 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTAN: Knowledge Transfer Adversarial Network
Oct 18, 2018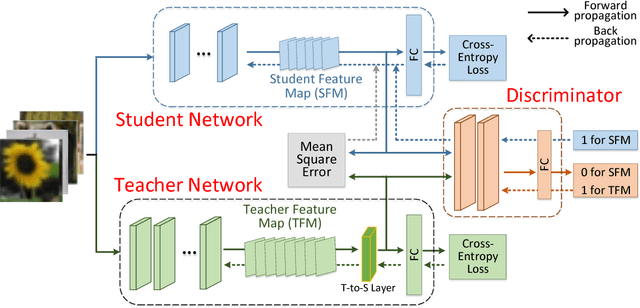
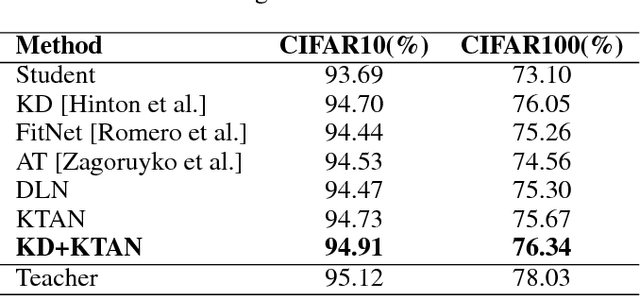


To reduce the large computation and storage cost of a deep convolutional neural network, the knowledge distillation based methods have pioneered to transfer the generalization ability of a large (teacher) deep network to a light-weight (student) network. However, these methods mostly focus on transferring the probability distribution of the softmax layer in a teacher network and thus neglect the intermediate representations. In this paper, we propose a knowledge transfer adversarial network to better train a student network. Our technique holistically considers both intermediate representations and probability distributions of a teacher network. To transfer the knowledge of intermediate representations, we set high-level teacher feature maps as a target, toward which the student feature maps are trained. Specifically, we arrange a Teacher-to-Student layer for enabling our framework suitable for various student structures. The intermediate representation helps the student network better understand the transferred generalization as compared to the probability distribution only. Furthermore, we infuse an adversarial learning process by employing a discriminator network, which can fully exploit the spatial correlation of feature maps in training a student network. The experimental results demonstrate that the proposed method can significantly improve the performance of a student network on both image classification and object detection tasks.
Exploring Visual Relationship for Image Captioning
Sep 19, 2018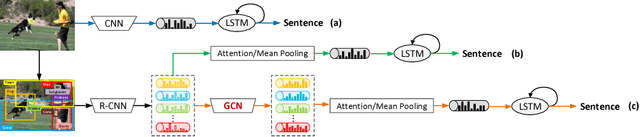
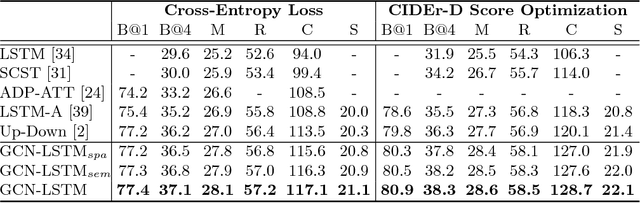
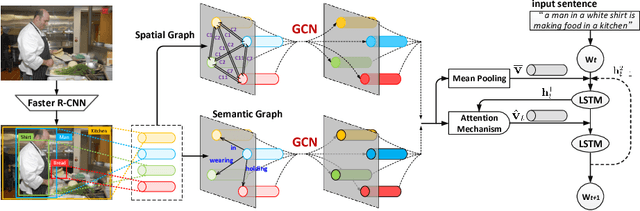
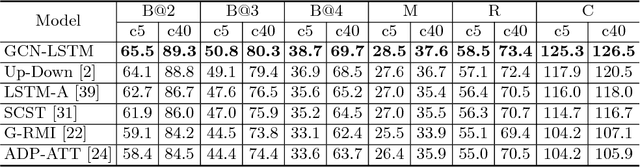
It is always well believed that modeling relationships between objects would be helpful for representing and eventually describing an image. Nevertheless, there has not been evidence in support of the idea on image description generation. In this paper, we introduce a new design to explore the connections between objects for image captioning under the umbrella of attention-based encoder-decoder framework. Specifically, we present Graph Convolutional Networks plus Long Short-Term Memory (dubbed as GCN-LSTM) architecture that novelly integrates both semantic and spatial object relationships into image encoder. Technically, we build graphs over the detected objects in an image based on their spatial and semantic connections. The representations of each region proposed on objects are then refined by leveraging graph structure through GCN. With the learnt region-level features, our GCN-LSTM capitalizes on LSTM-based captioning framework with attention mechanism for sentence generation. Extensive experiments are conducted on COCO image captioning dataset, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, GCN-LSTM increases CIDEr-D performance from 120.1% to 128.7% on COCO testing set.
