For the former, we fine-tune BERT on a single frame in a verbal-alternation pair and ask whether the model expects the novel verb to occur in its sister frame. For the latter, we fine-tune BERT on an incomplete selectional network of verbal objects and ask whether it expects unattested but plausible verb/object pairs. We find that BERT makes robust grammatical generalizations after just one or two instances of a novel word in fine-tuning. For the verbal alternation tests, we find that the model displays behavior that is consistent with a transitivity bias: verbs seen few times are expected to take direct objects, but verbs seen with direct objects are not expected to occur intransitively.