 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Optimization for Non-convex Inf-Projection Problems
Aug 26, 2019

In this paper, we study a family of non-convex and possibly non-smooth inf-projection minimization problems, where the target objective function is equal to minimization of a joint function over another variable. This problem includes difference of convex (DC) functions and a family of bi-convex functions as special cases. We develop stochastic algorithms and establish their first-order convergence for finding a (nearly) stationary solution of the target non-convex function under different conditions of the component functions. To the best of our knowledge, this is the first work that comprehensively studies stochastic optimization of non-convex inf-projection minimization problems with provable convergence guarantee. Our algorithms enable efficient stochastic optimization of a family of non-decomposable DC functions and a family of bi-convex functions. To demonstrate the power of the proposed algorithms we consider an important application in variance-based regularization, and experiments verify the effectiveness of our inf-projection based formulation and the proposed stochastic algorithm in comparison with previous stochastic algorithms based on the min-max formulation for achieving the same effect.
A Data Efficient and Feasible Level Set Method for Stochastic Convex Optimization with Expectation Constraints
Aug 07, 2019

Stochastic convex optimization problems with expectation constraints (SOECs) are encountered in statistics and machine learning, business, and engineering. In data-rich environments, the SOEC objective and constraints contain expectations defined with respect to large datasets. Therefore, efficient algorithms for solving such SOECs need to limit the fraction of data points that they use, which we refer to as algorithmic data complexity. Recent stochastic first order methods exhibit low data complexity when handling SOECs but guarantee near-feasibility and near-optimality only at convergence. These methods may thus return highly infeasible solutions when heuristically terminated, as is often the case, due to theoretical convergence criteria being highly conservative. This issue limits the use of first order methods in several applications where the SOEC constraints encode implementation requirements. We design a stochastic feasible level set method (SFLS) for SOECs that has low data complexity and emphasizes feasibility before convergence. Specifically, our level-set method solves a root-finding problem by calling a novel first order oracle that computes a stochastic upper bound on the level-set function by extending mirror descent and online validation techniques. We establish that SFLS maintains a high-probability feasible solution at each root-finding iteration and exhibits favorable iteration complexity compared to state-of-the-art deterministic feasible level set and stochastic subgradient methods. Numerical experiments on three diverse applications validate the low data complexity of SFLS relative to the former approach and highlight how SFLS finds feasible solutions with small optimality gaps significantly faster than the latter method.
Stochastic Primal-Dual Algorithms with Faster Convergence than $O(1/\sqrt{T})$ for Problems without Bilinear Structure
Apr 23, 2019



Previous studies on stochastic primal-dual algorithms for solving min-max problems with faster convergence heavily rely on the bilinear structure of the problem, which restricts their applicability to a narrowed range of problems. The main contribution of this paper is the design and analysis of new stochastic primal-dual algorithms that use a mixture of stochastic gradient updates and a logarithmic number of deterministic dual updates for solving a family of convex-concave problems with no bilinear structure assumed. Faster convergence rates than $O(1/\sqrt{T})$ with $T$ being the number of stochastic gradient updates are established under some mild conditions of involved functions on the primal and the dual variable. For example, for a family of problems that enjoy a weak strong convexity in terms of the primal variable and has a strongly concave function of the dual variable, the convergence rate of the proposed algorithm is $O(1/T)$. We also investigate the effectiveness of the proposed algorithms for learning robust models and empirical AUC maximization.
Why Does Stagewise Training Accelerate Convergence of Testing Error Over SGD?