Subspace Clustering by Block Diagonal Representation
May 23, 2018
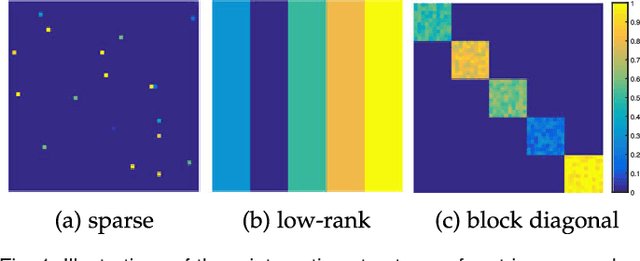
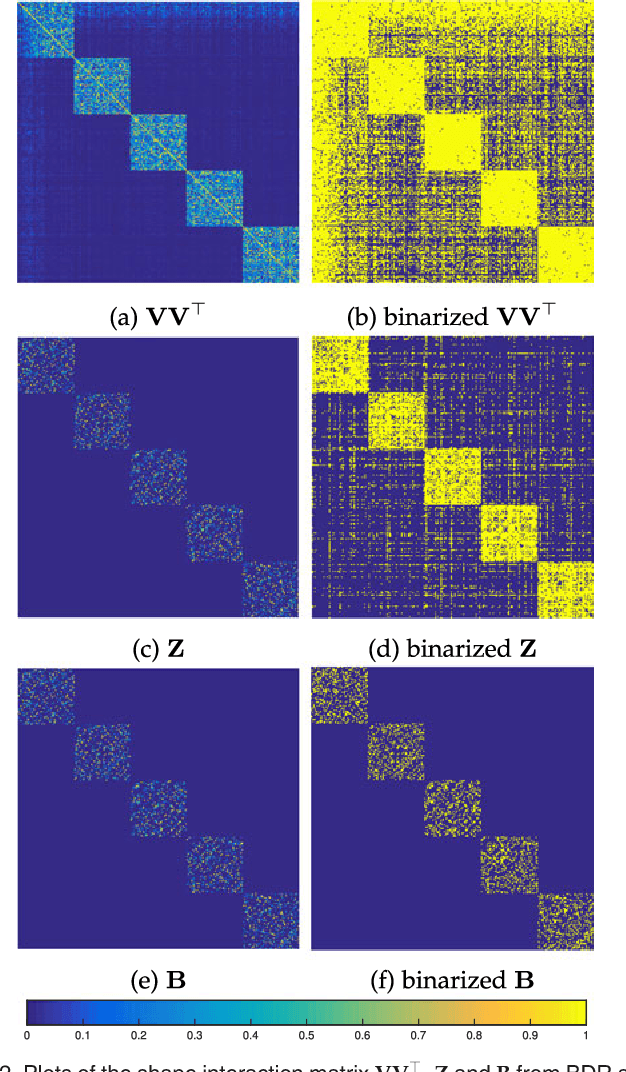
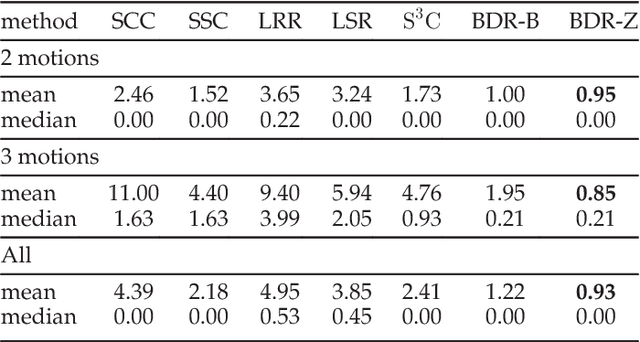
This paper studies the subspace clustering problem. Given some data points approximately drawn from a union of subspaces, the goal is to group these data points into their underlying subspaces. Many subspace clustering methods have been proposed and among which sparse subspace clustering and low-rank representation are two representative ones. Despite the different motivations, we observe that many existing methods own the common block diagonal property, which possibly leads to correct clustering, yet with their proofs given case by case. In this work, we consider a general formulation and provide a unified theoretical guarantee of the block diagonal property. The block diagonal property of many existing methods falls into our special case. Second, we observe that many existing methods approximate the block diagonal representation matrix by using different structure priors, e.g., sparsity and low-rankness, which are indirect. We propose the first block diagonal matrix induced regularizer for directly pursuing the block diagonal matrix. With this regularizer, we solve the subspace clustering problem by Block Diagonal Representation (BDR), which uses the block diagonal structure prior. The BDR model is nonconvex and we propose an alternating minimization solver and prove its convergence. Experiments on real datasets demonstrate the effectiveness of BDR.
Fully Convolutional Adaptation Networks for Semantic Segmentation
Apr 23, 2018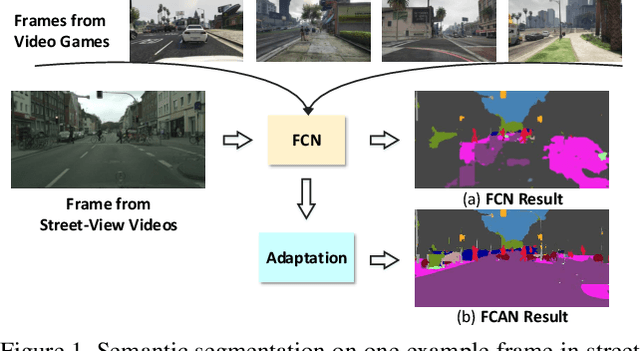

