 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent advances in interpretable machine learning using structure-based protein representations
Sep 26, 2024Recent advancements in machine learning (ML) are transforming the field of structural biology. For example, AlphaFold, a groundbreaking neural network for protein structure prediction, has been widely adopted by researchers. The availability of easy-to-use interfaces and interpretable outcomes from the neural network architecture, such as the confidence scores used to color the predicted structures, have made AlphaFold accessible even to non-ML experts. In this paper, we present various methods for representing protein 3D structures from low- to high-resolution, and show how interpretable ML methods can support tasks such as predicting protein structures, protein function, and protein-protein interactions. This survey also emphasizes the significance of interpreting and visualizing ML-based inference for structure-based protein representations that enhance interpretability and knowledge discovery. Developing such interpretable approaches promises to further accelerate fields including drug development and protein design.
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024



Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.
InterHandGen: Two-Hand Interaction Generation via Cascaded Reverse Diffusion
Mar 26, 2024



We present InterHandGen, a novel framework that learns the generative prior of two-hand interaction. Sampling from our model yields plausible and diverse two-hand shapes in close interaction with or without an object. Our prior can be incorporated into any optimization or learning methods to reduce ambiguity in an ill-posed setup. Our key observation is that directly modeling the joint distribution of multiple instances imposes high learning complexity due to its combinatorial nature. Thus, we propose to decompose the modeling of joint distribution into the modeling of factored unconditional and conditional single instance distribution. In particular, we introduce a diffusion model that learns the single-hand distribution unconditional and conditional to another hand via conditioning dropout. For sampling, we combine anti-penetration and classifier-free guidance to enable plausible generation. Furthermore, we establish the rigorous evaluation protocol of two-hand synthesis, where our method significantly outperforms baseline generative models in terms of plausibility and diversity. We also demonstrate that our diffusion prior can boost the performance of two-hand reconstruction from monocular in-the-wild images, achieving new state-of-the-art accuracy.
BiTT: Bi-directional Texture Reconstruction of Interacting Two Hands from a Single Image
Mar 21, 2024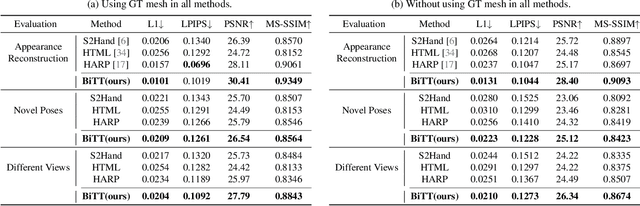
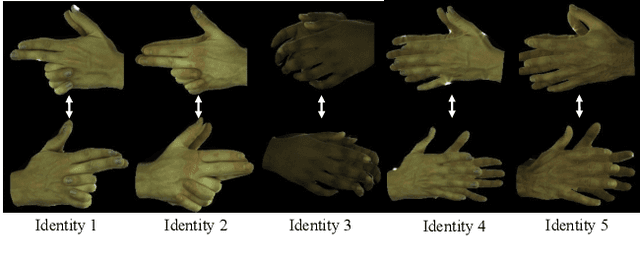
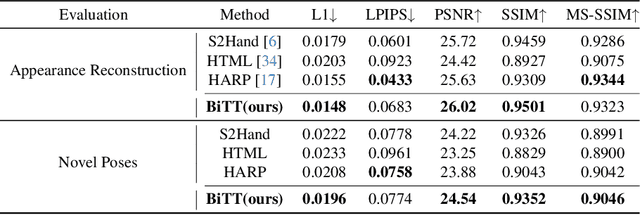
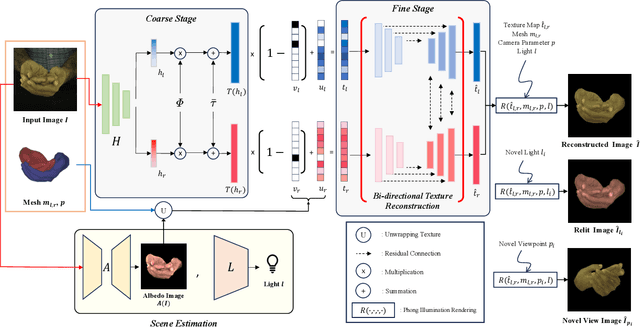
Creating personalized hand avatars is important to offer a realistic experience to users on AR / VR platforms. While most prior studies focused on reconstructing 3D hand shapes, some recent work has tackled the reconstruction of hand textures on top of shapes. However, these methods are often limited to capturing pixels on the visible side of a hand, requiring diverse views of the hand in a video or multiple images as input. In this paper, we propose a novel method, BiTT(Bi-directional Texture reconstruction of Two hands), which is the first end-to-end trainable method for relightable, pose-free texture reconstruction of two interacting hands taking only a single RGB image, by three novel components: 1) bi-directional (left $\leftrightarrow$ right) texture reconstruction using the texture symmetry of left / right hands, 2) utilizing a texture parametric model for hand texture recovery, and 3) the overall coarse-to-fine stage pipeline for reconstructing personalized texture of two interacting hands. BiTT first estimates the scene light condition and albedo image from an input image, then reconstructs the texture of both hands through the texture parametric model and bi-directional texture reconstructor. In experiments using InterHand2.6M and RGB2Hands datasets, our method significantly outperforms state-of-the-art hand texture reconstruction methods quantitatively and qualitatively. The code is available at https://github.com/yunminjin2/BiTT
Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
Mar 15, 2024



