 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019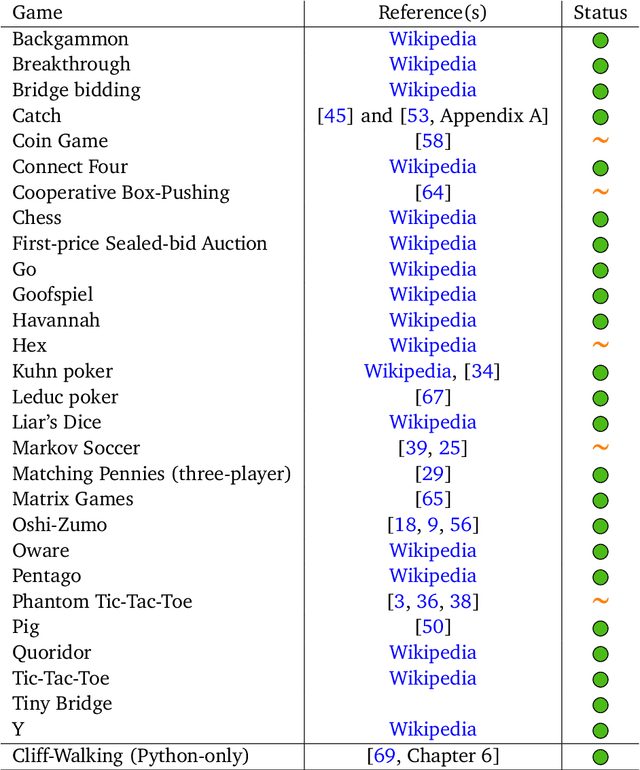
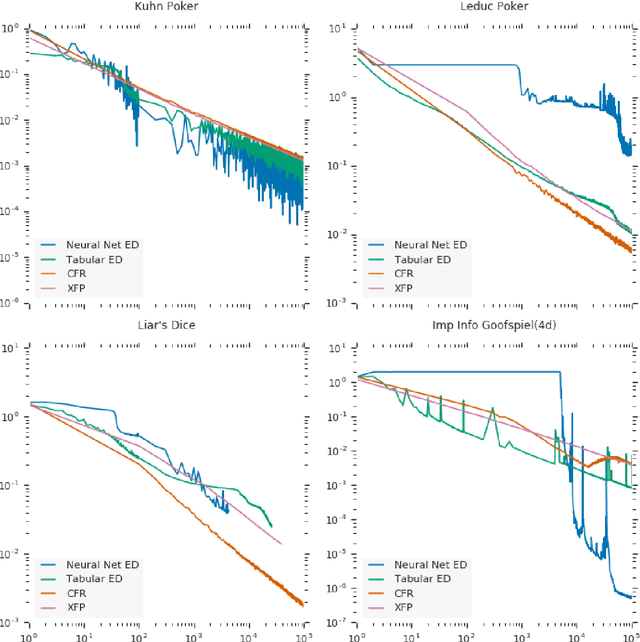
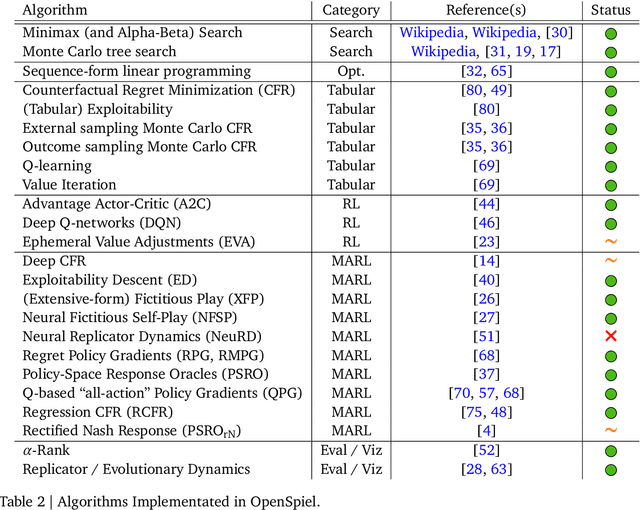
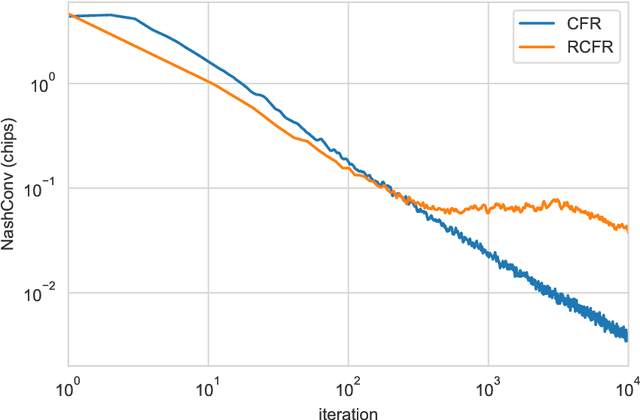
