 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models
May 19, 2023Stereotype benchmark datasets are crucial to detect and mitigate social stereotypes about groups of people in NLP models. However, existing datasets are limited in size and coverage, and are largely restricted to stereotypes prevalent in the Western society. This is especially problematic as language technologies gain hold across the globe. To address this gap, we present SeeGULL, a broad-coverage stereotype dataset, built by utilizing generative capabilities of large language models such as PaLM, and GPT-3, and leveraging a globally diverse rater pool to validate the prevalence of those stereotypes in society. SeeGULL is in English, and contains stereotypes about identity groups spanning 178 countries across 8 different geo-political regions across 6 continents, as well as state-level identities within the US and India. We also include fine-grained offensiveness scores for different stereotypes and demonstrate their global disparities. Furthermore, we include comparative annotations about the same groups by annotators living in the region vs. those that are based in North America, and demonstrate that within-region stereotypes about groups differ from those prevalent in North America. CONTENT WARNING: This paper contains stereotype examples that may be offensive.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Cultural Re-contextualization of Fairness Research in Language Technologies in India
Nov 21, 2022

Recent research has revealed undesirable biases in NLP data and models. However, these efforts largely focus on social disparities in the West, and are not directly portable to other geo-cultural contexts. In this position paper, we outline a holistic research agenda to re-contextualize NLP fairness research for the Indian context, accounting for Indian societal context, bridging technological gaps in capability and resources, and adapting to Indian cultural values. We also summarize findings from an empirical study on various social biases along different axes of disparities relevant to India, demonstrating their prevalence in corpora and models.
Auditing Algorithmic Fairness in Machine Learning for Health with Severity-Based LOGAN
Nov 16, 2022



Auditing machine learning-based (ML) healthcare tools for bias is critical to preventing patient harm, especially in communities that disproportionately face health inequities. General frameworks are becoming increasingly available to measure ML fairness gaps between groups. However, ML for health (ML4H) auditing principles call for a contextual, patient-centered approach to model assessment. Therefore, ML auditing tools must be (1) better aligned with ML4H auditing principles and (2) able to illuminate and characterize communities vulnerable to the most harm. To address this gap, we propose supplementing ML4H auditing frameworks with SLOGAN (patient Severity-based LOcal Group biAs detectioN), an automatic tool for capturing local biases in a clinical prediction task. SLOGAN adapts an existing tool, LOGAN (LOcal Group biAs detectioN), by contextualizing group bias detection in patient illness severity and past medical history. We investigate and compare SLOGAN's bias detection capabilities to LOGAN and other clustering techniques across patient subgroups in the MIMIC-III dataset. On average, SLOGAN identifies larger fairness disparities in over 75% of patient groups than LOGAN while maintaining clustering quality. Furthermore, in a diabetes case study, health disparity literature corroborates the characterizations of the most biased clusters identified by SLOGAN. Our results contribute to the broader discussion of how machine learning biases may perpetuate existing healthcare disparities.
The Tail Wagging the Dog: Dataset Construction Biases of Social Bias Benchmarks
Oct 18, 2022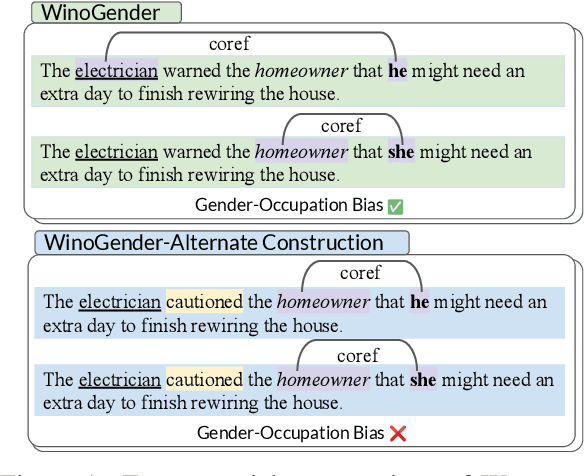
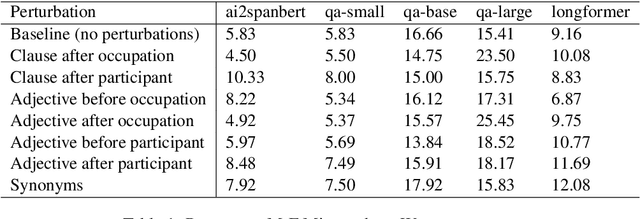


How reliably can we trust the scores obtained from social bias benchmarks as faithful indicators of problematic social biases in a given language model? In this work, we study this question by contrasting social biases with non-social biases stemming from choices made during dataset construction that might not even be discernible to the human eye. To do so, we empirically simulate various alternative constructions for a given benchmark based on innocuous modifications (such as paraphrasing or random-sampling) that maintain the essence of their social bias. On two well-known social bias benchmarks (Winogender and BiasNLI) we observe that these shallow modifications have a surprising effect on the resulting degree of bias across various models. We hope these troubling observations motivate more robust measures of social biases.
