 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Reinforcement Learning (QUARL)
Oct 04, 2019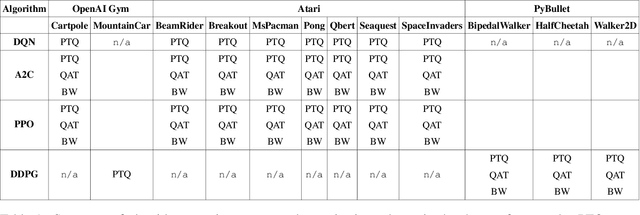
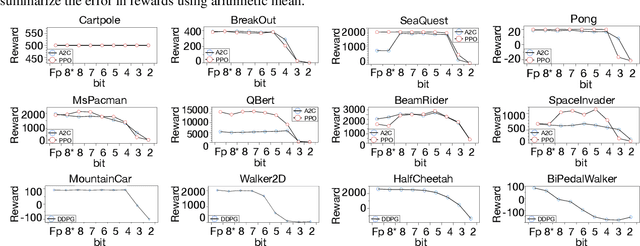
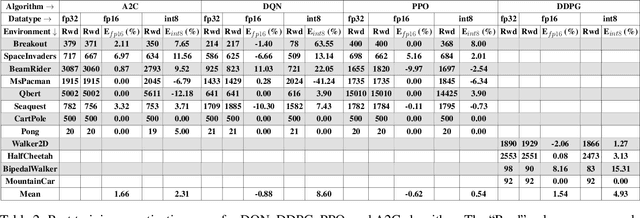
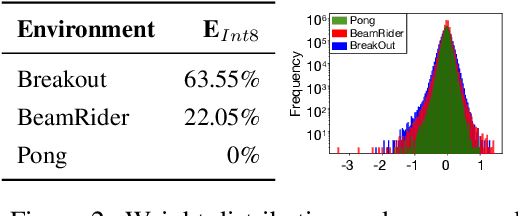
Recent work has shown that quantization can help reduce the memory, compute, and energy demands of deep neural networks without significantly harming their quality. However, whether these prior techniques, applied traditionally to image-based models, work with the same efficacy to the sequential decision making process in reinforcement learning remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the effects of quantization on various deep reinforcement learning policies with the intent to reduce their computational resource demands. We apply techniques such as post-training quantization and quantization aware training to a spectrum of reinforcement learning tasks (such as Pong, Breakout, BeamRider and more) and training algorithms (such as PPO, A2C, DDPG, and DQN). Across this spectrum of tasks and learning algorithms, we show that policies can be quantized to 6-8 bits of precision without loss of accuracy. We also show that certain tasks and reinforcement learning algorithms yield policies that are more difficult to quantize due to their effect of widening the models' distribution of weights and that quantization aware training consistently improves results over post-training quantization and oftentimes even over the full precision baseline. Finally, we demonstrate real-world applications of quantization for reinforcement learning. We use half-precision training to train a Pong model 50% faster, and we deploy a quantized reinforcement learning based navigation policy to an embedded system, achieving an 18$\times$ speedup and a 4$\times$ reduction in memory usage over an unquantized policy.