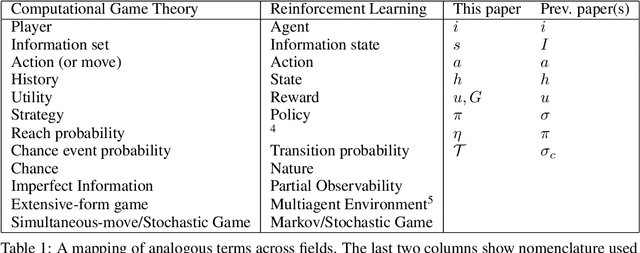
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
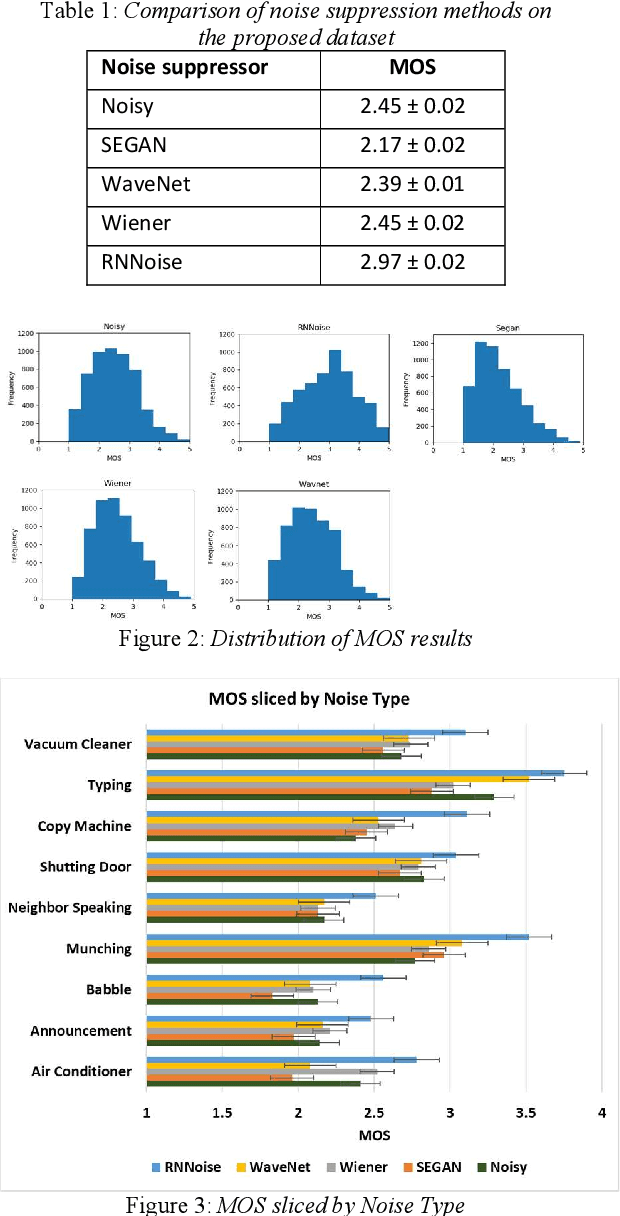
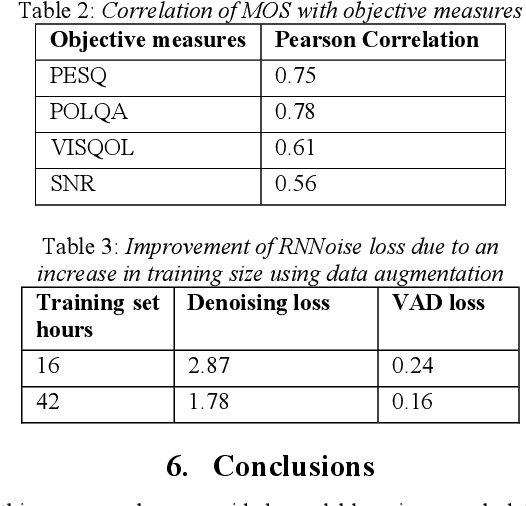
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.