Dec 11, 2018
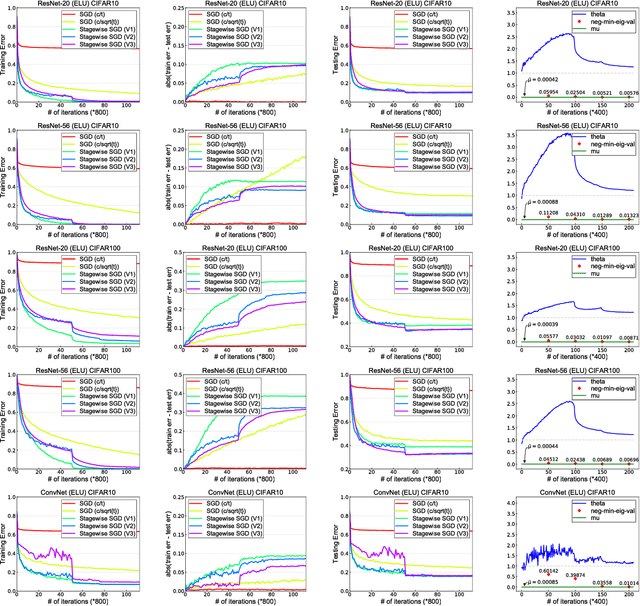
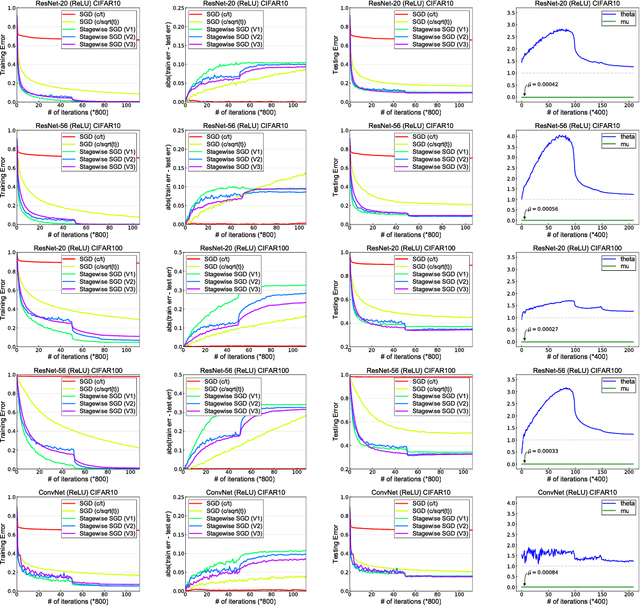
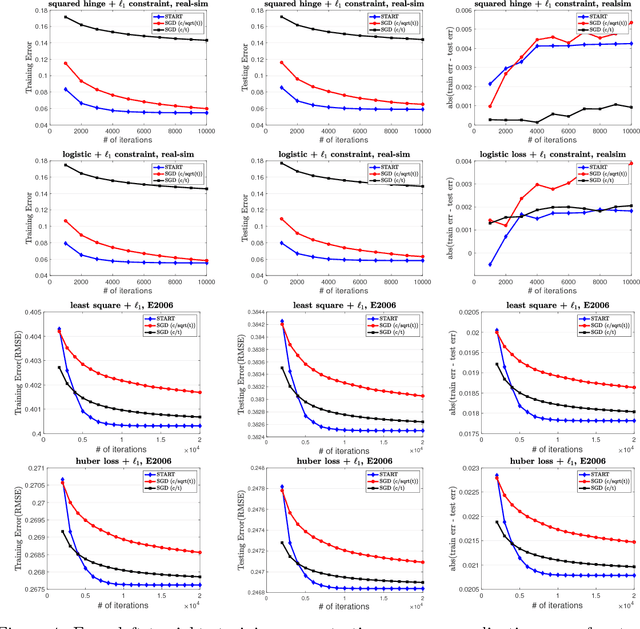
Stagewise training strategy is commonly used for learning neural networks, which uses a stochastic algorithm (e.g., SGD) starting with a relatively large step size (aka learning rate) and geometrically decreasing the step size after a number of iterations. It has been observed that the stagewise SGD has much faster convergence than the vanilla SGD with a polynomial decaying step size in terms of both training error and testing error. {\it But how to explain this phenomenon has been largely ignored by existing studies.} This paper provides some theoretical evidence for explaining this faster convergence. In particular, we consider the stagewise training strategy for minimizing empirical risk that satisfies the Polyak-\L ojasiewicz condition, which has been observed/proved for neural networks and also holds for a broad family of convex functions. For convex loss functions and "nice-behaviored" non-convex loss functions that are close to a convex function (namely weakly convex functions), we establish faster convergence of stagewise training than the vanilla SGD under the same condition on both training error and testing error. Indeed, the proposed algorithm has additional favorable features that come with theoretical guarantee for the considered non-convex optimization problems, including using explicit algorithmic regularization at each stage, using stagewise averaged solution for restarting, and returning the last stagewise averaged solution as the final solution. To differentiate from commonly used stagewise SGD, we refer to our algorithm as stagewise regularized training algorithm. Of independent interest, the proved testing error bounds for a family of non-convex loss functions are dimensionality and norm independent.