Learning to Seek: Autonomous Source Seeking with Deep Reinforcement Learning Onboard a Nano Drone Microcontroller
Sep 29, 2019


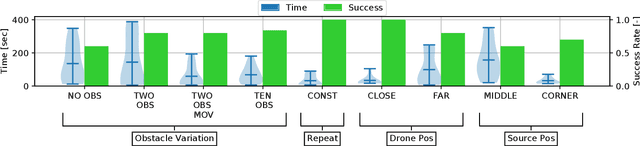
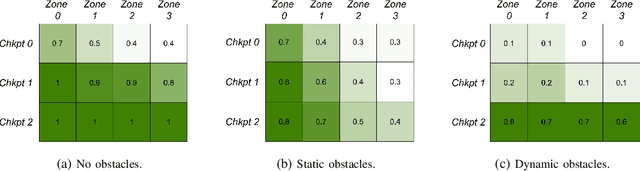
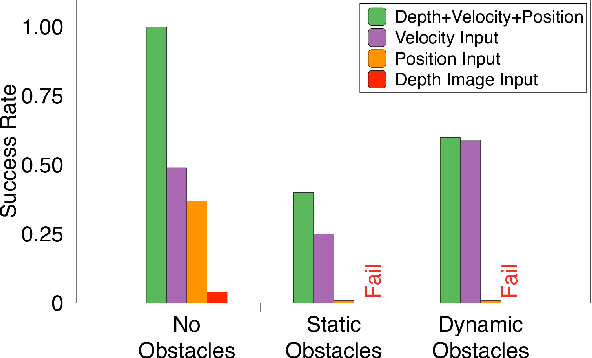
Fully autonomous navigation using nano drones has numerous applications in the real world, ranging from search and rescue to source seeking. Nano drones are well-suited for source seeking because of their agility, low price, and ubiquitous character. Unfortunately, their constrained form factor limits flight time, sensor payload, and compute capability. These challenges are a crucial limitation for the use of source-seeking nano drones in GPS-denied and highly cluttered environments. Hereby, we introduce a fully autonomous deep reinforcement learning-based light-seeking nano drone. The 33-gram nano drone performs all computation on-board the ultra-low-power microcontroller (MCU). We present the method for efficiently training, converting, and utilizing deep reinforcement learning policies. Our training methodology and novel quantization scheme allow fitting the trained policy in 3 kB of memory. The quantization scheme uses representative input data and input scaling to arrive at a full 8-bit model. Finally, we evaluate the approach in simulation and flight tests using a Bitcraze CrazyFlie, achieving 80% success rate on average in a highly cluttered and randomized test environment. Even more, the drone finds the light source in 29% fewer steps compared to a baseline simulation (obstacle avoidance without source information). To our knowledge, this is the first deep reinforcement learning method that enables source seeking within a highly constrained nano drone demonstrating robust flight behavior. Our general methodology is suitable for any (source seeking) highly constrained platform using deep reinforcement learning.
The Role of Compute in Autonomous Aerial Vehicles
Jun 24, 2019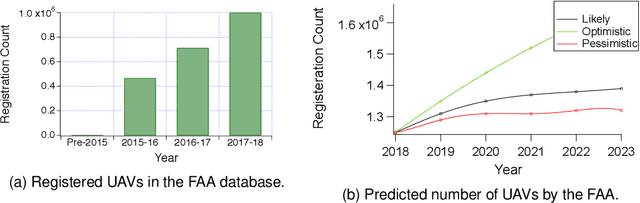
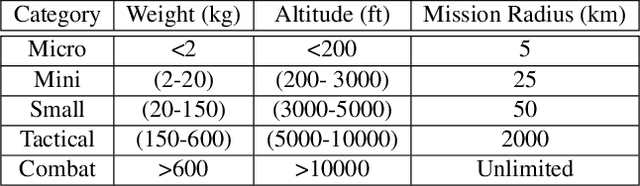

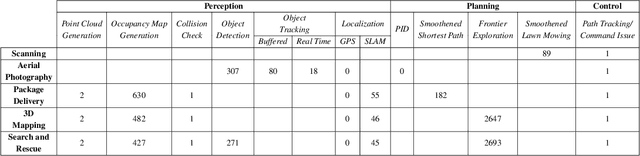
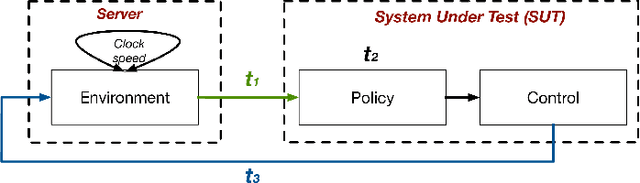
Autonomous-mobile cyber-physical machines are part of our future. Specifically, unmanned-aerial-vehicles have seen a resurgence in activity with use-cases such as package delivery. These systems face many challenges such as their low-endurance caused by limited onboard-energy, hence, improving the mission-time and energy are of importance. Such improvements traditionally are delivered through better algorithms. But our premise is that more powerful and efficient onboard-compute should also address the problem. This paper investigates how the compute subsystem, in a cyber-physical mobile machine, such as a Micro Aerial Vehicle, impacts mission-time and energy. Specifically, we pose the question as what is the role of computing for cyber-physical mobile robots? We show that compute and motion are tightly intertwined, hence a close examination of cyber and physical processes and their impact on one another is necessary. We show different impact paths through which compute impacts mission-metrics and examine them using analytical models, simulation, and end-to-end benchmarking. To enable similar studies, we open sourced MAVBench, our tool-set consisting of a closed-loop simulator and a benchmark suite. Our investigations show cyber-physical co-design, a methodology where robot's cyber and physical processes/quantities are developed with one another consideration, similar to hardware-software co-design, is necessary for optimal robot design.
