 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Race, Racism, and Anti-Racism in NLP
Jul 15, 2021
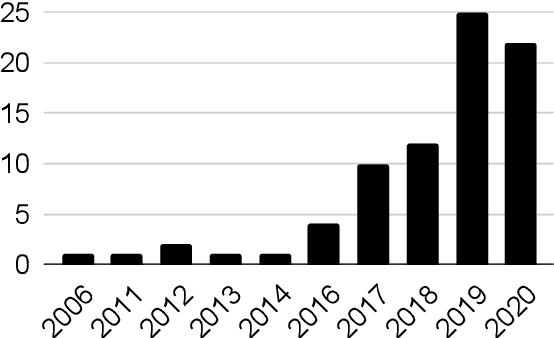
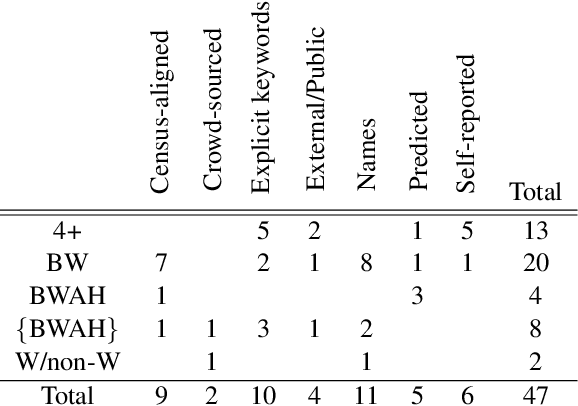
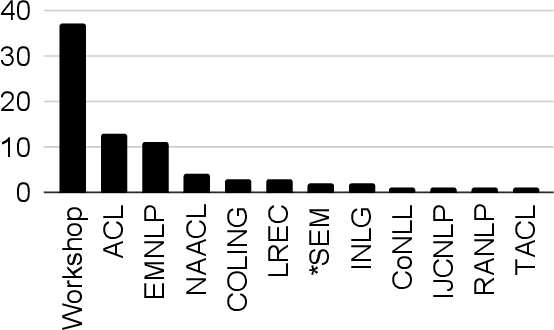
Despite inextricable ties between race and language, little work has considered race in NLP research and development. In this work, we survey 79 papers from the ACL anthology that mention race. These papers reveal various types of race-related bias in all stages of NLP model development, highlighting the need for proactive consideration of how NLP systems can uphold racial hierarchies. However, persistent gaps in research on race and NLP remain: race has been siloed as a niche topic and remains ignored in many NLP tasks; most work operationalizes race as a fixed single-dimensional variable with a ground-truth label, which risks reinforcing differences produced by historical racism; and the voices of historically marginalized people are nearly absent in NLP literature. By identifying where and how NLP literature has and has not considered race, especially in comparison to related fields, our work calls for inclusion and racial justice in NLP research practices.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021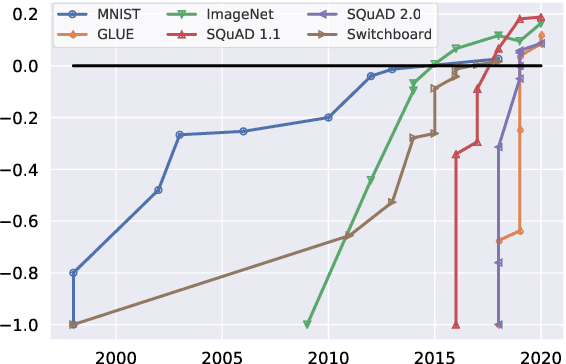
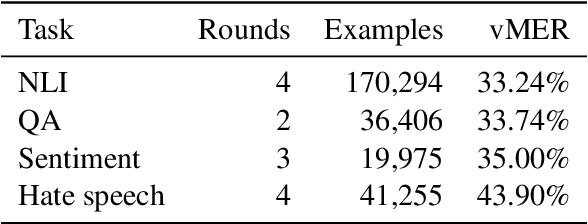
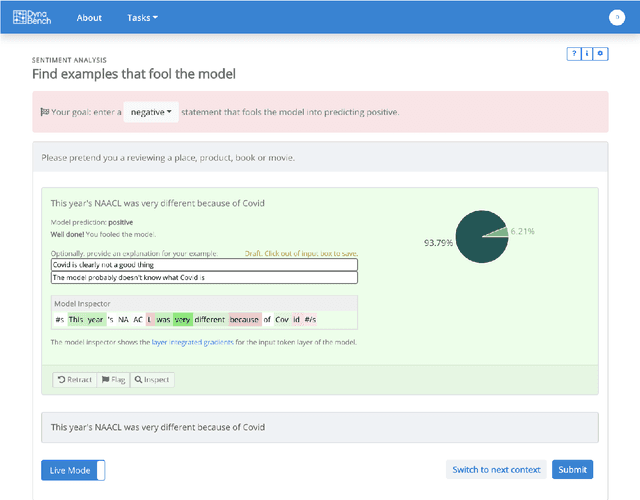
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
Disembodied Machine Learning: On the Illusion of Objectivity in NLP
Jan 28, 2021Machine Learning seeks to identify and encode bodies of knowledge within provided datasets. However, data encodes subjective content, which determines the possible outcomes of the models trained on it. Because such subjectivity enables marginalisation of parts of society, it is termed (social) `bias' and sought to be removed. In this paper, we contextualise this discourse of bias in the ML community against the subjective choices in