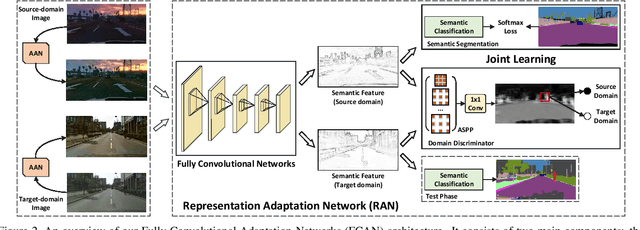

The recent advances in deep neural networks have convincingly demonstrated high capability in learning vision models on large datasets. Nevertheless, collecting expert labeled datasets especially with pixel-level annotations is an extremely expensive process. An appealing alternative is to render synthetic data (e.g., computer games) and generate ground truth automatically. However, simply applying the models learnt on synthetic images may lead to high generalization error on real images due to domain shift. In this paper, we facilitate this issue from the perspectives of both visual appearance-level and representation-level domain adaptation. The former adapts source-domain images to appear as if drawn from the "style" in the target domain and the latter attempts to learn domain-invariant representations. Specifically, we present Fully Convolutional Adaptation Networks (FCAN), a novel deep architecture for semantic segmentation which combines Appearance Adaptation Networks (AAN) and Representation Adaptation Networks (RAN). AAN learns a transformation from one domain to the other in the pixel space and RAN is optimized in an adversarial learning manner to maximally fool the domain discriminator with the learnt source and target representations. Extensive experiments are conducted on the transfer from GTA5 (game videos) to Cityscapes (urban street scenes) on semantic segmentation and our proposal achieves superior results when comparing to state-of-the-art unsupervised adaptation techniques. More remarkably, we obtain a new record: mIoU of 47.5% on BDDS (drive-cam videos) in an unsupervised setting.
