 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Clustering with Mean Teacher for Semi-supervised Learning
Apr 20, 2020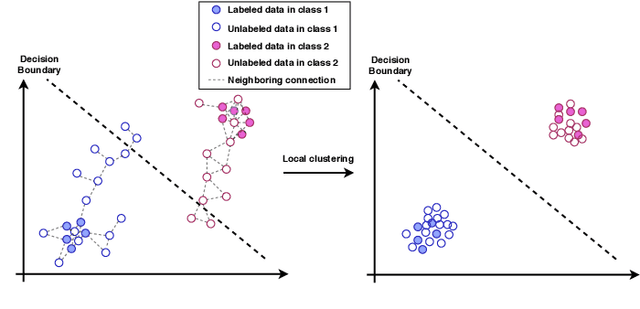
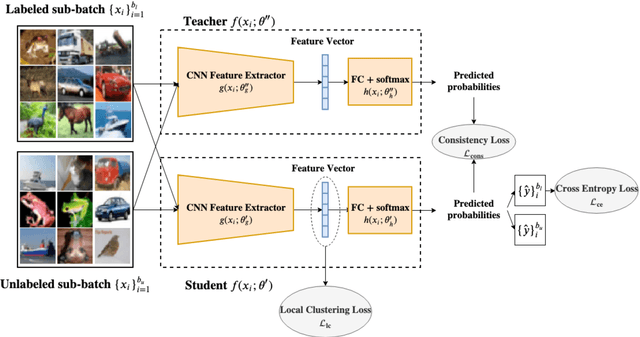
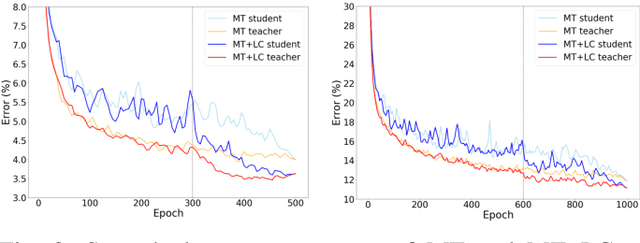
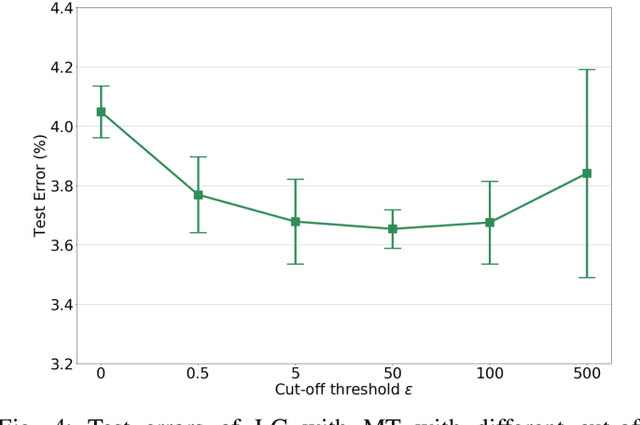
The Mean Teacher (MT) model of Tarvainen and Valpola has shown favorable performance on several semi-supervised benchmark datasets. MT maintains a teacher model's weights as the exponential moving average of a student model's weights and minimizes the divergence between their probability predictions under diverse perturbations of the inputs. However, MT is known to suffer from confirmation bias, that is, reinforcing incorrect teacher model predictions. In this work, we propose a simple yet effective method called Local Clustering (LC) to mitigate the effect of confirmation bias. In MT, each data point is considered independent of other points during training; however, data points are likely to be close to each other in feature space if they share similar features. Motivated by this, we cluster data points locally by minimizing the pairwise distance between neighboring data points in feature space. Combined with a standard classification cross-entropy objective on labeled data points, the misclassified unlabeled data points are pulled towards high-density regions of their correct class with the help of their neighbors, thus improving model performance. We demonstrate on semi-supervised benchmark datasets SVHN and CIFAR-10 that adding our LC loss to MT yields significant improvements compared to MT and performance comparable to the state of the art in semi-supervised learning.