Stochastic Optimization for DC Functions and Non-smooth Non-convex Regularizers with Non-asymptotic Convergence
Nov 28, 2018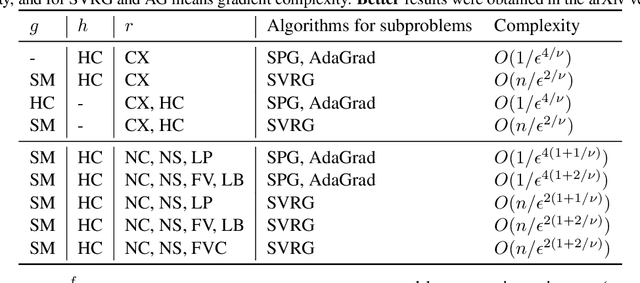
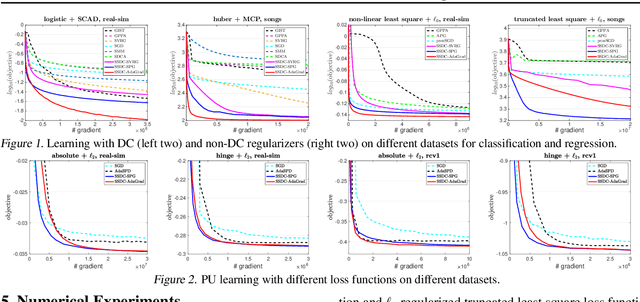
Difference of convex (DC) functions cover a broad family of non-convex and possibly non-smooth and non-differentiable functions, and have wide applications in machine learning and statistics. Although deterministic algorithms for DC functions have been extensively studied, stochastic optimization that is more suitable for learning with big data remains under-explored. In this paper, we propose new stochastic optimization algorithms and study their first-order convergence theories for solving a broad family of DC functions. We improve the existing algorithms and theories of stochastic optimization for DC functions from both practical and theoretical perspectives. On the practical side, our algorithm is more user-friendly without requiring a large mini-batch size and more efficient by saving unnecessary computations. On the theoretical side, our convergence analysis does not necessarily require the involved functions to be smooth with Lipschitz continuous gradient. Instead, the convergence rate of the proposed stochastic algorithm is automatically adaptive to the H\"{o}lder continuity of the gradient of one component function. Moreover, we extend the proposed stochastic algorithms for DC functions to solve problems with a general non-convex non-differentiable regularizer, which does not necessarily have a DC decomposition but enjoys an efficient proximal mapping. To the best of our knowledge, this is the first work that gives the first non-asymptotic convergence for solving non-convex optimization whose objective has a general non-convex non-differentiable regularizer.
Improving Sequential Determinantal Point Processes for Supervised Video Summarization
Oct 24, 2018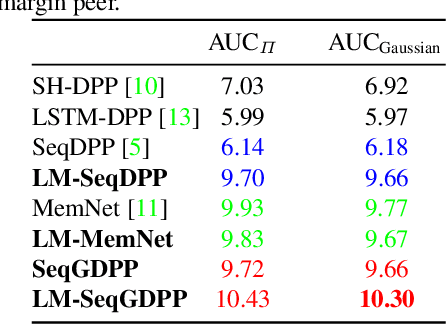
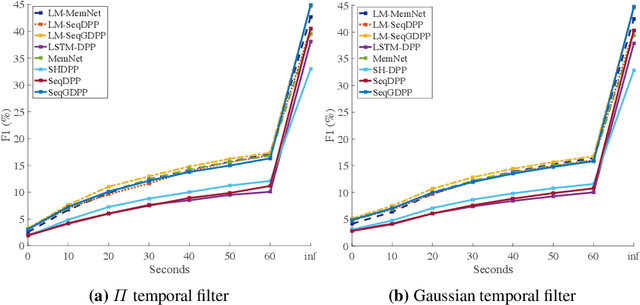
It is now much easier than ever before to produce videos. While the ubiquitous video data is a great source for information discovery and extraction, the computational challenges are unparalleled. Automatically summarizing the videos has become a substantial need for browsing, searching, and indexing visual content. This paper is in the vein of supervised video summarization using sequential determinantal point process (SeqDPP), which models diversity by a probabilistic distribution. We improve this model in two folds. In terms of learning, we propose a large-margin algorithm to address the exposure bias problem in SeqDPP. In terms of modeling, we design a new probabilistic distribution such that, when it is integrated into SeqDPP, the resulting model accepts user input about the expected length of the summary. Moreover, we also significantly extend a popular video summarization dataset by 1) more egocentric videos, 2) dense user annotations, and 3) a refined evaluation scheme. We conduct extensive experiments on this dataset (about 60 hours of videos in total) and compare our approach to several competitive baselines.
