 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
Agent Tools Orchestration Leaks More: Dataset, Benchmark, and Mitigation
Dec 18, 2025



Driven by Large Language Models, the single-agent, multi-tool architecture has become a popular paradigm for autonomous agents due to its simplicity and effectiveness. However, this architecture also introduces a new and severe privacy risk, which we term Tools Orchestration Privacy Risk (TOP-R), where an agent, to achieve a benign user goal, autonomously aggregates information fragments across multiple tools and leverages its reasoning capabilities to synthesize unexpected sensitive information. We provide the first systematic study of this risk. First, we establish a formal framework, attributing the risk's root cause to the agent's misaligned objective function: an overoptimization for helpfulness while neglecting privacy awareness. Second, we construct TOP-Bench, comprising paired leakage and benign scenarios, to comprehensively evaluate this risk. To quantify the trade-off between safety and robustness, we introduce the H-Score as a holistic metric. The evaluation results reveal that TOP-R is a severe risk: the average Risk Leakage Rate (RLR) of eight representative models reaches 90.24%, while the average H-Score is merely 0.167, with no model exceeding 0.3. Finally, we propose the Privacy Enhancement Principle (PEP) method, which effectively mitigates TOP-R, reducing the Risk Leakage Rate to 46.58% and significantly improving the H-Score to 0.624. Our work reveals both a new class of risk and inherent structural limitations in current agent architectures, while also offering feasible mitigation strategies.
Exploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
Jul 30, 2025Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.
Libra: Large Chinese-based Safeguard for AI Content
Jul 29, 2025



Large language models (LLMs) excel in text understanding and generation but raise significant safety and ethical concerns in high-stakes applications. To mitigate these risks, we present Libra-Guard, a cutting-edge safeguard system designed to enhance the safety of Chinese-based LLMs. Leveraging a two-stage curriculum training pipeline, Libra-Guard enhances data efficiency by employing guard pretraining on synthetic samples, followed by fine-tuning on high-quality, real-world data, thereby significantly reducing reliance on manual annotations. To enable rigorous safety evaluations, we also introduce Libra-Test, the first benchmark specifically designed to evaluate the effectiveness of safeguard systems for Chinese content. It covers seven critical harm scenarios and includes over 5,700 samples annotated by domain experts. Experiments show that Libra-Guard achieves 86.79% accuracy, outperforming Qwen2.5-14B-Instruct (74.33%) and ShieldLM-Qwen-14B-Chat (65.69%), and nearing closed-source models like Claude-3.5-Sonnet and GPT-4o. These contributions establish a robust framework for advancing the safety governance of Chinese LLMs and represent a tentative step toward developing safer, more reliable Chinese AI systems.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025