Learning Layout and Style Reconfigurable GANs for Controllable Image Synthesis
Mar 25, 2020With the remarkable recent progress on learning deep generative models, it becomes increasingly interesting to develop models for controllable image synthesis from reconfigurable inputs. This paper focuses on a recent emerged task, layout-to-image, to learn generative models that are capable of synthesizing photo-realistic images from spatial layout (i.e., object bounding boxes configured in an image lattice) and style (i.e., structural and appearance variations encoded by latent vectors). This paper first proposes an intuitive paradigm for the task, layout-to-mask-to-image, to learn to unfold object masks of given bounding boxes in an input layout to bridge the gap between the input layout and synthesized images. Then, this paper presents a method built on Generative Adversarial Networks for the proposed layout-to-mask-to-image with style control at both image and mask levels. Object masks are learned from the input layout and iteratively refined along stages in the generator network. Style control at the image level is the same as in vanilla GANs, while style control at the object mask level is realized by a proposed novel feature normalization scheme, Instance-Sensitive and Layout-Aware Normalization. In experiments, the proposed method is tested in the COCO-Stuff dataset and the Visual Genome dataset with state-of-the-art performance obtained.
Holistically-Attracted Wireframe Parsing
Mar 03, 2020
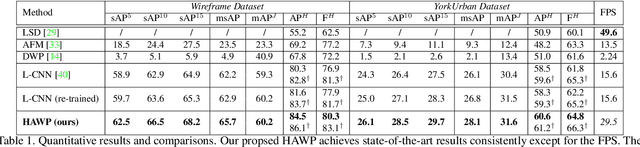
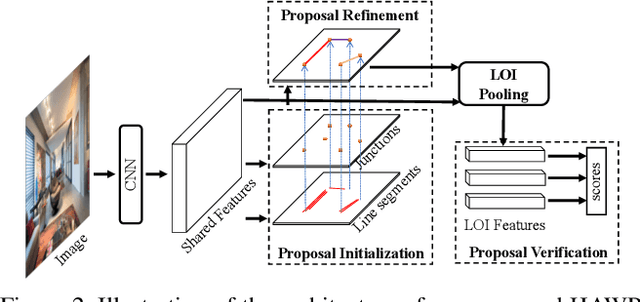
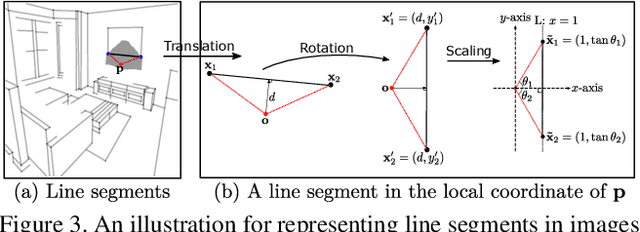
This paper presents a fast and parsimonious parsing method to accurately and robustly detect a vectorized wireframe in an input image with a single forward pass. The proposed method is end-to-end trainable, consisting of three components: (i) line segment and junction proposal generation, (ii) line segment and junction matching, and (iii) line segment and junction verification. For computing line segment proposals, a novel exact dual representation is proposed which exploits a parsimonious geometric reparameterization for line segments and forms a holistic 4-dimensional attraction field map for an input image. Junctions can be treated as the "basins" in the attraction field. The proposed method is thus called Holistically-Attracted Wireframe Parser (HAWP). In experiments, the proposed method is tested on two benchmarks, the Wireframe dataset, and the YorkUrban dataset. On both benchmarks, it obtains state-of-the-art performance in terms of accuracy and efficiency. For example, on the Wireframe dataset, compared to the previous state-of-the-art method L-CNN, it improves the challenging mean structural average precision (msAP) by a large margin ($2.8\%$ absolute improvements) and achieves 29.5 FPS on single GPU ($89\%$ relative improvement). A systematic ablation study is performed to further justify the proposed method.