the development process. Through a consideration of how choices in data and model development construct subjectivity, or biases that are represented in a model, we argue that addressing and mitigating biases is near-impossible. This is because both data and ML models are objects for which meaning is made in each step of the development pipeline, from data selection over annotation to model training and analysis. Accordingly, we find the prevalent discourse of bias limiting in its ability to address social marginalisation. We recommend to be conscientious of this, and to accept that de-biasing methods only correct for a fraction of biases.
Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection
Dec 31, 2020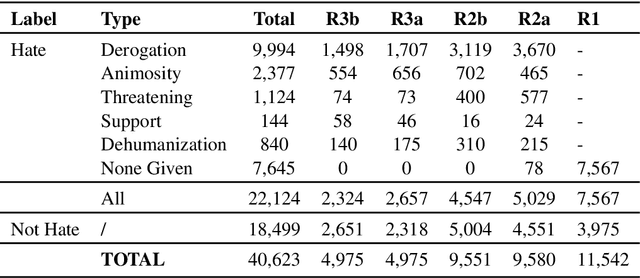
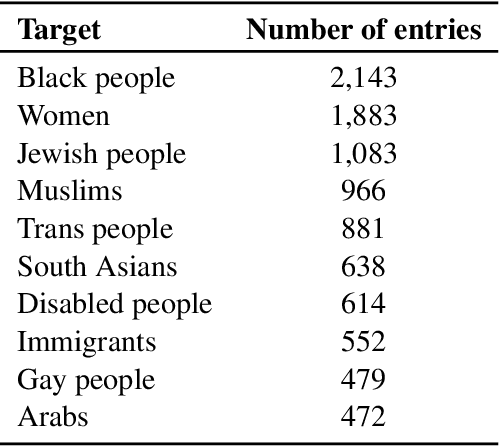
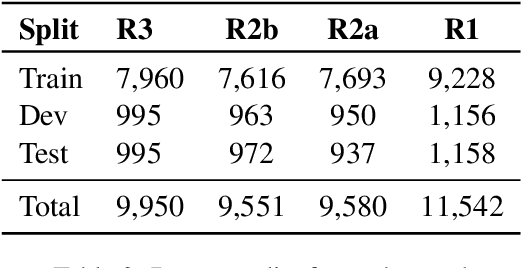
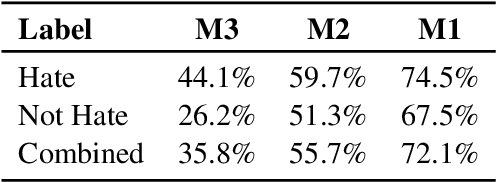
We present a first-of-its-kind large synthetic training dataset for online hate classification, created from scratch with trained annotators over multiple rounds of dynamic data collection. We provide a 40,623 example dataset with annotations for fine-grained labels, including a large number of challenging contrastive perturbation examples. Unusually for an abusive content dataset, it comprises 54% hateful and 46% not hateful entries. We show that model performance and robustness can be greatly improved using the dynamic data collection paradigm. The model error rate decreased across rounds, from 72.1% in the first round to 35.8% in the last round, showing that models became increasingly harder to trick -- even though content become progressively more adversarial as annotators became more experienced. Hate speech detection is an important and subtle problem that is still very challenging for existing AI methods. We hope that the models, dataset and dynamic system that we present here will help improve current approaches, having a positive social impact.
