 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Nov 07, 2024



Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they require significantly more memory and suffer from higher latency, posing substantial challenges for deployment. In this work, we aim to accelerate diffusion models by quantizing their weights and activations to 4 bits. At such an aggressive level, both weights and activations are highly sensitive, where conventional post-training quantization methods for large language models like smoothing become insufficient. To overcome this limitation, we propose SVDQuant, a new 4-bit quantization paradigm. Different from smoothing which redistributes outliers between weights and activations, our approach absorbs these outliers using a low-rank branch. We first consolidate the outliers by shifting them from activations to weights, then employ a high-precision low-rank branch to take in the weight outliers with Singular Value Decomposition (SVD). This process eases the quantization on both sides. However, na\"{\i}vely running the low-rank branch independently incurs significant overhead due to extra data movement of activations, negating the quantization speedup. To address this, we co-design an inference engine Nunchaku that fuses the kernels of the low-rank branch into those of the low-bit branch to cut off redundant memory access. It can also seamlessly support off-the-shelf low-rank adapters (LoRAs) without the need for re-quantization. Extensive experiments on SDXL, PixArt-$\Sigma$, and FLUX.1 validate the effectiveness of SVDQuant in preserving image quality. We reduce the memory usage for the 12B FLUX.1 models by 3.5$\times$, achieving 3.0$\times$ speedup over the 4-bit weight-only quantized baseline on the 16GB laptop 4090 GPU, paving the way for more interactive applications on PCs. Our quantization library and inference engine are open-sourced.
Training-Free Activation Sparsity in Large Language Models
Aug 26, 2024Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$\times$ and 1.8$\times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
FlexAttention for Efficient High-Resolution Vision-Language Models
Jul 29, 2024



Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.
Incremental Comprehension of Garden-Path Sentences by Large Language Models: Semantic Interpretation, Syntactic Re-Analysis, and Attention
May 25, 2024



When reading temporarily ambiguous garden-path sentences, misinterpretations sometimes linger past the point of disambiguation. This phenomenon has traditionally been studied in psycholinguistic experiments using online measures such as reading times and offline measures such as comprehension questions. Here, we investigate the processing of garden-path sentences and the fate of lingering misinterpretations using four large language models (LLMs): GPT-2, LLaMA-2, Flan-T5, and RoBERTa. The overall goal is to evaluate whether humans and LLMs are aligned in their processing of garden-path sentences and in the lingering misinterpretations past the point of disambiguation, especially when extra-syntactic information (e.g., a comma delimiting a clause boundary) is present to guide processing. We address this goal using 24 garden-path sentences that have optional transitive and reflexive verbs leading to temporary ambiguities. For each sentence, there are a pair of comprehension questions corresponding to the misinterpretation and the correct interpretation. In three experiments, we (1) measure the dynamic semantic interpretations of LLMs using the question-answering task; (2) track whether these models shift their implicit parse tree at the point of disambiguation (or by the end of the sentence); and (3) visualize the model components that attend to disambiguating information when processing the question probes. These experiments show promising alignment between humans and LLMs in the processing of garden-path sentences, especially when extra-syntactic information is available to guide processing.
SnapKV: LLM Knows What You are Looking for Before Generation
Apr 22, 2024



Large Language Models (LLMs) have made remarkable progress in processing extensive contexts, with the Key-Value (KV) cache playing a vital role in enhancing their performance. However, the growth of the KV cache in response to increasing input length poses challenges to memory and time efficiency. To address this problem, this paper introduces SnapKV, an innovative and fine-tuning-free approach that efficiently minimizes KV cache size while still delivering comparable performance in real-world applications. We discover that each attention head in the model consistently focuses on specific prompt attention features during generation. Meanwhile, this robust pattern can be obtained from an `observation' window located at the end of the prompts. Drawing on this insight, SnapKV automatically compresses KV caches by selecting clustered important KV positions for each attention head. Our approach significantly reduces the growing computational overhead and memory footprint when processing long input sequences. Specifically, SnapKV achieves a consistent decoding speed with a 3.6x increase in generation speed and an 8.2x enhancement in memory efficiency compared to baseline when processing inputs of 16K tokens. At the same time, it maintains comparable performance to baseline models across 16 long sequence datasets. Moreover, SnapKV can process up to 380K context tokens on a single A100-80GB GPU using HuggingFace implementation with minor changes, exhibiting only a negligible accuracy drop in the Needle-in-a-Haystack test. Further comprehensive studies suggest SnapKV's potential for practical applications.
JetMoE: Reaching Llama2 Performance with 0.1M Dollars
Apr 11, 2024



Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces JetMoE-8B, a new LLM trained with less than $0.1 million, using 1.25T tokens from carefully mixed open-source corpora and 30,000 H100 GPU hours. Despite its low cost, the JetMoE-8B demonstrates impressive performance, with JetMoE-8B outperforming the Llama2-7B model and JetMoE-8B-Chat surpassing the Llama2-13B-Chat model. These results suggest that LLM training can be much more cost-effective than generally thought. JetMoE-8B is based on an efficient Sparsely-gated Mixture-of-Experts (SMoE) architecture, composed of attention and feedforward experts. Both layers are sparsely activated, allowing JetMoE-8B to have 8B parameters while only activating 2B for each input token, reducing inference computation by about 70% compared to Llama2-7B. Moreover, JetMoE-8B is highly open and academia-friendly, using only public datasets and training code. All training parameters and data mixtures have been detailed in this report to facilitate future efforts in the development of open foundation models. This transparency aims to encourage collaboration and further advancements in the field of accessible and efficient LLMs. The model weights are publicly available at https://github.com/myshell-ai/JetMoE.
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Mar 07, 2024



Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
Accelerating Greedy Coordinate Gradient via Probe Sampling
Mar 02, 2024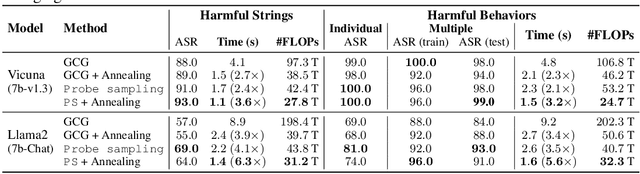
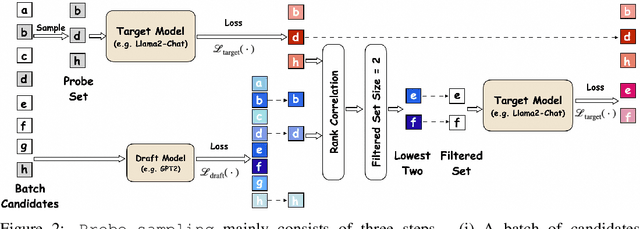

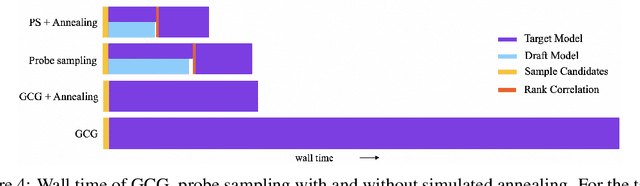
Safety of Large Language Models (LLMs) has become a central issue given their rapid progress and wide applications. Greedy Coordinate Gradient (GCG) is shown to be effective in constructing prompts containing adversarial suffixes to break the presumingly safe LLMs, but the optimization of GCG is time-consuming and limits its practicality. To reduce the time cost of GCG and enable more comprehensive studies of LLM safety, in this work, we study a new algorithm called $\texttt{Probe sampling}$ to accelerate the GCG algorithm. At the core of the algorithm is a mechanism that dynamically determines how similar a smaller draft model's predictions are to the target model's predictions for prompt candidates. When the target model is similar to the draft model, we rely heavily on the draft model to filter out a large number of potential prompt candidates to reduce the computation time. Probe sampling achieves up to $5.6$ times speedup using Llama2-7b and leads to equal or improved attack success rate (ASR) on the AdvBench.
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Feb 28, 2024Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it's intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, which can also be translated to enhanced generation latency in multi-tenant settings. We validate BitDelta through experiments across Llama-2 and Mistral model families, and on models up to 70B parameters, showcasing minimal performance degradation over all tested settings.
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Jan 19, 2024



The inference process in Large Language Models (LLMs) is often limited due to the absence of parallelism in the auto-regressive decoding process, resulting in most operations being restricted by the memory bandwidth of accelerators. While methods such as speculative decoding have been suggested to address this issue, their implementation is impeded by the challenges associated with acquiring and maintaining a separate draft model. In this paper, we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. Using a tree-based attention mechanism, Medusa constructs multiple candidate continuations and verifies them simultaneously in each decoding step. By leveraging parallel processing, Medusa introduces only minimal overhead in terms of single-step latency while substantially reducing the number of decoding steps required. We present two levels of fine-tuning procedures for Medusa to meet the needs of different use cases: Medusa-1: Medusa is directly fine-tuned on top of a frozen backbone LLM, enabling lossless inference acceleration. Medusa-2: Medusa is fine-tuned together with the backbone LLM, enabling better prediction accuracy of Medusa heads and higher speedup but needing a special training recipe that preserves the backbone model's capabilities. Moreover, we propose several extensions that improve or expand the utility of Medusa, including a self-distillation to handle situations where no training data is available and a typical acceptance scheme to boost the acceptance rate while maintaining generation quality. We evaluate Medusa on models of various sizes and training procedures. Our experiments demonstrate that Medusa-1 can achieve over 2.2x speedup without compromising generation quality, while Medusa-2 further improves the speedup to 2.3-3.6x.