 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKathDB: Explainable Multimodal Database Management System with Human-AI Collaboration
Dec 11, 2025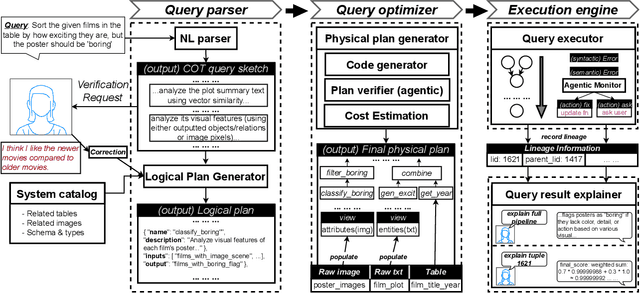

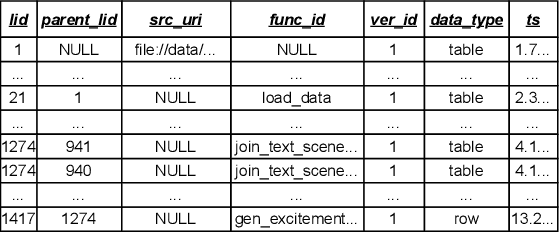
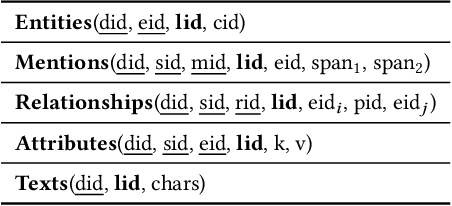
Traditional DBMSs execute user- or application-provided SQL queries over relational data with strong semantic guarantees and advanced query optimization, but writing complex SQL is hard and focuses only on structured tables. Contemporary multimodal systems (which operate over relations but also text, images, and even videos) either expose low-level controls that force users to use (and possibly create) machine learning UDFs manually within SQL or offload execution entirely to black-box LLMs, sacrificing usability or explainability. We propose KathDB, a new system that combines relational semantics with the reasoning power of foundation models over multimodal data. Furthermore, KathDB includes human-AI interaction channels during query parsing, execution, and result explanation, such that users can iteratively obtain explainable answers across data modalities.
ULFine: Unbiased Lightweight Fine-tuning for Foundation-Model-Assisted Long-Tailed Semi-Supervised Learning
May 08, 2025Based on the success of large-scale visual foundation models like CLIP in various downstream tasks, this paper initially attempts to explore their impact on Long-Tailed Semi-Supervised Learning (LTSSL) by employing the foundation model with three strategies: Linear Probing (LP), Lightweight Fine-Tuning (LFT), and Full Fine-Tuning (FFT). Our analysis presents the following insights: i) Compared to LTSSL algorithms trained from scratch, FFT results in a decline in model performance, whereas LP and LFT, although boosting overall model performance, exhibit negligible benefits to tail classes. ii) LP produces numerous false pseudo-labels due to \textit{underlearned} training data, while LFT can reduce the number of these false labels but becomes overconfident about them owing to \textit{biased fitting} training data. This exacerbates the pseudo-labeled and classifier biases inherent in LTSSL, limiting performance improvement in the tail classes. With these insights, we propose a Unbiased Lightweight Fine-tuning strategy, \textbf{ULFine}, which mitigates the overconfidence via confidence-aware adaptive fitting of textual prototypes and counteracts the pseudo-labeled and classifier biases via complementary fusion of dual logits. Extensive experiments demonstrate that ULFine markedly decreases training costs by over ten times and substantially increases prediction accuracies compared to state-of-the-art methods.
Recent Advances in Out-of-Distribution Detection with CLIP-Like Models: A Survey
May 05, 2025Out-of-distribution detection (OOD) is a pivotal task for real-world applications that trains models to identify samples that are distributionally different from the in-distribution (ID) data during testing. Recent advances in AI, particularly Vision-Language Models (VLMs) like CLIP, have revolutionized OOD detection by shifting from traditional unimodal image detectors to multimodal image-text detectors. This shift has inspired extensive research; however, existing categorization schemes (e.g., few- or zero-shot types) still rely solely on the availability of ID images, adhering to a unimodal paradigm. To better align with CLIP's cross-modal nature, we propose a new categorization framework rooted in both image and text modalities. Specifically, we categorize existing methods based on how visual and textual information of OOD data is utilized within image + text modalities, and further divide them into four groups: OOD Images (i.e., outliers) Seen or Unseen, and OOD Texts (i.e., learnable vectors or class names) Known or Unknown, across two training strategies (i.e., train-free or training-required). More importantly, we discuss open problems in CLIP-like OOD detection and highlight promising directions for future research, including cross-domain integration, practical applications, and theoretical understanding.
All-around Neural Collapse for Imbalanced Classification
Aug 14, 2024



