 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
Dec 21, 2021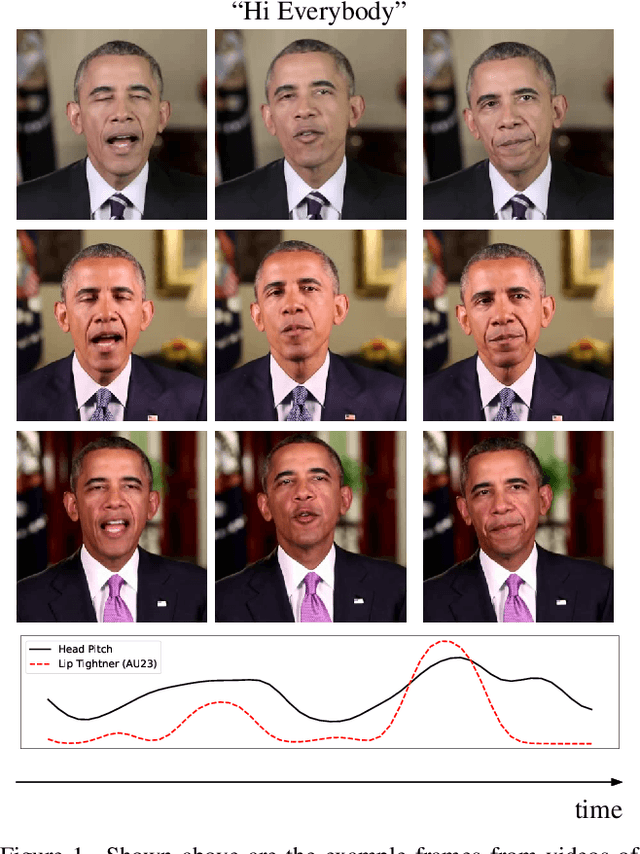
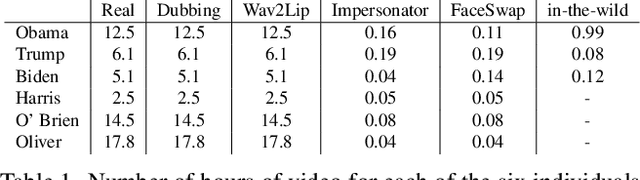
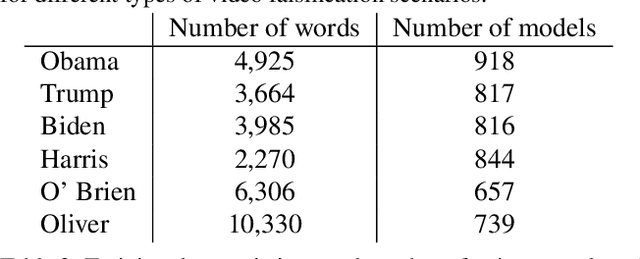
In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques. Such falsifications range from cheapfakes (e.g., lookalikes or audio dubbing) to deepfakes (e.g., sophisticated AI media synthesis methods), which are becoming perceptually indistinguishable from real videos. To tackle this challenge, we propose a multi-modal semantic forensic approach to discover clues that go beyond detecting discrepancies in visual quality, thereby handling both simpler cheapfakes and visually persuasive deepfakes. In this work, our goal is to verify that the purported person seen in the video is indeed themselves by detecting anomalous correspondences between their facial movements and the words they are saying. We leverage the idea of attribution to learn person-specific biometric patterns that distinguish a given speaker from others. We use interpretable Action Units (AUs) to capture a persons' face and head movement as opposed to deep CNN visual features, and we are the first to use word-conditioned facial motion analysis. Unlike existing person-specific approaches, our method is also effective against attacks that focus on lip manipulation. We further demonstrate our method's effectiveness on a range of fakes not seen in training including those without video manipulation, that were not addressed in prior work.
Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation
Dec 16, 2021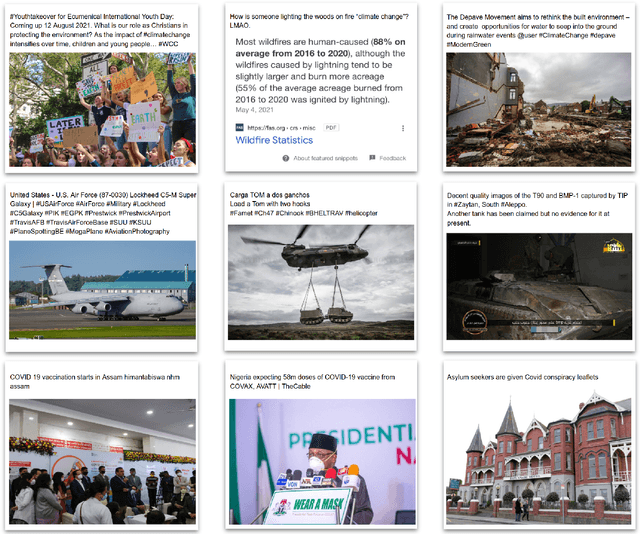
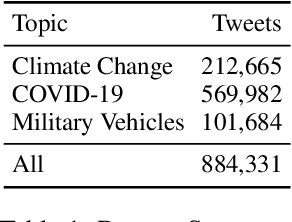
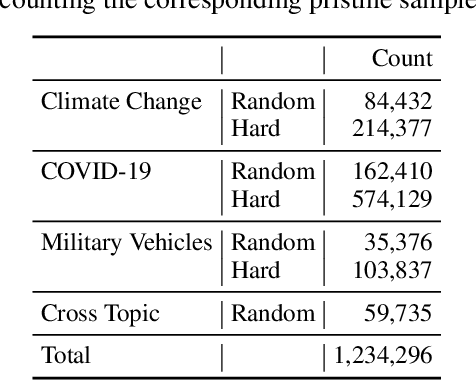

Detecting out-of-context media, such as "miscaptioned" images on Twitter, often requires detecting inconsistencies between the two modalities. This paper describes our approach to the Image-Text Inconsistency Detection challenge of the DARPA Semantic Forensics (SemaFor) Program. First, we collect Twitter-COMMs, a large-scale multimodal dataset with 884k tweets relevant to the topics of Climate Change, COVID-19, and Military Vehicles. We train our approach, based on the state-of-the-art CLIP model, leveraging automatically generated random and hard negatives. Our method is then tested on a hidden human-generated evaluation set. We achieve the best result on the program leaderboard, with 11% detection improvement in a high precision regime over a zero-shot CLIP baseline.
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Dec 14, 2021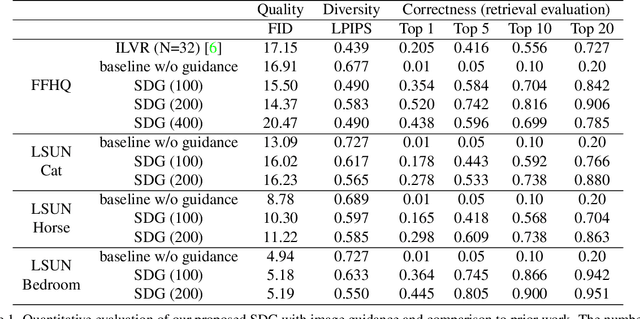
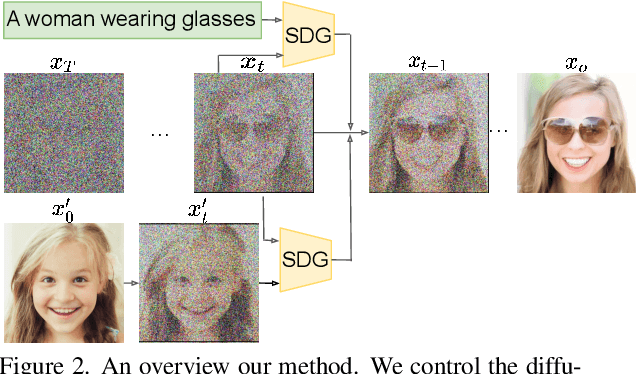
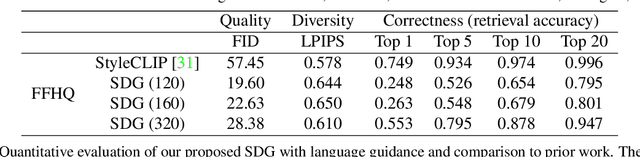

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.