Memory Matching Networks for One-Shot Image Recognition
Apr 23, 2018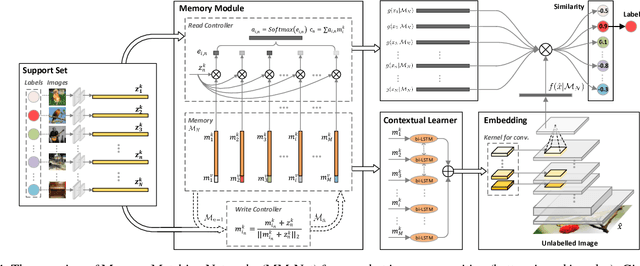
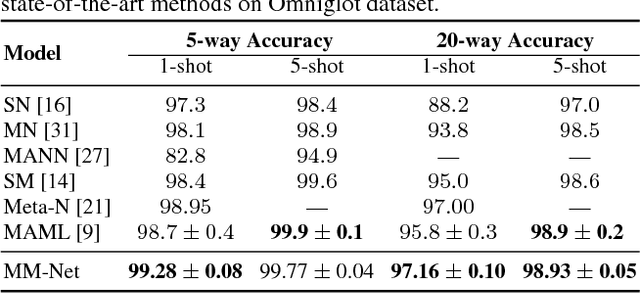
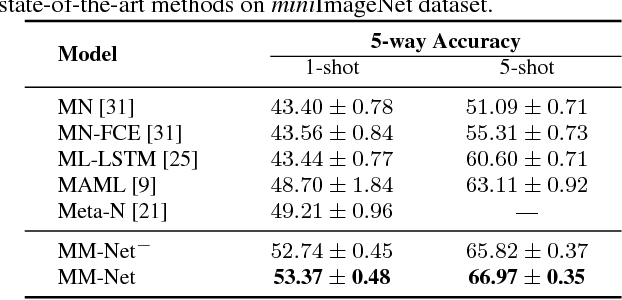
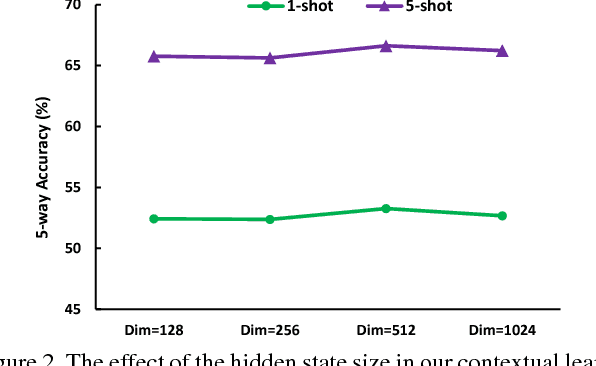
In this paper, we introduce the new ideas of augmenting Convolutional Neural Networks (CNNs) with Memory and learning to learn the network parameters for the unlabelled images on the fly in one-shot learning. Specifically, we present Memory Matching Networks (MM-Net) --- a novel deep architecture that explores the training procedure, following the philosophy that training and test conditions must match. Technically, MM-Net writes the features of a set of labelled images (support set) into memory and reads from memory when performing inference to holistically leverage the knowledge in the set. Meanwhile, a Contextual Learner employs the memory slots in a sequential manner to predict the parameters of CNNs for unlabelled images. The whole architecture is trained by once showing only a few examples per class and switching the learning from minibatch to minibatch, which is tailored for one-shot learning when presented with a few examples of new categories at test time. Unlike the conventional one-shot learning approaches, our MM-Net could output one unified model irrespective of the number of shots and categories. Extensive experiments are conducted on two public datasets, i.e., Omniglot and \emph{mini}ImageNet, and superior results are reported when compared to state-of-the-art approaches. More remarkably, our MM-Net improves one-shot accuracy on Omniglot from 98.95% to 99.28% and from 49.21% to 53.37% on \emph{mini}ImageNet.
