 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightRNN: Memory and Computation-Efficient Recurrent Neural Networks
Oct 31, 2016



Recurrent neural networks (RNNs) have achieved state-of-the-art performances in many natural language processing tasks, such as language modeling and machine translation. However, when the vocabulary is large, the RNN model will become very big (e.g., possibly beyond the memory capacity of a GPU device) and its training will become very inefficient. In this work, we propose a novel technique to tackle this challenge. The key idea is to use 2-Component (2C) shared embedding for word representations. We allocate every word in the vocabulary into a table, each row of which is associated with a vector, and each column associated with another vector. Depending on its position in the table, a word is jointly represented by two components: a row vector and a column vector. Since the words in the same row share the row vector and the words in the same column share the column vector, we only need $2 \sqrt{|V|}$ vectors to represent a vocabulary of $|V|$ unique words, which are far less than the $|V|$ vectors required by existing approaches. Based on the 2-Component shared embedding, we design a new RNN algorithm and evaluate it using the language modeling task on several benchmark datasets. The results show that our algorithm significantly reduces the model size and speeds up the training process, without sacrifice of accuracy (it achieves similar, if not better, perplexity as compared to state-of-the-art language models). Remarkably, on the One-Billion-Word benchmark Dataset, our algorithm achieves comparable perplexity to previous language models, whilst reducing the model size by a factor of 40-100, and speeding up the training process by a factor of 2. We name our proposed algorithm \emph{LightRNN} to reflect its very small model size and very high training speed.
Asynchronous Stochastic Proximal Optimization Algorithms with Variance Reduction
Sep 27, 2016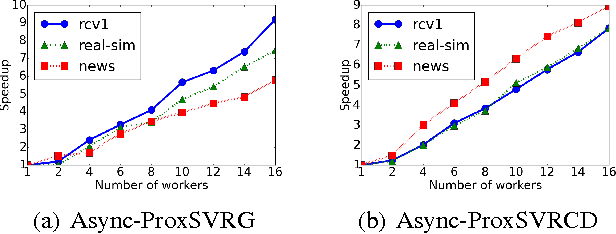

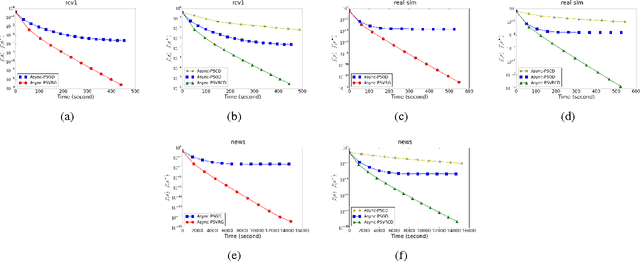
Regularized empirical risk minimization (R-ERM) is an important branch of machine learning, since it constrains the capacity of the hypothesis space and guarantees the generalization ability of the learning algorithm. Two classic proximal optimization algorithms, i.e., proximal stochastic gradient descent (ProxSGD) and proximal stochastic coordinate descent (ProxSCD) have been widely used to solve the R-ERM problem. Recently, variance reduction technique was proposed to improve ProxSGD and ProxSCD, and the corresponding ProxSVRG and ProxSVRCD have better convergence rate. These proximal algorithms with variance reduction technique have also achieved great success in applications at small and moderate scales. However, in order to solve large-scale R-ERM problems and make more practical impacts, the parallel version of these algorithms are sorely needed. In this paper, we propose asynchronous ProxSVRG (Async-ProxSVRG) and asynchronous ProxSVRCD (Async-ProxSVRCD) algorithms, and prove that Async-ProxSVRG can achieve near linear speedup when the training data is sparse, while Async-ProxSVRCD can achieve near linear speedup regardless of the sparse condition, as long as the number of block partitions are appropriately set. We have conducted experiments on a regularized logistic regression task. The results verified our theoretical findings and demonstrated the practical efficiency of the asynchronous stochastic proximal algorithms with variance reduction.