Solving Weakly-Convex-Weakly-Concave Saddle-Point Problems as Weakly-Monotone Variational Inequality
Oct 24, 2018
In this paper, we consider first-order algorithms for solving a class of non-convex non-concave min-max saddle-point problems, whose objective function is weakly convex (resp. weakly concave) in terms of the variable of minimization (resp. maximization). It has many important applications in machine learning, statistics, and operations research. One such example that attracts tremendous attention recently in machine learning is training Generative Adversarial Networks. We propose an algorithmic framework motivated by the proximal point method, which solve a sequence of strongly monotone variational inequalities constructed by adding a strongly monotone mapping to the original mapping with a periodically updated proximal center. By approximately solving each strongly monotone variational inequality, we prove that the solution obtained by the algorithm converges to a stationary solution of the original min-max problem. Iteration complexities are established for using different algorithms to solve the subproblems, including subgradient method, extragradient method and stochastic subgradient method. To the best of our knowledge, this is the first work that establishes the non-asymptotic convergence to a stationary point of a non-convex non-concave min-max problem.
Learning Discriminators as Energy Networks in Adversarial Learning
Oct 02, 2018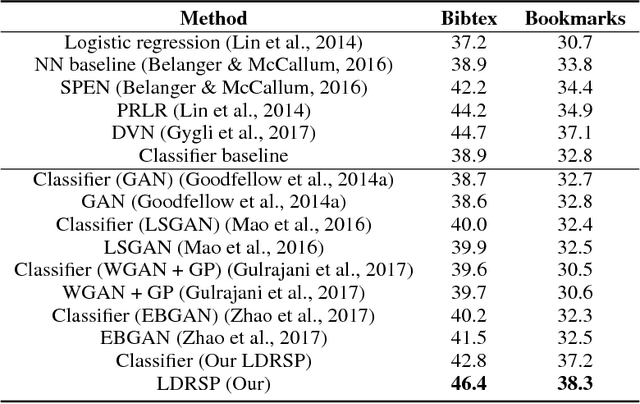

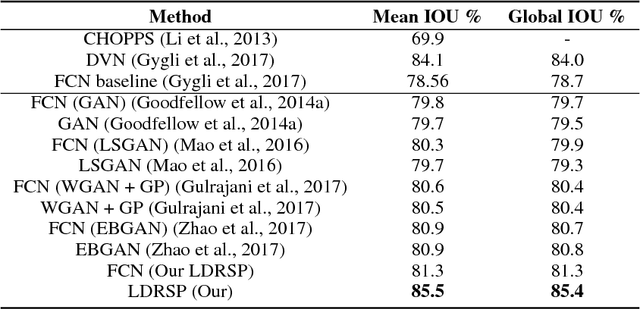
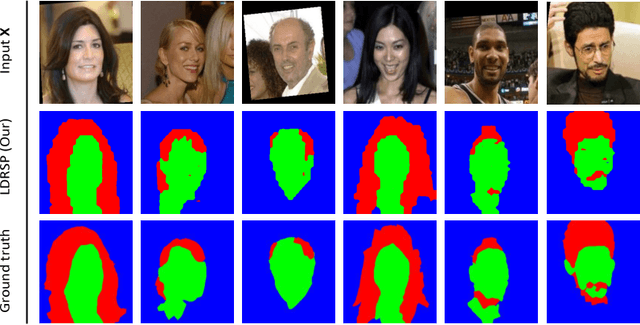
We propose a novel framework for structured prediction via adversarial learning. Existing adversarial learning methods involve two separate networks, i.e., the structured prediction models and the discriminative models, in the training. The information captured by discriminative models complements that in the structured prediction models, but few existing researches have studied on utilizing such information to improve structured prediction models at the inference stage. In this work, we propose to refine the predictions of structured prediction models by effectively integrating discriminative models into the prediction. Discriminative models are treated as energy-based models. Similar to the adversarial learning, discriminative models are trained to estimate scores which measure the quality of predicted outputs, while structured prediction models are trained to predict contrastive outputs with maximal energy scores. In this way, the gradient vanishing problem is ameliorated, and thus we are able to perform inference by following the ascent gradient directions of discriminative models to refine structured prediction models. The proposed method is able to handle a range of tasks, e.g., multi-label classification and image segmentation. Empirical results on these two tasks validate the effectiveness of our learning method.