Learning to Detect Every Thing in an Open World
Dec 03, 2021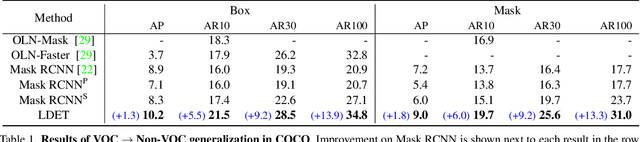
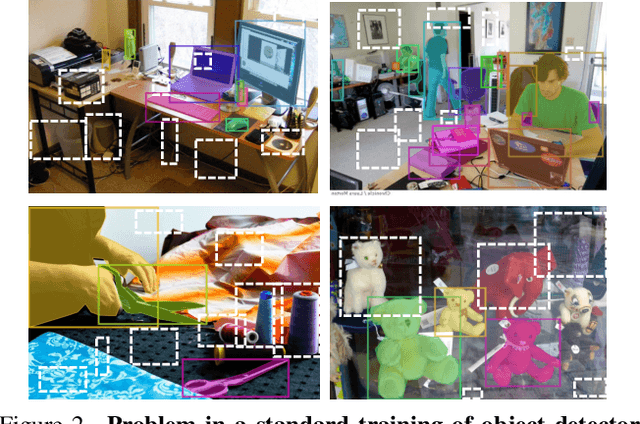
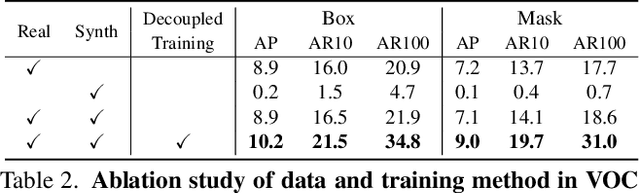
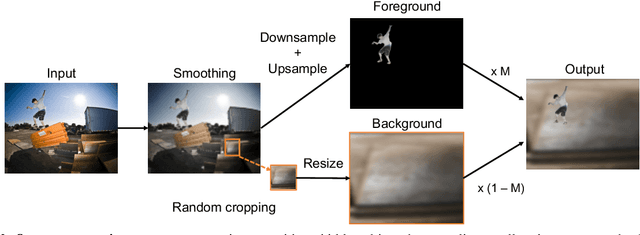
Many open-world applications require the detection of novel objects, yet state-of-the-art object detection and instance segmentation networks do not excel at this task. The key issue lies in their assumption that regions without any annotations should be suppressed as negatives, which teaches the model to treat the unannotated objects as background. To address this issue, we propose a simple yet surprisingly powerful data augmentation and training scheme we call Learning to Detect Every Thing (LDET). To avoid suppressing hidden objects, background objects that are visible but unlabeled, we paste annotated objects on a background image sampled from a small region of the original image. Since training solely on such synthetically augmented images suffers from domain shift, we decouple the training into two parts: 1) training the region classification and regression head on augmented images, and 2) training the mask heads on original images. In this way, a model does not learn to classify hidden objects as background while generalizing well to real images. LDET leads to significant improvements on many datasets in the open world instance segmentation task, outperforming baselines on cross-category generalization on COCO, as well as cross-dataset evaluation on UVO and Cityscapes.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021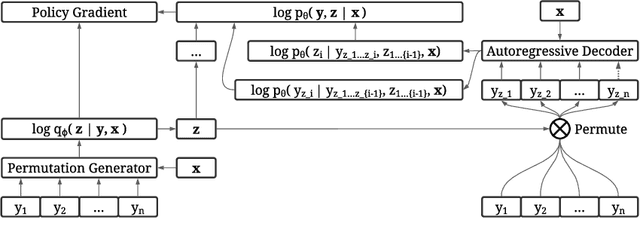
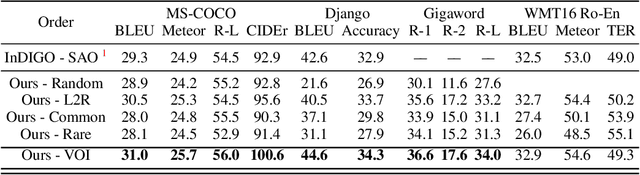
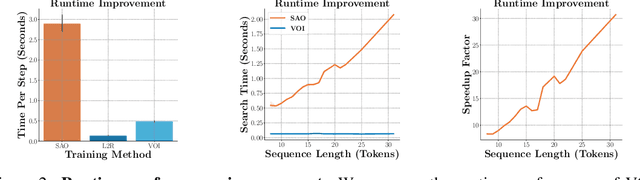
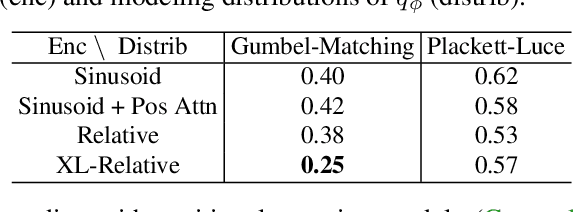
The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.