Air Learning: An AI Research Platform for Algorithm-Hardware Benchmarking of Autonomous Aerial Robots
Jun 09, 2019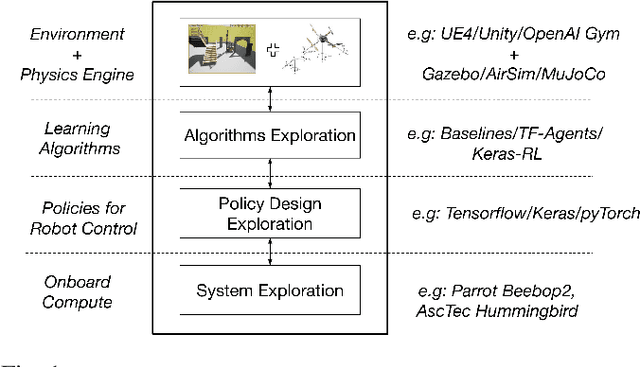
We introduce Air Learning, an AI research platform for benchmarking algorithm-hardware performance and energy efficiency trade-offs. We focus in particular on deep reinforcement learning (RL) interactions in autonomous unmanned aerial vehicles (UAVs). Equipped with a random environment generator, AirLearning exposes a UAV to a diverse set of challenging scenarios. Users can specify a task, train different RL policies and evaluate their performance and energy efficiency on a variety of hardware platforms. To show how Air Learning can be used, we seed it with Deep Q Networks (DQN) and Proximal Policy Optimization (PPO) to solve a point-to-point obstacle avoidance task in three different environments, generated using our configurable environment generator. We train the two algorithms using curriculum learning and non-curriculum-learning. Air Learning assesses the trained policies' performance, under a variety of quality-of-flight (QoF) metrics, such as the energy consumed, endurance and the average trajectory length, on resource-constrained embedded platforms like a Ras-Pi. We find that the trajectories on an embedded Ras-Pi are vastly different from those predicted on a high-end desktop system, resulting in up to 79.43% longer trajectories in one of the environments. To understand the source of such differences, we use Air Learning to artificially degrade desktop performance to mimic what happens on a low-end embedded system. QoF metrics with hardware-in-the-loop characterize those differences and expose how the choice of onboard compute affects the aerial robot's performance. We also conduct reliability studies to demonstrate how Air Learning can help understand how sensor failures affect the learned policies. All put together, Air Learning enables a broad class of RL studies on UAVs. More information and code for Air Learning can be found here: http://bit.ly/2JNAVb6.