Stochastic-Sign SGD for Federated Learning with Theoretical Guarantees
Feb 25, 2020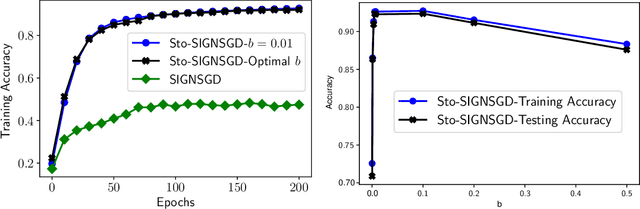
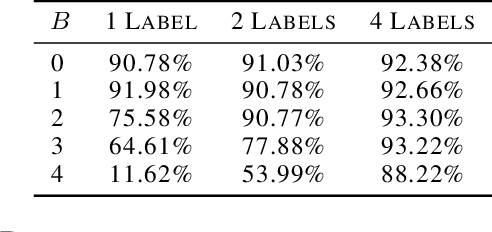
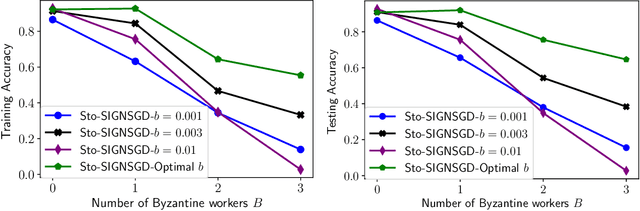
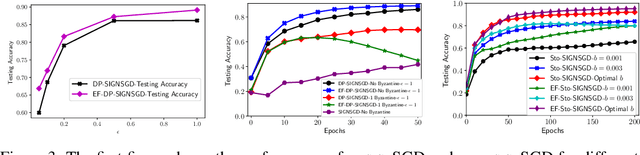
Federated learning (FL) has emerged as a prominent distributed learning paradigm. FL entails some pressing needs for developing novel parameter estimation approaches with theoretical guarantees of convergence, which are also communication efficient, differentially private and Byzantine resilient in the heterogeneous data distribution settings. Quantization-based SGD solvers have been widely adopted in FL and the recently proposed SIGNSGD with majority vote shows a promising direction. However, no existing methods enjoy all the aforementioned properties. In this paper, we propose an intuitively-simple yet theoretically-sound method based on SIGNSGD to bridge the gap. We present Stochastic-Sign SGD which utilizes novel stochastic-sign based gradient compressors enabling the aforementioned properties in a unified framework. We also present an error-feedback variant of the proposed Stochastic-Sign SGD which further improves the learning performance in FL. We test the proposed method with extensive experiments using deep neural networks on the MNIST dataset. The experimental results corroborate the effectiveness of the proposed method.
