 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteTransformerSearch: Training-free On-device Search for Efficient Autoregressive Language Models
Mar 04, 2022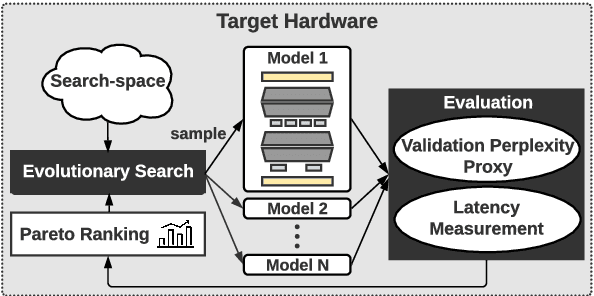
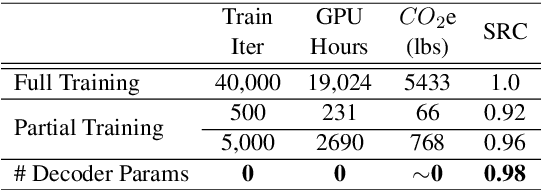
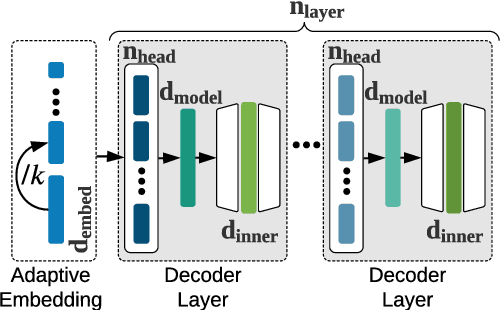

The transformer architecture is ubiquitously used as the building block of most large-scale language models. However, it remains a painstaking guessing game of trial and error to set its myriad of architectural hyperparameters, e.g., number of layers, number of attention heads, and inner size of the feed forward network, and find architectures with the optimal trade-off between task performance like perplexity and compute constraints like memory and latency. This challenge is further exacerbated by the proliferation of various hardware. In this work, we leverage the somewhat surprising empirical observation that the number of non-embedding parameters in autoregressive transformers has a high rank correlation with task performance, irrespective of the architectural hyperparameters. Since architectural hyperparameters affect the latency and memory footprint in a hardware-dependent manner, the above observation organically induces a simple search algorithm that can be directly run on target devices. We rigorously show that the latency and perplexity pareto-frontier can be found without need for any model training, using non-embedding parameters as a proxy for perplexity. We evaluate our method, dubbed Lightweight Transformer Search (LTS), on diverse devices from ARM CPUs to Nvidia GPUs and show that the perplexity of Transformer-XL can be achieved with up to 2x lower latency. LTS extracts the pareto-frontier in less than 3 hours while running on a commodity laptop. We effectively remove the carbon footprint of training for hundreds of GPU hours, offering a strong simple baseline for future NAS methods in autoregressive language modeling.
AutoDistil: Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models
Jan 29, 2022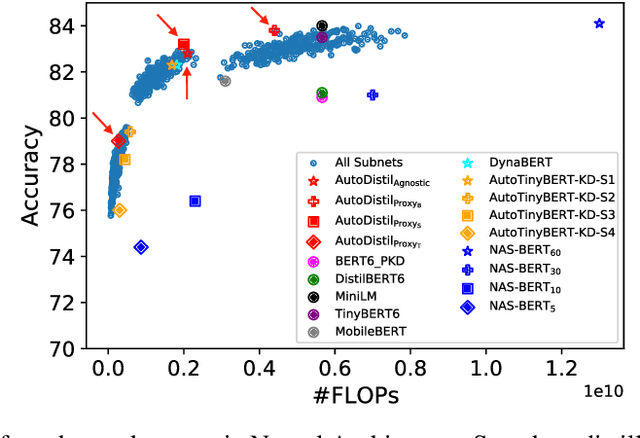
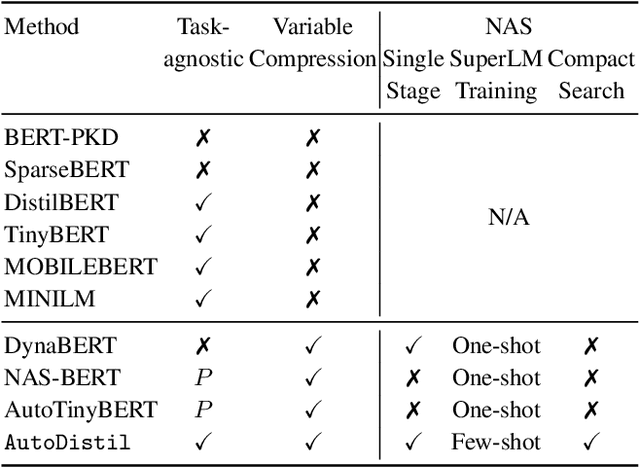
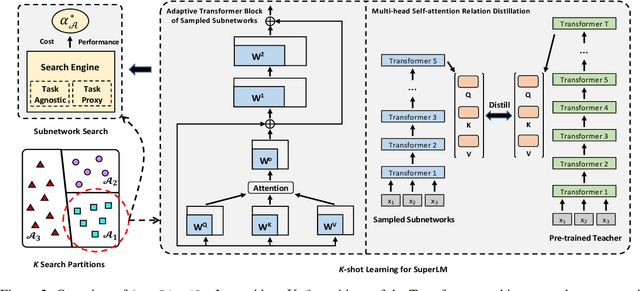
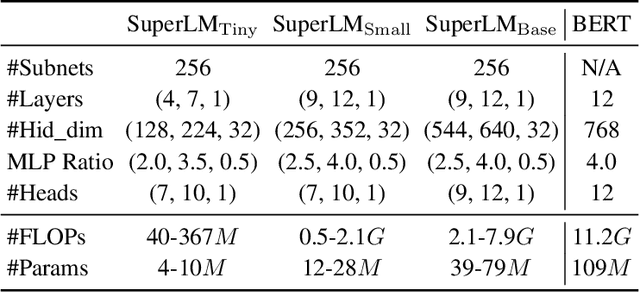