The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
AgentAlign: Navigating Safety Alignment in the Shift from Informative to Agentic Large Language Models
May 29, 2025The acquisition of agentic capabilities has transformed LLMs from "knowledge providers" to "action executors", a trend that while expanding LLMs' capability boundaries, significantly increases their susceptibility to malicious use. Previous work has shown that current LLM-based agents execute numerous malicious tasks even without being attacked, indicating a deficiency in agentic use safety alignment during the post-training phase. To address this gap, we propose AgentAlign, a novel framework that leverages abstract behavior chains as a medium for safety alignment data synthesis. By instantiating these behavior chains in simulated environments with diverse tool instances, our framework enables the generation of highly authentic and executable instructions while capturing complex multi-step dynamics. The framework further ensures model utility by proportionally synthesizing benign instructions through non-malicious interpretations of behavior chains, precisely calibrating the boundary between helpfulness and harmlessness. Evaluation results on AgentHarm demonstrate that fine-tuning three families of open-source models using our method substantially improves their safety (35.8% to 79.5% improvement) while minimally impacting or even positively enhancing their helpfulness, outperforming various prompting methods. The dataset and code have both been open-sourced.
LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions
May 22, 2025High-quality long-context instruction data is essential for aligning long-context large language models (LLMs). Despite the public release of models like Qwen and Llama, their long-context instruction data remains proprietary. Human annotation is costly and challenging, while template-based synthesis methods limit scale, diversity, and quality. We introduce LongMagpie, a self-synthesis framework that automatically generates large-scale long-context instruction data. Our key insight is that aligned long-context LLMs, when presented with a document followed by special tokens preceding a user turn, auto-regressively generate contextually relevant queries. By harvesting these document-query pairs and the model's responses, LongMagpie produces high-quality instructions without human effort. Experiments on HELMET, RULER, and Longbench v2 demonstrate that LongMagpie achieves leading performance on long-context tasks while maintaining competitive performance on short-context tasks, establishing it as a simple and effective approach for open, diverse, and scalable long-context instruction data synthesis.
LyapLock: Bounded Knowledge Preservation in Sequential Large Language Model Editing
May 21, 2025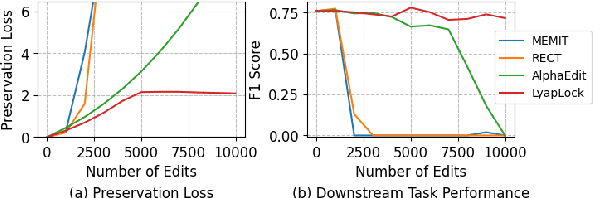
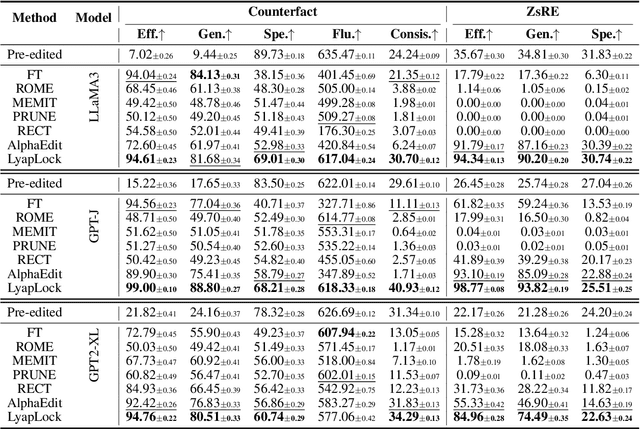
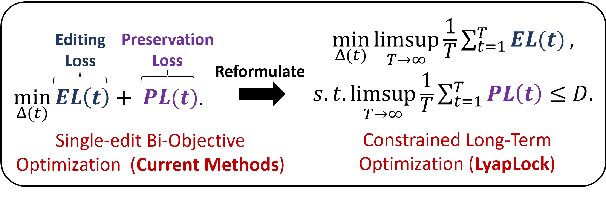
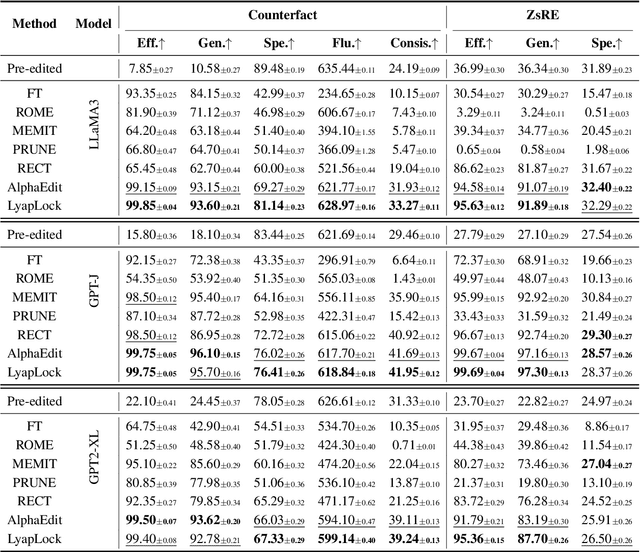
Large Language Models often contain factually incorrect or outdated knowledge, giving rise to model editing methods for precise knowledge updates. However, current mainstream locate-then-edit approaches exhibit a progressive performance decline during sequential editing, due to inadequate mechanisms for long-term knowledge preservation. To tackle this, we model the sequential editing as a constrained stochastic programming. Given the challenges posed by the cumulative preservation error constraint and the gradually revealed editing tasks, \textbf{LyapLock} is proposed. It integrates queuing theory and Lyapunov optimization to decompose the long-term constrained programming into tractable stepwise subproblems for efficient solving. This is the first model editing framework with rigorous theoretical guarantees, achieving asymptotic optimal editing performance while meeting the constraints of long-term knowledge preservation. Experimental results show that our framework scales sequential editing capacity to over 10,000 edits while stabilizing general capabilities and boosting average editing efficacy by 11.89\% over SOTA baselines. Furthermore, it can be leveraged to enhance the performance of baseline methods. Our code is released on https://github.com/caskcsg/LyapLock.
LightRetriever: A LLM-based Hybrid Retrieval Architecture with 1000x Faster Query Inference
May 18, 2025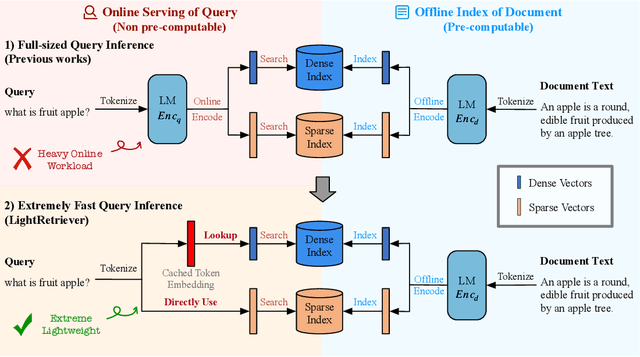
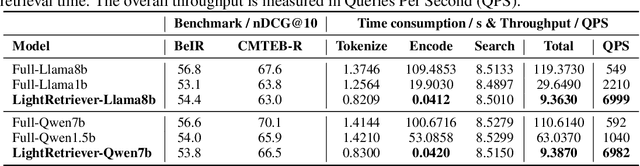