Learning Regional Attraction for Line Segment Detection
Dec 18, 2019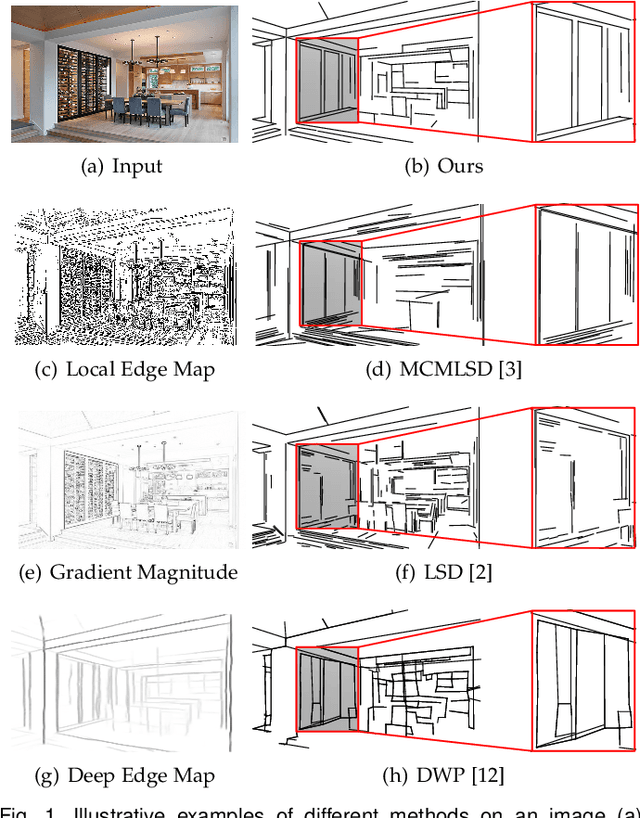
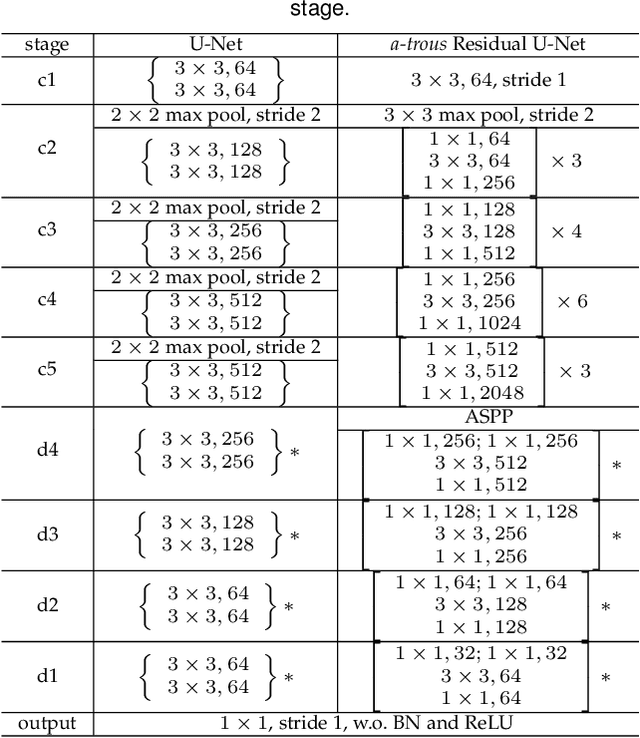
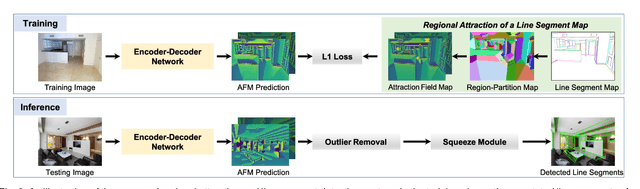
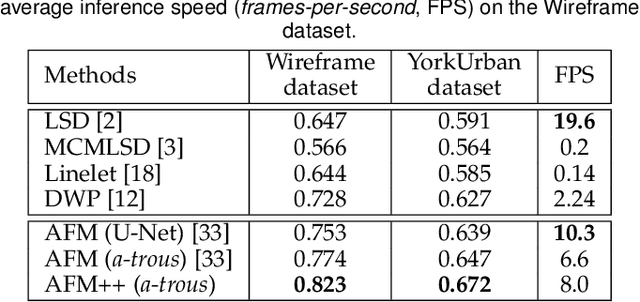
This paper presents regional attraction of line segment maps, and hereby poses the problem of line segment detection (LSD) as a problem of region coloring. Given a line segment map, the proposed regional attraction first establishes the relationship between line segments and regions in the image lattice. Based on this, the line segment map is equivalently transformed to an attraction field map (AFM), which can be remapped to a set of line segments without loss of information. Accordingly, we develop an end-to-end framework to learn attraction field maps for raw input images, followed by a squeeze module to detect line segments. Apart from existing works, the proposed detector properly handles the local ambiguity and does not rely on the accurate identification of edge pixels. Comprehensive experiments on the Wireframe dataset and the YorkUrban dataset demonstrate the superiority of our method. In particular, we achieve an F-measure of 0.831 on the Wireframe dataset, advancing the state-of-the-art performance by 10.3 percent.