Knowledge distillation (KD) methods compress large models into smaller students with manually-designed student architectures given pre-specified computational cost. This requires several trials to find a viable student, and further repeating the process for each student or computational budget change. We use Neural Architecture Search (NAS) to automatically distill several compressed students with variable cost from a large model. Current works train a single SuperLM consisting of millions of subnetworks with weight-sharing, resulting in interference between subnetworks of different sizes. Our framework AutoDistil addresses above challenges with the following steps: (a) Incorporates inductive bias and heuristics to partition Transformer search space into K compact sub-spaces (K=3 for typical student sizes of base, small and tiny); (b) Trains one SuperLM for each sub-space using task-agnostic objective (e.g., self-attention distillation) with weight-sharing of students; (c) Lightweight search for the optimal student without re-training. Fully task-agnostic training and search allow students to be reused for fine-tuning on any downstream task. Experiments on GLUE benchmark against state-of-the-art KD and NAS methods demonstrate AutoDistil to outperform leading compression techniques with upto 2.7x reduction in computational cost and negligible loss in task performance.
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
Nov 04, 2021
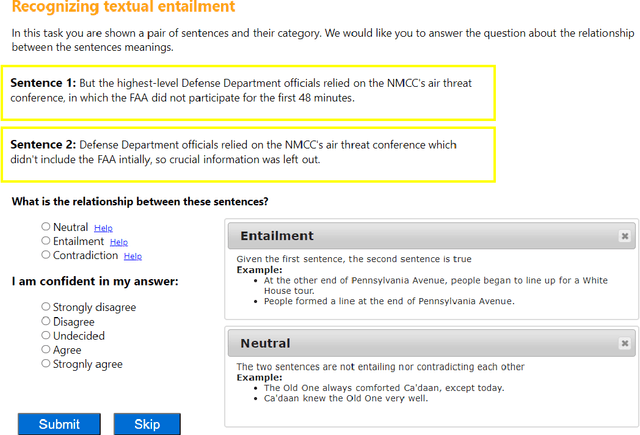

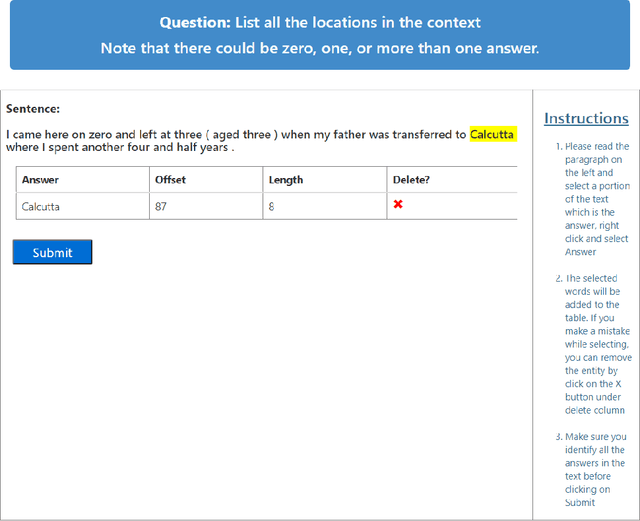
Most recent progress in natural language understanding (NLU) has been driven, in part, by benchmarks such as GLUE, SuperGLUE, SQuAD, etc. In fact, many NLU models have now matched or exceeded "human-level" performance on many tasks in these benchmarks. Most of these benchmarks, however, give models access to relatively large amounts of labeled data for training. As such, the models are provided far more data than required by humans to achieve strong performance. That has motivated a line of work that focuses on improving few-shot learning performance of NLU models. However, there is a lack of standardized evaluation benchmarks for few-shot NLU resulting in different experimental settings in different papers. To help accelerate this line of