Generalization Error Bounds for Optimization Algorithms via Stability
Sep 27, 2016
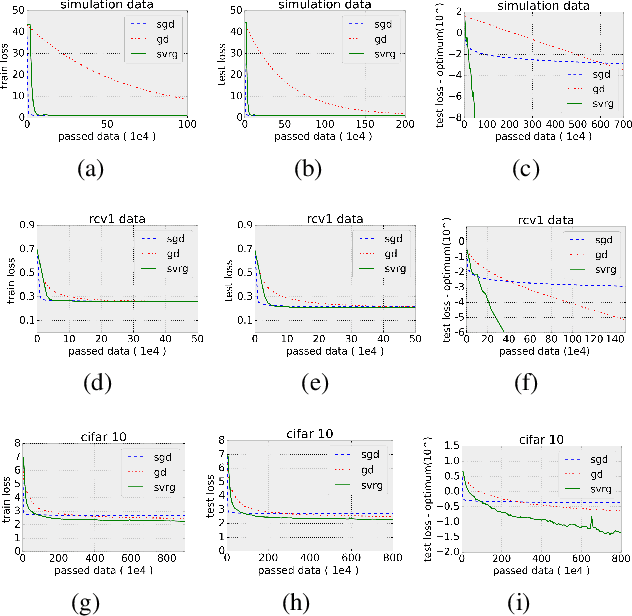
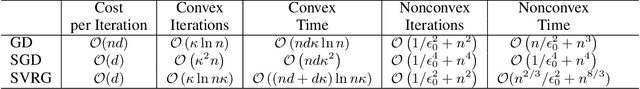
Many machine learning tasks can be formulated as Regularized Empirical Risk Minimization (R-ERM), and solved by optimization algorithms such as gradient descent (GD), stochastic gradient descent (SGD), and stochastic variance reduction (SVRG). Conventional analysis on these optimization algorithms focuses on their convergence rates during the training process, however, people in the machine learning community may care more about the generalization performance of the learned model on unseen test data. In this paper, we investigate on this issue, by using stability as a tool. In particular, we decompose the generalization error for R-ERM, and derive its upper bound for both convex and non-convex cases. In convex cases, we prove that the generalization error can be bounded by the convergence rate of the optimization algorithm and the stability of the R-ERM process, both in expectation (in the order of $\mathcal{O}((1/n)+\mathbb{E}\rho(T))$, where $\rho(T)$ is the convergence error and $T$ is the number of iterations) and in high probability (in the order of $\mathcal{O}\left(\frac{\log{1/\delta}}{\sqrt{n}}+\rho(T)\right)$ with probability $1-\delta$). For non-convex cases, we can also obtain a similar expected generalization error bound. Our theorems indicate that 1) along with the training process, the generalization error will decrease for all the optimization algorithms under our investigation; 2) Comparatively speaking, SVRG has better generalization ability than GD and SGD. We have conducted experiments on both convex and non-convex problems, and the experimental results verify our theoretical findings.
Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding
Apr 26, 2016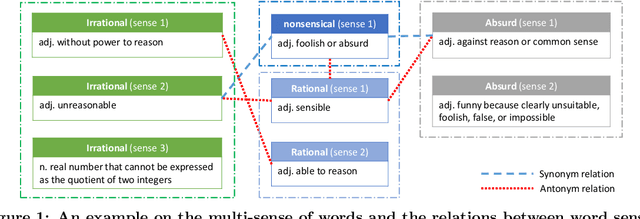
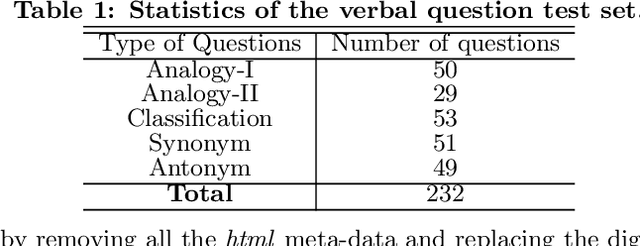
Intelligence Quotient (IQ) Test is a set of standardized questions designed to evaluate human intelligence. Verbal comprehension questions appear very frequently in IQ tests, which measure human's verbal ability including the understanding of the words with multiple senses, the synonyms and antonyms, and the analogies among words. In this work, we explore whether such tests can be solved automatically by artificial intelligence technologies, especially the deep learning technologies that are recently developed and successfully applied in a number of fields. However, we found that the task was quite challenging, and simply applying existing technologies (e.g., word embedding) could not achieve a good performance, mainly due to the multiple senses of words and the complex relations among words. To tackle these challenges, we propose a novel framework consisting of three components. First, we build a classifier to recognize the specific type of a verbal question (e.g., analogy, classification, synonym, or antonym). Second, we obtain distributed representations of words and relations by leveraging a novel word embedding method that considers the multi-sense nature of words and the relational knowledge among words (or their senses) contained in dictionaries. Third, for each type of questions, we propose a specific solver based on the obtained distributed word representations and relation representations. Experimental results have shown that the proposed framework can not only outperform existing methods for solving verbal comprehension questions but also exceed the average performance of the Amazon Mechanical Turk workers involved in the study. The results indicate that with appropriate uses of the deep learning technologies we might be a further step closer to the human intelligence.