Towards Interpretable Image Synthesis by Learning Sparsely Connected AND-OR Networks
Sep 10, 2019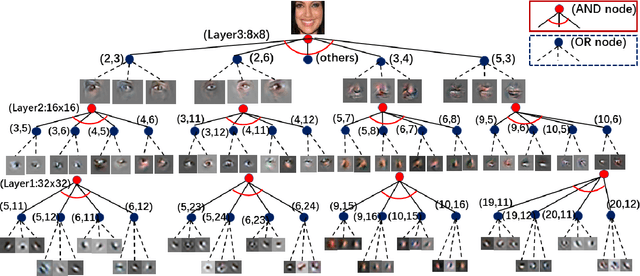

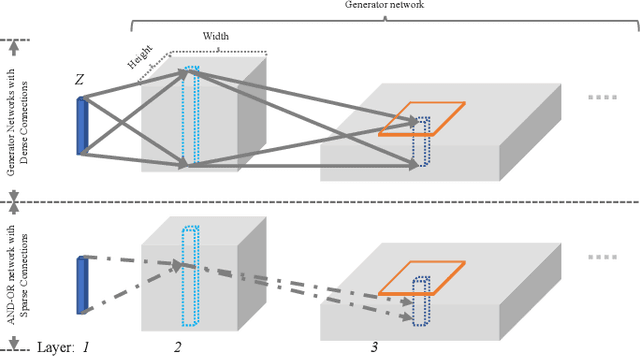

This paper proposes interpretable image synthesis by learning hierarchical AND-OR networks of sparsely connected semantically meaningful nodes. The proposed method is based on the compositionality and interpretability of scene-objects-parts-subparts-primitives hierarchy in image representation. A scene has different types (i.e., OR) each of which consists of a number of objects (i.e., AND). This can be recursively formulated across the scene-objects-parts-subparts hierarchy and is terminated at the primitive level (e.g., Gabor wavelets-like basis). To realize this interpretable AND-OR hierarchy in image synthesis, the proposed method consists of two components: (i) Each layer of the hierarchy is represented by an over-completed set of basis functions. The basis functions are instantiated using convolution to be translation covariant. Off-the-shelf convolutional neural architectures are then exploited to implement the hierarchy. (ii) Sparsity-inducing constraints are introduced in end-to-end training, which facilitate a sparsely connected AND-OR network to emerge from initially densely connected convolutional neural networks. A straightforward sparsity-inducing constraint is utilized, that is to only allow the top-$k$ basis functions to be active at each layer (where $k$ is a hyperparameter). The learned basis functions are also capable of image reconstruction to explain away input images. In experiments, the proposed method is tested on five benchmark datasets. The results show that meaningful and interpretable hierarchical representations are learned with better qualities of image synthesis and reconstruction obtained than state-of-the-art baselines.
Image Synthesis From Reconfigurable Layout and Style
Aug 20, 2019
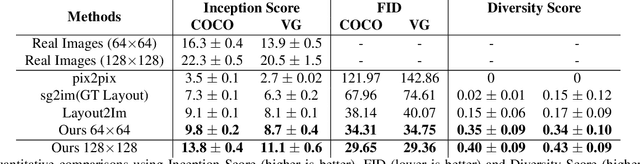
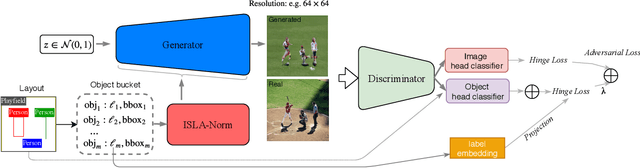
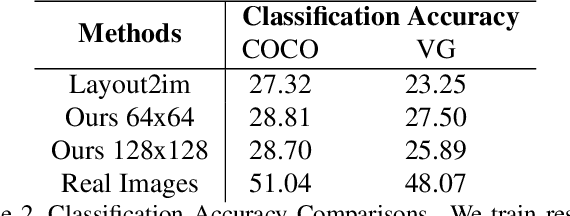
Despite remarkable recent progress on both unconditional and conditional image synthesis, it remains a long-standing problem to learn generative models that are capable of synthesizing realistic and sharp images from reconfigurable spatial layout (i.e., bounding boxes + class labels in an image lattice) and style (i.e., structural and appearance variations encoded by latent vectors), especially at high resolution. By reconfigurable, it means that a model can preserve the intrinsic one-to-many mapping from a given layout to multiple plausible images with different styles, and is adaptive with respect to perturbations of a layout and style latent code. In this paper, we present a layout- and style-based architecture for generative adversarial networks (termed LostGANs) that can be trained end-to-end to generate images from reconfigurable layout and style. Inspired by the vanilla StyleGAN, the proposed LostGAN consists of two new components: (i) learning fine-grained mask maps in a weakly-supervised manner to bridge the gap between layouts and images, and (ii) learning object instance-specific layout-aware feature normalization (ISLA-Norm) in the generator to realize multi-object style generation. In experiments, the proposed method is tested on the COCO-Stuff dataset and the Visual Genome dataset with state-of-the-art performance obtained. The code and pretrained models are available at \url{https://github.com/iVMCL/LostGANs}.