work, we introduce CLUES (Constrained Language Understanding Evaluation Standard), a benchmark for evaluating the few-shot learning capabilities of NLU models. We demonstrate that while recent models reach human performance when they have access to large amounts of labeled data, there is a huge gap in performance in the few-shot setting for most tasks. We also demonstrate differences between alternative model families and adaptation techniques in the few shot setting. Finally, we discuss several principles and choices in designing the experimental settings for evaluating the true few-shot learning performance and suggest a unified standardized approach to few-shot learning evaluation. We aim to encourage research on NLU models that can generalize to new tasks with a small number of examples. Code and data for CLUES are available at https://github.com/microsoft/CLUES.
What do Compressed Large Language Models Forget? Robustness Challenges in Model Compression
Oct 16, 2021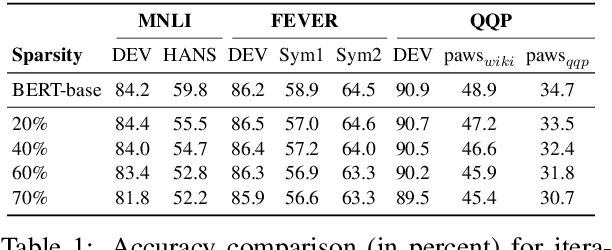
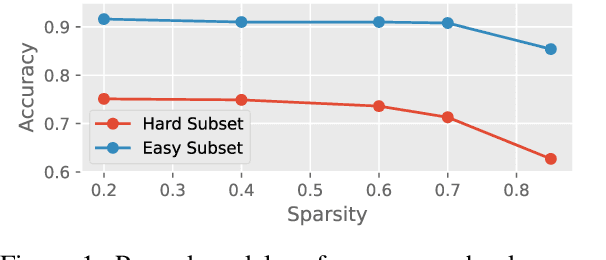
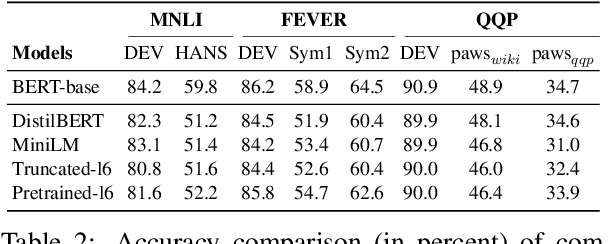
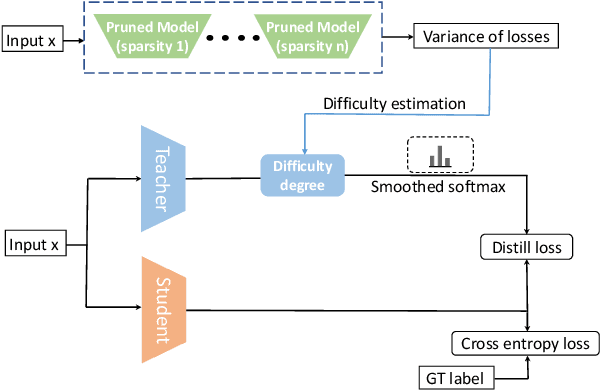
Recent works have focused on compressing pre-trained language models (PLMs) like BERT where the major focus has been to improve the compressed model performance for downstream tasks. However, there has been no study in analyzing the impact of compression on the generalizability and robustness of these models. Towards this end, we study two popular model compression techniques including knowledge distillation and pruning and show that compressed models are significantly less robust than their PLM counterparts on adversarial test sets although they obtain similar performance on in-distribution development sets for a task. Further analysis indicates that the compressed models overfit on the easy samples and generalize poorly on the hard ones. We further leverage this observation to develop a regularization strategy for model compression based on sample uncertainty. Experimental results on several natural language understanding tasks demonstrate our mitigation framework to improve both the adversarial generalization as well as in-distribution task performance of the compressed models.