Neural Collapse (NC) presents an elegant geometric structure that enables individual activations (features), class means and classifier (weights) vectors to reach \textit{optimal} inter-class separability during the terminal phase of training on a \textit{balanced} dataset. Once shifted to imbalanced classification, such an optimal structure of NC can be readily destroyed by the notorious \textit{minority collapse}, where the classifier vectors corresponding to the minority classes are squeezed. In response, existing works endeavor to recover NC typically by optimizing classifiers. However, we discover that this squeezing phenomenon is not only confined to classifier vectors but also occurs with class means. Consequently, reconstructing NC solely at the classifier aspect may be futile, as the feature means remain compressed, leading to the violation of inherent \textit{self-duality} in NC (\textit{i.e.}, class means and classifier vectors converge mutually) and incidentally, resulting in an unsatisfactory collapse of individual activations towards the corresponding class means. To shake off these dilemmas, we present a unified \textbf{All}-around \textbf{N}eural \textbf{C}ollapse framework (AllNC), aiming to comprehensively restore NC across multiple aspects including individual activations, class means and classifier vectors. We thoroughly analyze its effectiveness and verify on multiple benchmark datasets that it achieves state-of-the-art in both balanced and imbalanced settings.
All Beings Are Equal in Open Set Recognition
Jan 31, 2024In open-set recognition (OSR), a promising strategy is exploiting pseudo-unknown data outside given $K$ known classes as an additional $K$+$1$-th class to explicitly model potential open space. However, treating unknown classes without distinction is unequal for them relative to known classes due to the category-agnostic and scale-agnostic of the unknowns. This inevitably not only disrupts the inherent distributions of unknown classes but also incurs both class-wise and instance-wise imbalances between known and unknown classes. Ideally, the OSR problem should model the whole class space as $K$+$\infty$, but enumerating all unknowns is impractical. Since the core of OSR is to effectively model the boundaries of known classes, this means just focusing on the unknowns nearing the boundaries of targeted known classes seems sufficient. Thus, as a compromise, we convert the open classes from infinite to $K$, with a novel concept Target-Aware Universum (TAU) and propose a simple yet effective framework Dual Contrastive Learning with Target-Aware Universum (DCTAU). In details, guided by the targeted known classes, TAU automatically expands the unknown classes from the previous $1$ to $K$, effectively alleviating the distribution disruption and the imbalance issues mentioned above. Then, a novel Dual Contrastive (DC) loss is designed, where all instances irrespective of known or TAU are considered as positives to contrast with their respective negatives. Experimental results indicate DCTAU sets a new state-of-the-art.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building
Mar 07, 2023



We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.
Class-Aware Universum Inspired Re-Balance Learning for Long-Tailed Recognition
Aug 11, 2022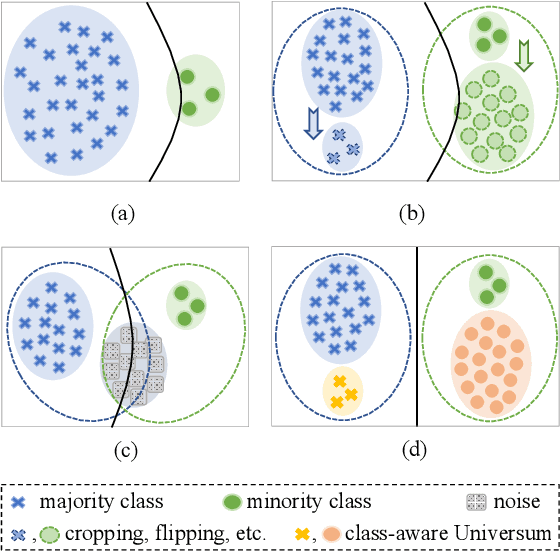

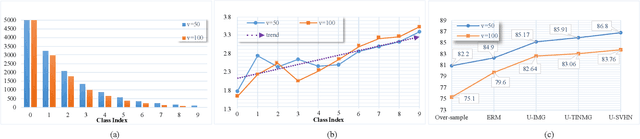

Data augmentation for minority classes is an effective strategy for long-tailed recognition, thus developing a large number of methods. Although these methods all ensure the balance in sample quantity, the quality of the augmented samples is not always satisfactory for recognition, being prone to such problems as over-fitting, lack of diversity, semantic drift, etc. For these issues, we propose the Class-aware Universum Inspired Re-balance Learning(CaUIRL) for long-tailed recognition, which endows the Universum with class-aware ability to re-balance individual minority classes from both sample quantity and quality. In particular, we theoretically prove that the classifiers learned by CaUIRL are consistent with those learned under the balanced condition from a Bayesian perspective. In addition, we further develop a higher-order mixup approach, which can automatically generate class-aware Universum(CaU) data without resorting to any external data. Unlike the traditional Universum, such generated Universum additionally takes the domain similarity, class separability, and sample diversity into account. Extensive experiments on benchmark datasets demonstrate the surprising advantages of our method, especially the top1 accuracy in minority classes is improved by 1.9% 6% compared to the state-of-the-art method.