 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Reinforcement Learning (QUARL)
Paper and Code
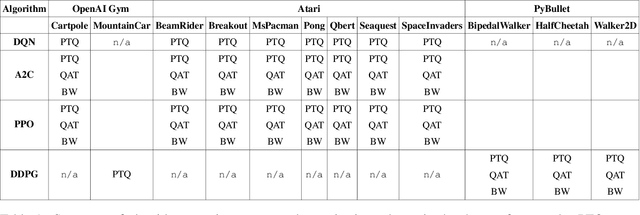
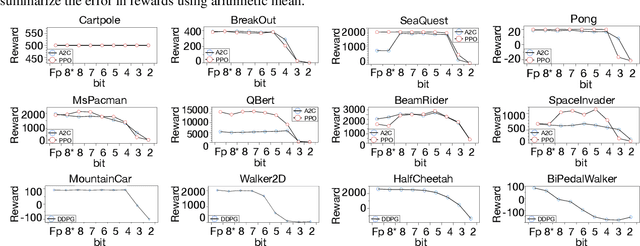
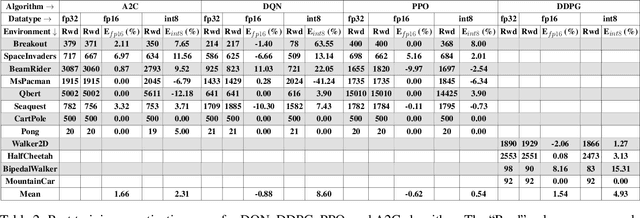
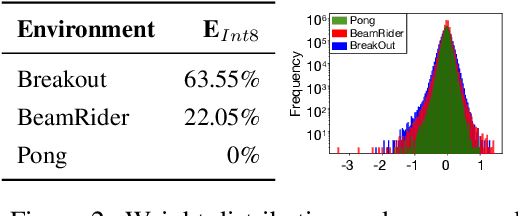
Recent work has shown that quantization can help reduce the memory, compute, and energy demands of deep neural networks without significantly harming their quality. However, whether these prior techniques, applied traditionally to image-based models, work with the same efficacy to the sequential decision making process in reinforcement learning remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the effects of quantization on various deep reinforcement learning policies with the intent to reduce their computational resource demands. We apply techniques such as post-training quantization and quantization aware training to a spectrum of reinforcement learning tasks (such as Pong, Breakout, BeamRider and more) and training algorithms (such as PPO, A2C, DDPG, and DQN). Across this spectrum of tasks and learning algorithms, we show that policies can be quantized to 6-8 bits of precision without loss of accuracy. We also show that certain tasks and reinforcement learning algorithms yield policies that are more difficult to quantize due to their effect of widening the models' distribution of weights and that quantization aware training consistently improves results over post-training quantization and oftentimes even over the full precision baseline. Finally, we demonstrate real-world applications of quantization for reinforcement learning. We use half-precision training to train a Pong model 50% faster, and we deploy a quantized reinforcement learning based navigation policy to an embedded system, achieving an 18$\times$ speedup and a 4$\times$ reduction in memory usage over an unquantized policy.