Re-contextualizing Fairness in NLP: The Case of India
Oct 12, 2022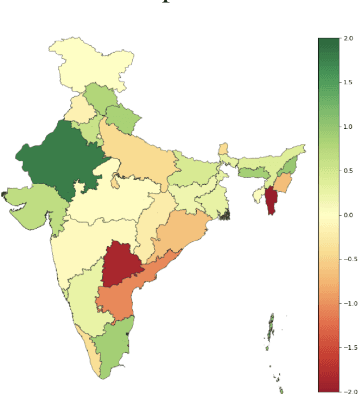

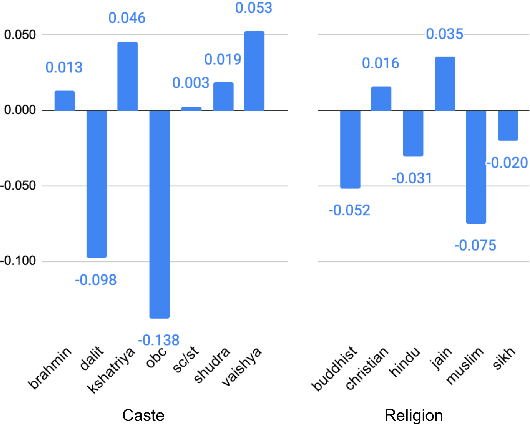
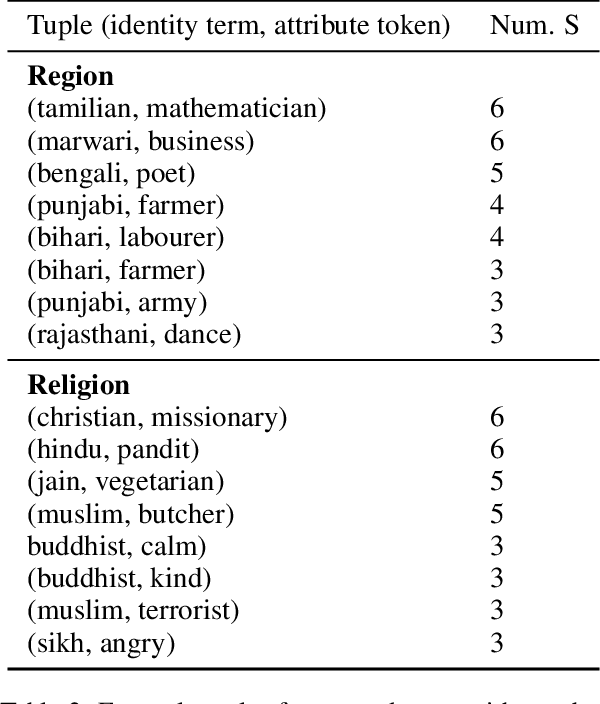
Recent research has revealed undesirable bi-ases in NLP data and models. However, theseefforts focus of social disparities in West, andare not directly portable to other geo-culturalcontexts. In this paper, we focus on NLP fair-ness in the context of India. We start witha brief account of the prominent axes of so-cial disparities in India. We build resourcesfor fairness evaluation in the Indian contextand use them to demonstrate prediction bi-ases along some of the axes. We then delvedeeper into social stereotypes for Region andReligion, demonstrating its prevalence in cor-pora and models. Finally, we outline a holis-tic research agenda to re-contextualize NLPfairness research for the Indian context, ac-counting for Indiansocietal context, bridgingtechnologicalgaps in NLP capabilities and re-sources, and adapting to Indian culturalvalues.While we focus on India, this framework canbe generalized to other geo-cultural contexts.