HateCheck: Functional Tests for Hate Speech Detection Models
Dec 31, 2020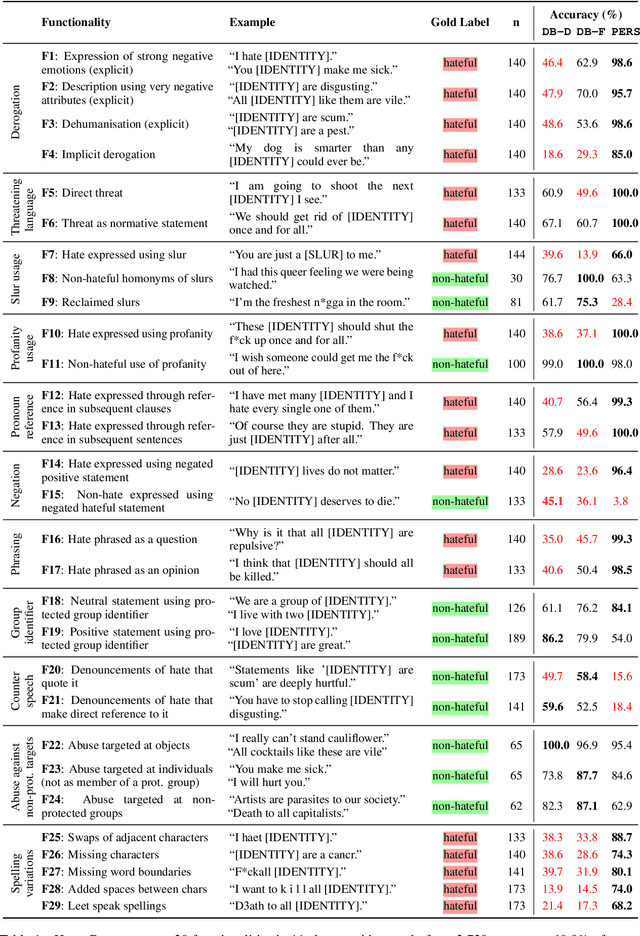
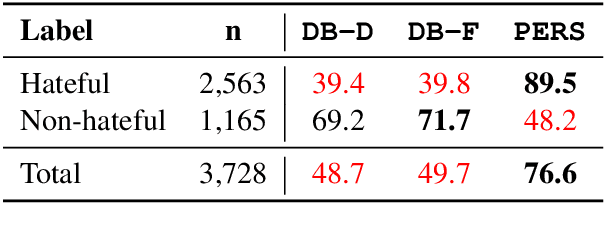
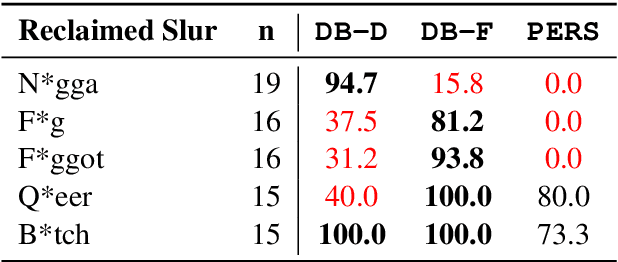

Detecting online hate is a difficult task that even state-of-the-art models struggle with. In previous research, hate speech detection models are typically evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model quality due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a first suite of functional tests for hate speech detection models. We specify 29 model functionalities, the selection of which we motivate by reviewing previous research and through a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate data quality through a structured annotation process. To illustrate HateCheck's utility, we test near-state-of-the-art transformer detection models as well as a popular commercial model, revealing critical model weaknesses.