Object-Region Video Transformers
Oct 13, 2021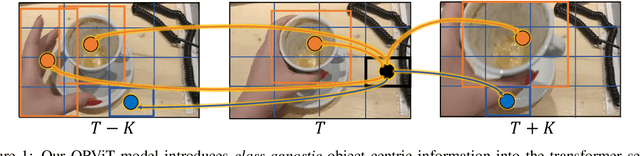
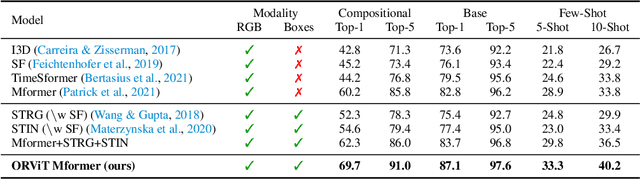
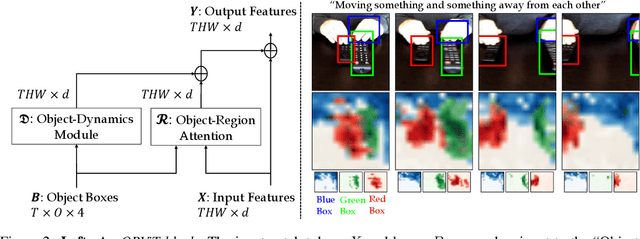
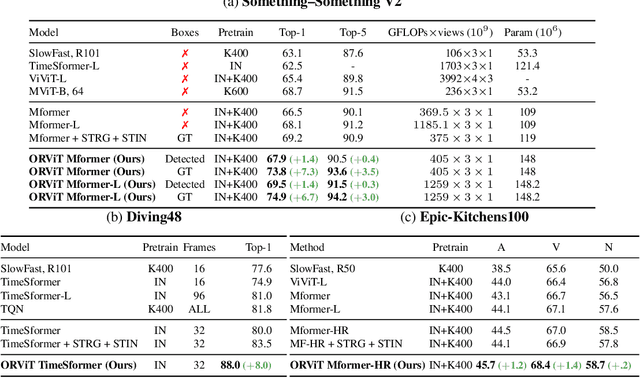
Evidence from cognitive psychology suggests that understanding spatio-temporal object interactions and dynamics can be essential for recognizing actions in complex videos. Therefore, action recognition models are expected to benefit from explicit modeling of objects, including their appearance, interaction, and dynamics. Recently, video transformers have shown great success in video understanding, exceeding CNN performance. Yet, existing video transformer models do not explicitly model objects. In this work, we present Object-Region Video Transformers (ORViT), an \emph{object-centric} approach that extends video transformer layers with a block that directly incorporates object representations. The key idea is to fuse object-centric spatio-temporal representations throughout multiple transformer layers. Our ORViT block consists of two object-level streams: appearance and dynamics. In the appearance stream, an ``Object-Region Attention'' element applies self-attention over the patches and \emph{object regions}. In this way, visual object regions interact with uniform patch tokens and enrich them with contextualized object information. We further model object dynamics via a separate ``Object-Dynamics Module'', which captures trajectory interactions, and show how to integrate the two streams. We evaluate our model on standard and compositional action recognition on Something-Something V2, standard action recognition on Epic-Kitchen100 and Diving48, and spatio-temporal action detection on AVA. We show strong improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a transformer architecture. For code and pretrained models, visit the project page at https://roeiherz.github.io/ORViT/.
On-target Adaptation
Sep 02, 2021


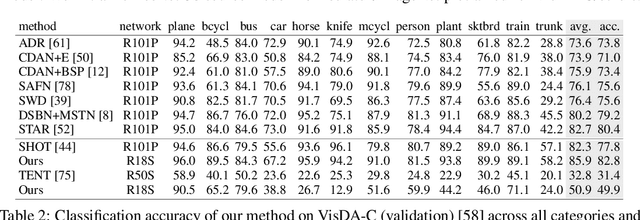
Domain adaptation seeks to mitigate the shift between training on the \emph{source} domain and testing on the \emph{target} domain. Most adaptation methods rely on the source data by joint optimization over source data and target data. Source-free methods replace the source data with a source model by fine-tuning it on target. Either way, the majority of the parameter updates for the model representation and the classifier are derived from the source, and not the target. However, target accuracy is the goal, and so we argue for optimizing as much as possible on the target data. We show significant improvement by on-target adaptation, which learns the representation purely from target data while taking only the source predictions for supervision. In the long-tailed classification setting, we show further improvement by on-target class distribution learning, which learns the (im)balance of classes from target data.