DisinfoMeme: A Multimodal Dataset for Detecting Meme Intentionally Spreading Out Disinformation
May 25, 2022
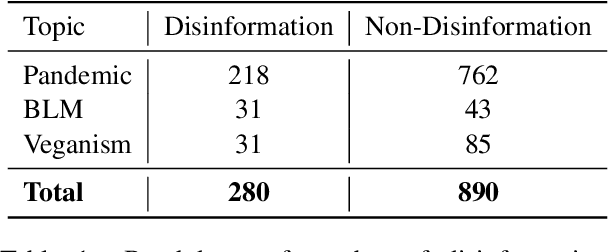

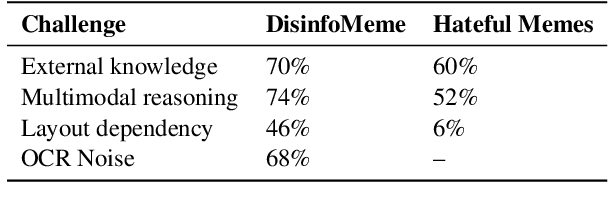
Disinformation has become a serious problem on social media. In particular, given their short format, visual attraction, and humorous nature, memes have a significant advantage in dissemination among online communities, making them an effective vehicle for the spread of disinformation. We present DisinfoMeme to help detect disinformation memes. The dataset contains memes mined from Reddit covering three current topics: the COVID-19 pandemic, the Black Lives Matter movement, and veganism/vegetarianism. The dataset poses multiple unique challenges: limited data and label imbalance, reliance on external knowledge, multimodal reasoning, layout dependency, and noise from OCR. We test multiple widely-used unimodal and multimodal models on this dataset. The experiments show that the room for improvement is still huge for current models.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Representation Learning for Resource-Constrained Keyphrase Generation
Mar 15, 2022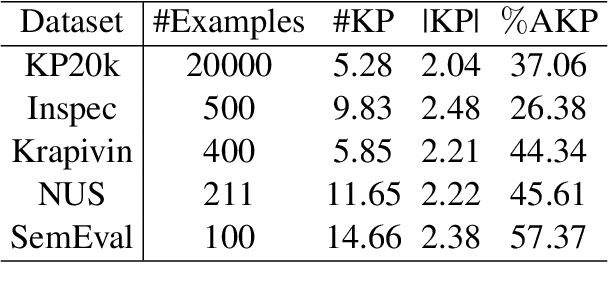
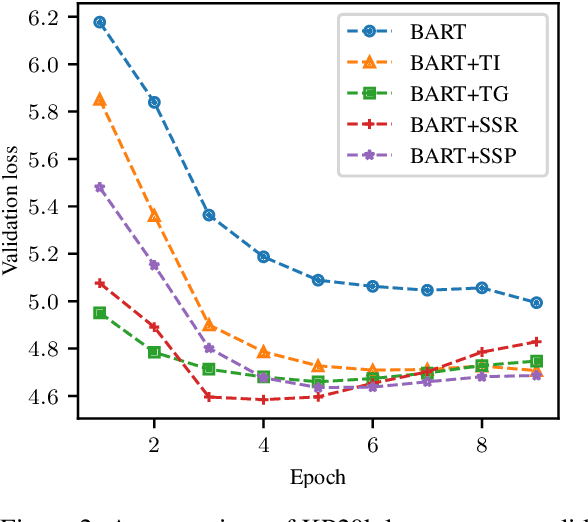
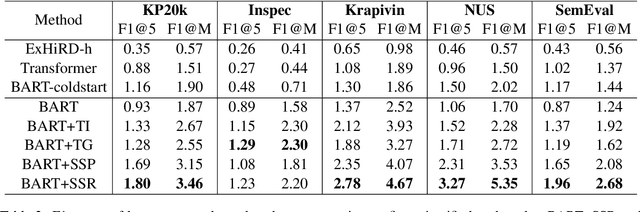
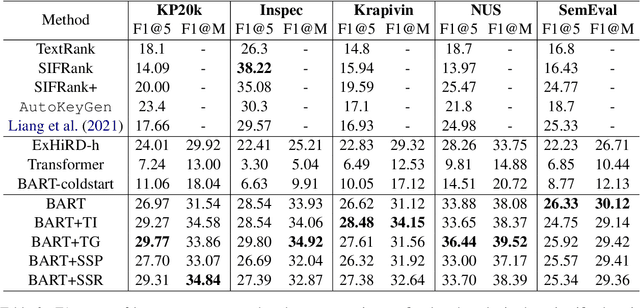
State-of-the-art keyphrase generation methods generally depend on large annotated datasets, limiting their performance in domains with constrained resources. To overcome this challenge, we investigate strategies to learn an intermediate representation suitable for the keyphrase generation task. We introduce salient span recovery