Deep Semantic Hashing with Generative Adversarial Networks
Apr 23, 2018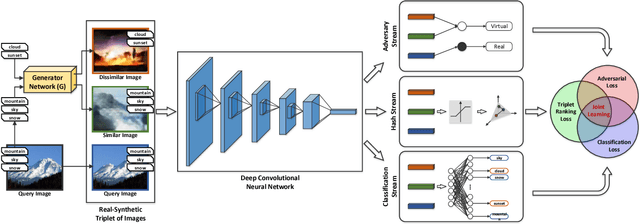
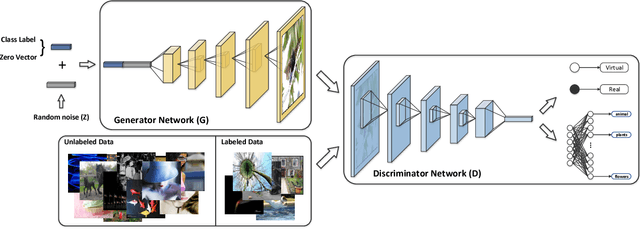
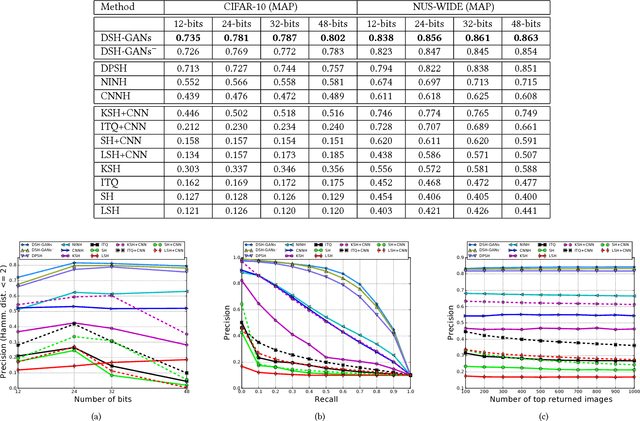
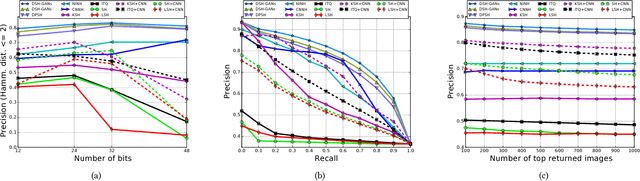
Hashing has been a widely-adopted technique for nearest neighbor search in large-scale image retrieval tasks. Recent research has shown that leveraging supervised information can lead to high quality hashing. However, the cost of annotating data is often an obstacle when applying supervised hashing to a new domain. Moreover, the results can suffer from the robustness problem as the data at training and test stage could come from similar but different distributions. This paper studies the exploration of generating synthetic data through semi-supervised generative adversarial networks (GANs), which leverages largely unlabeled and limited labeled training data to produce highly compelling data with intrinsic invariance and global coherence, for better understanding statistical structures of natural data. We demonstrate that the above two limitations can be well mitigated by applying the synthetic data for hashing. Specifically, a novel deep semantic hashing with GANs (DSH-GANs) is presented, which mainly consists of four components: a deep convolution neural networks (CNN) for learning image representations, an adversary stream to distinguish synthetic images from real ones, a hash stream for encoding image representations to hash codes and a classification stream. The whole architecture is trained end-to-end by jointly optimizing three losses, i.e., adversarial loss to correct label of synthetic or real for each sample, triplet ranking loss to preserve the relative similarity ordering in the input real-synthetic triplets and classification loss to classify each sample accurately. Extensive experiments conducted on both CIFAR-10 and NUS-WIDE image benchmarks validate the capability of exploiting synthetic images for hashing. Our framework also achieves superior results when compared to state-of-the-art deep hash models.