Tune it the Right Way: Unsupervised Validation of Domain Adaptation via Soft Neighborhood Density
Aug 24, 2021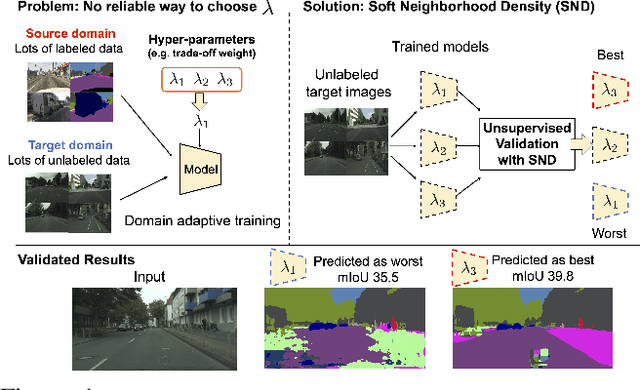

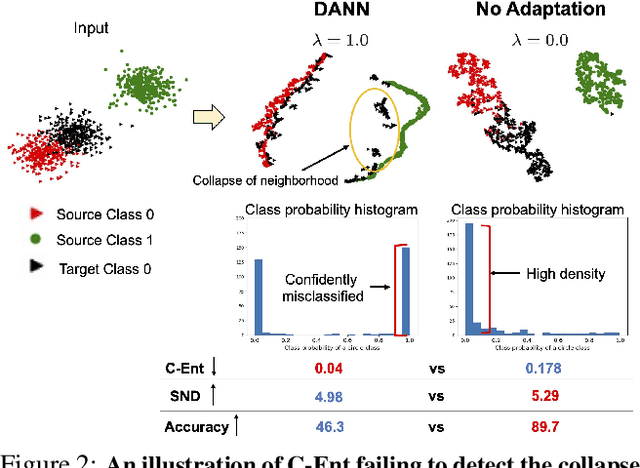

Unsupervised domain adaptation (UDA) methods can dramatically improve generalization on unlabeled target domains. However, optimal hyper-parameter selection is critical to achieving high accuracy and avoiding negative transfer. Supervised hyper-parameter validation is not possible without labeled target data, which raises the question: How can we validate unsupervised adaptation techniques in a realistic way? We first empirically analyze existing criteria and demonstrate that they are not very effective for tuning hyper-parameters. Intuitively, a well-trained source classifier should embed target samples of the same class nearby, forming dense neighborhoods in feature space. Based on this assumption, we propose a novel unsupervised validation criterion that measures the density of soft neighborhoods by computing the entropy of the similarity distribution between points. Our criterion is simpler than competing validation methods, yet more effective; it can tune hyper-parameters and the number of training iterations in both image classification and semantic segmentation models. The code used for the paper will be available at \url{https://github.com/VisionLearningGroup/SND}.
Region-level Active Learning for Cluttered Scenes
Aug 20, 2021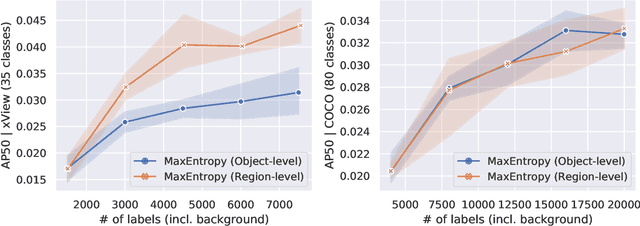
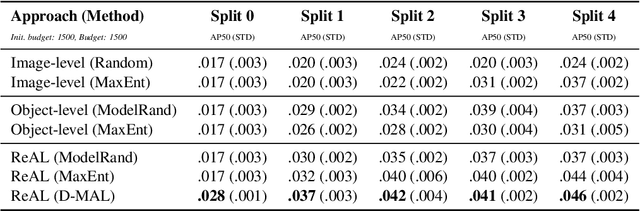
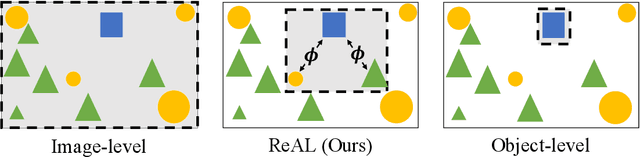
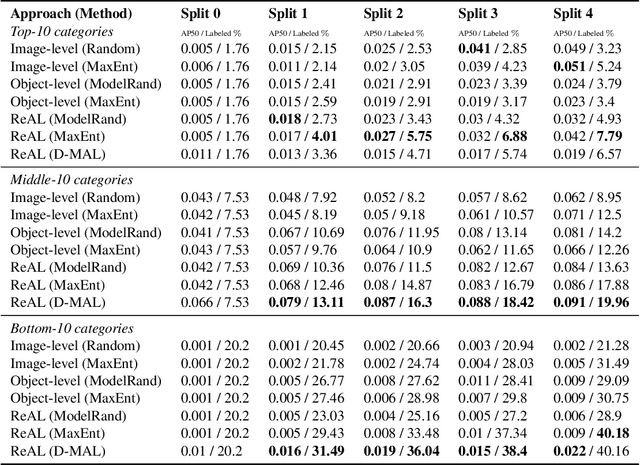
Active learning for object detection is conventionally achieved by applying techniques developed for classification in a way that aggregates individual detections into image-level selection criteria. This is typically coupled with the costly assumption that every image selected for labelling must be exhaustively annotated. This yields incremental improvements on well-curated vision datasets and struggles in the presence of data imbalance and visual clutter that occurs in real-world imagery. Alternatives to the image-level approach are surprisingly under-explored in the literature. In this work, we introduce a new strategy that subsumes previous