and salient span prediction as guided denoising language modeling objectives that condense the domain-specific knowledge essential for keyphrase generation. Through experiments on multiple scientific keyphrase generation benchmarks, we show the effectiveness of the proposed approach for facilitating low-resource and zero-shot keyphrase generation. Furthermore, we observe that our method especially benefits the generation of absent keyphrases, approaching the performance of SOTA methods trained with large training sets.
Socially Aware Bias Measurements for Hindi Language Representations
Oct 15, 2021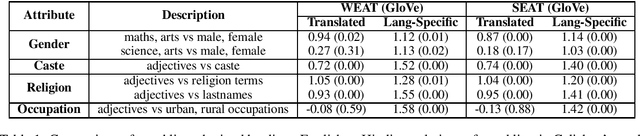
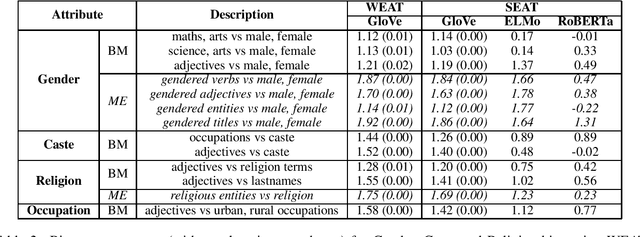
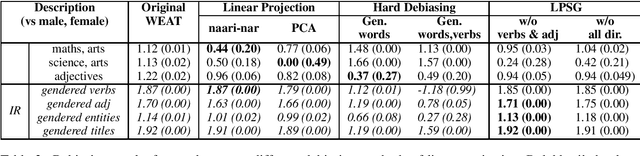
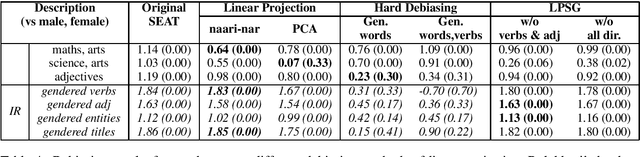
Language representations are an efficient tool used across NLP, but they are strife with encoded societal biases. These biases are studied extensively, but with a primary focus on English language representations and biases common in the context of Western society. In this work, we investigate the biases present in Hindi language representations such as caste and religion associated biases. We demonstrate how biases are unique to specific language representations based on the history and culture of the region they are widely spoken in, and also how the same societal bias (such as binary gender associated biases) when investigated across languages is encoded by different words and text spans. With this work, we emphasize on the necessity of social-awareness along with linguistic and grammatical artefacts when modeling language representations, in order to understand the biases encoded.