 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
May 26, 2025We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.
Are Your LLMs Capable of Stable Reasoning?
Dec 17, 2024



The rapid advancement of Large Language Models (LLMs) has demonstrated remarkable progress in complex reasoning tasks. However, a significant discrepancy persists between benchmark performances and real-world applications. We identify this gap as primarily stemming from current evaluation protocols and metrics, which inadequately capture the full spectrum of LLM capabilities, particularly in complex reasoning tasks where both accuracy and consistency are crucial. This work makes two key contributions. First, we introduce G-Pass@k, a novel evaluation metric that provides a continuous assessment of model performance across multiple sampling attempts, quantifying both the model's peak performance potential and its stability. Second, we present LiveMathBench, a dynamic benchmark comprising challenging, contemporary mathematical problems designed to minimize data leakage risks during evaluation. Through extensive experiments using G-Pass@k on state-of-the-art LLMs with LiveMathBench, we provide comprehensive insights into both their maximum capabilities and operational consistency. Our findings reveal substantial room for improvement in LLMs' "realistic" reasoning capabilities, highlighting the need for more robust evaluation methods. The benchmark and detailed results are available at: https://github.com/open-compass/GPassK.
Learning the Localization Function: Machine Learning Approach to Fingerprinting Localization
Mar 21, 2018
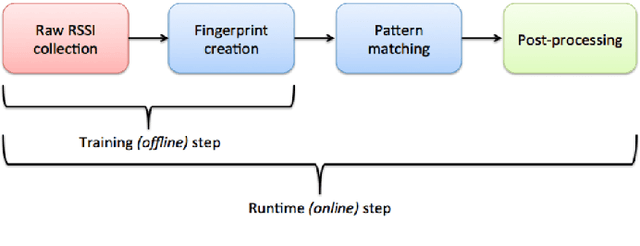
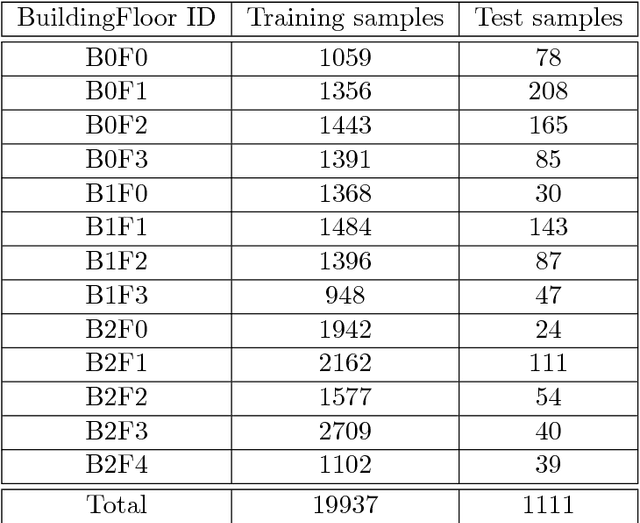
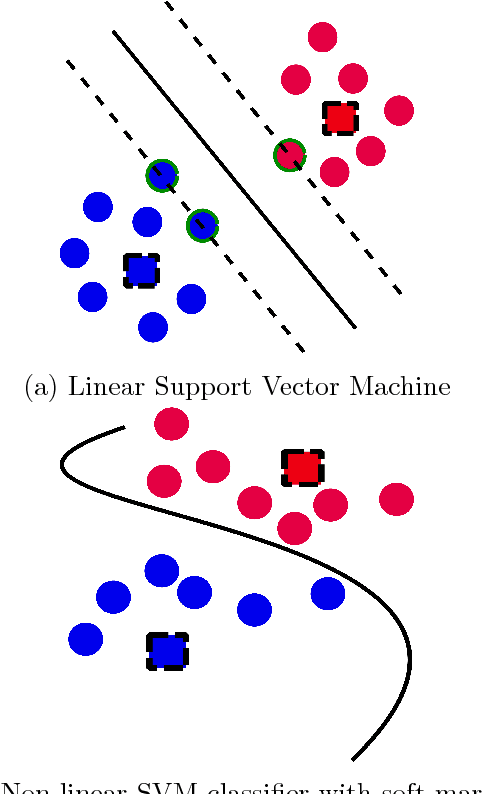
Considered as a data-driven approach, Fingerprinting Localization Solutions (FPSs) enjoy huge popularity due to their good performance and minimal environment information requirement. This papers addresses applications of artificial intelligence to solve two problems in Received Signal Strength Indicator (RSSI) based FPS, first the cumbersome training database construction and second the extrapolation of fingerprinting algorithm for similar buildings with slight environmental changes. After a concise overview of deep learning design techniques, two main techniques widely used in deep learning are exploited for the above mentioned issues namely data augmentation and transfer learning. We train a multi-layer neural network that learns the mapping from the observations to the locations. A data augmentation method is proposed to increase the training database size based on the structure of RSSI measurements and hence reducing effectively the amount of training data. Then it is shown experimentally how a model trained for a particular building can be transferred to a similar one by fine tuning with significantly smaller training numbers. The paper implicitly discusses the new guidelines to consider about deep learning designs when they are employed in a new application context.