Jointly Localizing and Describing Events for Dense Video Captioning
Apr 23, 2018
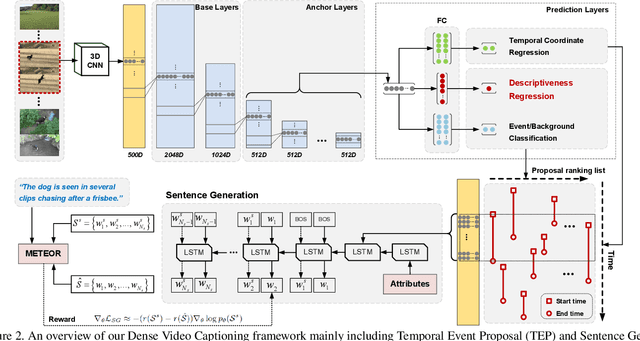
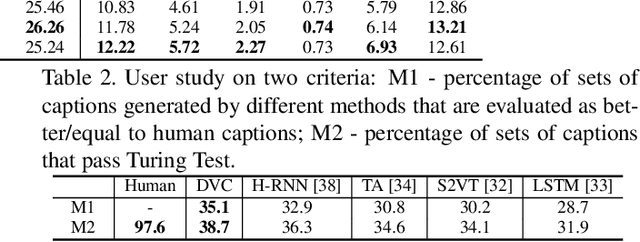
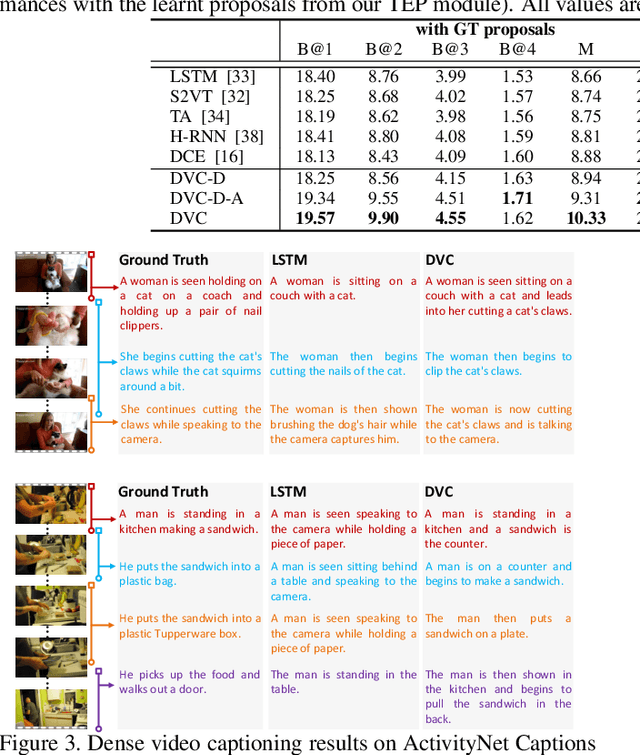
Automatically describing a video with natural language is regarded as a fundamental challenge in computer vision. The problem nevertheless is not trivial especially when a video contains multiple events to be worthy of mention, which often happens in real videos. A valid question is how to temporally localize and then describe events, which is known as "dense video captioning." In this paper, we present a novel framework for dense video captioning that unifies the localization of temporal event proposals and sentence generation of each proposal, by jointly training them in an end-to-end manner. To combine these two worlds, we integrate a new design, namely descriptiveness regression, into a single shot detection structure to infer the descriptive complexity of each detected proposal via sentence generation. This in turn adjusts the temporal locations of each event proposal. Our model differs from existing dense video captioning methods since we propose a joint and global optimization of detection and captioning, and the framework uniquely capitalizes on an attribute-augmented video captioning architecture. Extensive experiments are conducted on ActivityNet Captions dataset and our framework shows clear improvements when compared to the state-of-the-art techniques. More remarkably, we obtain a new record: METEOR of 12.96% on ActivityNet Captions official test set.
