 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Lower Privileges Suffice: Investigating Over-Privileged Tool Selection in LLM Agents
Jun 18, 2026As LLM agents increasingly select tools autonomously, their choices among tools with different privileges become safety-relevant. However, prior tool-selection studies focus on safety-agnostic metadata preferences, leaving privilege-sensitive choices underexplored. To address this gap, we study over-privileged tool selection, in which an agent selects or escalates to a higher-privilege tool despite a sufficient lower-privilege alternative. We introduce ToolPrivBench to evaluate whether agents choose higher-privilege tools despite sufficient lower-privilege alternatives, measuring both initial selection and escalation after transient tool failures. Across eight domains and five recurring risk patterns, we find that over-privileged tool selection is common among mainstream LLM agents and is further amplified by transient failures. We further find that general safety alignment does not reliably transfer to least-privilege tool choice, while prompt-level controls provide only limited mitigation under transient failures. We therefore introduce a privilege-aware post-training defense that teaches agents to prefer sufficient lower-privilege tools and escalate only when necessary. Our mitigation experiments show that this defense substantially reduces unnecessary high-privilege tool use while preserving general capabilities.
When the Manual Lies: A Realistic Benchmark to Evaluate MCP Poisoning Attacks for LLM Agents
May 22, 2026The rise of tool-using Large Language Model (LLM) agents, standardized by protocols like the Model Context Protocol (MCP), has unlocked unprecedented autonomous execution capabilities for LLM Agents by integrating external open-domain knowledge and tools. However, this interoperability introduces a covert attack surface targeting the agent's cognitive planning layer. This paper systematically investigates Tool Description Poisoning (TDP), a novel semantic attack. In TDP, malicious instructions are not embedded in a tool's executable code, but rather covertly injected into its descriptive metadata, the very "manual" an agent relies on for secure planning and decision-making. To rigorously and systematically evaluate this emerging threat, we introduce the MCP-TDP Security Benchmark. This high-fidelity sandbox environment comprises 32 realistic, real-world test cases spanning 6 distinct risk categories. Our evaluation of 8 mainstream LLMs reveals severe vulnerabilities, with leading models like GPT-4o exhibiting a nearly 100% Attack Success Rate (ASR) in six high-risk scenarios. Furthermore, our findings demonstrate that common prompt-guardrail defenses are largely ineffective and can, counterintuitively, even be counterproductive (a phenomenon which we term the "Firewall Fallacy"). Crucially, we also propose a defense mechanism: "Reactive Self-Correction," where an agent autonomously detects and reverts its own malicious actions post-execution. This work provides the first specialized security benchmark tailored for TDP, offering essential insights for securing the cognitive and planning layers of advanced agentic systems.
RouteGuard: Internal-Signal Detection of Skill Poisoning in LLM Agents
Apr 24, 2026Agent skills introduce a new and more severe form of indirect injection for LLM agents: unlike traditional indirect prompt injection, attackers can hide malicious instructions inside a dense, action-oriented skill that already functions as a legitimate instruction source. We study pre-execution skill-poison detection and show that successful skill poisoning induces a structured internal effect, attention hijacking, in which response-time attention shifts from trusted context to malicious skill spans and drives harmful behavior. Motivated by this mechanism, we propose RouteGuard, a frozen-backbone detector that combines response-conditioned attention and hidden-state alignment through reliability-gated late fusion. Across both real and synthetic open-source skill benchmarks, RouteGuard is consistently the strongest or most robust detector; on the critical Skill-Inject channel slice, it reaches 0.8834 F1 and recovers 90.51% of description attacks missed by lexical screening, showing that defending against skill poisoning requires internal-signal detection rather than text-only filtering
FABLE: Fine-grained Fact Anchoring for Unstructured Model Editing
Apr 14, 2026Unstructured model editing aims to update models with real-world text, yet existing methods often memorize text holistically without reliable fine-grained fact access. To address this, we propose FABLE, a hierarchical framework that decouples fine-grained fact injection from holistic text generation. FABLE follows a two-stage, fact-first strategy: discrete facts are anchored in shallow layers, followed by minimal updates to deeper layers to produce coherent text. This decoupling resolves the mismatch between holistic recall and fine-grained fact access, reflecting the unidirectional Transformer flow in which surface-form generation amplifies rather than corrects underlying fact representations. We also introduce UnFine, a diagnostic benchmark with fine-grained question-answer pairs and fact-level metrics for systematic evaluation. Experiments show that FABLE substantially improves fine-grained question answering while maintaining state-of-the-art holistic editing performance. Our code is publicly available at https://github.com/caskcsg/FABLE.
Exploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
Jul 30, 2025Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025



The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
LyapLock: Bounded Knowledge Preservation in Sequential Large Language Model Editing
May 21, 2025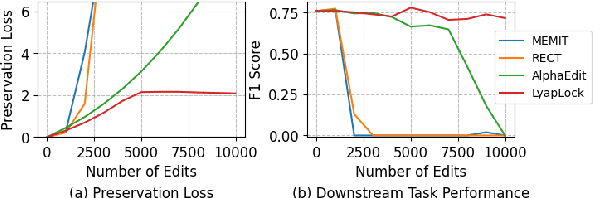
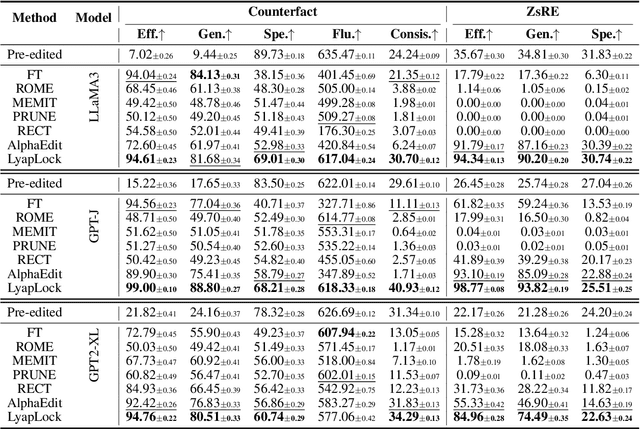
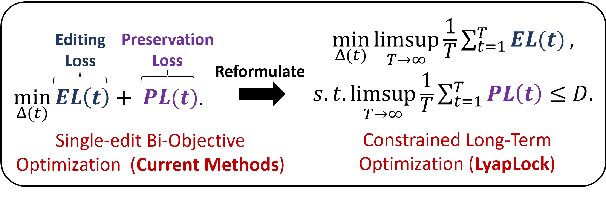
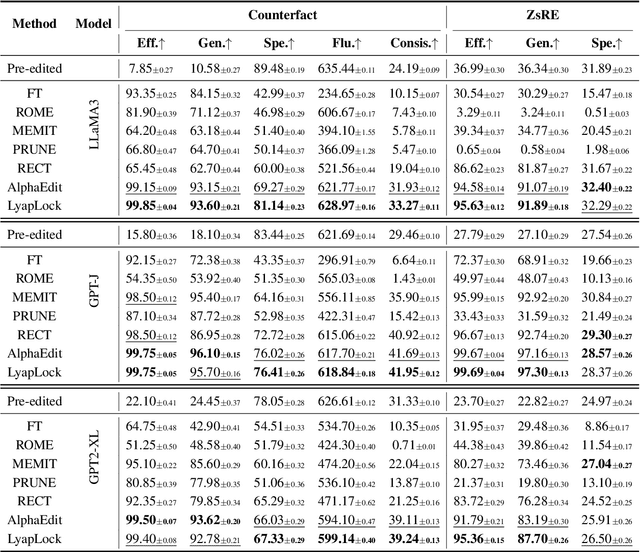
Large Language Models often contain factually incorrect or outdated knowledge, giving rise to model editing methods for precise knowledge updates. However, current mainstream locate-then-edit approaches exhibit a progressive performance decline during sequential editing, due to inadequate mechanisms for long-term knowledge preservation. To tackle this, we model the sequential editing as a constrained stochastic programming. Given the challenges posed by the cumulative preservation error constraint and the gradually revealed editing tasks, \textbf{LyapLock} is proposed. It integrates queuing theory and Lyapunov optimization to decompose the long-term constrained programming into tractable stepwise subproblems for efficient solving. This is the first model editing framework with rigorous theoretical guarantees, achieving asymptotic optimal editing performance while meeting the constraints of long-term knowledge preservation. Experimental results show that our framework scales sequential editing capacity to over 10,000 edits while stabilizing general capabilities and boosting average editing efficacy by 11.89\% over SOTA baselines. Furthermore, it can be leveraged to enhance the performance of baseline methods. Our code is released on https://github.com/caskcsg/LyapLock.