Universal Stagewise Learning for Non-Convex Problems with Convergence on Averaged Solutions
Sep 04, 2018Although stochastic gradient descent (SGD) method and its variants (e.g., stochastic momentum methods, AdaGrad) are the choice of algorithms for solving non-convex problems (especially deep learning), there still remain big gaps between the theory and the practice with many questions unresolved. For example, there is still a lack of theories of convergence for SGD and its variants that use stagewise step size and return an averaged solution in practice. In addition, theoretical insights of why adaptive step size of AdaGrad could improve non-adaptive step size of {\sgd} is still missing for non-convex optimization. This paper aims to address these questions and fill the gap between theory and practice. We propose a universal stagewise optimization framework for a broad family of {\bf non-smooth non-convex} (namely weakly convex) problems with the following key features: (i) at each stage any suitable stochastic convex optimization algorithms (e.g., SGD or AdaGrad) that return an averaged solution can be employed for minimizing a regularized convex problem; (ii) the step size is decreased in a stagewise manner; (iii) an averaged solution is returned as the final solution that is selected from all stagewise averaged solutions with sampling probabilities {\it increasing} as the stage number. Our theoretical results of stagewise AdaGrad exhibit its adaptive convergence, therefore shed insights on its faster convergence for problems with sparse stochastic gradients than stagewise SGD. To the best of our knowledge, these new results are the first of their kind for addressing the unresolved issues of existing theories mentioned earlier.
A Unified Analysis of Stochastic Momentum Methods for Deep Learning
Aug 30, 2018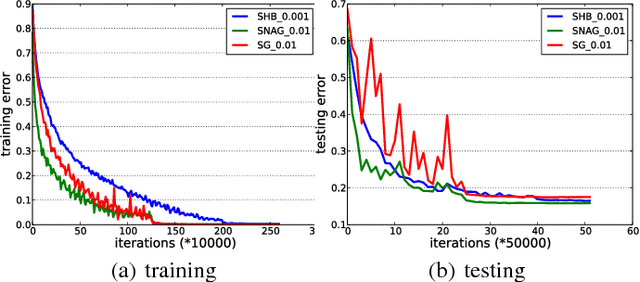
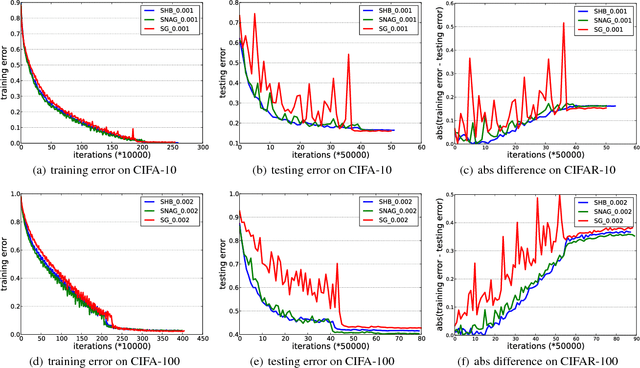
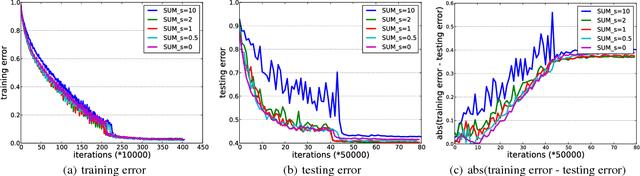
Stochastic momentum methods have been widely adopted in training deep neural networks. However, their theoretical analysis of convergence of the training objective and the generalization error for prediction is still under-explored. This paper aims to bridge the gap between practice and theory by analyzing the stochastic gradient (SG) method, and the stochastic momentum methods including two famous variants, i.e., the stochastic heavy-ball (SHB) method and the stochastic variant of Nesterov's accelerated gradient (SNAG) method. We propose a framework that unifies the three variants. We then derive the convergence rates of the norm of gradient for the non-convex optimization problem, and analyze the generalization performance through the uniform stability approach. Particularly, the convergence analysis of the training objective exhibits that SHB and SNAG have no advantage over SG. However, the stability analysis shows that the momentum term can improve the stability of the learned model and hence improve the generalization performance. These theoretical insights verify the common wisdom and are also corroborated by our empirical analysis on deep learning.
* Previous Technical Report: arXiv:1604.03257