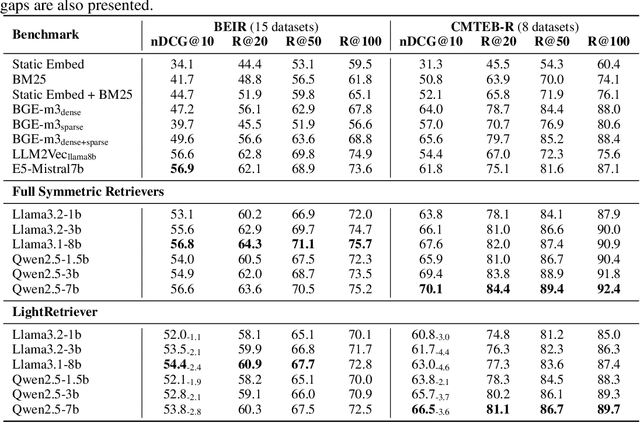
Large Language Models (LLMs)-based hybrid retrieval uses LLMs to encode queries and documents into low-dimensional dense or high-dimensional sparse vectors. It retrieves documents relevant to search queries based on vector similarities. Documents are pre-encoded offline, while queries arrive in real-time, necessitating an efficient online query encoder. Although LLMs significantly enhance retrieval capabilities, serving deeply parameterized LLMs slows down query inference throughput and increases demands for online deployment resources. In this paper, we propose LightRetriever, a novel LLM-based hybrid retriever with extremely lightweight query encoders. Our method retains a full-sized LLM for document encoding, but reduces the workload of query encoding to no more than an embedding lookup. Compared to serving a full-sized LLM on an H800 GPU, our approach achieves over a 1000x speedup for query inference with GPU acceleration, and even a 20x speedup without GPU. Experiments on large-scale retrieval benchmarks demonstrate that our method generalizes well across diverse retrieval tasks, retaining an average of 95% full-sized performance.
Enhancing Multi-Hop Fact Verification with Structured Knowledge-Augmented Large Language Models
Mar 11, 2025



The rapid development of social platforms exacerbates the dissemination of misinformation, which stimulates the research in fact verification. Recent studies tend to leverage semantic features to solve this problem as a single-hop task. However, the process of verifying a claim requires several pieces of evidence with complicated inner logic and relations to verify the given claim in real-world situations. Recent studies attempt to improve both understanding and reasoning abilities to enhance the performance, but they overlook the crucial relations between entities that benefit models to understand better and facilitate the prediction. To emphasize the significance of relations, we resort to Large Language Models (LLMs) considering their excellent understanding ability. Instead of other methods using LLMs as the predictor, we take them as relation extractors, for they do better in understanding rather than reasoning according to the experimental results. Thus, to solve the challenges above, we propose a novel Structured Knowledge-Augmented LLM-based Network (LLM-SKAN) for multi-hop fact verification. Specifically, we utilize an LLM-driven Knowledge Extractor to capture fine-grained information, including entities and their complicated relations. Besides, we leverage a Knowledge-Augmented Relation Graph Fusion module to interact with each node and learn better claim-evidence representations comprehensively. The experimental results on four common-used datasets demonstrate the effectiveness and superiority of our model.