MAVBench: Micro Aerial Vehicle Benchmarking
Jun 01, 2019
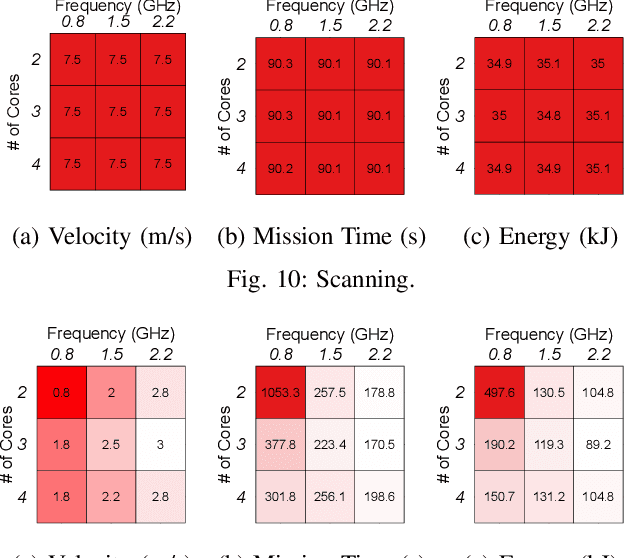
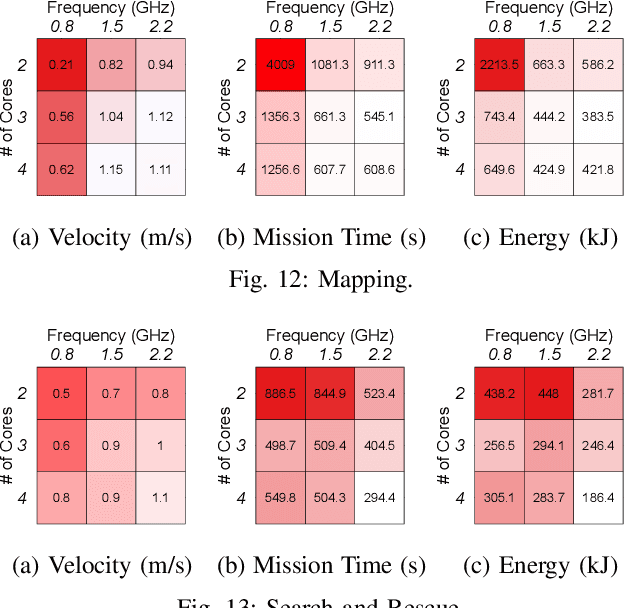
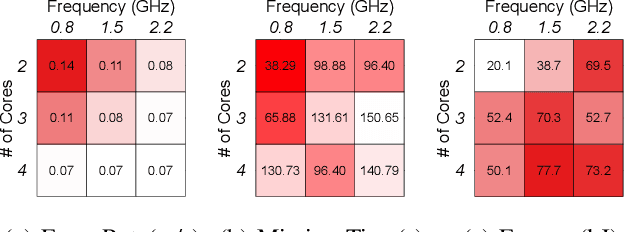
Unmanned Aerial Vehicles (UAVs) are getting closer to becoming ubiquitous in everyday life. Among them, Micro Aerial Vehicles (MAVs) have seen an outburst of attention recently, specifically in the area with a demand for autonomy. A key challenge standing in the way of making MAVs autonomous is that researchers lack the comprehensive understanding of how performance, power, and computational bottlenecks affect MAV applications. MAVs must operate under a stringent power budget, which severely limits their flight endurance time. As such, there is a need for new tools, benchmarks, and methodologies to foster the systematic development of autonomous MAVs. In this paper, we introduce the `MAVBench' framework which consists of a closed-loop simulator and an end-to-end application benchmark suite. A closed-loop simulation platform is needed to probe and understand the intra-system (application data flow) and inter-system (system and environment) interactions in MAV applications to pinpoint bottlenecks and identify opportunities for hardware and software co-design and optimization. In addition to the simulator, MAVBench provides a benchmark suite, the first of its kind, consisting of a variety of MAV applications designed to enable computer architects to perform characterization and develop future aerial computing systems. Using our open source, end-to-end experimental platform, we uncover a hidden, and thus far unexpected compute to total system energy relationship in MAVs. Furthermore, we explore the role of compute by presenting three case studies targeting performance, energy and reliability. These studies confirm that an efficient system design can improve MAV's battery consumption by up to 1.8X.