Sentence Level Recurrent Topic Model: Letting Topics Speak for Themselves
Apr 08, 2016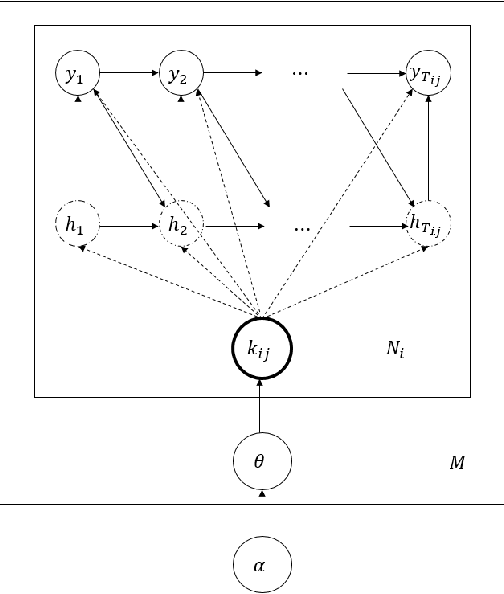
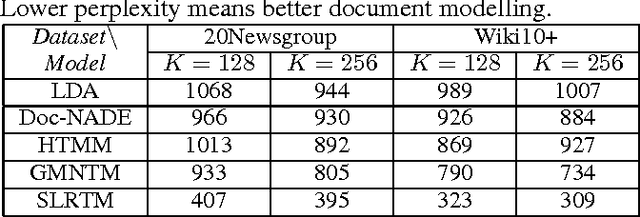
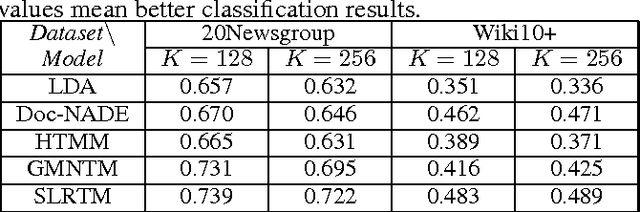
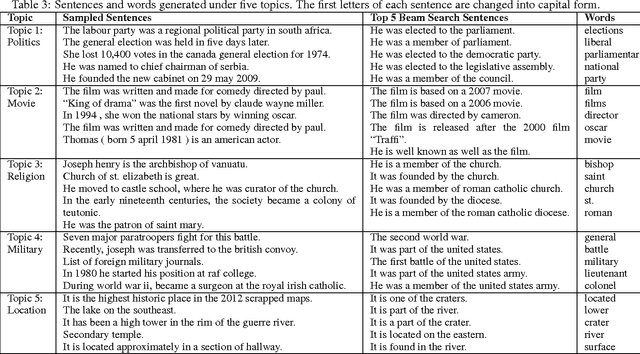
We propose Sentence Level Recurrent Topic Model (SLRTM), a new topic model that assumes the generation of each word within a sentence to depend on both the topic of the sentence and the whole history of its preceding words in the sentence. Different from conventional topic models that largely ignore the sequential order of words or their topic coherence, SLRTM gives full characterization to them by using a Recurrent Neural Networks (RNN) based framework. Experimental results have shown that SLRTM outperforms several strong baselines on various tasks. Furthermore, SLRTM can automatically generate sentences given a topic (i.e., topics to sentences), which is a key technology for real world applications such as personalized short text conversation.