To Create What You Tell: Generating Videos from Captions
Apr 23, 2018
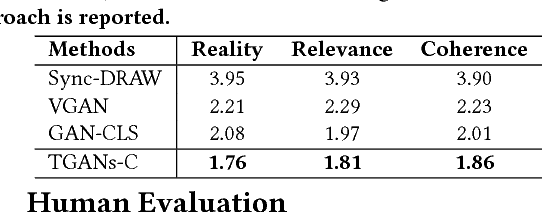
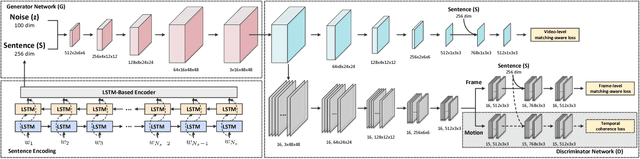
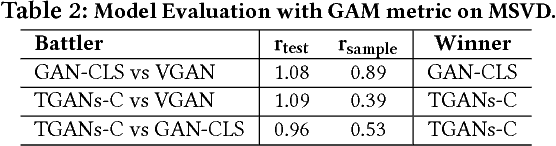
We are creating multimedia contents everyday and everywhere. While automatic content generation has played a fundamental challenge to multimedia community for decades, recent advances of deep learning have made this problem feasible. For example, the Generative Adversarial Networks (GANs) is a rewarding approach to synthesize images. Nevertheless, it is not trivial when capitalizing on GANs to generate videos. The difficulty originates from the intrinsic structure where a video is a sequence of visually coherent and semantically dependent frames. This motivates us to explore semantic and temporal coherence in designing GANs to generate videos. In this paper, we present a novel Temporal GANs conditioning on Captions, namely TGANs-C, in which the input to the generator network is a concatenation of a latent noise vector and caption embedding, and then is transformed into a frame sequence with 3D spatio-temporal convolutions. Unlike the naive discriminator which only judges pairs as fake or real, our discriminator additionally notes whether the video matches the correct caption. In particular, the discriminator network consists of three discriminators: video discriminator classifying realistic videos from generated ones and optimizes video-caption matching, frame discriminator discriminating between real and fake frames and aligning frames with the conditioning caption, and motion discriminator emphasizing the philosophy that the adjacent frames in the generated videos should be smoothly connected as in real ones. We qualitatively demonstrate the capability of our TGANs-C to generate plausible videos conditioning on the given captions on two synthetic datasets (SBMG and TBMG) and one real-world dataset (MSVD). Moreover, quantitative experiments on MSVD are performed to validate our proposal via Generative Adversarial Metric and human study.
Part-Aligned Bilinear Representations for Person Re-identification
Apr 19, 2018
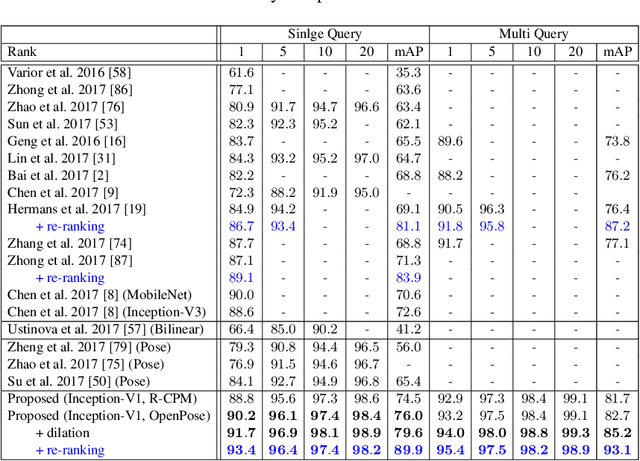
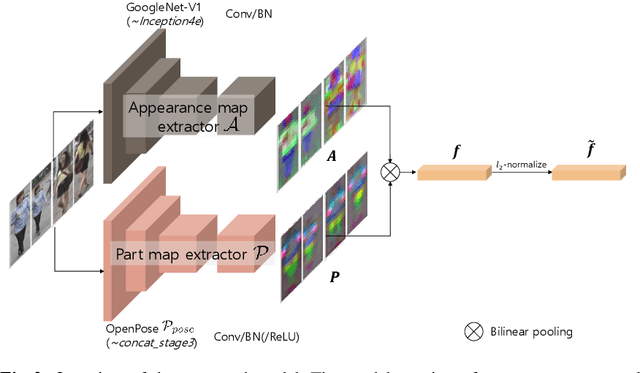

We propose a novel network that learns a part-aligned representation for person re-identification. It handles the body part misalignment problem, that is, body parts are misaligned across human detections due to pose/viewpoint change and unreliable detection. Our model consists of a two-stream network (one stream for appearance map extraction and the other one for body part map extraction) and a bilinear-pooling layer that generates and spatially pools a part-aligned map. Each local feature of the part-aligned map is obtained by a bilinear mapping of the corresponding local appearance and body part descriptors. Our new representation leads to a robust image matching similarity, which is equivalent to an aggregation of the local similarities of the corresponding body parts combined with the weighted appearance similarity. This part-aligned representation reduces the part misalignment problem significantly. Our approach is also advantageous over other pose-guided representations (e.g., extracting representations over the bounding box of each body part) by learning part descriptors optimal for person re-identification. For training the network, our approach does not require any part annotation on the person re-identification dataset. Instead, we simply initialize the part sub-stream using a pre-trained sub-network of an existing pose estimation network, and train the whole network to minimize the re-identification loss. We validate the effectiveness of our approach by demonstrating its superiority over the state-of-the-art methods on the standard benchmark datasets, including Market-1501, CUHK03, CUHK01 and DukeMTMC, and standard video dataset MARS.