Actor-Critic Policy Optimization in Partially Observable Multiagent Environments
Oct 21, 2018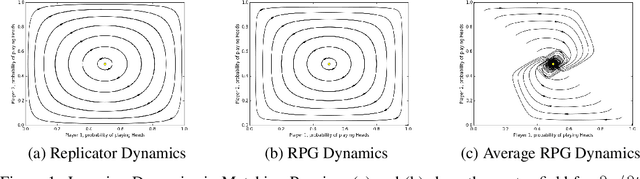
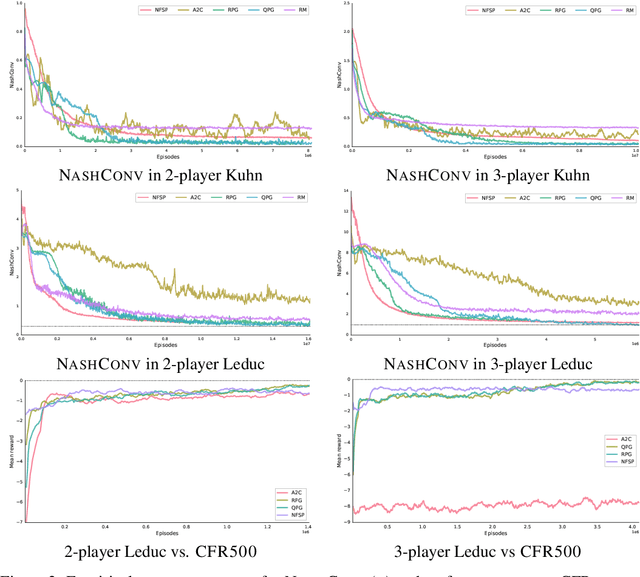
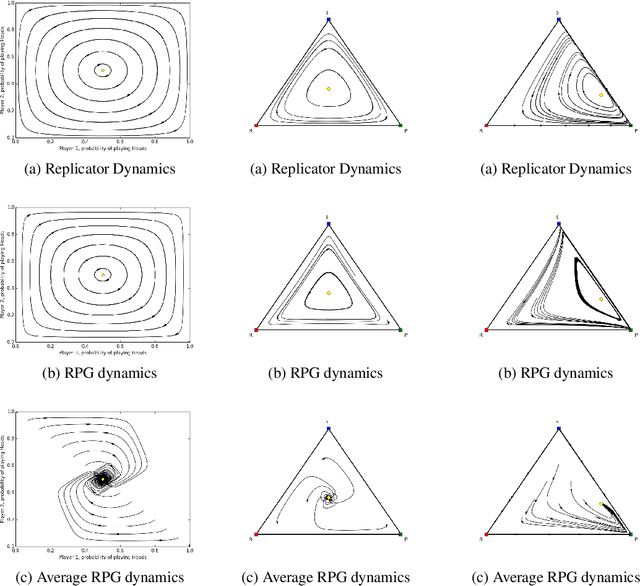
Optimization of parameterized policies for reinforcement learning (RL) is an important and challenging problem in artificial intelligence. Among the most common approaches are algorithms based on gradient ascent of a score function representing discounted return. In this paper, we examine the role of these policy gradient and actor-critic algorithms in partially-observable multiagent environments. We show several candidate policy update rules and relate them to a foundation of regret minimization and multiagent learning techniques for the one-shot and tabular cases, leading to previously unknown convergence guarantees. We apply our method to model-free multiagent reinforcement learning in adversarial sequential decision problems (zero-sum imperfect information games), using RL-style function approximation. We evaluate on commonly used benchmark Poker domains, showing performance against fixed policies and empirical convergence to approximate Nash equilibria in self-play with rates similar to or better than a baseline model-free algorithm for zero sum games, without any domain-specific state space reductions.