LiST: Lite Self-training Makes Efficient Few-shot Learners
Oct 12, 2021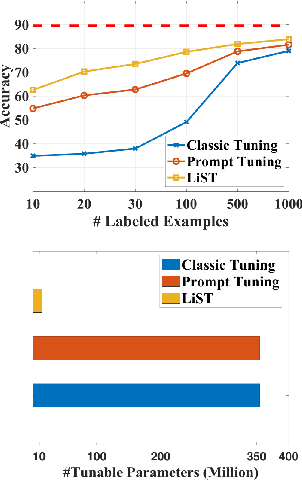
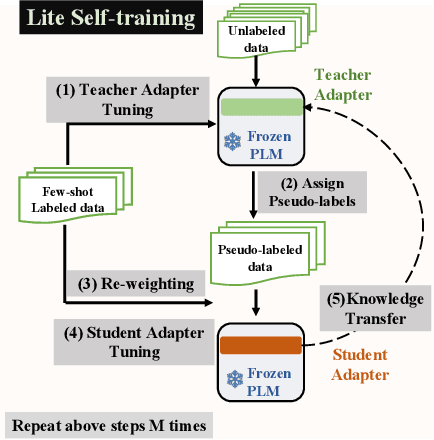
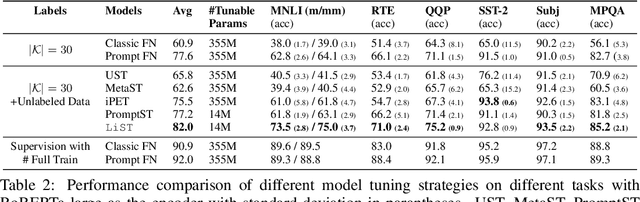
We present a new method LiST for efficient fine-tuning of large pre-trained language models (PLMs) in few-shot learning settings. LiST significantly improves over recent methods that adopt prompt fine-tuning using two key techniques. The first one is the use of self-training to leverage large amounts of unlabeled data for prompt-tuning to significantly boost the model performance in few-shot settings. We use self-training in conjunction with meta-learning for re-weighting noisy pseudo-prompt labels. However, traditional self-training is expensive as it requires updating all the model parameters repetitively. Therefore, we use a second technique for light-weight fine-tuning where we introduce a small number of task-specific adapter parameters that are fine-tuned during self-training while keeping the PLM encoder frozen. This also significantly reduces the overall model footprint across several tasks that can now share a common PLM encoder as backbone for inference. Combining the above techniques, LiST not only improves the model performance for few-shot learning on target domains but also reduces the model memory footprint. We present a comprehensive study on six NLU tasks to validate the effectiveness of LiST. The results show that LiST improves by 35% over classic fine-tuning methods and 6% over prompt-tuning with 96% reduction in number of trainable parameters when fine-tuned with no more than 30 labeled examples from each target domain.