On the Depth of Deep Neural Networks: A Theoretical View
Nov 28, 2015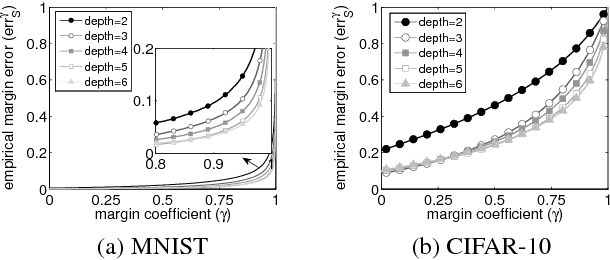

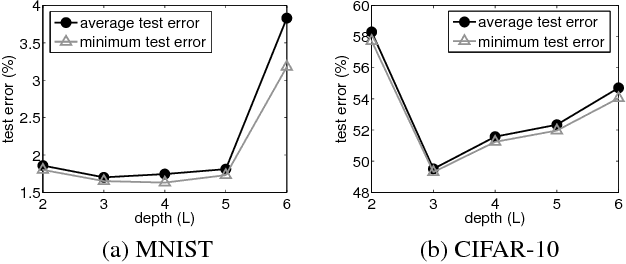
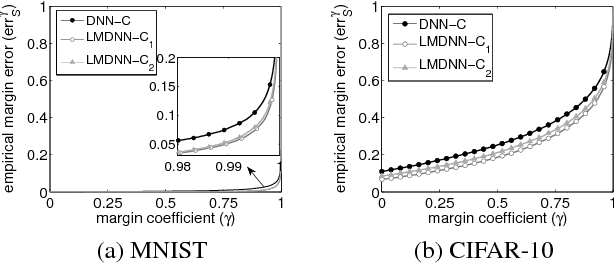
People believe that depth plays an important role in success of deep neural networks (DNN). However, this belief lacks solid theoretical justifications as far as we know. We investigate role of depth from perspective of margin bound. In margin bound, expected error is upper bounded by empirical margin error plus Rademacher Average (RA) based capacity term. First, we derive an upper bound for RA of DNN, and show that it increases with increasing depth. This indicates negative impact of depth on test performance. Second, we show that deeper networks tend to have larger representation power (measured by Betti numbers based complexity) than shallower networks in multi-class setting, and thus can lead to smaller empirical margin error. This implies positive impact of depth. The combination of these two results shows that for DNN with restricted number of hidden units, increasing depth is not always good since there is a tradeoff between positive and negative impacts. These results inspire us to seek alternative ways to achieve positive impact of depth, e.g., imposing margin-based penalty terms to cross entropy loss so as to reduce empirical margin error without increasing depth. Our experiments show that in this way, we achieve significantly better test performance.
Learning Better Word Embedding by Asymmetric Low-Rank Projection of Knowledge Graph
Jun 14, 2015
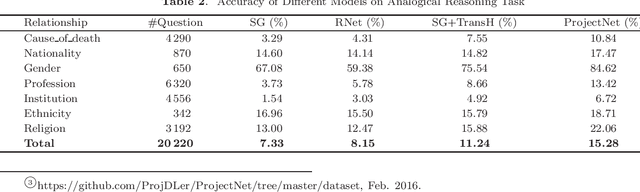
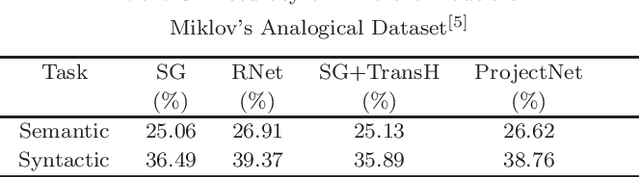
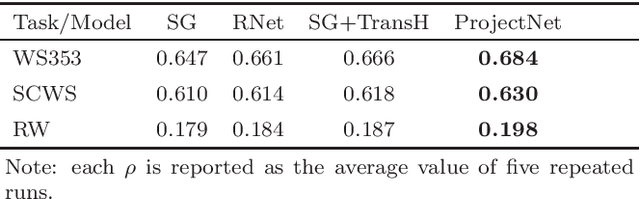
Word embedding, which refers to low-dimensional dense vector representations of natural words, has demonstrated its power in many natural language processing tasks. However, it may suffer from the inaccurate and incomplete information contained in the free text corpus as training data. To tackle this challenge, there have been quite a few works that leverage knowledge graphs as an additional information source to improve the quality of word embedding. Although these works have achieved certain success, they have neglected some important facts about knowledge graphs: (i) many relationships in knowledge graphs are \emph{many-to-one}, \emph{one-to-many} or even \emph{many-to-many}, rather than simply \emph{one-to-one}; (ii) most head entities and tail entities in knowledge graphs come from very different semantic spaces. To address these issues, in this paper, we propose a new algorithm named ProjectNet. ProjecNet models the relationships between head and tail entities after transforming them with different low-rank projection matrices. The low-rank projection can allow non \emph{one-to-one} relationships between entities, while different projection matrices for head and tail entities allow them to originate in different semantic spaces. The experimental results demonstrate that ProjectNet yields more accurate word embedding than previous works, thus leads to clear improvements in various natural language processing tasks.