Image-level and Object-level approaches into a generalized, Region-level approach that promotes spatial-diversity by avoiding nearby redundant queries from the same image and minimizes context-switching for the labeler. We show that this approach significantly decreases labeling effort and improves rare object search on realistic data with inherent class-imbalance and cluttered scenes.
Early Convolutions Help Transformers See Better
Jul 12, 2021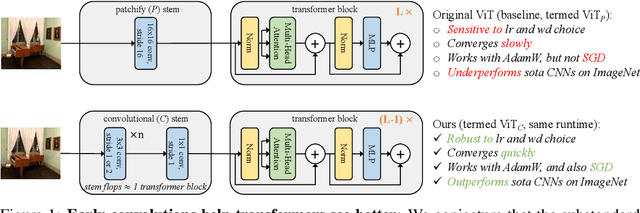

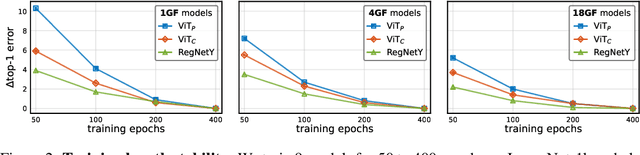
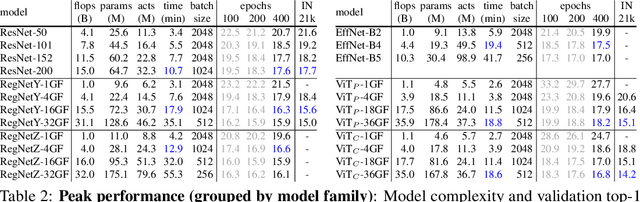
Vision transformer (ViT) models exhibit substandard optimizability. In particular, they are sensitive to the choice of optimizer (AdamW vs. SGD), optimizer hyperparameters, and training schedule length. In comparison, modern convolutional neural networks are far easier to optimize. Why is this the case? In this work, we conjecture that the issue lies with the patchify stem of ViT models, which is implemented by a stride-p pxp convolution (p=16 by default) applied to the input image. This large-kernel plus large-stride convolution runs counter to typical design choices of convolutional layers in neural networks. To test whether this atypical design choice causes an issue, we analyze the optimization behavior of ViT models with their original patchify stem versus a simple counterpart where we replace the ViT stem by a small number of stacked stride-two 3x3 convolutions. While the vast majority of computation in the two ViT designs is identical, we find that this small change in early visual processing results in markedly different training behavior in terms of the sensitivity to optimization settings as well as the final model accuracy. Using a convolutional stem in ViT dramatically increases optimization stability and also improves peak performance (by ~1-2% top-1 accuracy on ImageNet-1k), while maintaining flops and runtime. The improvement can be observed across the wide spectrum of model complexities (from 1G to 36G flops) and dataset scales (from ImageNet-1k to ImageNet-21k). These findings lead us to recommend using a standard, lightweight convolutional stem for ViT models as a more robust architectural choice compared to the original ViT model design.