Self-training with Few-shot Rationalization: Teacher Explanations Aid Student in Few-shot NLU
Sep 17, 2021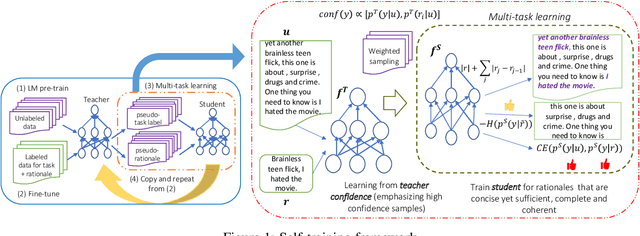
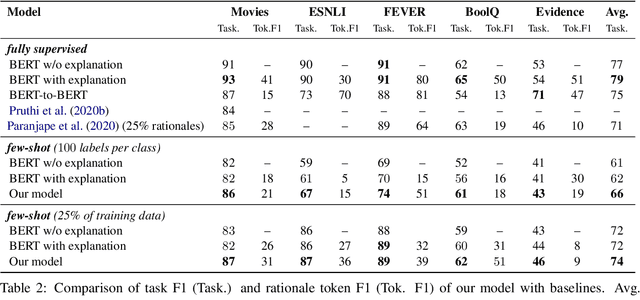

While pre-trained language models have obtained state-of-the-art performance for several natural language understanding tasks, they are quite opaque in terms of their decision-making process. While some recent works focus on rationalizing neural predictions by highlighting salient concepts in the text as justifications or rationales, they rely on thousands of labeled training examples for both task labels as well as an-notated rationales for every instance. Such extensive large-scale annotations are infeasible to obtain for many tasks. To this end, we develop a multi-task teacher-student framework based on self-training language models with limited task-specific labels and rationales, and judicious sample selection to learn from informative pseudo-labeled examples1. We study several characteristics of what constitutes a good rationale and demonstrate that the neural model performance can be significantly improved by making it aware of its rationalized predictions, particularly in low-resource settings. Extensive experiments in several bench-mark datasets demonstrate the effectiveness of our approach.
Fairness via Representation Neutralization
Jun 23, 2021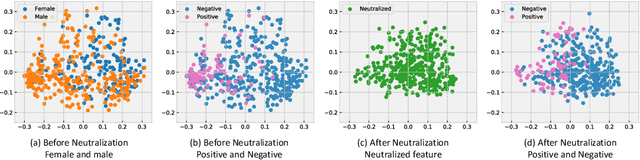
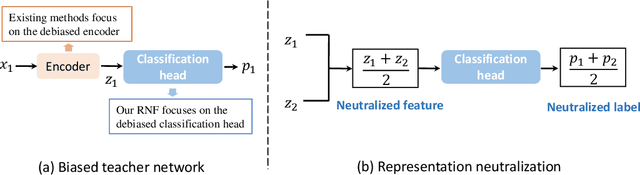
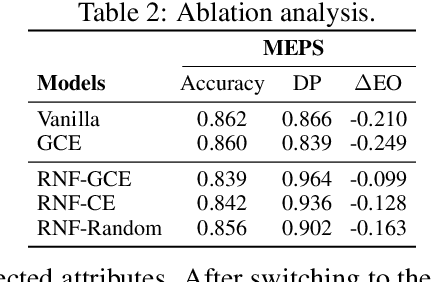
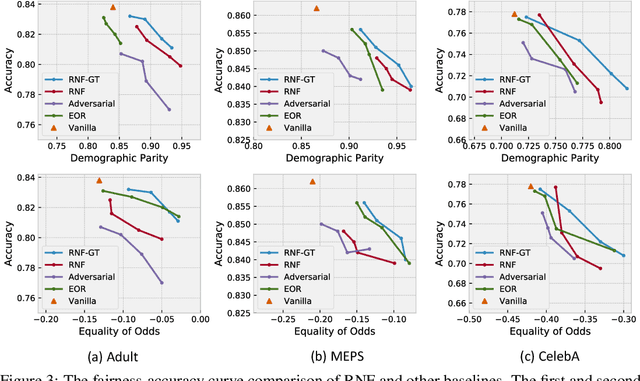
Existing bias mitigation methods for DNN models primarily work on learning debiased encoders. This process not only requires a lot of instance-level annotations for sensitive attributes, it also does not guarantee that all fairness sensitive information has been removed from the encoder. To address these limitations, we explore the following research question: Can we reduce the discrimination of DNN models by only debiasing the classification head, even with biased representations as inputs? To this end, we propose a new mitigation technique, namely, Representation Neutralization for Fairness (RNF) that achieves fairness by debiasing only the task-specific classification head of DNN models. To this end, we leverage samples with the same ground-truth label but different sensitive attributes, and use their neutralized representations to train the classification head of the DNN model. The key idea of RNF is to discourage the classification head from capturing spurious correlation between fairness sensitive information in encoder representations with specific class labels. To address low-resource settings with no access to sensitive attribute annotations, we leverage a bias-amplified model to generate proxy annotations for sensitive attributes. Experimental results over several benchmark datasets demonstrate our RNF framework to effectively reduce discrimination of DNN models with minimal degradation in task-specific performance.
XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation
Jun 12, 2021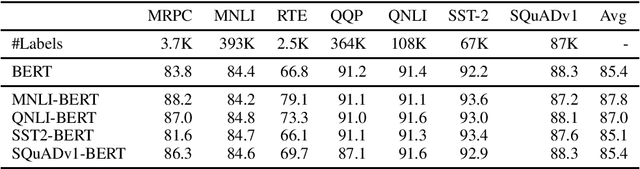


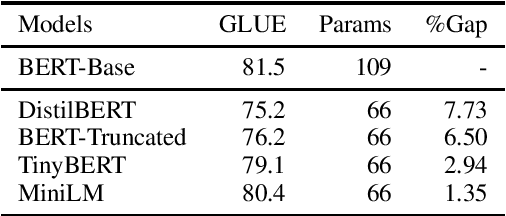
While deep and large pre-trained models are the state-of-the-art for various natural language processing tasks, their huge size poses significant challenges for practical uses in resource constrained settings. Recent works in knowledge distillation propose task-agnostic as well as task-specific methods to compress these models, with task-specific ones often yielding higher compression rate. In this work, we develop a new task-agnostic distillation framework XtremeDistilTransformers that leverages the advantage of task-specific methods for learning a small universal model that can be applied to arbitrary tasks and languages. To this end, we study the transferability of several source tasks, augmentation resources and model architecture for distillation. We evaluate our model performance on multiple tasks, including the General Language Understanding Evaluation (GLUE) benchmark, SQuAD question answering dataset and a massive multi-lingual NER dataset with 41 languages. We release three distilled task-agnostic checkpoints with 13MM, 22MM and 33MM parameters obtaining SOTA performance in several tasks.
MetaXL: Meta Representation Transformation for Low-resource Cross-lingual Learning
Apr 16, 2021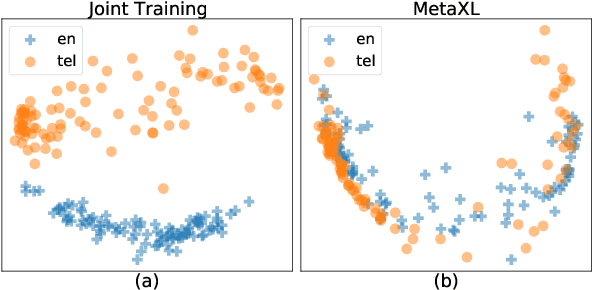
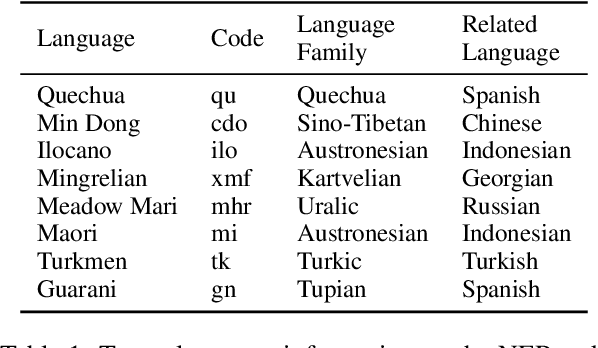
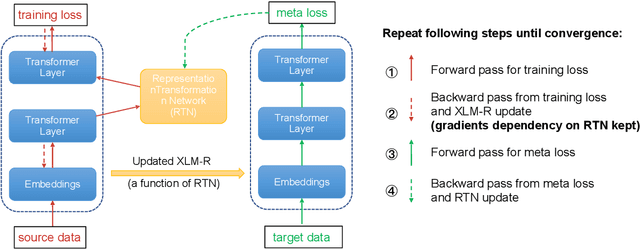
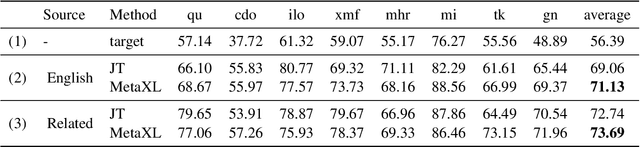
The combination of multilingual pre-trained representations and cross-lingual transfer learning is one of the most effective methods for building functional NLP systems for low-resource languages. However, for extremely low-resource languages without large-scale monolingual corpora for pre-training or sufficient annotated data for fine-tuning, transfer learning remains an under-studied and challenging task. Moreover, recent work shows that multilingual representations are surprisingly disjoint across languages, bringing additional challenges for transfer onto extremely low-resource languages. In this paper, we propose MetaXL, a meta-learning based framework that learns to transform representations judiciously from auxiliary languages to a target one and brings their representation spaces closer for effective transfer. Extensive experiments on real-world low-resource languages - without access to large-scale monolingual corpora or large amounts of labeled data - for tasks like cross-lingual sentiment analysis and named entity recognition show the effectiveness of our approach. Code for MetaXL is publicly available at github.com/microsoft/MetaXL.