A Fairness-aware Hybrid Recommender System
Sep 13, 2018
Recommender systems are used in variety of domains affecting people's lives. This has raised concerns about possible biases and discrimination that such systems might exacerbate. There are two primary kinds of biases inherent in recommender systems: observation bias and bias stemming from imbalanced data. Observation bias exists due to a feedback loop which causes the model to learn to only predict recommendations similar to previous ones. Imbalance in data occurs when systematic societal, historical, or other ambient bias is present in the data. In this paper, we address both biases by proposing a hybrid fairness-aware recommender system. Our model provides efficient and accurate recommendations by incorporating multiple user-user and item-item similarity measures, content, and demographic information, while addressing recommendation biases. We implement our model using a powerful and expressive probabilistic programming language called probabilistic soft logic. We experimentally evaluate our approach on a popular movie recommendation dataset, showing that our proposed model can provide more accurate and fairer recommendations, compared to a state-of-the art fair recommender system.
DS-MLR: Exploiting Double Separability for Scaling up Distributed Multinomial Logistic Regression
Aug 03, 2018
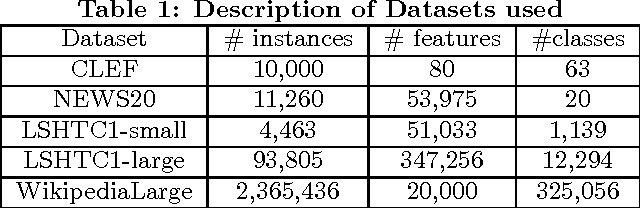
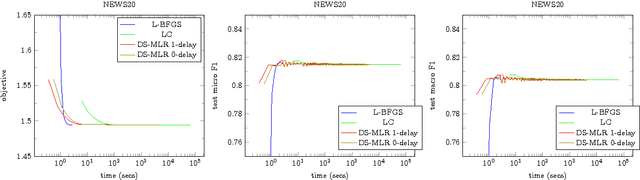
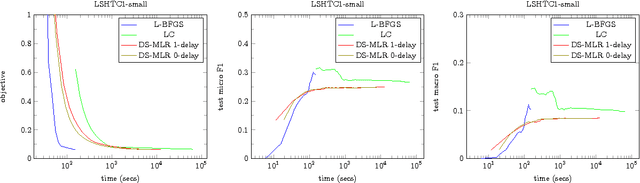
Scaling multinomial logistic regression to datasets with very large number of data points and classes is challenging. This is primarily because one needs to compute the log-partition function on every data point. This makes distributing the computation hard. In this paper, we present a distributed stochastic gradient descent based optimization method (DS-MLR) for scaling up multinomial logistic regression problems to massive scale datasets without hitting any storage constraints on the data and model parameters. Our algorithm exploits double-separability, an attractive property that allows us to achieve both data as well as model parallelism simultaneously. In addition, we introduce a non-blocking and asynchronous variant of our algorithm that avoids bulk-synchronization. We demonstrate the versatility of DS-MLR to various scenarios in data and model parallelism, through an extensive empirical study using several real-world datasets. In particular, we demonstrate the scalability of DS-MLR by solving an extreme multi-class classification problem on the Reddit dataset (159 GB data, 358 GB parameters) where, to the best of our knowledge, no other existing methods apply.