Attentive Normalization
Aug 04, 2019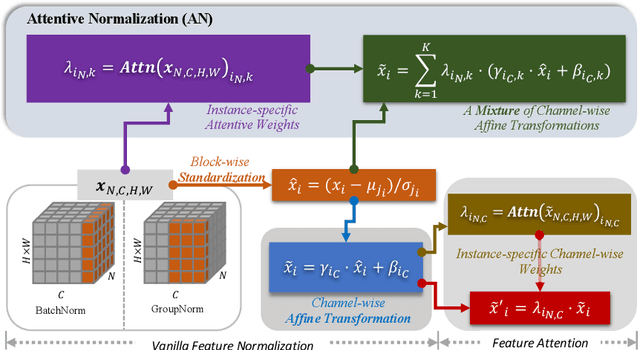
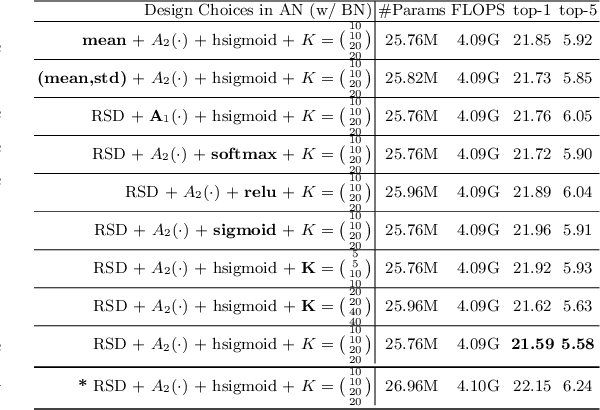
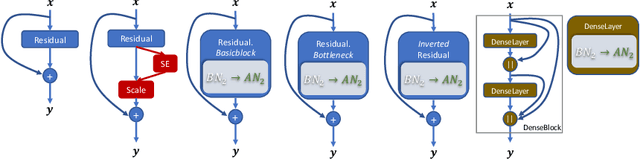
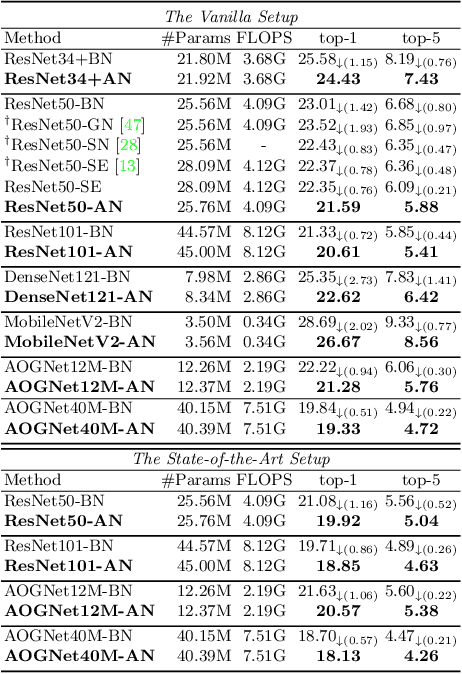
Batch Normalization (BN) is a vital pillar in the development of deep learning with many recent variations such as Group Normalization (GN) and Switchable Normalization. Channel-wise feature attention methods such as the squeeze-and-excitation (SE) unit have also shown impressive performance improvement. BN and its variants take into account different ways of computing the mean and variance within a min-batch for feature normalization, followed by a learnable channel-wise affine transformation. SE explicitly learns how to adaptively recalibrate channel-wise feature responses. They have been studied separately, however. In this paper, we propose a novel and lightweight integration of feature normalization and feature channel-wise attention. We present Attentive Normalization (AN) as a simple and unified alternative. AN absorbs SE into the affine transformation of BN. AN learns a small number of scale and offset parameters per channel (i.e., different affine transformations). Their weighted sums (i.e., mixture) are used in the final affine transformation. The weights are instance-specific and learned in a way that channel-wise attention is considered, similar in spirit to the squeeze module in the SE unit. AN is complementary and applicable to existing variants of BN. In experiments, we test AN in the ImageNet-1K classification dataset and the MS-COCO object detection and instance segmentation dataset with significantly better performance obtained than the vanilla BN. Our AN also outperforms two state-of-the-art variants of BN, GN and SN. The source code will be released at \url{http://github.com/ivMCL/AttentiveNorm}.