Self-Training with Weak Supervision
Apr 12, 2021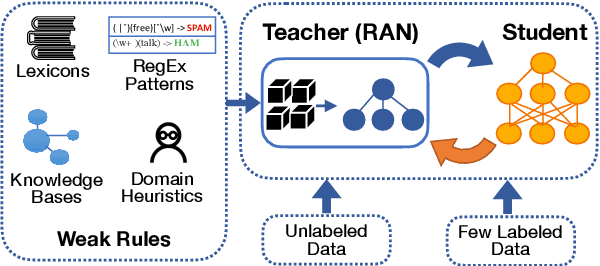
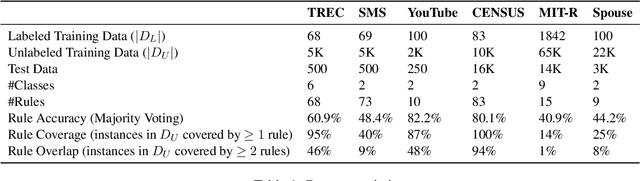
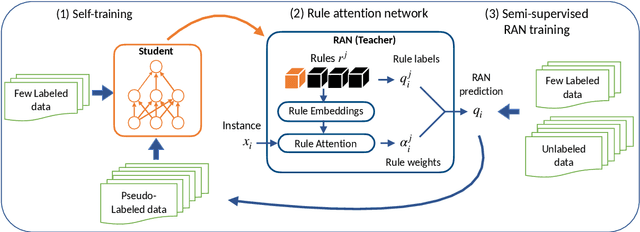
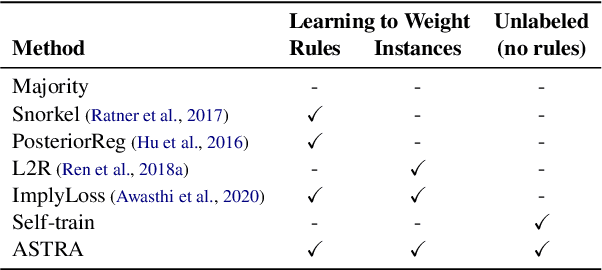
State-of-the-art deep neural networks require large-scale labeled training data that is often expensive to obtain or not available for many tasks. Weak supervision in the form of domain-specific rules has been shown to be useful in such settings to automatically generate weakly labeled training data. However, learning with weak rules is challenging due to their inherent heuristic and noisy nature. An additional challenge is rule coverage and overlap, where prior work on weak supervision only considers instances that are covered by weak rules, thus leaving valuable unlabeled data behind. In this work, we develop a weak supervision framework (ASTRA) that leverages all the available data for a given task. To this end, we leverage task-specific unlabeled data through self-training with a model (student) that considers contextualized representations and predicts pseudo-labels for instances that may not be covered by weak rules. We further develop a rule attention network (teacher) that learns how to aggregate student pseudo-labels with weak rule labels, conditioned on their fidelity and the underlying context of an instance. Finally, we construct a semi-supervised learning objective for end-to-end training with unlabeled data, domain-specific rules, and a small amount of labeled data. Extensive experiments on six benchmark datasets for text classification demonstrate the effectiveness of our approach with significant improvements over state-of-the-art baselines.