Super-resolution (SR) and image generation are important tasks in computer vision and are widely adopted in real-world applications. Most existing methods, however, generate images only at fixed-scale magnification and suffer from over-smoothing and artifacts. Additionally, they do not offer enough diversity of output images nor image consistency at different scales. Most relevant work applied Implicit Neural Representation (INR) to the denoising diffusion model to obtain continuous-resolution yet diverse and high-quality SR results. Since this model operates in the image space, the larger the resolution of image is produced, the more memory and inference time is required, and it also does not maintain scale-specific consistency. We propose a novel pipeline that can super-resolve an input image or generate from a random noise a novel image at arbitrary scales. The method consists of a pretrained auto-encoder, a latent diffusion model, and an implicit neural decoder, and their learning strategies. The proposed method adopts diffusion processes in a latent space, thus efficient, yet aligned with output image space decoded by MLPs at arbitrary scales. More specifically, our arbitrary-scale decoder is designed by the symmetric decoder w/o up-scaling from the pretrained auto-encoder, and Local Implicit Image Function (LIIF) in series. The latent diffusion process is learnt by the denoising and the alignment losses jointly. Errors in output images are backpropagated via the fixed decoder, improving the quality of output images. In the extensive experiments using multiple public benchmarks on the two tasks i.e. image super-resolution and novel image generation at arbitrary scales, the proposed method outperforms relevant methods in metrics of image quality, diversity and scale consistency. It is significantly better than the relevant prior-art in the inference speed and memory usage.
Energy-based Domain-Adaptive Segmentation with Depth Guidance
Feb 06, 2024Recent endeavors have been made to leverage self-supervised depth estimation as guidance in unsupervised domain adaptation (UDA) for semantic segmentation. Prior arts, however, overlook the discrepancy between semantic and depth features, as well as the reliability of feature fusion, thus leading to suboptimal segmentation performance. To address this issue, we propose a novel UDA framework called SMART (croSs doMain semAntic segmentation based on eneRgy esTimation) that utilizes Energy-Based Models (EBMs) to obtain task-adaptive features and achieve reliable feature fusion for semantic segmentation with self-supervised depth estimates. Our framework incorporates two novel components: energy-based feature fusion (EB2F) and energy-based reliable fusion Assessment (RFA) modules. The EB2F module produces task-adaptive semantic and depth features by explicitly measuring and reducing their discrepancy using Hopfield energy for better feature fusion. The RFA module evaluates the reliability of the feature fusion using an energy score to improve the effectiveness of depth guidance. Extensive experiments on two datasets demonstrate that our method achieves significant performance gains over prior works, validating the effectiveness of our energy-based learning approach.
PromptRR: Diffusion Models as Prompt Generators for Single Image Reflection Removal
Feb 04, 2024Existing single image reflection removal (SIRR) methods using deep learning tend to miss key low-frequency (LF) and high-frequency (HF) differences in images, affecting their effectiveness in removing reflections. To address this problem, this paper proposes a novel prompt-guided reflection removal (PromptRR) framework that uses frequency information as new visual prompts for better reflection performance. Specifically, the proposed framework decouples the reflection removal process into the prompt generation and subsequent prompt-guided restoration. For the prompt generation, we first propose a prompt pre-training strategy to train a frequency prompt encoder that encodes the ground-truth image into LF and HF prompts. Then, we adopt diffusion models (DMs) as prompt generators to generate the LF and HF prompts estimated by the pre-trained frequency prompt encoder. For the prompt-guided restoration, we integrate specially generated prompts into the PromptFormer network, employing a novel Transformer-based prompt block to effectively steer the model toward enhanced reflection removal. The results on commonly used benchmarks show that our method outperforms state-of-the-art approaches. The codes and models are available at https://github.com/TaoWangzj/PromptRR.
Dream360: Diverse and Immersive Outdoor Virtual Scene Creation via Transformer-Based 360 Image Outpainting
Jan 19, 2024