Learning human behaviors from motion capture by adversarial imitation
Jul 10, 2017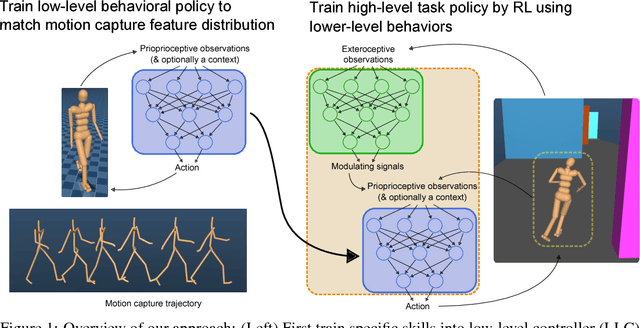
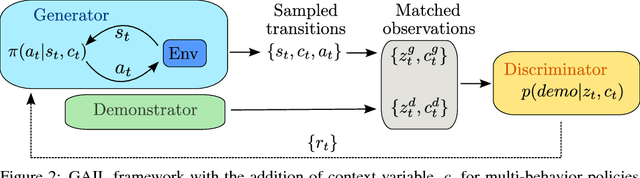
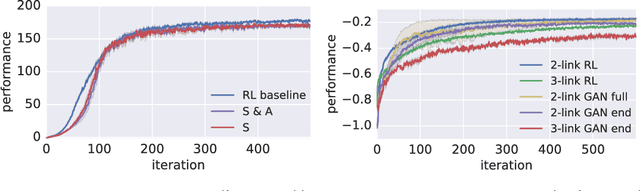
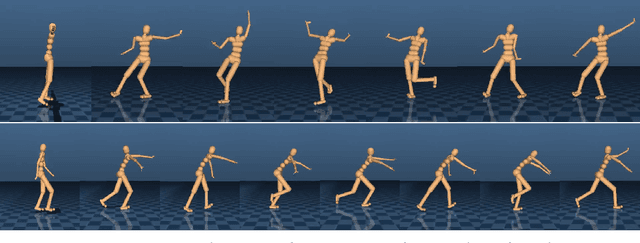
Rapid progress in deep reinforcement learning has made it increasingly feasible to train controllers for high-dimensional humanoid bodies. However, methods that use pure reinforcement learning with simple reward functions tend to produce non-humanlike and overly stereotyped movement behaviors. In this work, we extend generative adversarial imitation learning to enable training of generic neural network policies to produce humanlike movement patterns from limited demonstrations consisting only of partially observed state features, without access to actions, even when the demonstrations come from a body with different and unknown physical parameters. We leverage this approach to build sub-skill policies from motion capture data and show that they can be reused to solve tasks when controlled by a higher level controller.
Neural Episodic Control
Mar 06, 2017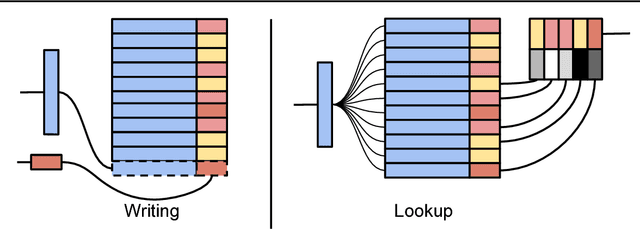
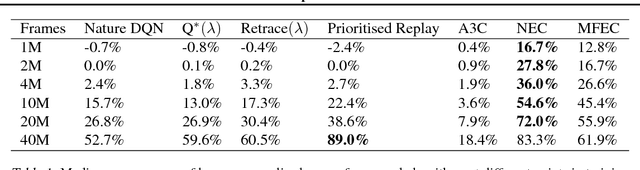
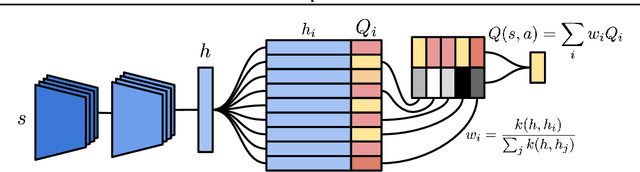
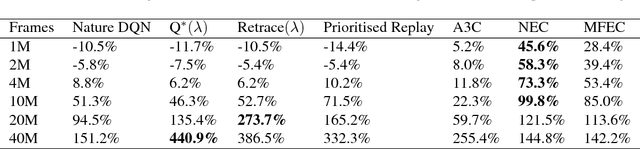
Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.