Automatic Dataset Augmentation
Apr 16, 2018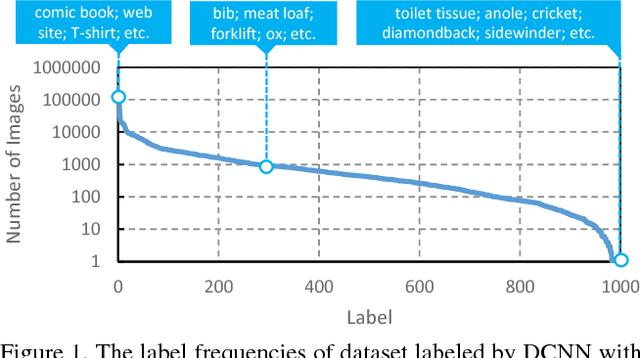
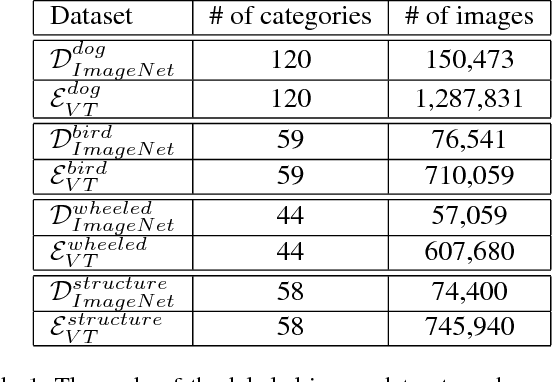
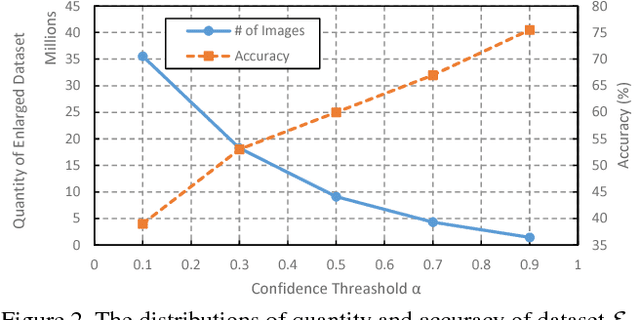
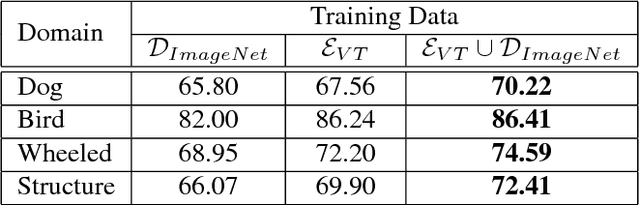
Large scale image dataset and deep convolutional neural network (DCNN) are two primary driving forces for the rapid progress made in generic object recognition tasks in recent years. While lots of network architectures have been continuously designed to pursue lower error rates, few efforts are devoted to enlarge existing datasets due to high labeling cost and unfair comparison issues. In this paper, we aim to achieve lower error rate by augmenting existing datasets in an automatic manner. Our method leverages both Web and DCNN, where Web provides massive images with rich contextual information, and DCNN replaces human to automatically label images under guidance of Web contextual information. Experiments show our method can automatically scale up existing datasets significantly from billions web pages with high accuracy, and significantly improve the performance on object recognition tasks by using the automatically augmented datasets, which demonstrates that more supervisory information has been automatically gathered from the Web. Both the dataset and models trained on the dataset are made publicly available.