Thompson Sampling for Budgeted Multi-armed Bandits
May 01, 2015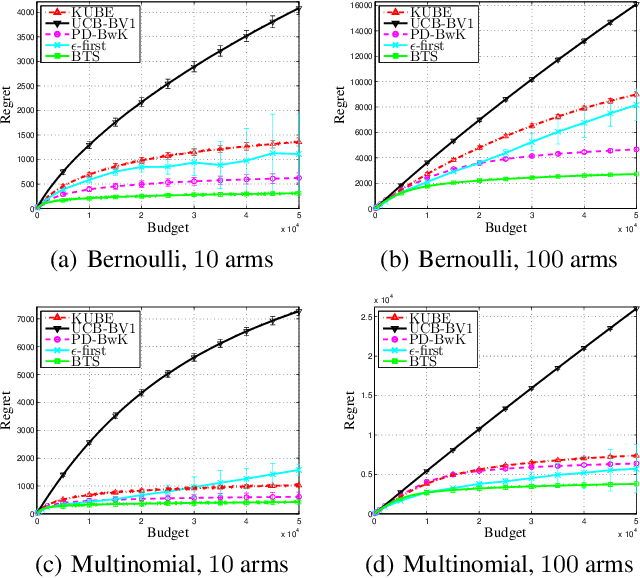
Thompson sampling is one of the earliest randomized algorithms for multi-armed bandits (MAB). In this paper, we extend the Thompson sampling to Budgeted MAB, where there is random cost for pulling an arm and the total cost is constrained by a budget. We start with the case of Bernoulli bandits, in which the random rewards (costs) of an arm are independently sampled from a Bernoulli distribution. To implement the Thompson sampling algorithm in this case, at each round, we sample two numbers from the posterior distributions of the reward and cost for each arm, obtain their ratio, select the arm with the maximum ratio, and then update the posterior distributions. We prove that the distribution-dependent regret bound of this algorithm is $O(\ln B)$, where $B$ denotes the budget. By introducing a Bernoulli trial, we further extend this algorithm to the setting that the rewards (costs) are drawn from general distributions, and prove that its regret bound remains almost the same. Our simulation results demonstrate the effectiveness of the proposed algorithm.
LightLDA: Big Topic Models on Modest Compute Clusters
Dec 04, 2014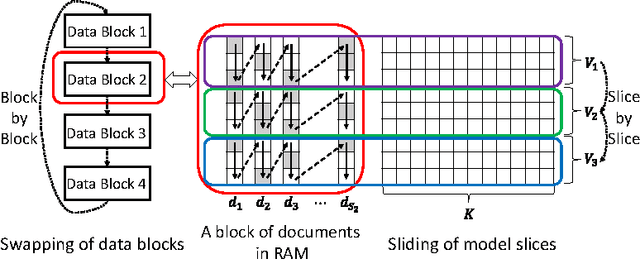

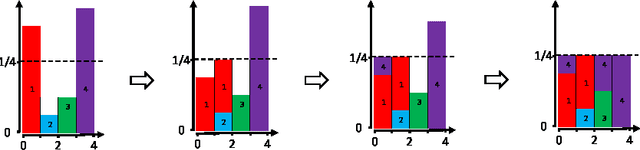
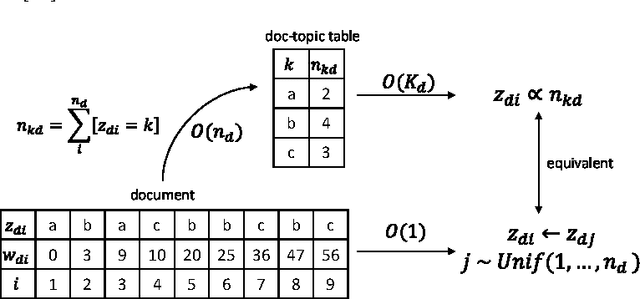
When building large-scale machine learning (ML) programs, such as big topic models or deep neural nets, one usually assumes such tasks can only be attempted with industrial-sized clusters with thousands of nodes, which are out of reach for most practitioners or academic researchers. We consider this challenge in the context of topic modeling on web-scale corpora, and show that with a modest cluster of as few as 8 machines, we can train a topic model with 1 million topics and a 1-million-word vocabulary (for a total of 1 trillion parameters), on a document collection with 200 billion tokens -- a scale not yet reported even with thousands of machines. Our major contributions include: 1) a new, highly efficient O(1) Metropolis-Hastings sampling algorithm, whose running cost is (surprisingly) agnostic of model size, and empirically converges nearly an order of magnitude faster than current state-of-the-art Gibbs samplers; 2) a structure-aware model-parallel scheme, which leverages dependencies within the topic model, yielding a sampling strategy that is frugal on machine memory and network communication; 3) a differential data-structure for model storage, which uses separate data structures for high- and low-frequency words to allow extremely large models to fit in memory, while maintaining high inference speed; and 4) a bounded asynchronous data-parallel scheme, which allows efficient distributed processing of massive data via a parameter server. Our distribution strategy is an instance of the model-and-data-parallel programming model underlying the Petuum framework for general distributed ML, and was implemented on top of the Petuum open-source system. We provide experimental evidence showing how this development puts massive models within reach on a small cluster while still enjoying proportional time cost reductions with increasing cluster size, in comparison with alternative options.