Unifying Count-Based Exploration and Intrinsic Motivation
Nov 07, 2016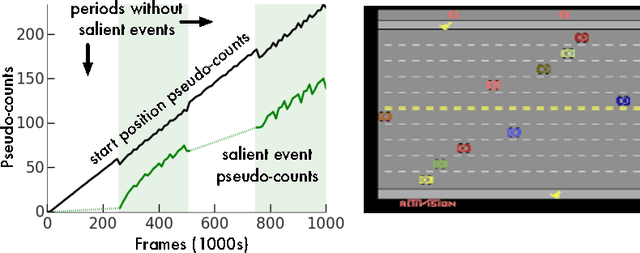

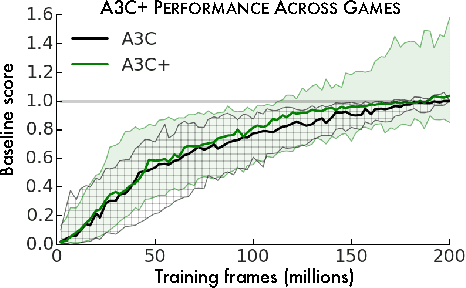
We consider an agent's uncertainty about its environment and the problem of generalizing this uncertainty across observations. Specifically, we focus on the problem of exploration in non-tabular reinforcement learning. Drawing inspiration from the intrinsic motivation literature, we use density models to measure uncertainty, and propose a novel algorithm for deriving a pseudo-count from an arbitrary density model. This technique enables us to generalize count-based exploration algorithms to the non-tabular case. We apply our ideas to Atari 2600 games, providing sensible pseudo-counts from raw pixels. We transform these pseudo-counts into intrinsic rewards and obtain significantly improved exploration in a number of hard games, including the infamously difficult Montezuma's Revenge.
Domain-Independent Optimistic Initialization for Reinforcement Learning
Oct 16, 2014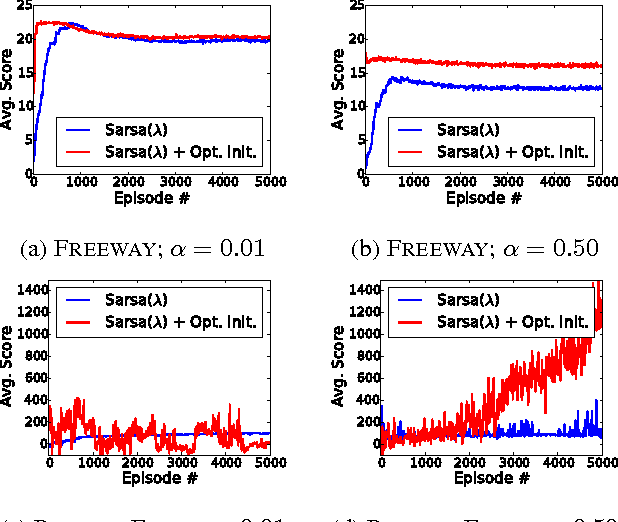
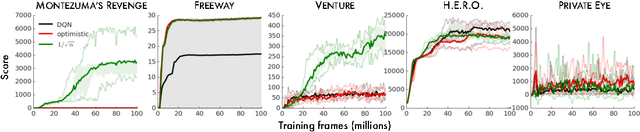
In Reinforcement Learning (RL), it is common to use optimistic initialization of value functions to encourage exploration. However, such an approach generally depends on the domain, viz., the scale of the rewards must be known, and the feature representation must have a constant norm. We present a simple approach that performs optimistic initialization with less dependence on the domain.