Detecting East Asian Prejudice on Social Media
May 08, 2020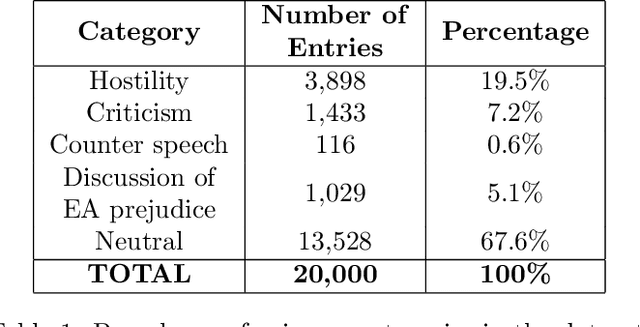
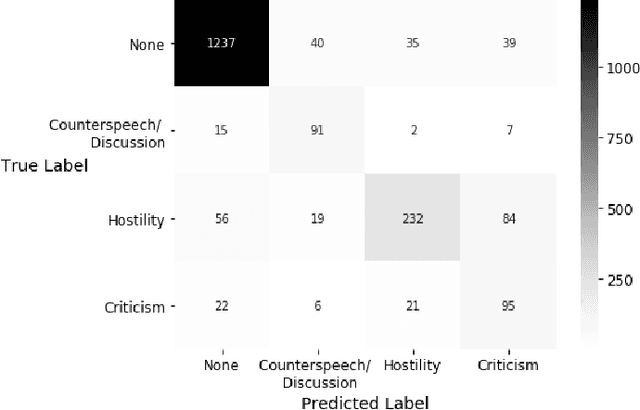
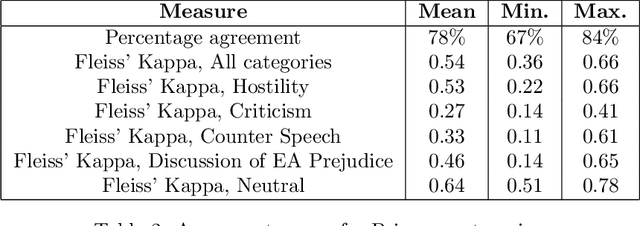
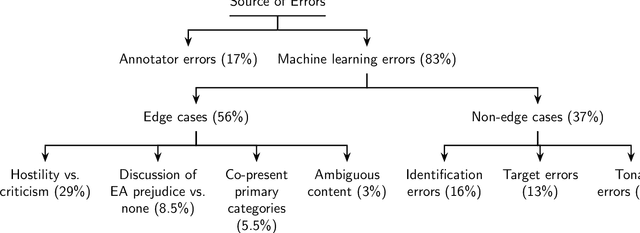
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.
Understanding Abuse: A Typology of Abusive Language Detection Subtasks
May 30, 2017
As the body of research on abusive language detection and analysis grows, there is a need for critical consideration of the relationships between different subtasks that have been grouped under this label. Based on work on hate speech, cyberbullying, and online abuse we propose a typology that captures central similarities and differences between subtasks and we discuss its implications for data annotation and feature construction. We emphasize the practical actions that can be taken by researchers to best approach their abusive language detection subtask of interest.