Generalization Analysis for Game-Theoretic Machine Learning
Oct 09, 2014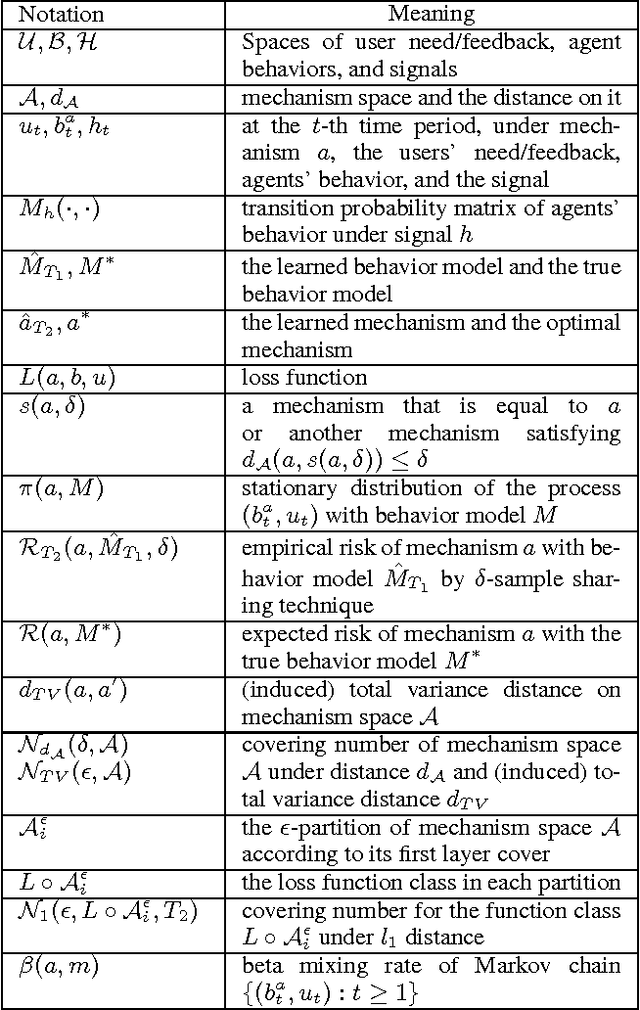
For Internet applications like sponsored search, cautions need to be taken when using machine learning to optimize their mechanisms (e.g., auction) since self-interested agents in these applications may change their behaviors (and thus the data distribution) in response to the mechanisms. To tackle this problem, a framework called game-theoretic machine learning (GTML) was recently proposed, which first learns a Markov behavior model to characterize agents' behaviors, and then learns the optimal mechanism by simulating agents' behavior changes in response to the mechanism. While GTML has demonstrated practical success, its generalization analysis is challenging because the behavior data are non-i.i.d. and dependent on the mechanism. To address this challenge, first, we decompose the generalization error for GTML into the behavior learning error and the mechanism learning error; second, for the behavior learning error, we obtain novel non-asymptotic error bounds for both parametric and non-parametric behavior learning methods; third, for the mechanism learning error, we derive a uniform convergence bound based on a new concept called nested covering number of the mechanism space and the generalization analysis techniques developed for mixing sequences. To the best of our knowledge, this is the first work on the generalization analysis of GTML, and we believe it has general implications to the theoretical analysis of other complicated machine learning problems.