360 images, with a field-of-view (FoV) of 180x360, provide immersive and realistic environments for emerging virtual reality (VR) applications, such as virtual tourism, where users desire to create diverse panoramic scenes from a narrow FoV photo they take from a viewpoint via portable devices. It thus brings us to a technical challenge: `How to allow the users to freely create diverse and immersive virtual scenes from a narrow FoV image with a specified viewport?' To this end, we propose a transformer-based 360 image outpainting framework called Dream360, which can generate diverse, high-fidelity, and high-resolution panoramas from user-selected viewports, considering the spherical properties of 360 images. Compared with existing methods, e.g., [3], which primarily focus on inputs with rectangular masks and central locations while overlooking the spherical property of 360 images, our Dream360 offers higher outpainting flexibility and fidelity based on the spherical representation. Dream360 comprises two key learning stages: (I) codebook-based panorama outpainting via Spherical-VQGAN (S-VQGAN), and (II) frequency-aware refinement with a novel frequency-aware consistency loss. Specifically, S-VQGAN learns a sphere-specific codebook from spherical harmonic (SH) values, providing a better representation of spherical data distribution for scene modeling. The frequency-aware refinement matches the resolution and further improves the semantic consistency and visual fidelity of the generated results. Our Dream360 achieves significantly lower Frechet Inception Distance (FID) scores and better visual fidelity than existing methods. We also conducted a user study involving 15 participants to interactively evaluate the quality of the generated results in VR, demonstrating the flexibility and superiority of our Dream360 framework.
Deep Video Restoration for Under-Display Camera
Sep 09, 2023



Images or videos captured by the Under-Display Camera (UDC) suffer from severe degradation, such as saturation degeneration and color shift. While restoration for UDC has been a critical task, existing works of UDC restoration focus only on images. UDC video restoration (UDC-VR) has not been explored in the community. In this work, we first propose a GAN-based generation pipeline to simulate the realistic UDC degradation process. With the pipeline, we build the first large-scale UDC video restoration dataset called PexelsUDC, which includes two subsets named PexelsUDC-T and PexelsUDC-P corresponding to different displays for UDC. Using the proposed dataset, we conduct extensive benchmark studies on existing video restoration methods and observe their limitations on the UDC-VR task. To this end, we propose a novel transformer-based baseline method that adaptively enhances degraded videos. The key components of the method are a spatial branch with local-aware transformers, a temporal branch embedded temporal transformers, and a spatial-temporal fusion module. These components drive the model to fully exploit spatial and temporal information for UDC-VR. Extensive experiments show that our method achieves state-of-the-art performance on PexelsUDC. The benchmark and the baseline method are expected to promote the progress of UDC-VR in the community, which will be made public.
LLDiffusion: Learning Degradation Representations in Diffusion Models for Low-Light Image Enhancement
Jul 27, 2023Current deep learning methods for low-light image enhancement (LLIE) typically rely on pixel-wise mapping learned from paired data. However, these methods often overlook the importance of considering degradation representations, which can lead to sub-optimal outcomes. In this paper, we address this limitation by proposing a degradation-aware learning scheme for LLIE using diffusion models, which effectively integrates degradation and image priors into the diffusion process, resulting in improved image enhancement. Our proposed degradation-aware learning scheme is based on the understanding that degradation representations play a crucial role in accurately modeling and capturing the specific degradation patterns present in low-light images. To this end, First, a joint learning framework for both image generation and image enhancement is presented to learn the degradation representations. Second, to leverage the learned degradation representations, we develop a Low-Light Diffusion model (LLDiffusion) with a well-designed dynamic diffusion module. This module takes into account both the color map and the latent degradation representations to guide the diffusion process. By incorporating these conditioning factors, the proposed LLDiffusion can effectively enhance low-light images, considering both the inherent degradation patterns and the desired color fidelity. Finally, we evaluate our proposed method on several well-known benchmark datasets, including synthetic and real-world unpaired datasets. Extensive experiments on public benchmarks demonstrate that our LLDiffusion outperforms state-of-the-art LLIE methods both quantitatively and qualitatively. The source code and pre-trained models are available at https://github.com/TaoWangzj/LLDiffusion.