Pose Guided Fashion Image Synthesis Using Deep Generative Model
Jun 17, 2019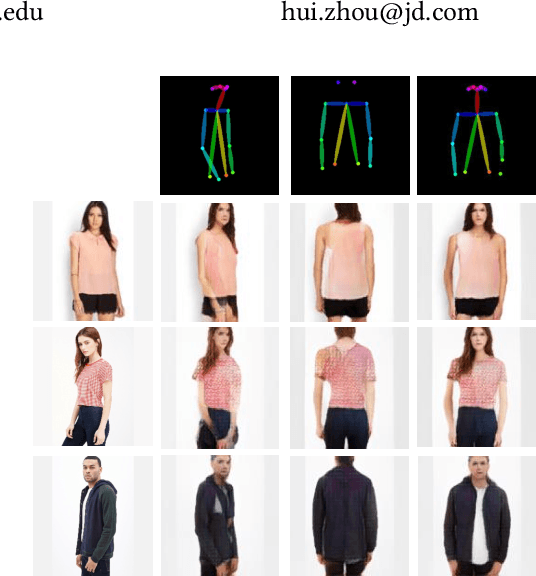
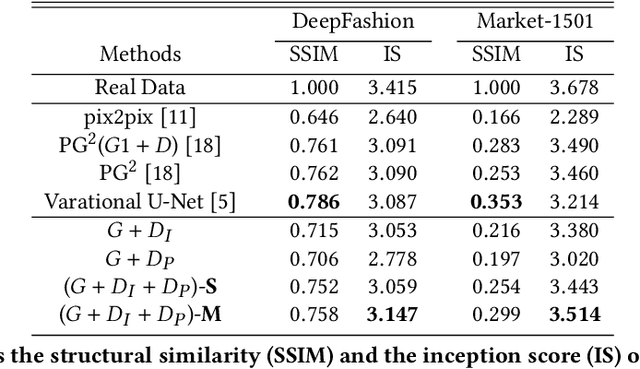
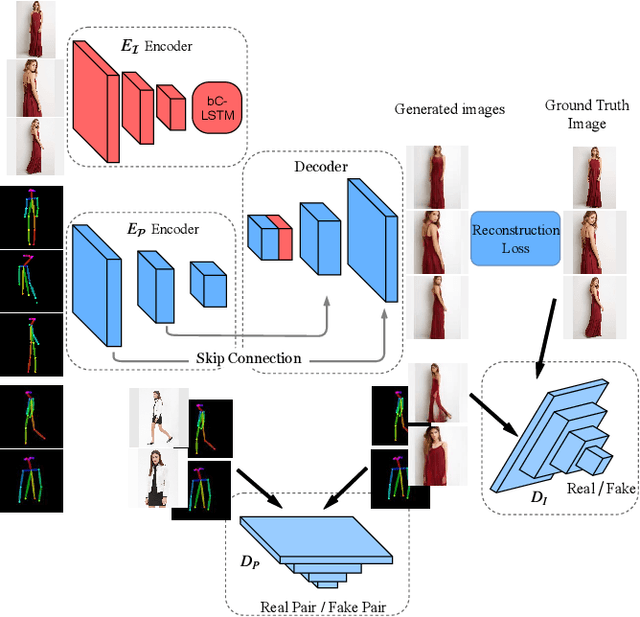

Generating a photorealistic image with intended human pose is a promising yet challenging research topic for many applications such as smart photo editing, movie making, virtual try-on, and fashion display. In this paper, we present a novel deep generative model to transfer an image of a person from a given pose to a new pose while keeping fashion item consistent. In order to formulate the framework, we employ one generator and two discriminators for image synthesis. The generator includes an image encoder, a pose encoder and a decoder. The two encoders provide good representation of visual and geometrical context which will be utilized by the decoder in order to generate a photorealistic image. Unlike existing pose-guided image generation models, we exploit two discriminators to guide the synthesis process where one discriminator differentiates between generated image and real images (training samples), and another discriminator verifies the consistency of appearance between a target pose and a generated image. We perform end-to-end training of the network to learn the parameters through back-propagation given ground-truth images. The proposed generative model is capable of synthesizing a photorealistic image of a person given a target pose. We have demonstrated our results by conducting rigorous experiments on two data sets, both quantitatively and qualitatively.
Adversarial Distillation for Ordered Top-k Attacks
May 25, 2019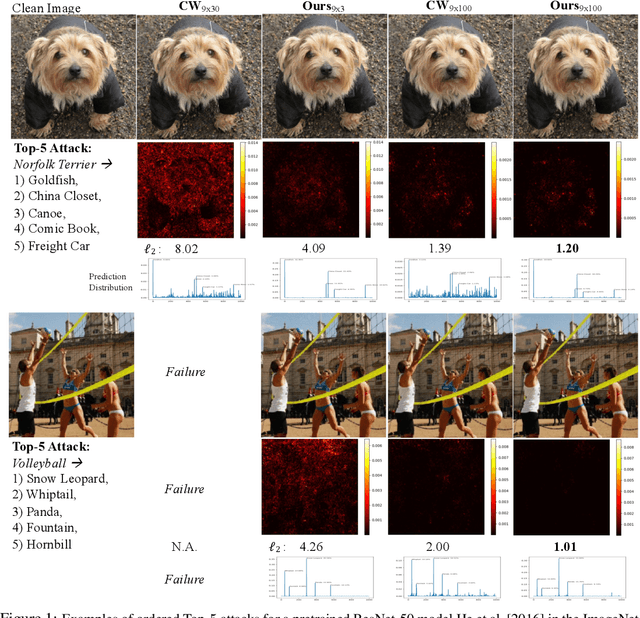

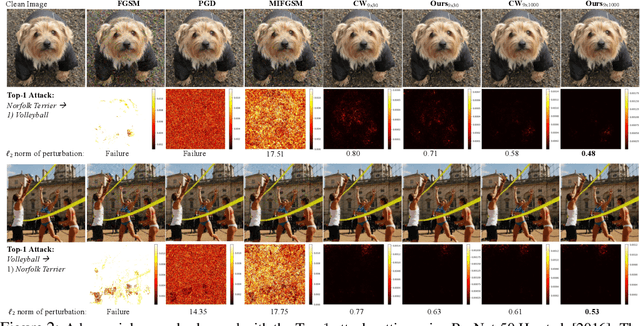
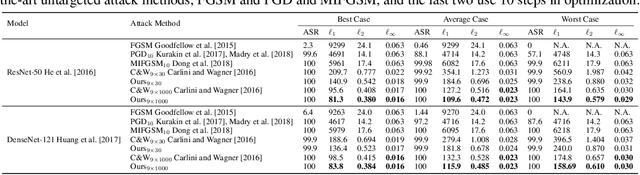
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks, especially white-box targeted attacks. One scheme of learning attacks is to design a proper adversarial objective function that leads to the imperceptible perturbation for any test image (e.g., the Carlini-Wagner (C&W) method). Most methods address targeted attacks in the Top-1 manner. In this paper, we propose to learn ordered Top-k attacks (k>= 1) for image classification tasks, that is to enforce the Top-k predicted labels of an adversarial example to be the k (randomly) selected and ordered labels (the ground-truth label is exclusive). To this end, we present an adversarial distillation framework: First, we compute an adversarial probability distribution for any given ordered Top-k targeted labels with respect to the ground-truth of a test image. Then, we learn adversarial examples by minimizing the Kullback-Leibler (KL) divergence together with the perturbation energy penalty, similar in spirit to the network distillation method. We explore how to leverage label semantic similarities in computing the targeted distributions, leading to knowledge-oriented attacks. In experiments, we thoroughly test Top-1 and Top-5 attacks in the ImageNet-1000 validation dataset using two popular DNNs trained with clean ImageNet-1000 train dataset, ResNet-50 and DenseNet-121. For both models, our proposed adversarial distillation approach outperforms the C&W method in the Top-1 setting, as well as other baseline methods. Our approach shows significant improvement in the Top-5 setting against a strong modified C&W method.